冷热概念
冷数据
如何优化
- 进行汇总:销售报表
- 持久化:压缩、采用更节省空间的存储结构
热数据
经常需要进行高强度的计算任务
冷热数据分离存储查询思路
分库:
1、数据库分库而不是分表,分表需要考虑后期的查询问题,此外还需要注意分表的算法(哈希算法)。
2、热数据只占全部数据的一部分,因此每次优先查询热库,以下情况才查询冷库
- 当查询条件未命中(结果集为空)时,查询冷库。
- 当查询条件部分命中时,查询冷库。
3、为了区分部分命中和全部命中,可以在热库中建一张R表存放每次查询冷库的查询条件和查询结果数量和查询结果的主键,每次查询热库时,对比相同查询条件的查询结果数量是否一致。一致,则本次查询结束。不一致,则需要到冷库中进行查询。
4、更优方案:不一致的情况,只到冷库中查询未查到的数据。此时R表需要存放的不仅是查询结果数量,还有查询结果的所有主键。
5、举例说明:100条中80条还是热数据 20条变成了冷数据,其实应该只是对冷数据库发起这20条数据的请求。此时需要将R表数据拿出来比对,只查一部分冷数据。
6、热库=>冷库 : 查询和使用热数据时,将一段时间不再使用的热数据移到冷库。
7、冷库=>热库 :查询冷库时,将本次查询的结果移到热库,附上最新查询日期。
8、数据同步(每次查询进行或达到一定量级进行)
9、关于命中的处理:制定查询条件字典 如 where a=? and b=? 这个条件的字典为
public static IDictionary<int,int> QueryKeyValues =new IDictionary<int,int>{(0,1),(1,2),(3,3)}
先进行查询条件的字典命中处理=> 假设此时的查询方法为 queryFunction(int a,int b) ;
public object QueryFunction(int a,int b) {1.若 <a,b> 存在于 QueryKeyValues中则到R表中找出查询条件为<a,b>的IdString都有哪些以此将Id分开存取2.获得IdString后 比对需要到冷库查询的List<string> singleId3.循环执行单条语句查询逻辑 SingleColdDBQuery(List<string> singleId)}
分表:
例:按数据的新旧分表
比如我现在有一个订单表,日均写入几万几十万数据进去,可以这样处理,存储数据的时候存储双份,order表存一份数据,order_history表同样也存一份数据,然后呢,order表弄一个定时任务,每天定期删除30天以上的数据(一般半夜删数据),一天无非几万条数据,性能影响几乎没有,不过量多的话,删除就要小心点,不然很容易就锁表,可以查一下一个月前的数据的区间范围(表的主键id范围),然后呢按区间删除,几千几千的删除(可以自行调节,保证 IOPS跟CUP别跑满就行),这样就能保证不会锁表;order_history表不做任何删除操作,只插入新的数据,保留最原始的数据。
说一下表的查询,一个月以内的数据直接在order表查询就行,一个月以上的旧数据在history表查,order_history表的查询可以配合搜索引擎进行处理(比如阿里云的opensearch),每次查出对应的主键id(节省opensearch的流量,要钱的!),然后再去order_history根据主键查数据,这里底层封装好就行
使用redis实现冷热数据分离
来源:CSDN博客
一,当前KV数据库从存储介质可以分为两种模式:
1,一种是以内存为主持久化为辅,如memcache(无持久化),redis等—————侧重高性能
2,一种是以持久化为主内存为辅,如ssdb(基于leveldb/rocksdb存储引擎)———-侧重大容量
冷热分离方案主要基于redis或者基于redis协议及命令实现
方案一 改造redis,是它支持冷热分离
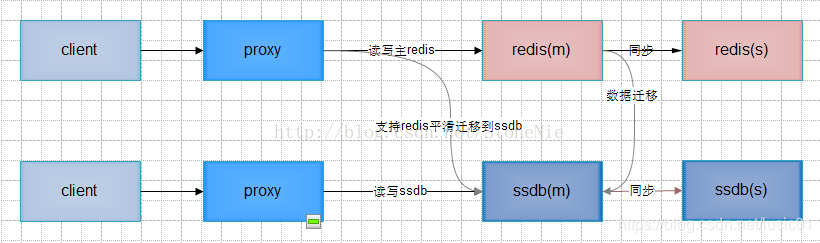
client————————->proxy———-读写主redis———->redis(m)——同步——>redis(s)
client—————————>proxy——-读写ssdb—————>ssdb(m)<——同步———>ssdb(s)
支持redis平滑迁移到ssdb
实现描述:
可以使用开源的rocksdb或imdb引擎读写落地数据
写操作全部记录在内存,不同步写磁盘
常驻写子进程定时将内存中的数据写到磁盘
内存中标记不存在的key,如果一个key在磁盘上不存在,则在标记之后不用再去磁盘查看这个值是否存在
读操作先读内存,如内存中不存在且key未被标识磁盘不存在,则由读子进程从磁盘读并写回到redis(key不存在才写回)。之后子进程通知主进程再次读取,此过程会阻塞主进程上单个连接的处理。
优点:真正意义上实现单机redis的冷热分离。redis和落地数据在同一台机器,容易保证数据一致性。
缺点:基于redis做二次开发,后续不方便升级redis

若有收获,就点个赞吧
0 人点赞
