写给自己
Mysql作为目前世界上使用最广泛的免费数据库,相信所有从事系统运维的工程师都一定接触过。但在实际的生产环境中,由单台Mysql作为独立的数据库是完全不能满足实际需求的,无论是在安全性,高可用性以及高并发等各个方面。
随着业务规模的不断扩大,需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量。 关于数据库的扩展主要包括:业务拆分、主从复制,数据库分库与分表。
创作时间
作者
正文
一、 业务拆分
二、 主从复制
MySQL的Replication(英文为复制)是一个多MySQL数据库做主从同步的方案,特点是异步复制。 一般来说都是通过主从复制(Master-Slave)的方式来同步数据。
MySQL Replication 就是从服务器拉取主服务器上的二进制日志文件,然后再将日志文件解析成相应的SQL语句在从服务器上重新执行一遍主服务器的操作,通过这种方式来保证数据的一致性。
应用
应用场景场景——实现读写分离,或业务分离,即运行报表,备份,数据仓库等应用。
最易配置,对应用改动最小,并可以减轻主库的负担。 主数据库可以读写,从数据库只读。
为什么要使用主从同步?
- 实时灾备,用于故障切换
- 读写负载均衡
- 定时任务专用
- 开发人员查看
1. 主从复制原理
master(主)在执行sql之后,记录二进制log文件(bin-log)。
slave(从)连接master,并从master获取binlog,存于本地relay-log中,然后从上次记住的位置起执行SQL语句,一旦遇到错误则停止同步。
简记:MySQL的主从复制,实际上就是Master记录自己的执行日志binlog,然后发送给Slave,Slave解析日志并执行,来实现数据复制。
2. 流程分析
- 主服务器流程分析
首先bin-log日志文件加锁,然后读取更新的操作,读取完毕以后将锁释放掉,最后将读取的记录发送给从服务器。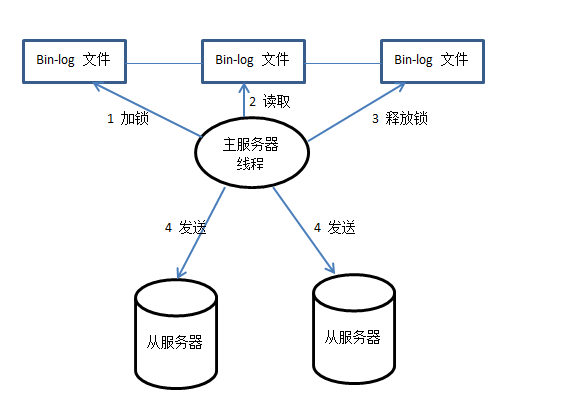
- 从服务器流程分析
在一次主从复制过程中需要用到三个线程:Binlog dump 线程、Slave I/O 线程和Slave SQL线程,其中Binlog dump 线程在主服务器上面,剩下的两个线程是在从服务器上面工作的。
这两个线程在从服务器上面的工作流程如下图所示: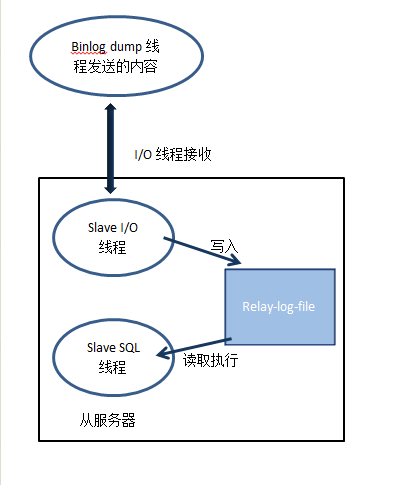
3. 如何提高Mysql主从复制的效率
1.master 端 master端有2个参数可以控制。
Binlog_Do_DB : 设定哪些数据库需要记录Binlog。Binlog_Ignore_DB : 设定哪些数据库不要记录Binlog。
2.slave 端
slave端有6个参数可以控制。Replicate_Do_DB : 设定须要复制的数据库,多个DB用逗号分隔。 Replicate_Ignore_DB : 设定可以忽略的数据库。 Replicate_Do_Table : 设定须要复制的Table。 Replicate_Ignore_Table : 设定可以忽略的Table。 Replicate_Wild_Do_Table : 功能同Replicate_Do_Table,但可以带通配符来进行设置。 Replicate_Wild_Ignore_Table : 功能同Replicate_Ig-nore_Table,可带通配符设置。
4. 常见主从同步方案

环形多主:环环相扣(赤壁之战,铁锁连船),任何一个master挂掉系统就不可用了
级联同步,一主多从:选择一个从节点作为主节点故障时临时主节点
三、 分库分表
拆分后库、表的数量一般为2的n次方,这样方便计算,计算机世界本身就是二进制嘛,好干活。
约定一下库、表索引从0开始,但是存的第一条数据0001则存在1库1表中,需要注意。
1. 分表 (水平分区)
对于访问极为频繁且数据量巨大的单表来说,我们首先要做的就是减少单表的记录条数(字段),以便减少数据查询所需要的时间,提高数据库的吞吐,这就是所谓的分表!
将原有的单表分为16个表
算法 :order_id%16
2. 分库 (垂直分区)
分表能够解决单表数据量过大带来的查询效率下降的问题,但是,却无法给数据库的并发处理能力带来质的提升。面对高并发的读写访问,对数据库进行拆分,从而提高数据库写入能力,这就是所谓的分库!
将原有的单库分为8个库
算法 :order_id%8
3. 分库分表(综合优化)
有时数据库可能既面临着高并发访问的压力,又需要面对海量数据的存储问题,这时需要对数据库既采用分表策略,又采用分库策略,以便同时扩展系统的并发处理能力,以及提升单表的查询性能,这就是所谓的分库分表。
一种分库分表的路由策略如下:
1. temp = order_id% (分库数量 * 每个库的表数量)
2. 对应库索引 = 取整数 (temp / 每个库的表数量)
3. 对应表索引 = temp % 每个库的表数量
举例:
假设将原来的单库单表order拆分成个8库,每个库包含16个表,那么按照前面所提到的路由策略,
对于order_id=7180 的访问,路由的计算过程如下:
temp = 7180 % (8 * 16) = 12
对应库索引 = 取整 (12/8) = 1
对应表索引 = 12 % 16 = 12
这就意味着,对于order_id=7180的订单记录的查询和修改,将被路由到第1个库的第12个order_12表中执行!!!
四、 生成有序增长的id
当我们对MySQL进行分表操作后,将不能依赖MySQL的自动增量来产生唯一ID了,因为数据已经分散到多个表中。 应尽量避免使用自增IP来做为主键,为数据库分表操作带来极大的不便。 在postgreSQL、oracle、db2数据库中有一个特殊的特性—-sequence。 任何时候数据库可以根据当前表中的记录数大小和步长来获取到该表下一条记录数。然而,MySQL是没有这种序列对象的。 可以通过下面的方法来实现sequence特性产生唯一ID:
1、 通过MySQL表生成ID
对于插入也就是insert操作,首先就是获取唯一的id了,就需要一个表来专门创建id,插入一条记录,并获取最后插入的ID。代码如下:
CREATE TABLE ttlsa_com.create_id (
id BIGINT( 20 ) NOT NULL AUTO_INCREMENT PRIMARY KEY
) ENGINE = MYISAM
也就是说,当我们需要插入数据的时候,必须由这个表来产生id值。
这种方法效果很好,但是在高并发情况下,MySQL的AUTO_INCREMENT将导致整个数据库慢。如果存在自增字段,MySQL会维护一个自增 锁,innodb会在内存里保存一个计数器来记录auto_increment值,当插入一个新行数据时,就会用一个表锁来锁住这个计数器,直到插入结 束。如果是一行一行的插入是没有问题的,但是在高并发情况下,那就悲催了,表锁会引起SQL阻塞,极大的影响性能,还可能会达到 max_connections值。 innodb_autoinc_lock_mode:可以设定3个值:0、1、2
0:traditonal (每次都会产生表锁) 1:consecutive (默认,可预判行数时使用新方式,不可时使用表锁,对于simple insert会获得批量的锁,保证连续插入) 2:interleaved (不会锁表,来一个处理一个,并发最高)
对于myisam表引擎是traditional,每次都会进行表锁的。
2、 通过redis生成ID
3、 队列方式
其实这也算是上面的一个解说 使用队列服务,如redis、memcacheq等等,将一定量的ID预分配在一个队列里,每次插入操作,先从队列中获取一个ID,若插入失败的话,将该ID再次添加到队列中,同时监控队列数量,当小于阀值时,自动向队列中添加元素。 这种方式可以有规划的对ID进行分配,还会带来经济效应,比如QQ号码,各种靓号,明码标价。如网站的userid, 允许uid登陆,推出各种靓号,明码标价,对于普通的ID打乱后再随机分配。
外部参考
Sharding-Proxy
简介
Sharding-Sphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar这3款相互独立的产品组成。他们均提供标准化的数据分片、读写分离、柔性事务和数据治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
官网
Github
https://github.com/sharding-sphere
三大核心模块分别是Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar。
shardingsphere Apache项目
结束语

若有收获,就点个赞吧
0 人点赞
