数据插入
客户端通过调用 insert 接口来插入数据,单次插入的数据量不能大于 256 MB。插入数据的流程如下:
- 服务端接收到插入请求后,将数据写入预写日志(WAL)。
- 当预写日志成功记录后,返回插入操作。
- 将数据写入可写缓冲区(mutable buffer)。
每个集合都有独立的可写缓冲区。每个可写缓冲区的容量上限是 128 MB。所有集合的可写缓冲区总容量上限由系统参数 insert_buffer_size 决定,默认是 1 GB。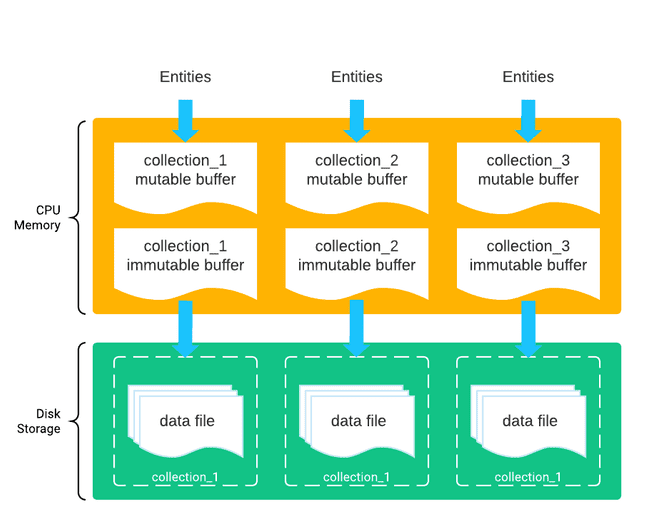
数据落盘
定时触发
系统会定时触发落盘任务。定时间隔由系统参数 auto_flush_interval 决定,默认是 1 秒。
落盘操作的流程如下:
- 系统开辟一块新的可写缓冲区,用于容纳后续插入的数据。
- 系统将之前的可写缓冲区设为只读(immutable buffer)。
- 系统把只读缓冲区的数据写入磁盘,并将新数据段的描述信息写入元数据后端服务。
完成以上流程后,系统就成功创建了一个数据段(segment)。
客户端触发
缓冲区达到上限触发
累积数据达到可写缓冲区的上限(128MB)会触发落盘操作。
每个数据段的所有相关文件都被存放在以段 ID 命名的文件夹中,比如记录实体 ID 的 UID 文件、用于标记已被删除实体的 delete_docs 文件,以及用于快速查找实体的布隆过滤器(bloom-filter)文件。
段内数据文件请参考 分区和数据段 中的示意图。
self.milvus.flush([collection_name])
数据合并
小数据段过多会导致查询性能低下。为了避免此问题,Milvus 会在需要的时候触发后台段合并任务,即把小数据段合并成新的数据段,并删除小数据段、更新元数据。其中,新数据段的大小不低于 index_file_size。
合并操作的触发时机如下:
- 启动服务时
- 完成落盘任务后
- 建索引前
- 删除索引后
已经建立了索引的数据段不会参与合并操作。
milvus.compact([collection_name])
建立索引
未建立索引之前,Milvus 对集合的查询操作都是以暴力搜索(brute-force search)的方式完成的。为提高查询性能,你可以为集合建立合适的索引。索引建成后,每个数据段都会产生一个索引文件,此时元数据也会同步更新。
def Create_index(self, collection):index_param = {'nlist': 2048}status = self.milvus.create_index(collection, IndexType.IVF_SQ8H, index_param)print("Creating index: {}".format(index_param), status)status, index = self.milvus.get_index_info(collection)print(index)def Drop_index(self, collection):self.milvus.drop_index(collection)

若有收获,就点个赞吧
0 人点赞
