一、索引介绍
索引是对数据库表中一列或多列的值进行排序的一种结构。在关系数据库中,索引是一种与表有关的数据库结构。它能够使相应于表的SQL语句运行得更快。<br /> 索引是一个单独的、物理的数据库结构。它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引提供指向存储在表的指定列中的数据值的指针。然后依据您指定的排序顺序对这些指针排序。<br />数据库使用索引的方式与您使用书籍中的索引的方式非常类似:它搜索索引以找到特定值,然后顺指针找到包括该值的行。在数据库关系图中,能够在选定表的“索引/键”属性页中创建、编辑或删除每一个索引类型。当保存索引所附加到的表,或保存该表所在的关系图时,索引将保存在数据库中。<br />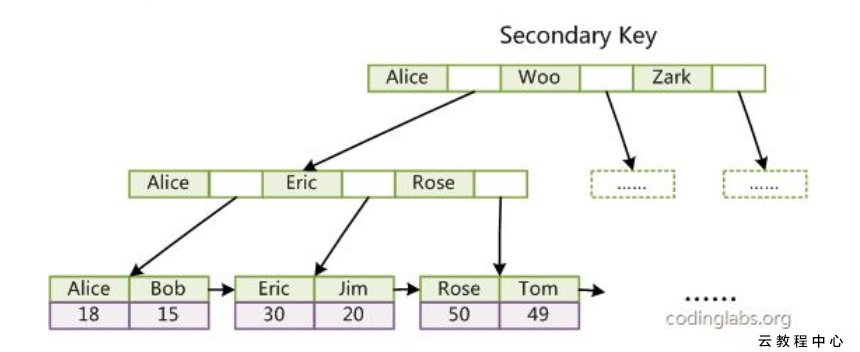<br />**聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。**<br /> 引申:为什么不建议使用过长的字段作为主键?<br /> 因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
聚簇索引与非聚簇索引
InnoDB 使用的是聚簇索引, 将主键组织到一棵 B+树中, 而行数据就储存在叶子节点上, 若使用”where id = 14”这样的条件查找主键, 则按照 B+树的检索算法即可查找到对应的叶节点, 之后获得行数据。 若对 Name 列进行条件搜索, 则需要两个步骤:
第一步在辅助索引 B+树中检索 Name, 到达其叶子节点获取对应的主键。
第二步使用主键在主索引 B+树种再执行一次 B+树检索操作, 最终到达叶子节点即可获取整行数据。
MyISM 使用的是非聚簇索引, 非聚簇索引的两棵 B+树看上去没什么不同, 节点
的结构完全一致只是存储的内容不同而已, 主键索引 B+树的节点存储了主键, 辅助键索引B+树存储了辅助键。 表数据存储在独立的地方, 这两颗 B+树的叶子节点都使用一个地址指向真正的表数据, 对于表数据来说, 这两个键没有任何差别。 由于索引树是独立的, 通过辅助键检索无需访问主键的索引树。
为了更形象说明这两种索引的区别, 我们假想一个表如下图存储了 4 行数据。 其中Id 作为主索引, Name 作为辅助索引。 图示清晰的显示了聚簇索引和非聚簇索引的差异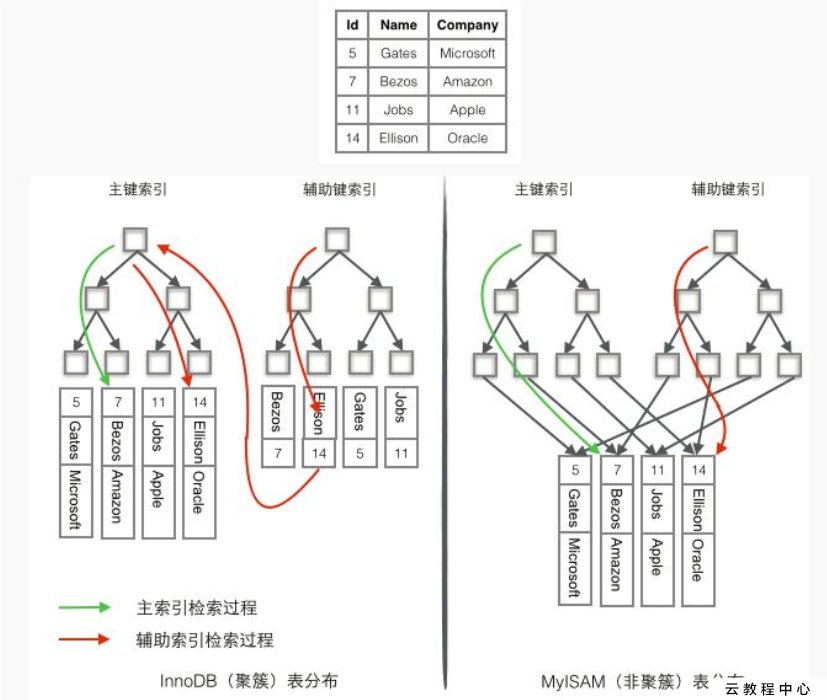
联合索引及最左原则
联合索引存储数据结构图: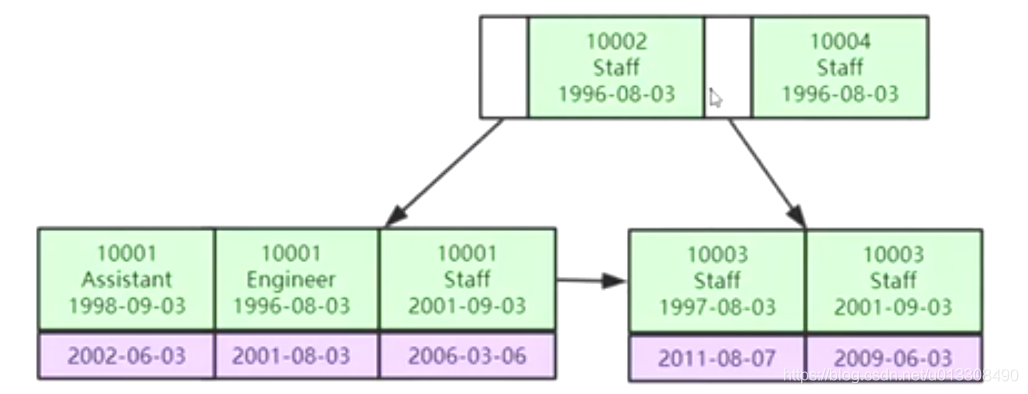
最左原则:
例如联合索引有三个索引字段(A,B,C)
查询条件:
(A,,)—-会使用索引
(A,B,)—-会使用索引
(A,B,C)—-会使用索引
(,B,C)—-不会使用索引
(,,C)—-不会使用索引
为什么一个节点为1页(16k)就够了
假设我们一行数据大小为1K,那么一页就能存16条数据,也就是一个叶子节点能存16条数据;再看非叶子节点,假设主键ID为bigint类型,那么长度为8B,指针大小在Innodb源码中为6B,一共就是14B,那么一页里就可以存储16K/14=1170个(主键+指针),那么一颗高度为2的B+树能存储的数据为:117016=18720条,一颗高度为3的B+树能存储的数据为:11701170*16=21902400(千万级条)。所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。在查找数据时一次页的查找代表一次IO,所以通过主键索引查询通常只需要1-3次IO操作即可查找到数据。所以也就回答了我们的问题,1页=16k这么设置是比较合适的,是适用大多数的企业的,当然这个值是可以修改的,所以也能根据业务的时间情况进行调整。

若有收获,就点个赞吧
0 人点赞
