DMA
直接内存访问( DMA)是一种允许硬件不经过 CPU 介入访问内存的特性。 在最高层面上,硬件被告知要传输的存储区域的源和目的地(及其大小),并被告知要复制数据。 某些硬件周边件甚至具有多“分散/收集”类型操作的能力,这样可以执行多个复制操作,一个接一个,而不需要额外的 CPU 干预。
DMA 注意事项
为了充分理解所涉及的问题,重要的是要记住以下几点:
- 每一个进程都在虚拟地址空间中运行,
- MMU 可以映射连续虚拟地址范围到多个非连续物理地址范围内(反之亦然),
- 每一个进程在物理地址空间中都有限制窗口,
- 某些周边件用输入/输出内存管理单元(IOMMU)支持他们自身的虚拟地址。
让我们依次来讨论以上提到的每点事项。
虚拟,物理和实体设备地址
进程访问的地址为虚拟地址;这就是说,它们是由 CPU 的内存管理单元(MMU)创造的假象。虚拟地址由 MMU 映射到物理地址中。映射的粒度是基于一个叫做“页表大小”的参数决定,这个参数最少为 4K 字节,而现代处理器上可以支持更大的大小。
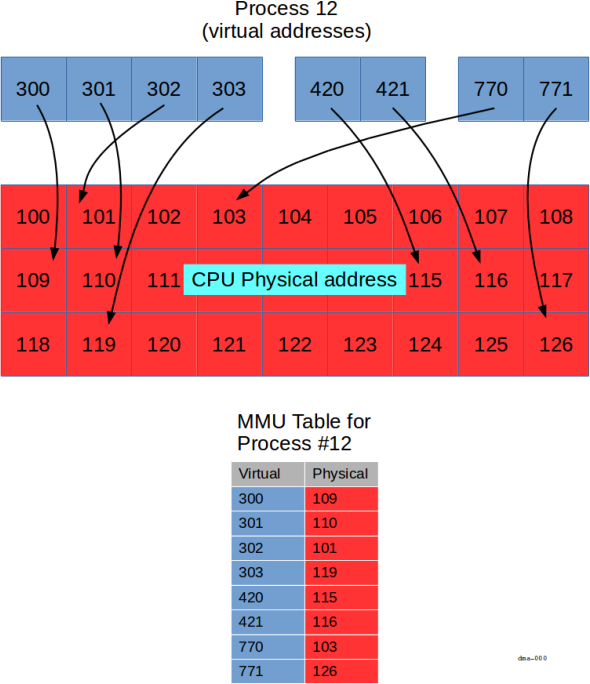
在上图中,我们展示了一个特定进程(进程12)带有一组虚拟地址(蓝色框中)。
MMU 负责映射蓝色的虚拟地址到 CPU 物理总线地址上(红色框中)。
每一个进程有它自己的映射规则;所以即使进程12有虚拟地址300,一些其他的进程可能也有虚拟地址300。
那些其他进程中的虚拟地址300(如果它存在的话)将被映射到和进程12中不一样的物理地址中。
注意:为了保持讨论的简单,我们使用很小的十进制数作为”地址”。 事实上,每一个上述展示的方块代表了一页内存( 4K 或者更多), 并由32位或64位值来标识(取决于平台决定)。
图中展示的关键点是:
- 虚拟地址可以按组分配(下面展示三组,
300-303,420-421和770-771), - 虚拟地址连续(例如
300-303)是不需要物理地址连续, - 某些虚拟地址是没有被映射的(例如,这里没有虚拟地址
304) - 不是所有的物理地址对于每一个进程都是可用的(例如,进程
12不能访问物理地址120)。
根据平台上的硬件可用性,设备地址空间可以或不用遵照相同的转译方式。 没有 IOMMU,周边件使用的地址就是和 CPU 使用的物理地址相同。

在上图中,设备地址空间(例如,一个帧缓存或控制寄存器)的部分直接出现在 CPU 的物理地址范围内。
这也就是说,设备占用从122 到125(包含)的物理地址。
为了让进程能够访问设备内存,需要创建一个从122到125的某些虚拟地址到物理地址的 MMU 映射。
我们可以从下图中看到怎样实现。
但是在 IOMMU 中,周边件看到的地址可能和 CPU 的物理地址不同:
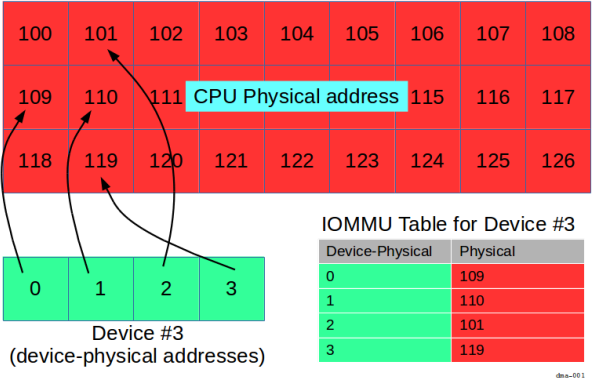
现在,设备拥有它自己知道的“实体设备”地址,也就是说,地址从0到3(包含3)。
由 IOMMU 将实体物理地址0 到3分别映射到 CPU 物理地址 109, 110, 101 和119上。
在这种规则下,为了进程能使用设备内存,就需要安排两个映射:
- 一组通过 MMU 完成从虚拟地址空间(例如
300到30)到 CPU 物理地址空间(分别到109,110,101, 和119上)的映射, - 一组通过 IOMMU 从 CPU 物理地址空间(
109,110,101, 和119)到实体设备地址(0到3)的映射。
虽然这看起来很复杂,但 Zircon 提供了一个抽象的概念来消除复杂性。
同样,正如我们在上图中看到的,拥有 IOMMU 的原因和它提供的好处和使用 MMU 是一样的。
内存连续性
当你分配了一大块内存(例如使用calloc())时,你当然能在进程中看到一块大的,连续的虚拟地址范围。 MMU 创建了一个连续内存在虚拟地址上的错觉,甚至 MMU 可以在物理地址层级上不连续内存中选择内存区域。
更进一步讲,因为进程分配和解除分配内存,所以物理内存到虚拟地址空间的映射则趋向于越来越复杂,这样会有更多的碎片(类”瑞士奶酪“的孔洞)出现(这也就是更多在映射中的非连续性)。
因此,重要的是要记住,连续的虚拟地址不一定是连续的物理地址,事实上,随着时间的推移,连续的物理内存会变得越来越珍贵。
访问控制
MMU 的另一个优势在于限制物理内存的视角(出于安全和可靠性的原因)。 尽管对驱动有一些影响,可能进程需要特别地请求虚拟地址空间到物理地址空间的映射,并且还要有必要权限去实现。
IOMMU
连续物理内存通常是首选项。 比起建立和管理多个独立转换(为了建立下一次转换,在每次转移时都可能需要 CPU 介入),完成一次转换(使用一个源地址和一个目的地地址)是更有效率的。
如果 IOMMU 可用,通过对外围设备执行与 CPU 的 MMU 对进程执行的相同操作,可以缓解这个问题 — 使用映射多个非连续块到一个虚拟连续空间,这让外围设备产生一种它们可以处理一个连续地址空间的假象。 通过限制映射区域, IOMMU 同样可以提供安全性(和 MMU 使用同样的方式),防止外设访问不在当前操作“范围内“的内存。
综上所述
所以,当你在写自己的驱动时,就会出现你需要关注虚拟,物理和实体设备地址空间的情况。 但事实并非如此。
DMA 和你的驱动
Zircon 提供一组功能,让你可以简单的处理以上提到的所有内容。 以下是要做的事:
BTI 内核对象提供一个抽象的模型和 API 来处理 VMO 相关的物理(或实体物理)地址。
在你的驱动初始化时,调用 pci_get_bti() 来获取 BTI 句柄。
zx_status_t pci_get_bti(const pci_protocol_t* pci,uint32_t index,zx_handle_t* bti_handle);
pci_get_bti()
函数获取pci协议指针(就像上述讨论的所有其他pci_…()函数一样)和index (保留给未来使用,现在使用0)。
它通过bti_handle指针参数返回了一个 BTI 句柄。
接下来,你需要一个 VMO 。 简而言之,你可以认为 VMO 作为一个内存块的指针,但是比指针更多的是 — 它是一个代表了一组虚拟页的内核对象(可能有,也可能没有确定的物理页),它可以被映射到驱动进程的虚拟地址空间。(它甚至还有其他更多意义,但我们将在不同的章节中再讨论。)
最后,这些页作为 DMA 传输的源或目的地。
这里有两个函数,zx_vmo_create() 和 zx_vmo_create_contiguous() 可以分配内存并绑定到 VMO上:
zx_status_t zx_vmo_create(uint64_t size,uint32_t options,zx_handle_t* out);zx_status_t zx_vmo_create_contiguous(zx_handle_t bti,size_t size,uint32_t alignment_log2,zx_handle_t* out);
正如你所了解到,它们同样都是获取size参数代表所需的字节数,并且它们同样都返回了一个 VMO (通过out句柄)。
它们都对给定的大小分配虚拟的连续页。
注意:这和标准 C 库的内存分配函数不同,(例如malloc()),它分配了虚拟连续内存,但不考虑页的界限。连续两次调用小的malloc()可能从相同的页中分配两个内存区域,但是,例如 VMO 创建函数却总是从一个新的页开始分配内存。
zx_vmo_create_contiguous()
函数则和
zx_vmo_create()
函数完成相同功能,并且确保页对于特定的 BTI 被适当地组织起来以供使用(这也是它为什么需要 BTI 句柄的原因)。
它同样提供一个alignment_log2参数的功能,可以被用来明确最小对齐需求。
正如名字所表达的,它必须是一个2的整数次方(数值0表示页对齐)。
在这一点上,你将对分配内存有两种“视角”:
- 一个连续虚拟地址空间,代表驱动看到的内存视角,和
- 一组(可能连续,可能确定)物理页,代表外设使用。
在使用这些页之前,你需要确保它们在内存中存在(这就是“确定”的意思—你的进程可以访问这些物理页),并且外设也可以访问它们(如果 IOMMU 存在,则通过它访问)。 同样你也需要页的地址(从设备的角度看),这样你可以在你设备上操作 DMA 控制器去访问它们。
zx_bti_pin() 函数用来做所有的事:
#include <zircon/syscalls.h>zx_status_t zx_bti_pin(zx_handle_t bti, uint32_t options,zx_handle_t vmo, uint64_t offset, uint64_t size,zx_paddr_t* addrs, size_t addrs_count,zx_handle_t* pmt);
在函数中有8个参数:
| Parameter | Purpose |
|---|---|
bti |
这个外设的 BTI |
options |
选项(见后续描述) |
vmo |
这个内存区域的 VMO |
offset |
VMO 的起始偏移 |
| `size | VMO 中的所有字节数 |
addrs |
返回地址的列表 |
addrs_count |
addrs 的元素数量 |
pmt |
返回 PMT (见后续描述) |
addrs参数是一组你要提供的zx_paddr_t指针。
这就是每个页的外设地址被返回的地方。
数组为addrs_count长度,而且必须匹配zx_bti_pin()期望的长度。
addrs中写入的数据对于规划外设的 DMA 控制器要适配— 也就是说,如果存在的话,需要考虑可能由 IOMMU 执行的任何转译。
从技术角度来看,zx_bti_pin() 的其他影响在于驱动将确保那些页在选中时没有被回收(例如移除或重用)。
options 参数是一个选项的位图:
| Option | Purpose |
|---|---|
ZX_BTI_PERM_READ |
外设可读的页 (由驱动写入) |
ZX_BTI_PERM_WRITE |
外设可写的页(由驱动读取) |
ZX_BTI_COMPRESS |
(参见下述“最小邻接性”) |
例如,参考上述展示的”Device #3”图片。
如果存在 IOMMU , addrs将包含 0, 1, 2, 和 3 (也就是设备-物理地址)。
如果不存在 IOMMU,addrs将包含 109, 110, 101, 和 119 (也就是物理地址)。
权限
请记住,这些权限是从外设的角度出发,而不是驱动。
例如,在块设备执行写 操作,设备从内存页中执行读取,因此驱动规定ZX_BTI_PERM_READ,反之亦然,在块设备中读取的话。
最小邻接性
默认情况,每一个通过addrs返回的地址都是一个页的长度。
更大的块通过在options参数中设置ZX_BTI_COMPRESS选项来申请。
在这种使用场景下,每一个条目返回的长度对应“最小邻接”属性。
当你没有设置这个属性时,你可以通过zx_object_get_info() 读取。
实际上,最小邻接性是zx_bti_pin() 总是可以返回至少有那么多字节的连续地址的保证。
例如如果设置为 1 MB,那么调用 zx_bti_pin() 请求 2 MB 页将返回最多两个物理连续的地址。 如果请求的大小为 2.5 MB,它将返回最多三个物理连续的地址,等等。
选中内存令牌 ( PMT )
zx_bti_pin() 运行成功,则通过pmt参数返回选中内存令牌 (PMT)。
当设备完成内存转移,取消固定并撤销对内存的访问,驱动必须调用zx_pmt_unpin() 。
拓展话题
缓存一致性
在完全 DMA 一致性的架构中,硬件在没有软件干预下,确保 CPU 缓存中的数据和在主存中的数据相同。但不是所有的架构都是 DMA 一致性的。在这些系统上,驱动必须通过在执行 DMA 操作之前调用内存范围上的适当缓存操作来确保 CPU 缓存是一致的,这样就不会访问到旧数据了。
为了在 VMO 代表的内存上调用缓存操作,使用zx_vmo_op_range() 系统调用接口。
在外设读取(驱动写入)操作之前,使用ZX_VMO_OP_CACHE_CLEAN清除缓存,来写出脏数据到主存中。在外设写入(驱动读取)操作之前,使用ZX_VMO_OP_CACHE_INVALIDATE标记无效化缓存线,来确保在下一次访问时从主存中取出数据。

若有收获,就点个赞吧
0 人点赞
