
分类业务不能随便拆 所有标签中都要分到
在训练之前,使用model selecion 中的方法,划分集合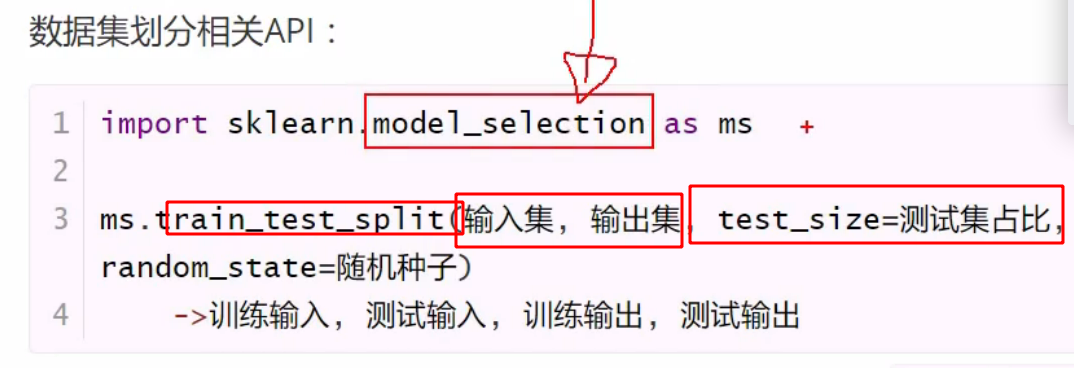
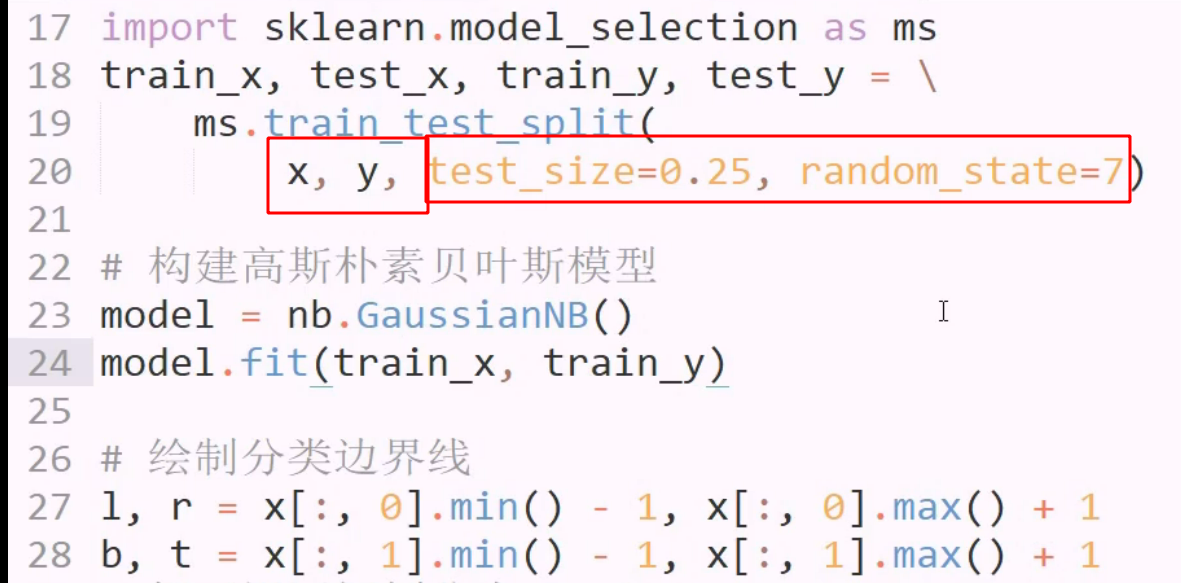 返回四个集合
返回四个集合
两个数组做比较运算,返回布尔数组
对布尔数组使用者sum,得到正确个数 为预测结果打分
为预测结果打分
交叉验证
 随机性导致 强势样本可能都被分到了站训练中,导致模型片面,考虑了太多异常,但测试时没有那么多特殊样本
随机性导致 强势样本可能都被分到了站训练中,导致模型片面,考虑了太多异常,但测试时没有那么多特殊样本
测试集中有大量的特殊样本,则评估有问题
 使用已经训练好的模型进行交叉验证,并指定交叉次数,指定评估指标(准确度,找回率)
使用已经训练好的模型进行交叉验证,并指定交叉次数,指定评估指标(准确度,找回率)
 每次交叉的得分,即准确度 accuracy
每次交叉的得分,即准确度 accuracy
泛化: 对所有交叉求均值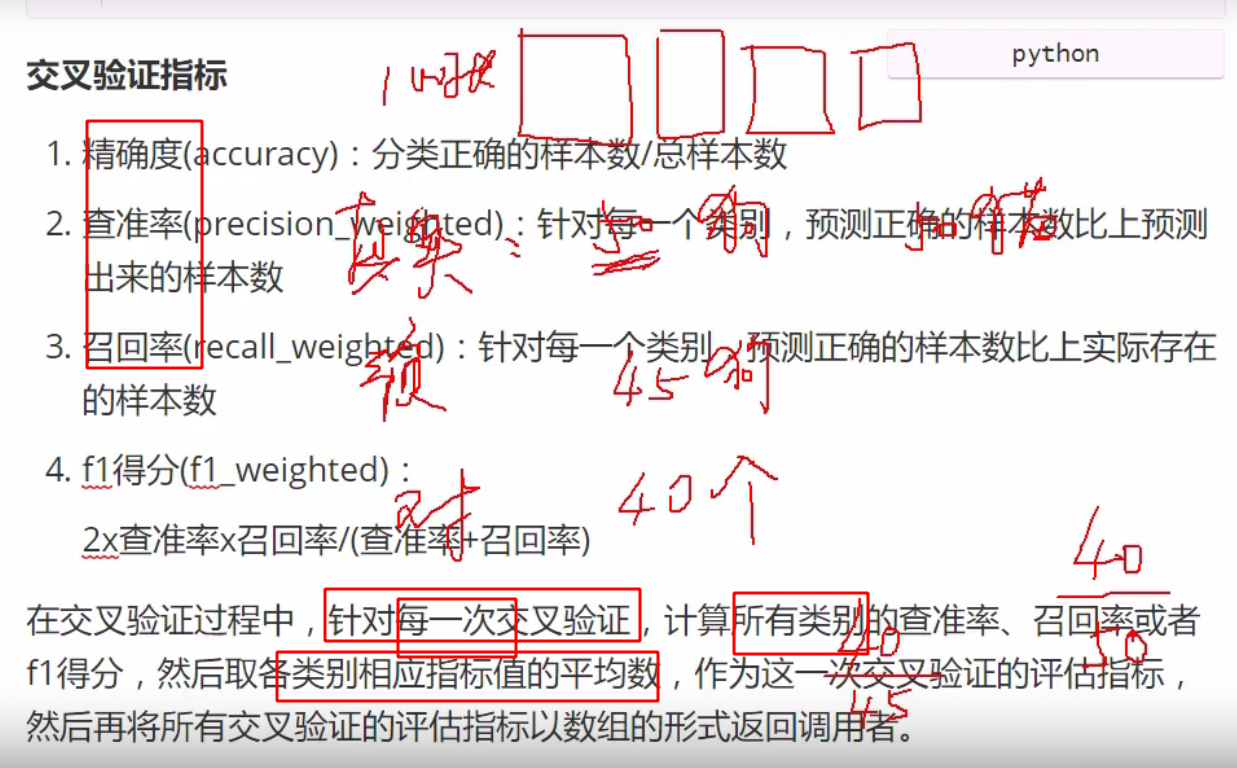
有些场景我们重视找回率,哪怕差准率很低也要全部找回
有些场景则反之
是不是小偷? 看差准率,没证据不能错杀
间黄石? 看找回率,可以错杀也不能放过
应该每个标签都有自己的指标,但这里交叉验证api 给的是四个标签均值
R2 F1 两个得分
交叉验证不能用于回归 没有类别对的上就不能用
混淆矩阵 用于评估模型的算法

一个矩阵表示所有指标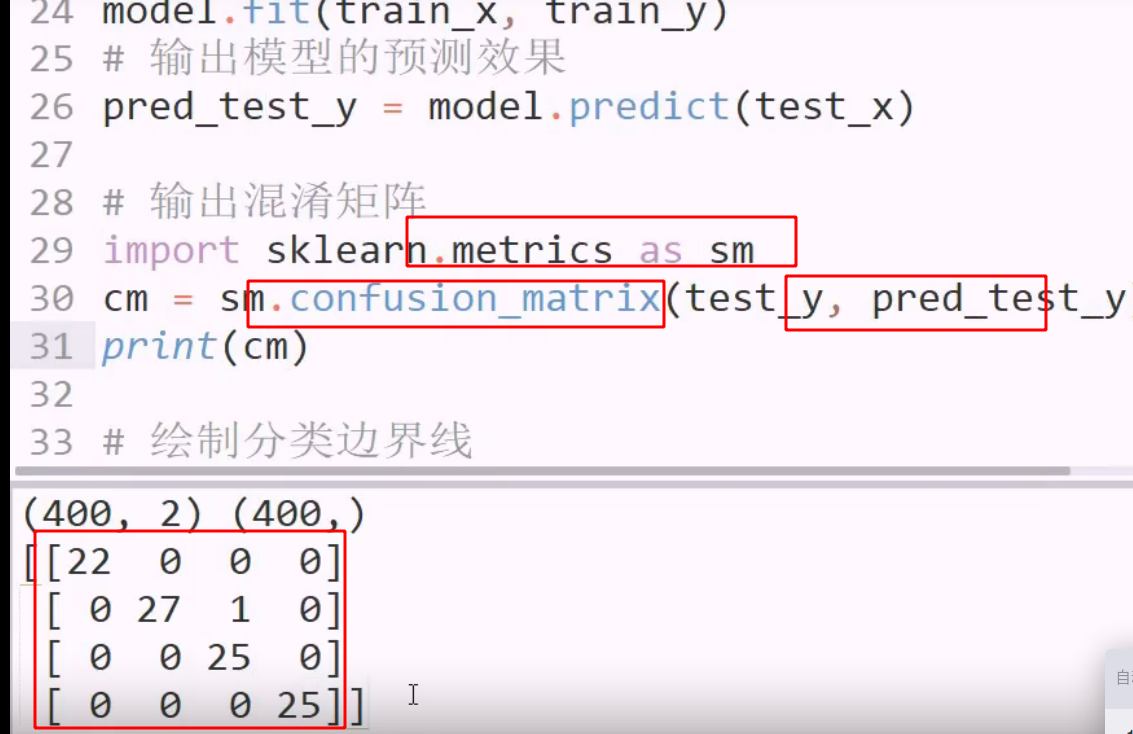
 优秀的矩阵
优秀的矩阵
可视化: 噪点少,对角线发白,其他发黑,则是好的
分类报告 直观的评估结果 方便分析


 supprot 是实际样本
supprot 是实际样本
交叉验证在模型之前做,看得分,评估这个样本是不适合,再用大量样本
决策树 分类 决策树可回归可分类
 每个特征的形态种类都不同
每个特征的形态种类都不同
最终标签有四种
通过前6 列 预测第七列
当前所有x 都是字符串,所有模型都不能用
由于是分类业务,对字符串进行标签编码,忽略其具体含义即可
7列,因此需要找7个标签编码器,一列一个编码器,做完后不要扔掉编码器,因为还要解析回到原有信息
读取每一行,在数组中,转制后,每列是一个样本

使用随机森林分类器
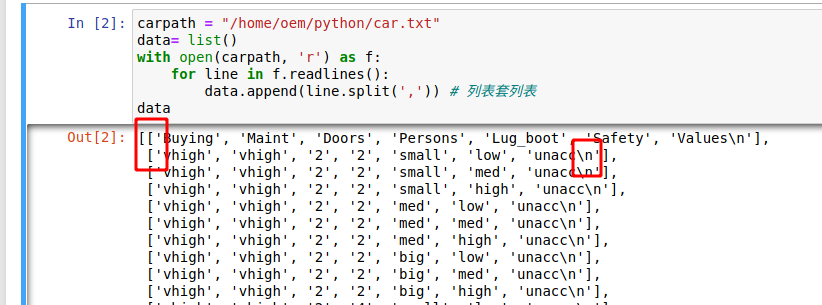
读取,构建二维列表,每行字符串按逗号 拆分
import sklearn.preprocessing as sp # 预处理模块 标签编码
import sklearn.ensemble as se # 随机森林
import sklearn.model_selection as sm # 交叉验证 由于这些属性都是站array 才有的,因此可以检测是否是array
由于这些属性都是站array 才有的,因此可以检测是否是array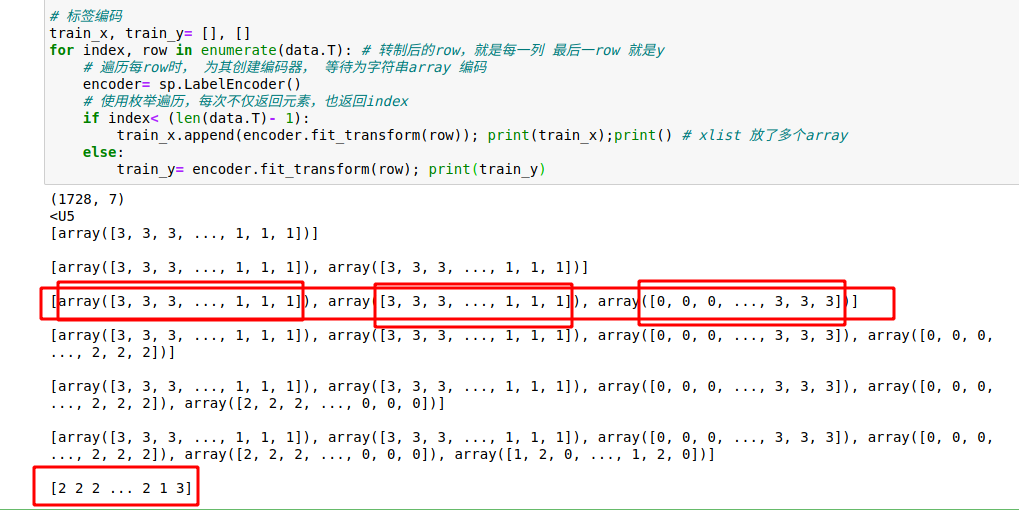 为每个字row array 的元素编码,再加入list
为每个字row array 的元素编码,再加入list
train_x, train_y= [], []
for index, row in enumerate(data.T): # 转制后的row,就是每一列 最后一row 就是y
# 遍历每row时, 为其创建编码器, 等待为字符串array 编码
encoder= sp.LabelEncoder()
# 使用枚举遍历,每次不仅返回元素,也返回index
if index< (len(data.T)- 1):
train_x.append(encoder.fit_transform(row)); print(train_x);print() # xlist 放了多个array
else:
train_y.append(encoder.fit_transform(row)); print(train_y); # print(train_y.dtype) 列表没有dtype
train_y= encoder.fit_transform(row); print(train_y); print(train_y.dtype) 重定向,y指向了数组,有了dtype
转换后,x 二维数组, y 一维数组 330021 才是一个记录的各个特征
330021 才是一个记录的各个特征
随机森林
model= se.RandomForestClassifier(max_depth=6, n_estimators=200, random_state=7)
层数/树数/随机种子

0.75 不好,该样本集不太适合做模型 需要调参优化
但当前认为适合

编码器 encoder fit 输入, transform 转换,实现将数组输入并编码为新数组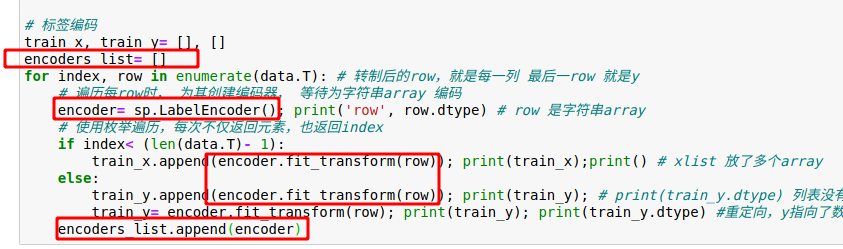 用列表存储 所有列的标签编码器,用于为训练集编码
用列表存储 所有列的标签编码器,用于为训练集编码
逆编码器 用最后一个encoder inverse即可
思路有,但实现又是另一回事
玩的就是操作数据结构,用api对其变化
one hot 只认数字,不认字符串,因此编码后可以再用one hot编码后进行逻辑回归
验证曲线

调参前后,模型好坏
只能调整参数后,对新模型一个一个测试,计较他们的f1得分
在训练之前进行,选出最好的超参数
 10× 5 每个都是测试集得分
10× 5 每个都是测试集得分
调参现状: 花很大力气,最后没啥反映
一个参数调好后,再调另一个: 片面,有排列组合情况很多没考虑到
学习曲线

定下来: 用多大的训练集 不是测试集
开头下划线的含义: 拆包其实拿到一个元组三个元素,第一个不想要,用下划线敷衍
与验证曲线一样
年龄不能标签,不是离散的,大部分数值都不行
但凡是字符串,都要标签化

若有收获,就点个赞吧
0 人点赞
