难度最大,最坑的一个方向
尤其是中文,最坑,极端情况过多
我们要做的是分析语义
 分句子的和分词汇的API
分句子的和分词汇的API
特殊的分词api:与标点相关的分词器 punct
当前分词效果: 大写作为新词,单复数,时态都是新词
统一形式: 词干提取,词性还原
 kankan 三种提取器的效果
kankan 三种提取器的效果 相当于对单词实现了归一化
相当于对单词实现了归一化
中文麻烦在分词,不在归一
 用单词列表才能构建分类模型
用单词列表才能构建分类模型
构建模型: 词袋模型

中文也有 词袋模型


输出 的是稀疏矩阵 只有这些位置不是0
因为可能出现的词很多,但每个句子的词很少 将稀疏矩阵 转为 二维数组形式
将稀疏矩阵 转为 二维数组形式
因为本案例涉及词库很小,看起来不稀疏
 展示词库
展示词库
如何用 词袋模型 建模,得到想要输出的y
特征的贡献度: 词频削弱了冠词的贡献
词频削弱了冠词的贡献
每行归一化,即可得到词频
文档频率: 考虑文档之间(句子之间) 的联系
代表影响程度低,因为过于宽泛,无法区分文档
最终用逆文档 和词频一起表达: 对the等数量大的,削弱其

自动根据词袋模型,构建tdf模型
拿到的tdf是稀疏矩阵,转为二维矩阵(toarray)
 非常好反映了贡献 从而进一步构建有监督模型
非常好反映了贡献 从而进一步构建有监督模型 文当频率 2/3
文当频率 2/3
tdf 无法统计前后单词的连续性,只能用深度学习解决 五个领域的样本,每个都是上百个邮件
五个领域的样本,每个都是上百个邮件
共计几千个,作为样本
当前业务: 给新的邮件,区分邮件类别
类别编码作为输出,是分类业务
tdf 本质是提供了一种将字符串量化参与计算的方法
主题识别 案例 接上
 skl 提供的新api 更加直接
skl 提供的新api 更加直接
shuffle 打乱 但凡手动打乱,都要随机种子
看一下train: 列表没有shape
列表没有shape  全部混杂了
全部混杂了
构建tdf 矩阵: 对每个x 样本拆分: 要得就是多个样本构成的矩阵
要得就是多个样本构成的矩阵
构成词袋模型 bow
得到这tdf 模型 即将字符串数组 数值化
tdf 有了就可以拆 测试集 训练集
样本很大时效果很好

只有分词,没有语义,一旦出现否定,则效果很差
主题分类只是涉及名词,动作,没有情感

封装的更好,但train data 结构不同: 字典做样x,元组做样本,列表整个是输入集
情感分析 案例
与主题识别类似,都是每个类别下有上千样本
nltk 也有自己读取文件夹的方法: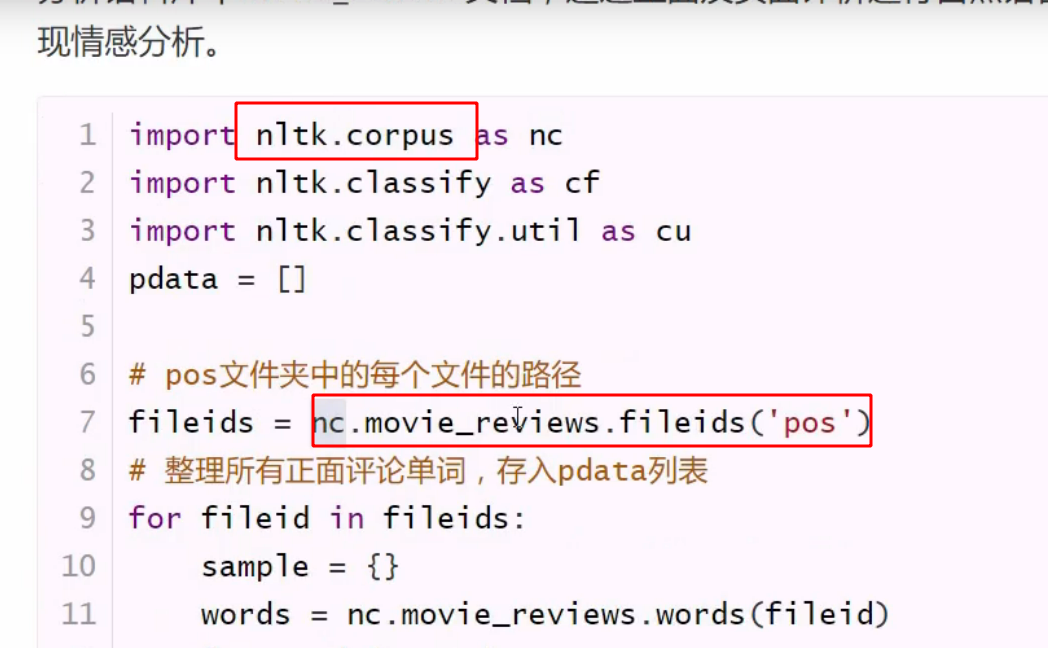

若有收获,就点个赞吧
0 人点赞
