数据分析 文件加载 股票案例
数据分析就是从金融领域来的
读样本: 数据库,文件,图片信息,音频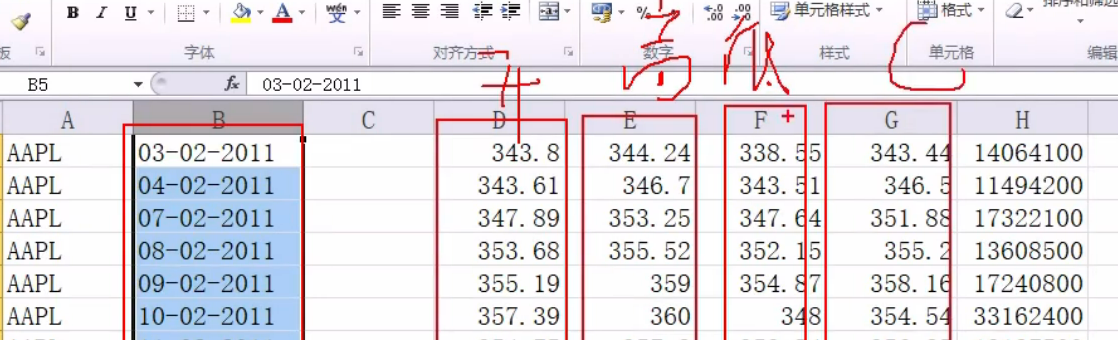 苹果股价
苹果股价
看开盘收盘 看涨跌
csv: 逗号分隔符文件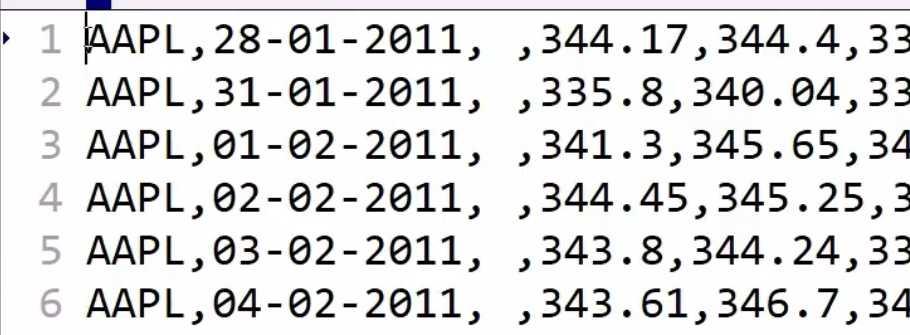
,:; 都能被 numpy 解释为二位数组
如果拆开返回,就要多个变量接受 不拆就好了
晚上多侧api 默认按空格拆分
默认按空格拆分
默认转为 float
我们选择性读入 可转 float 类型
对于日期,修改dtype
日开高低收 UFFFF 列不够接受
列不够接受
U10 是字符串,不能作为横轴
改为M8,即日期类型,是数值类型
numpy 只能识别年月日, 月日年 不可
 将第一列传给 dmy函数,转后,再M8成为日期类型
将第一列传给 dmy函数,转后,再M8成为日期类型 返回字符串
返回字符串
python 日期类型做的很垃圾
15000: 1970 年至今,经过的天数
改为周一为主刻度,其他每天为次刻度
api 多到讲不完
使用 matplot 自己的日期定位器 主定位使用周定位器,并且为周一 md.MO
设置主刻度模式 formatter: 日期展示
库多到学不完,学到哪记到哪,知道谁能解决即可
读取时用numpy 的日期,显示用matplot 日期很烦
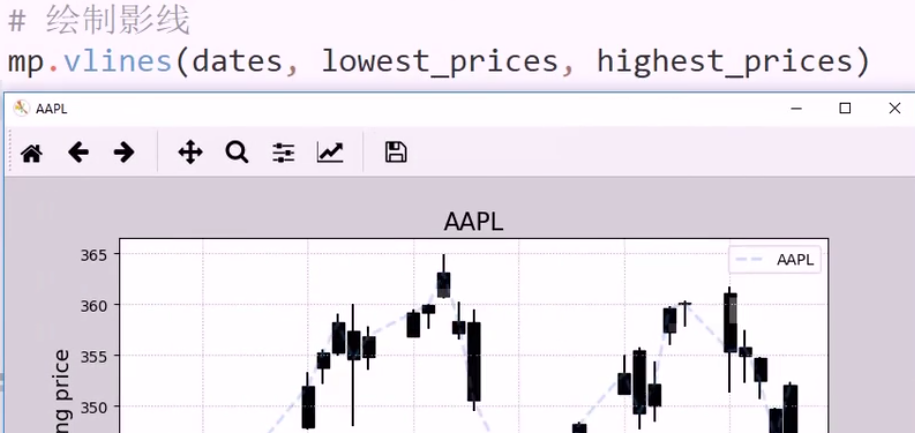
K 线

关注蜡烛图: 小柱子
一个蜡烛是一天的交易信息 开高低收 A 股 红色为阳,绿色为阴
A 股 红色为阳,绿色为阴
蜡烛体: 实体 蜡烛线: 影线
涨了,收盘价就是最高价,则全天一直在涨,称为光头阳线
红色十字线: 全天震荡剧烈,但最后开盘等于收盘,闹着玩(但也在涨
连续几天十字线,但逐渐走高: 涨停
第二天开盘比前一天收盘高了很多,但第二天却没涨
只有中国有这个涨停跌停机制,不让大涨大跌
有想卖的心理,则涨停,开始跌

柱子长度 闭盘-开盘, 起始位置 开盘 宽度 0.8 这里涉及到了数组减法
根据涨跌 添加颜色 if判断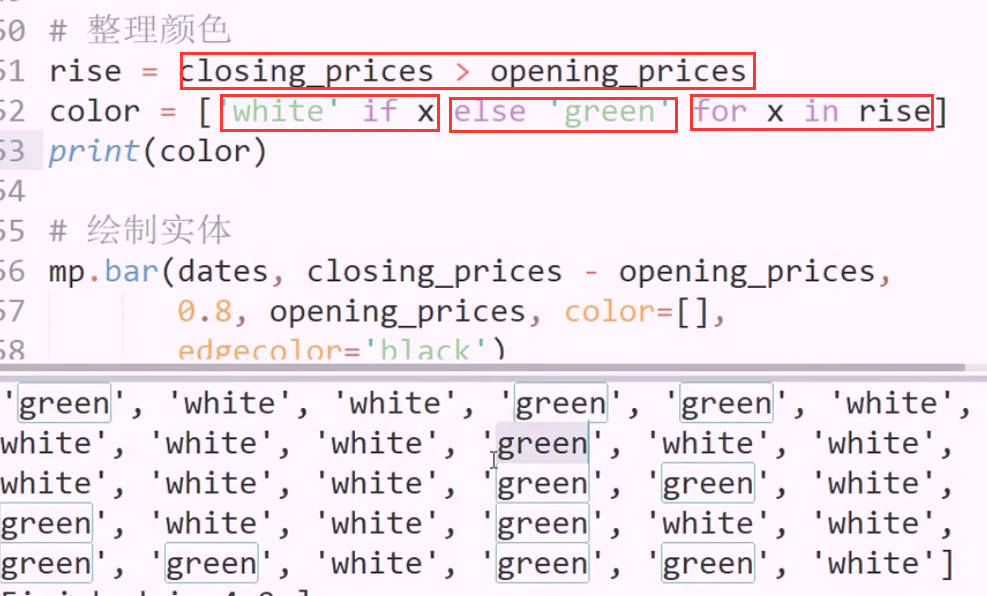
返回 rise 布尔数组,用列表推导式,将true false 映射为 white green(字符串)
另一种映射方法:
先根据 boolean 数组构建等大小的字符串数组
dtype=”U5”表示字符串不超过5位 先全部置为 green
先全部置为 green
利用掩码,目前 color 数组全是 true, 与rise 数组相与,得到新的boolean数组,将true 位置改为 white即可

同样,列表推导得到 边缘颜色数组 也是映射
修改图层,让bar 覆盖 vlines: 随便设一个值

股市量化的统计量 五六种指标预测得到五六种结果,如何综合
均值 股票的真实价值
 两种求mean 的方法
两种求mean 的方法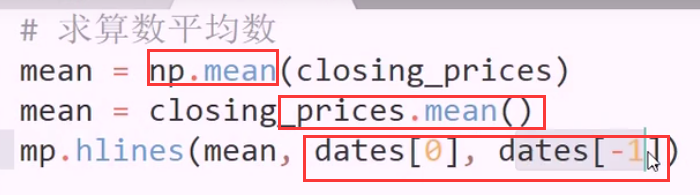 从第一天划到最后一天
从第一天划到最后一天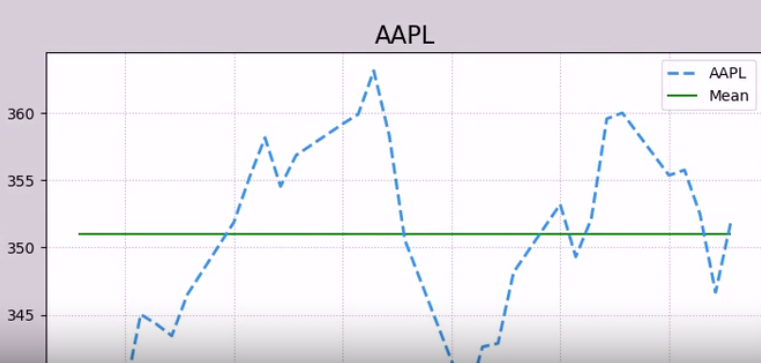
均值只能对公司股价估值,不能做走势预测
除非当前股价偏离均值很多,可能会反向走
加权均值 机器学习

用当天成交量作为权重 双方达成买卖共识

 时间权重
时间权重
权重大小,根据业务经验选定,或深度学习生成
最值


arg 开头的函数,都是返回索引 反推日期

 保留对应位置的大者
保留对应位置的大者
方差标准差
 用总体的,还是样本的, 根据业务,统一使用即可,无需纠结,甚至灵活调整分母,得到调大调小的
用总体的,还是样本的, 根据业务,统一使用即可,无需纠结,甚至灵活调整分母,得到调大调小的
时间处理 和 数组轴向汇总
对二维数组的横向汇总和纵向汇总
量化指标——移动均线

实现了震荡的平滑处理,更能反应变化
短期移动均线: 5日
长期移动均线: 40日
短期均线反应迅速
可以看到 5日均线 更能反映股市上升的趋势
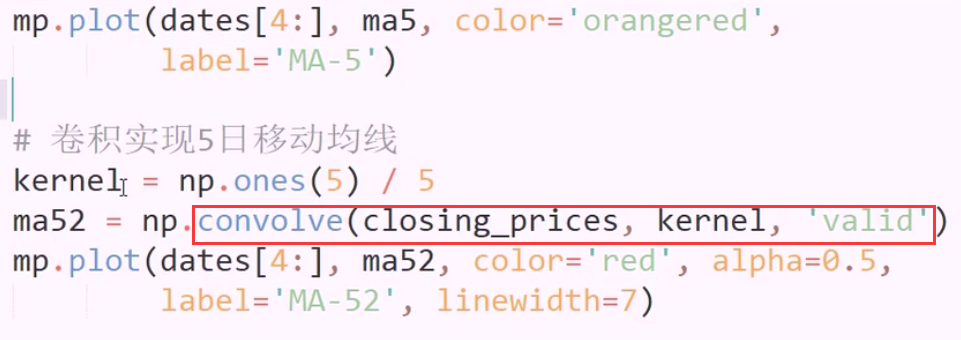
卷积 与 均线 计算原理相同 滑动窗口
卷积的运算规则,适用于什么场景
完全卷积: 只要卷积核中有一个元素被卷到就生效
同维卷积: 只有卷积核被卷到就生效
有效卷积: 卷积核全被卷到才生效
痛感累加模型:
如果第二天痛感完全消失,那么每天挨巴掌数目和痛感应该是正比的 可以直接预测
实际受历史痛感叠加影响
卷积核反映了叠加(激励) 根据当前激励算到一些残留函数的影响,叠加到当前关注的变量上


加权卷积下的五日均线




整体左移,即预测时间提前 
二维卷积
指标——布林带



 填充lower 小于 upper 之间
填充lower 小于 upper 之间
带宽收窄,标准差小,建议卖,因为马上要跌了
先在上轨和中轨之间,再到中轨和下轨之间,穿过中轨线,则要卖出
贷宽放大,标准差大
向上穿过中轨线,则建议买入
这个图震荡良好,稳步上升,稳步下跌
线性模型
用前六天的收盘价,推第七天

解矩阵的方法 底层是梯度下降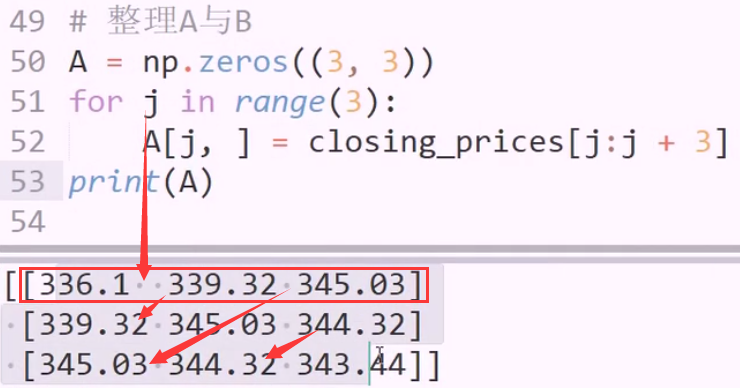
快速创建数组,逐行赋值,使用切片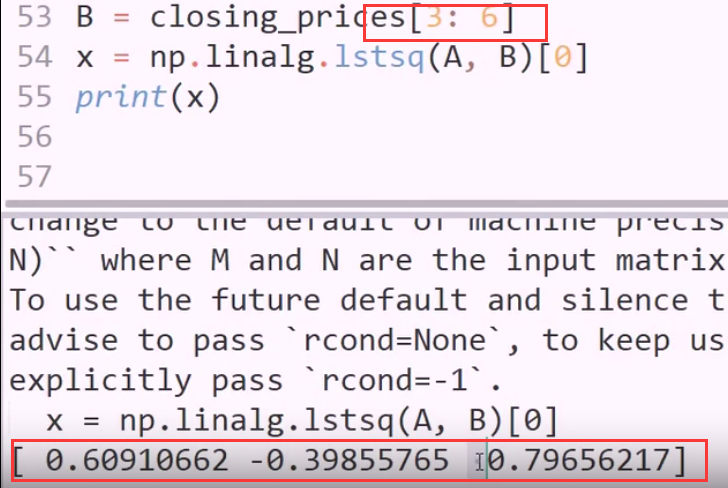
 预测结果
预测结果
递推预测 接着向后预测,看看与实际最后偏离多少

线性拟合 对一组散点 迭代求解 线性回归

linalg函数的强大之处 自动拟合
我们要提供 xy 两个矩阵(AB)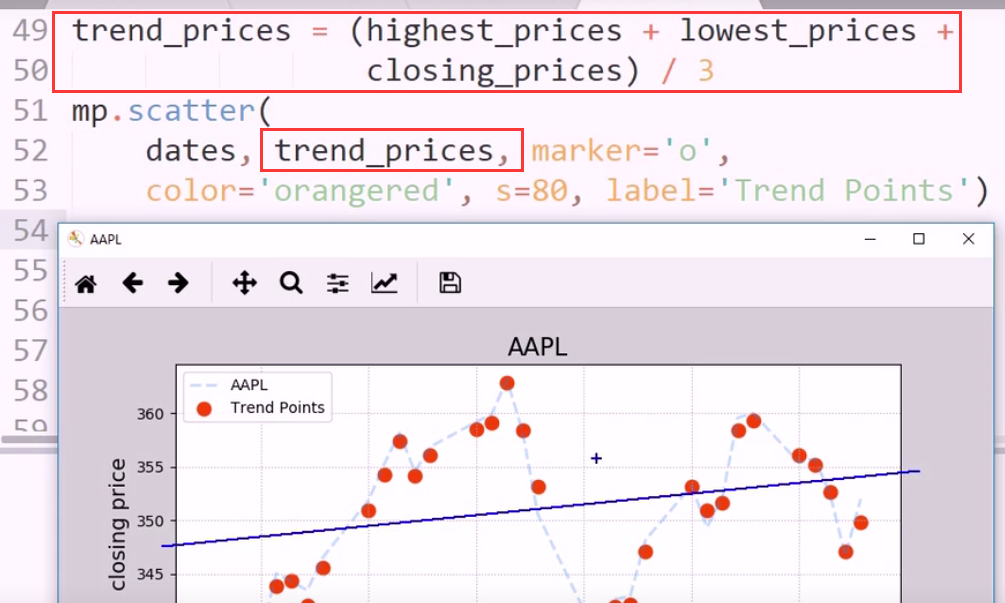
仍然是数组运算
训练时,日期作为 x数组元素,要转化为可迭代的:
从matplot 画图用的date。date 类型,转为matplot和numpy 都能识别的M8D,再转为numpy可迭代的int

按列合并方法: 创建一列x 一列1
这就是个大计算器
协方差/相关矩阵/相关系数
推荐系统 两组数据相似程度
两组数据的离差数组,做乘积
数组乘积,对应相乘即可
方差也是数组乘积,但一定每个元素都是正,不能抵消
对数组乘积求均值得到协方差
相关性强弱,0则不相关,只有随机性
两只股票的相关性: 板块股票 两个相关行业的相互影响 一起涨
读入两只股票部分属性的数据:
默认就是按 f8 读取,因此可以不写 注意 usecols 写成元组
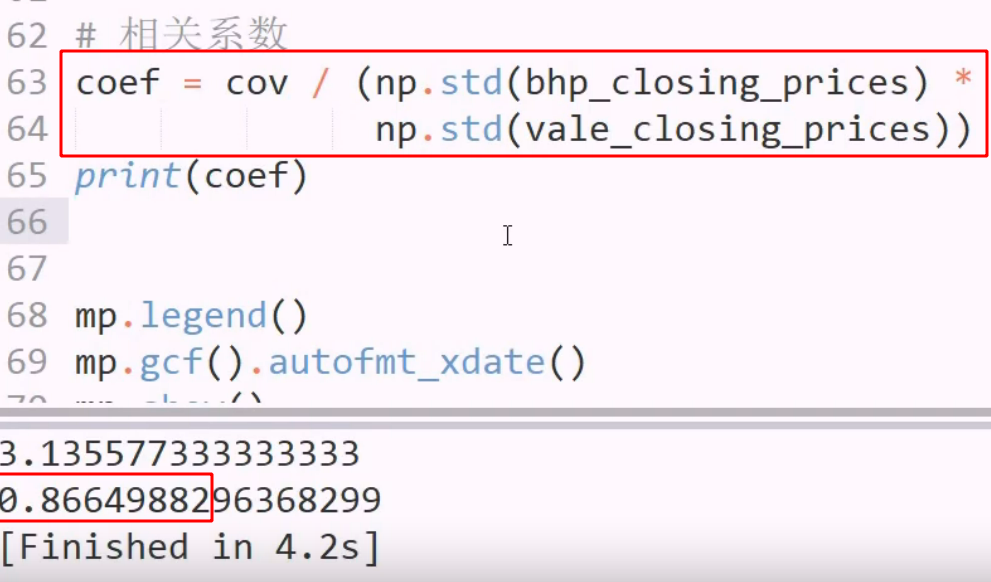
计算两只股票的协防差

正数: 正相关 3.135 是大是小?
看看没有抵消的情况: 用标准差衡量,因此二者相除,看比例即可,即相关系数
相关系数 相关矩阵

相关矩阵: 无需手动计算
 AA AB BA BB 各自的相关系数
AA AB BA BB 各自的相关系数
输入两个数组,评价其 相关性
方差和标准差计算经常不同,因为我们使用了总体的标准差,而np使用的是样本的,分母小,得到的大
相似性使用场景
推荐系统
相似用户,如何量化 用特征向量描述,计算特征向量之间的相关系数
电影之间的相似度
广告的相似度
多项式拟合 从线性到高阶
某些样本空间,线性误差过大 梯度下降
梯度下降
numpy 表示多项式: 数组记录系数
 必须规定最高次数
必须规定最高次数
拿到多项式
两个多项式相减,返回新多项式
 匹配当前样本数据
匹配当前样本数据
次数太高,则过拟合
不能去区间之外预测,因为不会拐弯了
数据平滑/降噪

 政策,信心等,都是噪声
政策,信心等,都是噪声
使用卷积 将噪声降到最低,光滑 有导数
拿到数据先降噪,各行各业都如此
np 提供的 diff 函数,可以逐个后项减去前项 总长度 减一 收益率
收益率
何时转换投资方向? 不能看到尖刺超过就改,能把人累死
要平滑后,再找交点
卷积降噪: 找一个核,对序列卷积 convolve 免费汉宁卷积核
免费汉宁卷积核
卷积核归一:
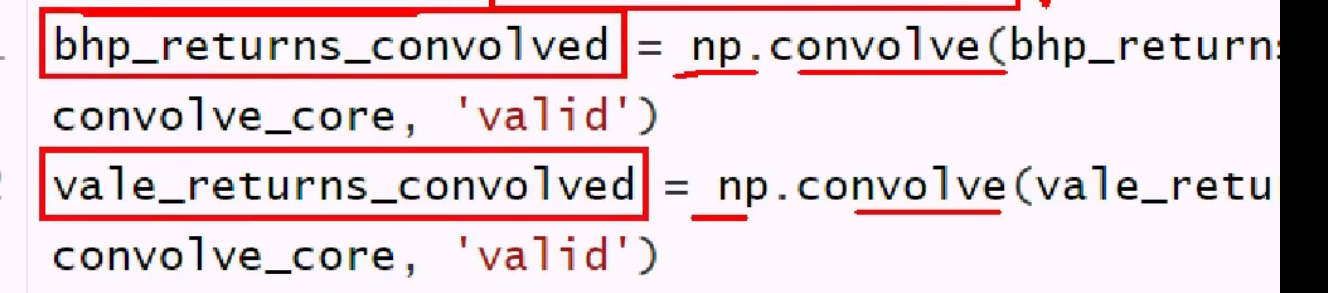 使用有效卷积模式 去掉7个
使用有效卷积模式 去掉7个 绘图
绘图 交叉明显减少了
交叉明显减少了
拿到交叉点:映射到日期
交叉点求法: 拟合两条曲线即可
 无法一步到位转换日期 必须M8D
无法一步到位转换日期 必须M8D
求交点: 差函数求根
符号数组 提取符号 映射到另一个数组
两个 api 与一个量化指标

猪肉25 国家说明天会降价,则今天没人买了。第二天期望跌停,买方挂牌22。5 (10%) 有人卖则是真的跌停
第二天还能再跌停,引起大卖,卖不出去的第二天还会真的跌停
跌到顶不住了国家队进场,强行抬起股价,连续几天涨价
分析红酒,指标不了解,但看得多了总有规律, 找到自己熟悉的行业
股民对股价的评论不一致,才会有买卖,否则都认为该买,则无成交
土豆涨价,买土豆的少了,则土豆会降回来
反之,买盘强力,则股价回升
增长过快,则尽快卖出
写if else
不知道业务,则无法分析,进入医疗领域,五六十个特征,你不懂就要找专业人士讲给你
OBV
涨了就大于零
数组处理函数
`
 作用是映射
作用是映射
矢量化
数组之间运算 用数组代替标量 函数的返回值是新的函数,这是函数式编程
函数的返回值是新的函数,这是函数式编程
批量运算,无需for循环
numpy 自己的函数,肯定都是矢量化了的,我们要对自己的函数矢量化
也可以匿名使用
06 年流行过函数编程,java也流行过,但不宜读,现在没有人喜欢用
数组维度不同的情况: 只有当有一个一维时,可以不匹配,正如我们用过的给点上色
矢量化案例
 无脑策略 只要开盘价跌1%,就买,且按当天收盘价卖出
无脑策略 只要开盘价跌1%,就买,且按当天收盘价卖出 对其矢量化,可以传入数组
对其矢量化,可以传入数组
代码少,因为封装好
报出买价 buying price
numpy 不允许连续比大小
根据 nan出现位置,构造boolean数组 nan 为true 使用掩码,dates 数组中指出 bolean 位置的元素,返回得到新的数组
使用掩码,dates 数组中指出 bolean 位置的元素,返回得到新的数组
 赔了 而且还赔了手续
赔了 而且还赔了手续
矩阵 系统普及 api 过于重要
matrix 类专用于表示矩阵,但ndarray 可以做到大部分需求 是继承关系

不复制,则就是视图

 必须是二维,因此要 reshape
必须是二维,因此要 reshape
矩阵运算
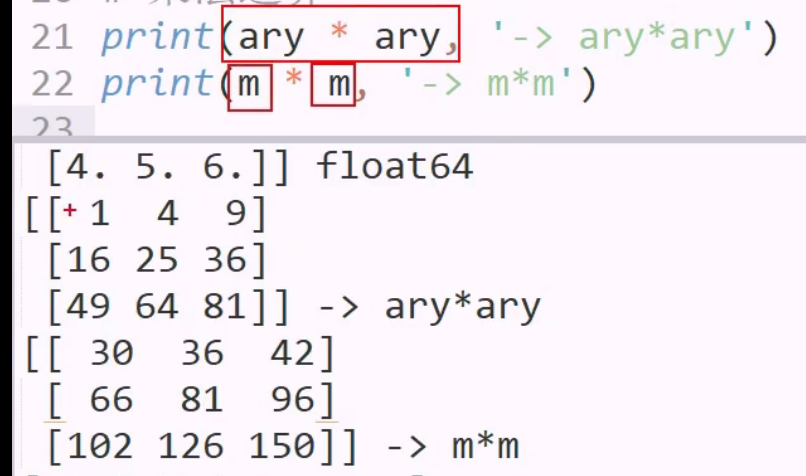 矩阵 数组 乘法
矩阵 数组 乘法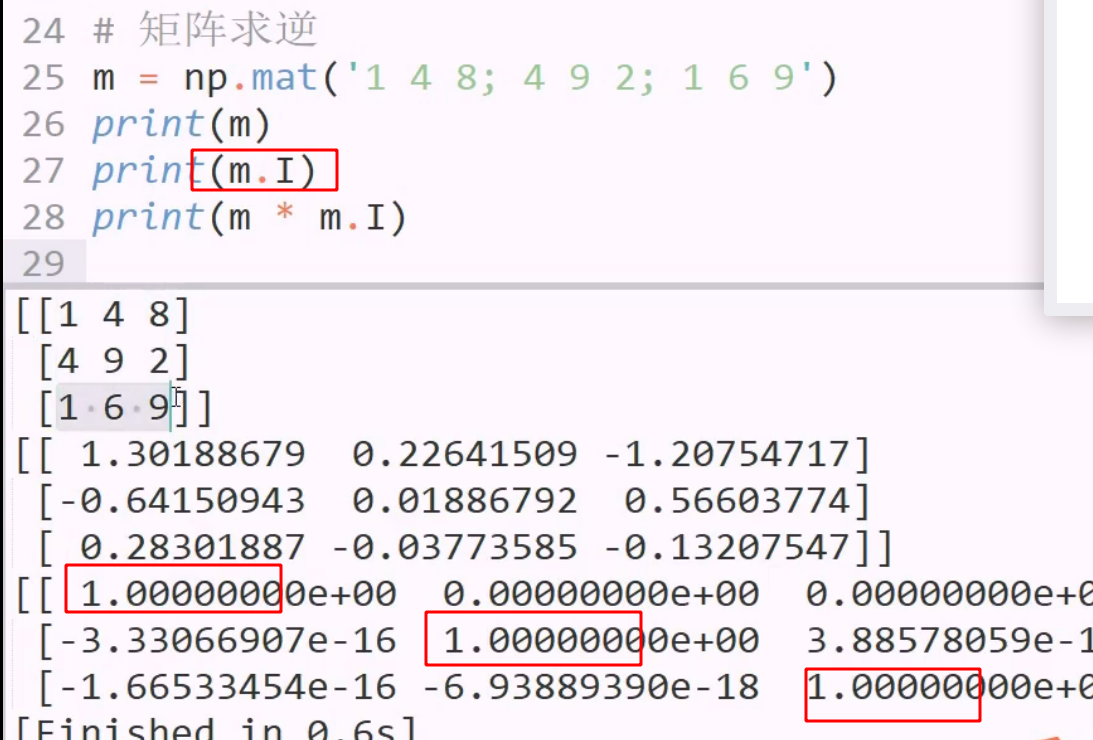
 前两行 的所有列 这里是二维切片
前两行 的所有列 这里是二维切片
只要涉及算法的设计才用到
通用函数 稀奇古怪的常见 api

调整数组中的元素界限 对像素进行裁剪 卷积时容易超过最大最小值

使用了掩码
两种clip: 一个numpy 的函数,一个数组的方法
很常见的情况,都是一一对应 np的更加普适,列表也客串进入
裁剪: 矢量化运算,相当于布尔运算,只保留true 效率极高
如果a 是标量,在python中确实可以这么写,但现在a是矢量(数组) 数组没有连比较重写
因此提示 用 any all 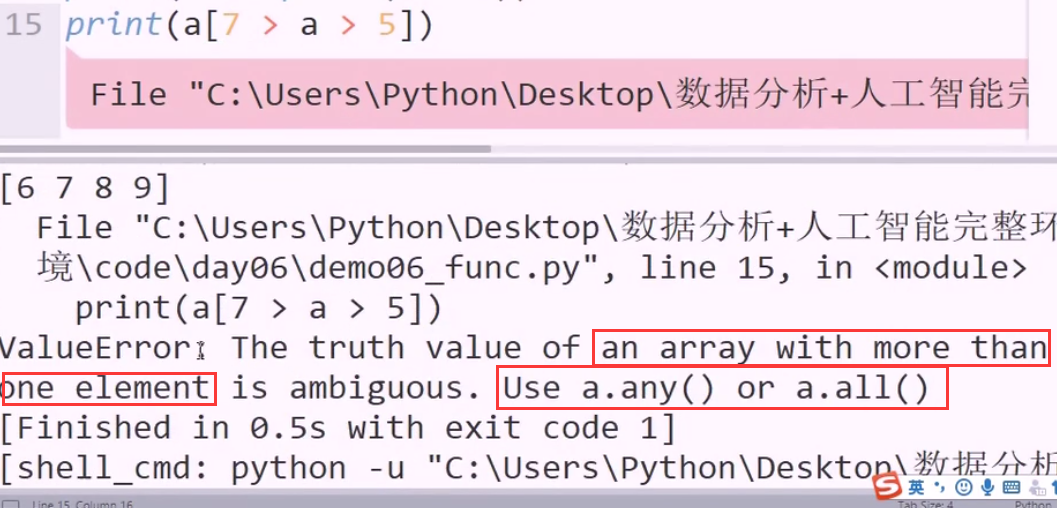
查阅api 文档:

 纵向比较
纵向比较
给两个Boolean数组,让我们的数组与他们纵向比较,即可得到 两边夹的不等式 all
将 a > 3 和 a < 7 的两个布尔数组,叠成一个二维数组,并按列做交运算 实现掩码效果


过程数组可以防止为了取到中间某个值,而反复累加累积
外和/外积:

除法通用函数 取整方法
只有 DML 语句才有事务,可以回滚 , trunc 是DDL 语句,直接截断整张表,无法回滚

round: 四舍五入

若有收获,就点个赞吧
0 人点赞
