按结构总结
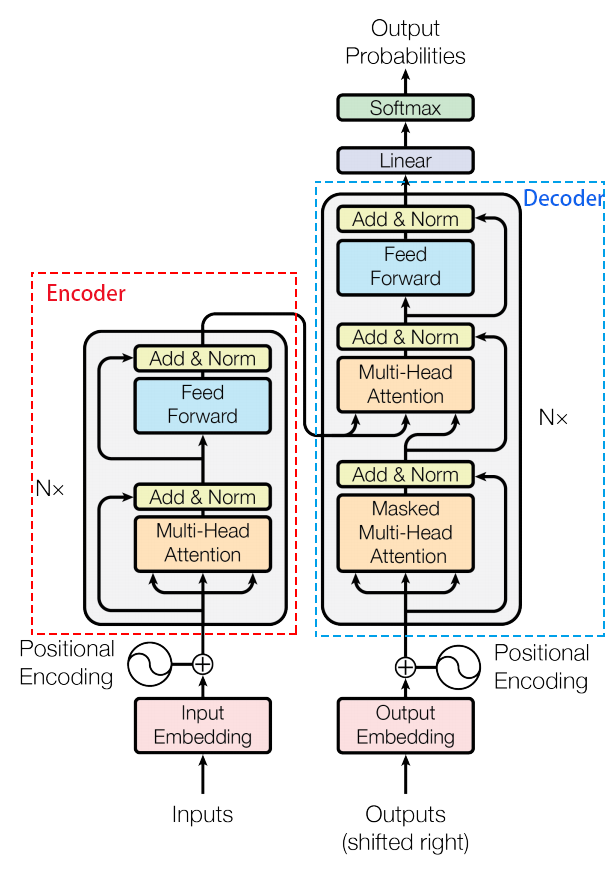
一、Encoder
- embedding层
单词的embedding等于embedding + positional encoding,positional encoding与embedding的维度相同,其中pos是指当前词在句子中的位置,i是指向量中每个值的index。在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。计算方法是: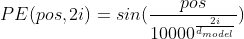
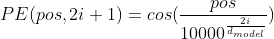
- self-attention层
输入的embedding和三个随机初始化的矩阵相乘映射为维度相同的Q,K, V,然后使用self-attention公式计算,这三个矩阵在BP过程中会一直更新。
multi-head attention是初始化多组Q、K、V的矩阵,tranformer最后得到的结果是8个矩阵,拼接后再映射到输出维度。
- 残差模块和Layer normalization
残差模块X + self-attention(X),即X经过self-attention后的结果再加上输入X,目的是为了反向传播时不会梯度消失,防止网络退化。Normalization的目的是把输入转化成均值为0方差为1的数据。我们在把数据送入激活函数之前进行norm,可以使输入数据落不在激活函数没有梯度的区域。Layer norm是在同一个数据的不同维度上进行归一化。
- Feed forward neural network
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下。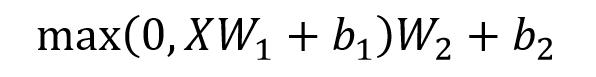
- 残差模块和Layer normalization
残差模块X + ffn(X),即X经过ffn后的结果再加上输入X。
二、Decoder
- masked mutil-head attetion
- padding mask(所有的 scaled dot-product attention 里面都需要用到):给在较短的序列后面填充 0,截取较长序列。给这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0。
- sequence mask(只在decoder中用到):sequence mask 是为了使得 decoder 不能看见未来的信息。一个序列的解码输出,在time_step为t的时刻应该只能依赖于t时刻之前的输出,而不能依赖t之后的输出。因此需要产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
Decoder的self-attention使用到的scaled dot-product attention,需要将两种mask相加作为attn_mask。其他情况,attn_mask一律等于padding mask。
- encoder-decoder multi-head attention
- 输入:encoder的输出 & 对应i-1位置decoder的输出。
- 输出:对应i位置的输出词的概率分布
所以中间的attention不是self-attention,它的K,V来自encoder,Q来自上一位置decoder的输出。
- 解码:这里要注意一下,训练和预测是不一样的。在训练时,解码是一次全部decode出来,用上一步的ground truth来预测(mask矩阵也会改动,让解码时看不到未来的token);而预测时,因为没有ground truth了,需要一个个预测。
- 一个全连接层和softmax层
假如我们的词典是1w个词,那最终softmax会输入1w个词的概率,概率值最大的对应的词就是我们最终的结果。解码阶段的每个步骤都会输出一个输出序列的元素,每个步骤的输出在下一个时间步被提供给底端解码器,接下来的步骤重复了这个过程,直到输出一个终止符号。
知识点
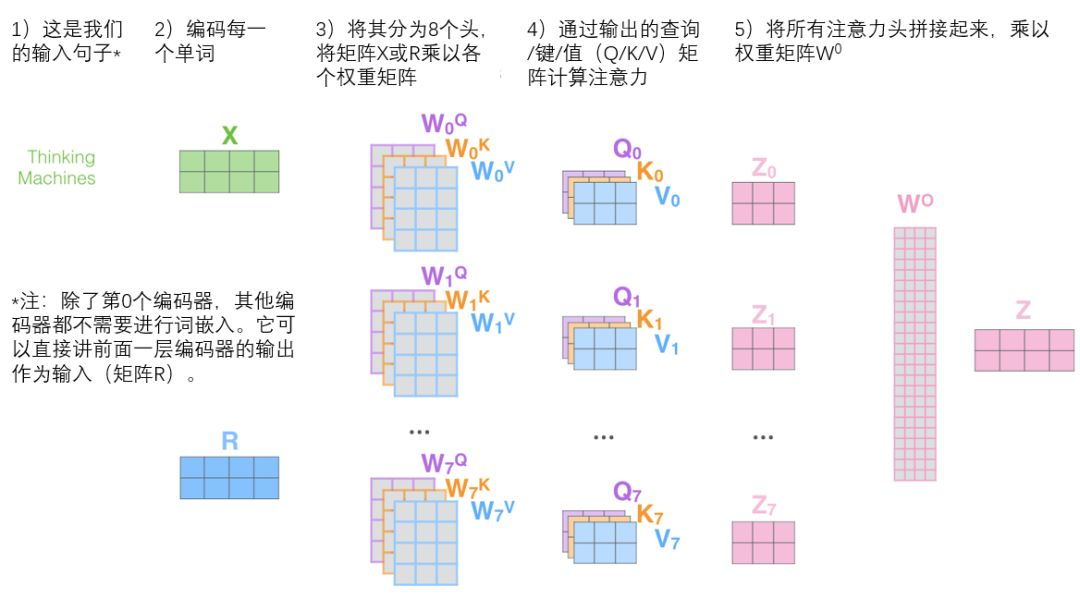
- multi-head attention的不同点及过程:
- 扩展了模型专注不同位置的能力
- 给出了注意力层的多个表示子空间
- 位置编码
- 位置编码的形状与隐状态相同
- 位置编码在-1到1之间,由sin,cos函数计算得出,是不可学习的向量(BERT中是可学习向量)
- attention公式除以根号d:attention值与维度大小成正比,除以根号d使经过softmax计算后的值更稳定
- transformer解码器的输出:每一步输出一个词表大小的分布,选择概率最大的一个词作为这一步的输出,直到输出特定标记结束。
- Transformer为什么需要进行Multi-head Attention?
将计算结果映射到不同的子空间,使模型关注到不同方面的信息,最后再综合起来。
- 残差连接:
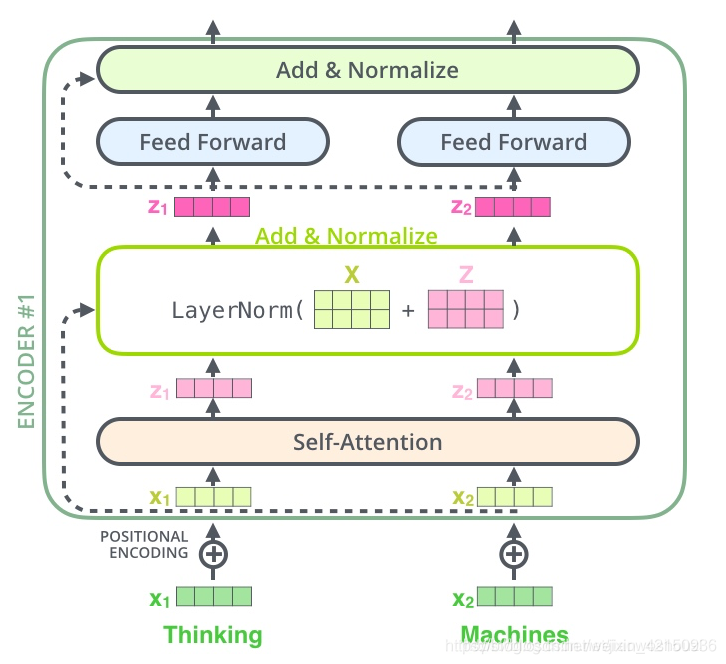
在编码器的self-attention和前馈神经网络后分别都有,目的是(1)防止梯度消失。(2)解决深度学习网络的退化问题。(退化问题是指,当模型对不同的输入均给出同样的输出)
也就是Attention(Q,K,V), 对它进行转置(图中的Z),使其和X_embedding的维度一致,然后把它们加起来做残差连接,直接进行元素相加。
- LayerNorm。目的是加速模型的收敛。用每一行的每一个元素减去这行的均值,再除以这行的标准差,从而得到归一化以后的数值。
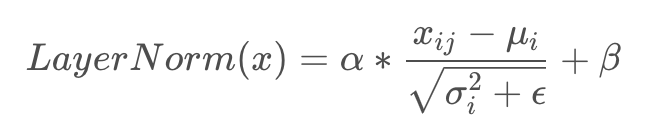
- Transformer相比于RNN/LSTM,有什么优势?
(1)并行计算的能力。RNN系列的模型,并行计算能力很差,因为 T 时刻的计算依赖 T-1 时刻的隐层计算结果,而 T-1 时刻的计算依赖 T-2 时刻的隐层计算结果,如此下去就形成了序列依赖关系。
(2)特征提取能力更好。
- Transformer的并行化提现在哪里?
训练时一个 batch 的句子是一起生成的,而且每个句子的每个词也是一起生成的。encoder是并行的,训练的时候decoder也是并行的,但是inference的时候不是,因为你没有golden label,只能一个一个产生,所以decoder端跟RNN一样还是自回归的。
- self-attention时间复杂度:O(n2*d)
Self-Attention时间复杂度:  ,这里,n是序列的长度,d是embedding的维度。
,这里,n是序列的长度,d是embedding的维度。
Self-Attention包括三个步骤:相似度计算,softmax和加权平均,它们分别的时间复杂度是:
相似度计算可以看作大小为(n,d)和(d,n)的两个矩阵相乘:  ,得到一个(n,n)的矩阵。
,得到一个(n,n)的矩阵。
softmax就是直接计算了,时间复杂度为 
加权平均可以看作大小为(n,n)和(n,d)的两个矩阵相乘:  ,得到一个(n,d)的矩阵
,得到一个(n,d)的矩阵
因此,Self-Attention的时间复杂度是  。
。

若有收获,就点个赞吧
0 人点赞
