推荐系统流程及相应算法
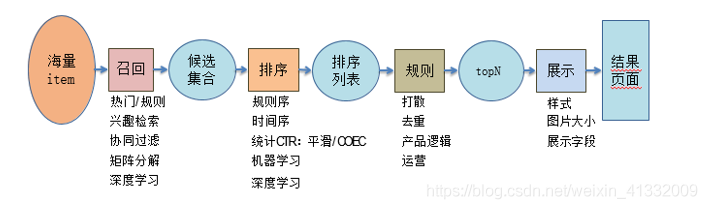
工业推荐系统,经常讲的有两个阶段。召回强调快,排序强调准。
- 召回,主要根据用户部分特征,从海量的物品库里,快速找回用户潜在感兴趣的那一小部分物品,然后交给排序环节。
- 排序环节可以融入较多特征,使用复杂模型,来精准地做个性化推荐。
细分可分为四个阶段。
- 召回。
- 粗排:有时候因为每个用户召回环节返回的物品数量还是太多,怕排序环节速度跟不上,所以可以在召回和精排之间加入一个粗排环节,通过少量用户和物品特征、简单模型,来对召回的结果进行个粗略的排序,在保证一定精准的前提下,进一步减少往后传送的物品数量,粗排往往是可选的,可用可不同,跟场景有关。
- 精排:使用你能想到的任何特征,可以上你能承受速度极限的复杂模型,尽量精准地对物品进行个性化排序。
- 重排:传统地看,这里往往会上各种技术及业务策略,比如去已读、去重、打散、多样性保证、固定类型物品插入等等,主要是技术产品策略主导或者为了改进用户体验。
召回
常用模型:FM, DNN
- 多路召回

把某个召回路看作是:单特征模型排序的排序结果。某路召回是某个排序模型的排序结果,这个排序模型,在用户侧和物品侧只用了一个特征。比如说,标签召回,其实就是用用户兴趣标签和物品标签进行排序的单特征排序结果;再比如协同召回,可以看成是只包含UID和ItemID的两个特征的排序结果。
- 用户行为序列召回
用户行为包括,比如点击一些感兴趣的物品,收藏或者互动行为,或者是购买商品等。输入是用户行为过的物品序列,可以只用物品ID表征,也可以融入物品的content Information比如名称,描述,图片等,现在我们需要一个函数Fun,这个函数以这些物品为输入,需要通过一定的方法把这些进行糅合到一个embedding里,而这个糅合好的embedding,就代表了用户兴趣。无论是在召回过程,还是排序过程,都可以融入用户行为序列。在召回阶段,我们可以用用户兴趣Embedding采取向量召回,而在排序阶段,这个embedding则可以作为用户侧的特征。
所以,核心在于:这个物品聚合函数Fun如何定义的问题。要注意的一点是:用户行为序列中的物品,是有时间顺序的。理论上,任何能够体现时序特点或特征局部性关联的模型,都比较适合应用在这里,典型的比如CNN、RNN、Transformer等,都比较适合用来集成用户行为序列信息。而目前的很多试验结果证明,GRU可能是聚合用户行为序列效果最好又比较简单的模型。[
](https://blog.csdn.net/weixin_41332009/article/details/113738132)
- 用户兴趣拆分
用户往往是多兴趣的,比如可能同时对娱乐、体育、收藏感兴趣。这些不同的兴趣也能从用户行为序列的物品构成上看出来,比如行为序列中大部分是娱乐类,一部分体育类,少部分收藏类等。需要把用户行为序列物品中不同类型的用户兴趣细分,而不是都笼统地打到一个用户兴趣Embedding里。用户多兴趣拆分就是解决这类更细致刻画用户兴趣的方向。
用户多兴趣拆分,依然是以用户行为序列物品作为输入,输出是多个用户兴趣embedding。但是在具体技术使用方向上却不太一样,对于单用户兴趣embedding来说,只需要考虑信息有效集成即可;而对于多用户兴趣拆分来说,需要多做些事情,本质上,把用户行为序列打到多个embedding上,实际它是个类似聚类的过程,就是把不同的Item,聚类到不同的兴趣类别里去。目前常用的拆分用户兴趣embedding的方法,主要是胶囊网络和Memory Network,但是理论上,很多类似聚类的方法应该都是有效的,所以完全可以在这块替换成你自己的能产生聚类效果的方法来做。
- 用户行为序列拆分到不同的embedding里的必要性:
反正不论怎样,即使是一个embedding,信息都已经包含到里面了,并未有什么信息损失问题呀?这个问题很好。我的个人感觉是:在召回阶段,把用户兴趣拆分成多个embedding是有直接价值和意义的,前面我们说过,召回阶段有时候容易碰到头部问题,就是比如通过用户兴趣embedding拉回来的物料,可能集中在头部优势领域中,造成弱势兴趣不太能体现出来的问题。而如果把用户兴趣进行拆分,每个兴趣embedding各自拉回部分相关的物料,则可以很大程度缓解召回的头部问题。
- 用户协同过滤
- 物品协同过滤
排序
基于ctr,即广告点击率,进行排序。在推荐系统中,通常是按照ctr来对召回的内容子集进行排序,然后再结合策略进行内容的分发。
- LR
优点:处理离散化特征,而且模型十分简单。
缺点:
- 特征与特征之间在模型中是独立的,对于一些存在交叉可能性的特征(比如: 衣服类型与性别,这两个特征交叉很有意义),需要进行大量的人工特征工程。
- 特征离散化过程中出现边界问题。
- GBDT
优点:
- 在于处理连续值特征,比如用户历史点击率,用户历史浏览次数等连续值特征。
- 由于树的分裂算法,它具有一定的组合特征的能力,模型的表达能力要比LR强。GBDT对特征的数值线性变化不敏感,它会按照目标函数,自动选择最优的分裂特征和该特征的最优分裂点,而且根据特征的分裂次数,还可以得到一个特征的重要性排序。所以,使用GBDT减少人工特征工程的工作量和进行特征筛选。
缺点:
- 连续特征离散化耗时较多
- 因为GBDT模型特点,它具有很强的记忆行为,不利于挖掘长尾特征
- 组合的能力十分有限,远不能与dnn相比
- Xgboost
- Wide & Deep Network
评价指标
AUC:ROC(receiver operating characteristic curve) 横轴FP率,纵轴TP率,ROC曲线越靠近左上角越好,越接近 y=x(模型分正例和分负例的概率相等,基本相当于没用) AUC越小。
优点:
- 同时考虑了分类器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器作出合理的评价。
例如在反欺诈场景,设欺诈类样本为正例,正例占比很少(假设0.1%),如果使用准确率评估,把所有的样本预测为负例,便可以获得99.9%的准确率。但是如果使用AUC,把所有样本预测为负例,TPRate和FPRate同时为0(没有Positive),与(0,0) (1,1)连接,得出AUC仅为0.5,成功规避了样本不均匀带来的问题。
- 关心样本间相对顺序
美团搜索
- 搜索的流程
- 在互联中发现、搜集网页信息;
- 对信息进行提取和组织建立索引库;
- 再由检索器根据用户输入的查询关字,在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将查询结果返回给用户。(倒排索引是搜索引擎实现毫秒级别检索非常关键的一个环节)
- 特点:个性化程度高,返回结构化数据,有一定的位置约束和供给约束

- 搜索步骤:
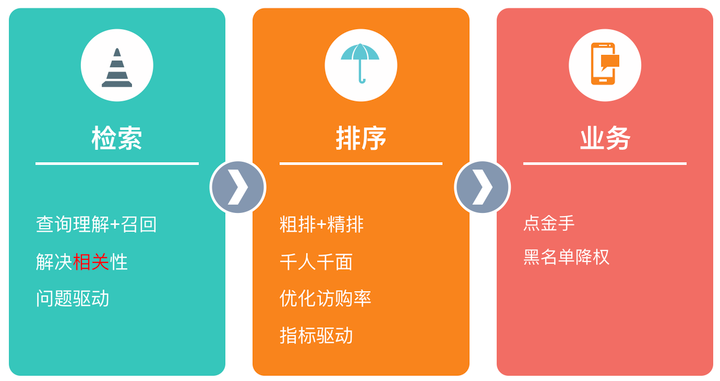
- 检索层:包括查询理解和召回两部分,主要解决相关性问题。查询理解做的事情就是理解用户意图,召回根据用户意图来召回相关的酒店,两者强耦合,需要放在一起。检索的核心是语义理解。
- 排序层:使用机器学习和深度学习的技术提供“千人千面”的个性化排序结果。
业务层:比如对刷单作弊商家做降权处理。
- 排序步骤
- 特点:有连续特征(酒店价格,距离),优化目标是访购率或者点击率
[
](https://blog.csdn.net/weixin_41332009/article/details/113738132)

若有收获,就点个赞吧
0 人点赞
