Good frontend development is hard. Scaling frontend development so that many teams can work simultaneously on a large and complex product is even harder. In this article we’ll describe a recent trend of breaking up frontend monoliths into many smaller, more manageable pieces, and how this architecture can increase the effectiveness and efficiency of teams working on frontend code. As well as talking about the various benefits and costs, we’ll cover some of the implementation options that are available, and we’ll dive deep into a full example application that demonstrates the technique.
良好的前端开发是困难的。前端开发,对于许多团队来说同时处理大型且复杂的产品难度更大。在本篇文章中我们将描述一个最近的趋势,将单一前端项目分拆成更小的易于管理的小模块,改体系结构如何提高团队提高代码编程的效率。除了讨论各种好处与代价之外,我们将介绍一些可选的实现,我们将深入演示一个示例以验证这个技术。
In recent years, microservices have exploded in popularity, with many organisations using this architectural style to avoid the limitations of large, monolithic backends. While much has been written about this style of building server-side software, many companies continue to struggle with monolithic frontend codebases.
Perhaps you want to build a progressive or responsive web application, but can’t find an easy place to start integrating these features into the existing code. Perhaps you want to start using new JavaScript language features (or one of the myriad languages that can compile to JavaScript), but you can’t fit the necessary build tools into your existing build process. Or maybe you just want to scale your development so that multiple teams can work on a single product simultaneously, but the coupling and complexity in the existing monolith means that everyone is stepping on each other’s toes. These are all real problems that can all negatively affect your ability to efficiently deliver high quality experiences to your customers.
Lately we are seeing more and more attention being paid to the overall architecture and organisational structures that are necessary for complex, modern web development. In particular, we’re seeing patterns emerge for decomposing frontend monoliths into smaller, simpler chunks that can be developed, tested and deployed independently, while still appearing to customers as a single cohesive product. We call this technique micro frontends, which we define as:
“An architectural style where independently deliverable frontend applications are composed into a greater whole”
In the November 2016 issue of the Thoughtworks technology radar, we listed micro frontends as a technique that organisations should Assess. We later promoted it into Trial, and finally into Adopt, which means that we see it as a proven approach that you should be using when it makes sense to do so.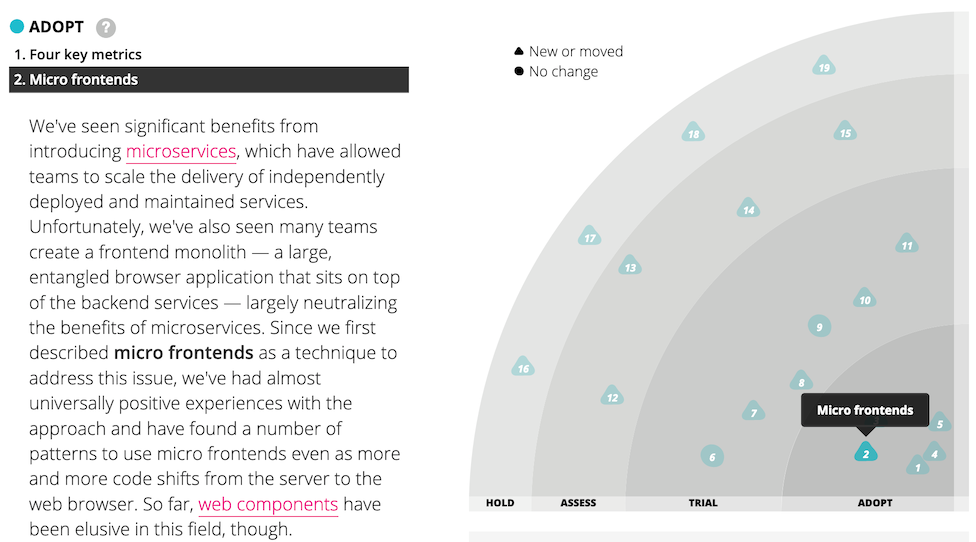
Figure 1: Micro frontends has appeared on the tech radar several times.
Some of the key benefits that we’ve seen from micro frontends are:
- smaller, more cohesive and maintainable codebases
- more scalable organisations with decoupled, autonomous teams
- the ability to upgrade, update, or even rewrite parts of the frontend in a more incremental fashion than was previously possible
It is no coincidence that these headlining advantages are some of the same ones that microservices can provide.
Of course, there are no free lunches when it comes to software architecture - everything comes with a cost. Some micro frontend implementations can lead to duplication of dependencies, increasing the number of bytes our users must download. In addition, the dramatic increase in team autonomy can cause fragmentation in the way your teams work. Nonetheless, we believe that these risks can be managed, and that the benefits of micro frontends often outweigh the costs.
Benefits
Rather than defining micro frontends in terms of specific technical approaches or implementation details, we instead place emphasis on the attributes that emerge and the benefits they give.
Incremental upgrades
For many organisations this is the beginning of their micro frontends journey. The old, large, frontend monolith is being held back by yesteryear’s tech stack, or by code written under delivery pressure, and it’s getting to the point where a total rewrite is tempting. In order to avoid the perils of a full rewrite, we’d much prefer to strangle the old application piece by piece, and in the meantime continue to deliver new features to our customers without being weighed down by the monolith.
This often leads towards a micro frontends architecture. Once one team has had the experience of getting a feature all the way to production with little modification to the old world, other teams will want to join the new world as well. The existing code still needs to be maintained, and in some cases it may make sense to continue to add new features to it, but now the choice is available.
The endgame here is that we’re afforded more freedom to make case-by-case decisions on individual parts of our product, and to make incremental upgrades to our architecture, our dependencies, and our user experience. If there is a major breaking change in our main framework, each micro frontend can be upgraded whenever it makes sense, rather than being forced to stop the world and upgrade everything at once. If we want to experiment with new technology, or new modes of interaction, we can do it in a more isolated fashion than we could before.
Simple, decoupled codebases
The source code for each individual micro frontend will by definition be much smaller than the source code of a single monolithic frontend. These smaller codebases tend to be simpler and easier for developers to work with. In particular, we avoid the complexity arising from unintentional and inappropriate coupling between components that should not know about each other. By drawing thicker lines around the bounded contexts of the application, we make it harder for such accidental coupling to arise.
Of course, a single, high-level architectural decision (i.e. “let’s do micro frontends”), is not a substitute for good old fashioned clean code. We’re not trying to exempt ourselves from thinking about our code and putting effort into its quality. Instead, we’re trying to set ourselves up to fall into the pit of successby making bad decisions hard, and good ones easy. For example, sharing domain models across bounded contexts becomes more difficult, so developers are less likely to do so. Similarly, micro frontends push you to be explicit and deliberate about how data and events flow between different parts of the application, which is something that we should have been doing anyway!
Independent deployment
Just as with microservices, independent deployability of micro frontends is key. This reduces the scope of any given deployment, which in turn reduces the associated risk. Regardless of how or where your frontend code is hosted, each micro frontend should have its own continuous delivery pipeline, which builds, tests and deploys it all the way to production. We should be able to deploy each micro frontend with very little thought given to the current state of other codebases or pipelines. It shouldn’t matter if the old monolith is on a fixed, manual, quarterly release cycle, or if the team next door has pushed a half-finished or broken feature into their master branch. If a given micro frontend is ready to go to production, it should be able to do so, and that decision should be up to the team who build and maintain it.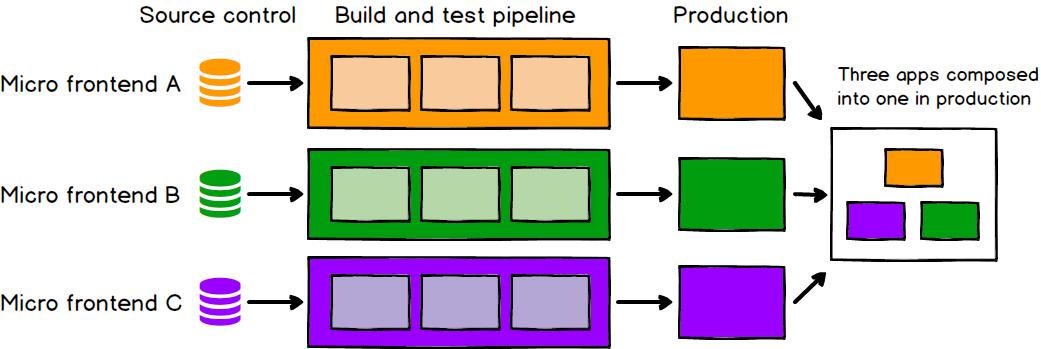
Figure 2: Each micro frontend is deployed to production independently
Autonomous teams
As a higher-order benefit of decoupling both our codebases and our release cycles, we get a long way towards having fully independent teams, who can own a section of a product from ideation through to production and beyond. Teams can have full ownership of everything they need to deliver value to customers, which enables them to move quickly and effectively. For this to work, our teams need to be formed around vertical slices of business functionality, rather than around technical capabilities. An easy way to do this is to carve up the product based on what end users will see, so each micro frontend encapsulates a single page of the application, and is owned end-to-end by a single team. This brings higher cohesiveness of the teams’ work than if teams were formed around technical or “horizontal” concerns like styling, forms, or validation.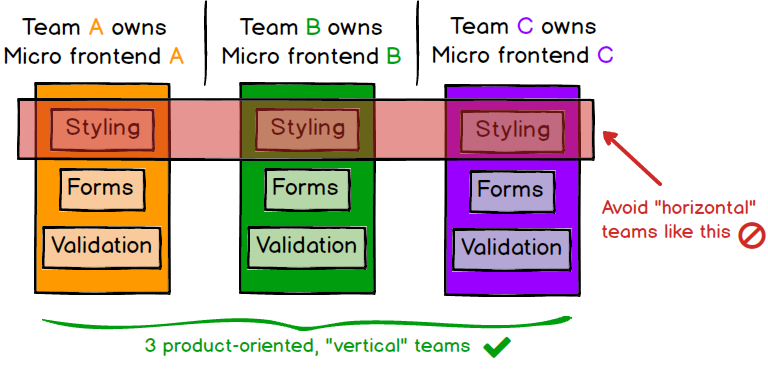
Figure 3: Each application should be owned by a single team
In a nutshell
In short, micro frontends are all about slicing up big and scary things into smaller, more manageable pieces, and then being explicit about the dependencies between them. Our technology choices, our codebases, our teams, and our release processes should all be able to operate and evolve independently of each other, without excessive coordination.
The example
Imagine a website where customers can order food for delivery. On the surface it’s a fairly simple concept, but there’s a surprising amount of detail if you want to do it well:
- There should be a landing page where customers can browse and search for restaurants. The restaurants should be searchable and filterable by any number of attributes including price, cuisine, or what a customer has ordered previously
- Each restaurant needs its own page that shows its menu items, and allows a customer to choose what they want to eat, with discounts, meal deals, and special requests
- Customers should have a profile page where they can see their order history, track delivery, and customise their payment options
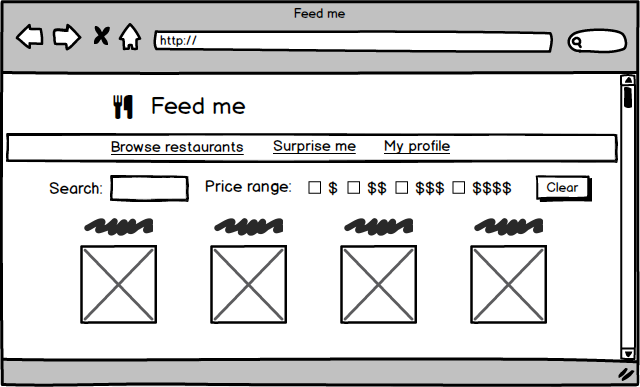
Figure 4: A food delivery website may have several reasonably complex pages
There is enough complexity in each page that we could easily justify a dedicated team for each one, and each of those teams should be able to work on their page independently of all the other teams. They should be able to develop, test, deploy, and maintain their code without worrying about conflicts or coordination with other teams. Our customers, however, should still see a single, seamless website.
Throughout the rest of this article, we’ll be using this example application wherever we need example code or scenarios.
Integration approaches
Given the fairly loose definition above, there are many approaches that could reasonably be called micro frontends. In this section we’ll show some examples and discuss their tradeoffs. There is a fairly natural architecture that emerges across all of the approaches - generally there is a micro frontend for each page in the application, and there is a single container application, which:
- renders common page elements such as headers and footers
- addresses cross-cutting concerns like authentication and navigation
- brings the various micro frontends together onto the page, and tells each micro frontend when and where to render itself
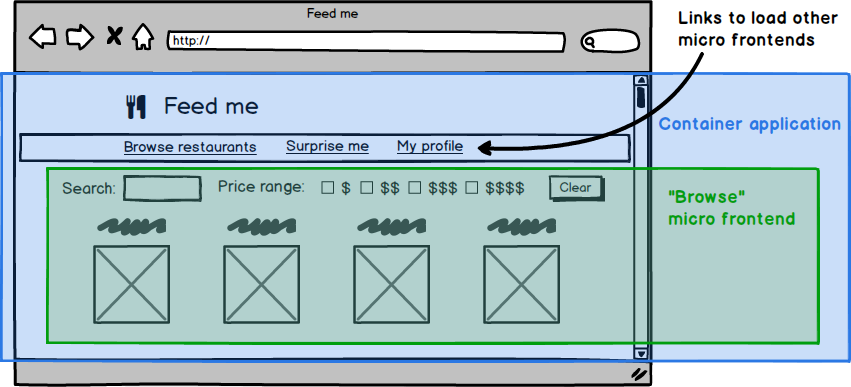
Figure 5: You can usually derive your architecture from the visual structure of the page
Server-side template composition
We start with a decidedly un-novel approach to frontend development - rendering HTML on the server out of multiple templates or fragments. We have an index.html which contains any common page elements, and then uses server-side includes to plug in page-specific content from fragment HTML files:
<html lang="en" dir="ltr">
<head>
<meta charset="utf-8">
<title>Feed me</title>
</head>
<body>
<h1>🍽 Feed me</h1>
<!--# include file="$PAGE.html" -->
</body>
</html>
We serve this file using Nginx, configuring the $PAGE variable by matching against the URL that is being requested:
server {
listen 8080;
server_name localhost;
root /usr/share/nginx/html;
index index.html;
ssi on;
# Redirect / to /browse
rewrite ^/$ http://localhost:8080/browse redirect;
# Decide which HTML fragment to insert based on the URL
location /browse {
set $PAGE 'browse';
}
location /order {
set $PAGE 'order';
}
location /profile {
set $PAGE 'profile'
}
# All locations should render through index.html
error_page 404 /index.html;
}
This is fairly standard server-side composition. The reason we could justifiably call this micro frontends is that we’ve split up our code in such a way that each piece represents a self-contained domain concept that can be delivered by an independent team. What’s not shown here is how those various HTML files end up on the web server, but the assumption is that they each have their own deployment pipeline, which allows us to deploy changes to one page without affecting or thinking about any other page.
For even greater independence, there could be a separate server responsible for rendering and serving each micro frontend, with one server out the front that makes requests to the others. With careful caching of responses, this could be done without impacting latency.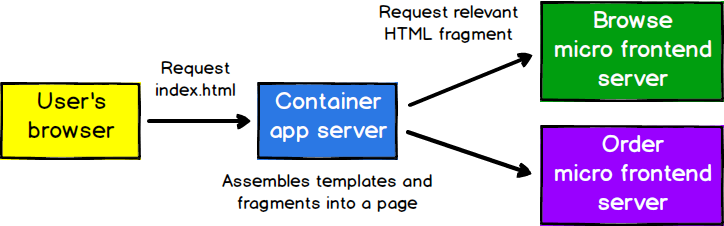
Figure 6: Each of these servers can be built and deployed to independently
This example shows how micro frontends is not necessarily a new technique, and does not have to be complicated. As long as we’re careful about how our design decisions affect the autonomy of our codebases and our teams, we can achieve many of the same benefits regardless of our tech stack.
Build-time integration
One approach that we sometimes see is to publish each micro frontend as a package, and have the container application include them all as library dependencies. Here is how the container’s package.json might look for our example app:
{
"name": "@feed-me/container",
"version": "1.0.0",
"description": "A food delivery web app",
"dependencies": {
"@feed-me/browse-restaurants": "^1.2.3",
"@feed-me/order-food": "^4.5.6",
"@feed-me/user-profile": "^7.8.9"
}
}
At first this seems to make sense. It produces a single deployable Javascript bundle, as is usual, allowing us to de-duplicate common dependencies from our various applications. However, this approach means that we have to re-compile and release every single micro frontend in order to release a change to any individual part of the product. Just as with microservices, we’ve seen enough pain caused by such a lockstep release process that we would recommend strongly against this kind of approach to micro frontends.
Having gone to all of the trouble of dividing our application into discrete codebases that can be developed and tested independently, let’s not re-introduce all of that coupling at the release stage. We should find a way to integrate our micro frontends at run-time, rather than at build-time.
Run-time integration via iframes
One of the simplest approaches to composing applications together in the browser is the humble iframe. By their nature, iframes make it easy to build a page out of independent sub-pages. They also offer a good degree of isolation in terms of styling and global variables not interfering with each other.
<html>
<head>
<title>Feed me!</title>
</head>
<body>
<h1>Welcome to Feed me!</h1>
<iframe id="micro-frontend-container"></iframe>
<script type="text/javascript">
const microFrontendsByRoute = {
'/': 'https://browse.example.com/index.html',
'/order-food': 'https://order.example.com/index.html',
'/user-profile': 'https://profile.example.com/index.html',
};
const iframe = document.getElementById('micro-frontend-container');
iframe.src = microFrontendsByRoute[window.location.pathname];
</script>
</body>
</html>
Just as with the server-side includes option, building a page out of iframes is not a new technique and perhaps does not seem that exciting. But if we revisit the chief benefits of micro frontends listed earlier, iframes mostly fit the bill, as long as we’re careful about how we slice up the application and structure our teams.
We often see a lot of reluctance to choose iframes. While some of that reluctance does seem to be driven by a gut feel that iframes are a bit “yuck”, there are some good reasons that people avoid them. The easy isolation mentioned above does tend to make them less flexible than other options. It can be difficult to build integrations between different parts of the application, so they make routing, history, and deep-linking more complicated, and they present some extra challenges to making your page fully responsive.
Run-time integration via JavaScript
The next approach that we’ll describe is probably the most flexible one, and the one that we see teams adopting most frequently. Each micro frontend is included onto the page using a

若有收获,就点个赞吧
0 人点赞
