目标
zeppelin中已经添加了 jdbc 解释器, 需要在 notebook 中输入 %hive 直接执行 hive sql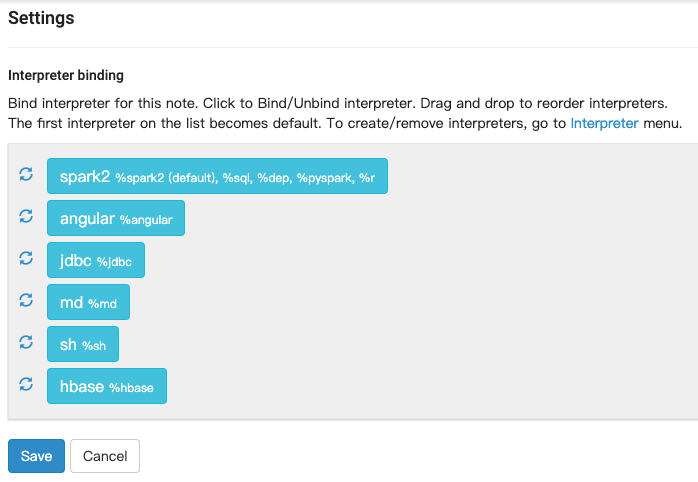
准备
开启hive需要开启hiveserver2, 并准备好 jdbc url,步骤略过,可参考其他文章,这里使用 jdbc:hive2://cluster137:10000/default 示例。
步骤
一、处理jdbc添加依赖
到
http://cluster119:9995/#/interpreter
找到 jdbc 添加如下依赖然后保存。
/usr/hdp/current/zeppelin-server/interpreter/jdbc/hadoop-common-2.7.3.2.6.5.0-292.jar/usr/hdp/current/zeppelin-server/interpreter/jdbc/hive-jdbc-1.2.1000.2.6.5.0-292.jar/usr/hdp/current/zeppelin-server/interpreter/jdbc/curator-client-2.7.1.jar/usr/hdp/current/zeppelin-server/interpreter/jdbc/hive-common-1.2.1000.2.6.5.0-292.jar/usr/hdp/current/zeppelin-server/interpreter/jdbc/hive-serde-1.2.1000.2.6.5.0-292.jar/usr/hdp/current/zeppelin-server/interpreter/jdbc/hive-service-1.2.1000.2.6.5.0-292.jar
hive.driver 填写 org.apache.hive.jdbc.HiveDriver
二、添加hive
点右上角的 Create
Interpreter Name 输入 hive, Interpreter group 选择 jdbc
default.url 填写上面的 hiveserver2 url jdbc:hive2://cluster137:10000/default
default.user 填写 相应的用户,我这里填写 root
default.driver 也填写 org.apache.hive.jdbc.HiveDriver
保存,返回。
应用
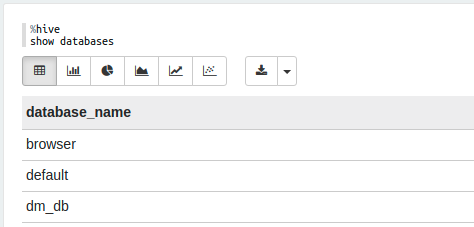
%hive
show databases
如图
收工!

欢迎订阅公众号「大数据学习指北」,
记住能力越大,薪资越高
💰
👆

若有收获,就点个赞吧
0 人点赞
