为什么要迁移?
业务初期,为快速试错,我们选择把服务部署在阿里云,试运行1个多月以来,效果不错,阿里云服务器是比较昂贵的,同时公司一直有合作的机房,并且运维同事有着不错的运维能力,遂决定将服务迁移到合作机房。
制定计划
迁移工作就是「数据迁移」和「程序迁移」,程序迁移可以提前准备和测试,数据迁移则必须保证数据完整性,需要周密的计划。
业务处于初期,每日数据量保持在150w左右,为了保证业务稳定,和产品确认后,同意2小时的停服时间,所以说我们必须在两小时之内迁移完成。
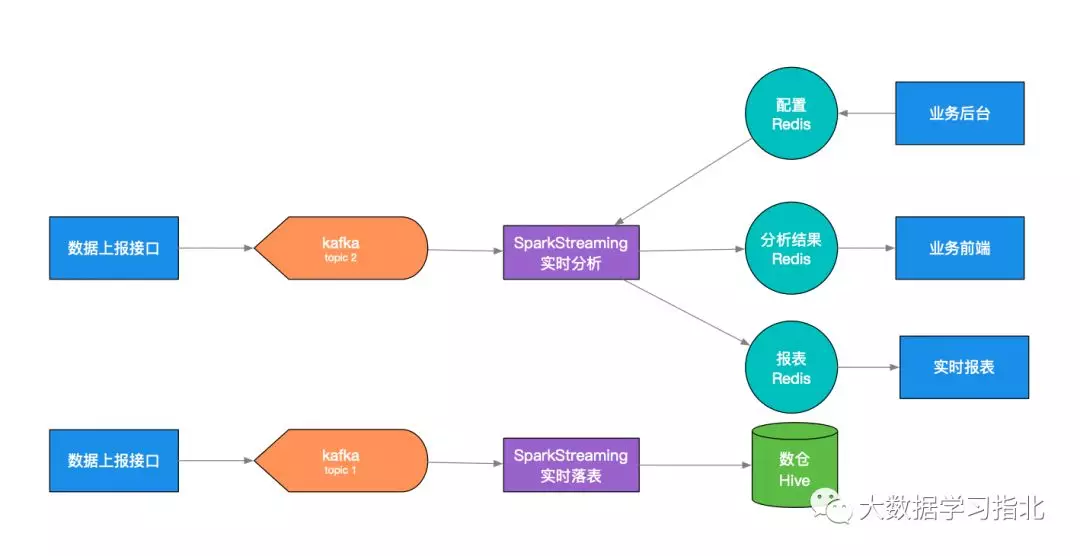
数据流向图
「数据迁移」和「程序迁移」,这些看来都只需要运维操作就可以了,而且又有2个小时的停服时间。
而迁移的目标是「数据完整」,我们必须保证万无一失,有了目标就开始制定计划了。
ps: 一般来说,还有一个目标是:「用户切换无感」,业务初期,为了避免不必要的麻烦,就选择了停服2小时,并且在凌晨1点执行操作。
- 环境部署
- 程序部署并测试
- 停止测试并清理测试数据
迁移hive历史数据和mysql历史数据
老机房停服 lvs
- 迁移hive和数据库增量数据,redis备份
- 检查数据完整性
- 按顺序启动新机房程序
- 线上测试
- 服务对外开放
计划执行**
环境部署(4天前)
我认为迁移非常重要的一点,要保证前后服务器环境一致。硬件性能只高不低,软件配置必须保持一致,迁移过程是没有太多时间排查问题的,特别是因为软件版本差异导致的问题,这些问题通常需要耗费较多时间。
程序部署并测试(3天前)
即使做到环境的一致,我们的程序也需要做些修改,比如kafka,数据库,redis等配置。为了加速,只在大流程回归测试,尽可能多地进行用例测试。这一步我们花了2天时间。
停止测试并清理测试数据(1天前)
测试完成后,需清理数据,包括 zookeeper,数据库,redis,log。
迁移hive历史数据和mysql历史数据(1天前)
数据迁移才是服务迁移的本质,从这一步开始,就要操作数据了。我们的hive表都使用日期和小时做分区,所以可以提前迁移。为了保证,停服之前能完成所有历史数据迁移,这里分两步迁移历史数据,1. 操作的头一天迁移历史数据,2. 操作当天12点开始,确保分区没有数据更新,再执行一次。确保在1点停服之前完成数据迁移。
老机房停服(当天 01:00)
时间来到了停服时间,上线停服页面,lvs 踢掉所有服务器,停止所有实时和定时任务。查看 tengine 服务器日志,越来越少,服务器监控的网络流量越来越少,10分钟后,基本确定已经没有用户触达服务器。
迁移hive和数据库增量数据,redis备份(01:10)
hive的增量也就是当天的数据,直接拷贝hdfs,mysql的增量数据,由运维复制对应时间的 binlog 日志,在新服务器重新执行。redis 备份出现了一次小插曲,阿里云的redis集群控制台访问报错,好在2分钟左右恢复访问了。
检查数据完整性(01:30)
数据迁移后,由开发通过 zeppelin 抽查对比两个机房数据是否一致。
按顺序启动新机房程序(01:40)
数据实时分析有些基于历史数据,必须让这些脚本先执行完成,在开启后续脚本。要注意定时任务的时间,如果是停服期间执行的任务,必须先手动执行一次。
ps: 定时任务,一般都要保证冥等性,即多次调用结果一致;
线上测试(01:50)
lvs 已经踢下线了,测试可以绑定host访问和测试,测试耗费了1个小时,完成所有回归。这里也出现一个小插曲,tengine client_max_body_size 设置太小导致文件上传不成功。
服务重新上线(03:00)
收到测试通过的通知,运维同时把服务器都挂上了lvs负载均衡,看到陆陆续续越来越多的请求进来,hive,实时报表等数据都有了,我们知道这次迁移成功了。
总结
整个服务迁移过程没有出现卡壳,数据未造成丢失,保证数据迁移的数据完整性,需要改进的是耗时太长,但迁移的应用场景实际上并不会出现太多,所以暂时不会去寻找无缝迁移的解决方案。

欢迎订阅公众号「大数据学习指北」,
记住能力越大,薪资越高
💰
👆

若有收获,就点个赞吧
0 人点赞
