
题图:金黄阳光下的建筑
+—————————————+
| Spark Streaming |
+—————————————+
Spark Streaming 实时消费kafka入hive,一般控制批次数据在1分钟以内,甚至30s,而hive分区一般都会按照小时分区,就会导致小文件数据非常多。小文件多了,那么如上篇文章所说,有如下两个问题:
- 小文件过多,占用 namenode 资源,hive 查询也会读取过多数据块 block 的数据,影响 hive 查询性能;
- 因如上的问题,一般需要在某个分区不再更新的时候,比如上一个小时的数据不再更新了,就可以执行hive sql达到指定文件大小来合并分区。而合并小文件同样需要消耗 namenode 资源;
-- hive 合并小文件示例ALTER TABLE test_table PARTITION(p_dt='${date}',p_hours='${hour}') CONCATENATE;
那么没有更好的方案呢?
实际使用过程,我们看到,1分钟一个批次的数据,处理时间只需20s左右(业务场景不同时长有所不同),这空闲的40s,显然浪费了。
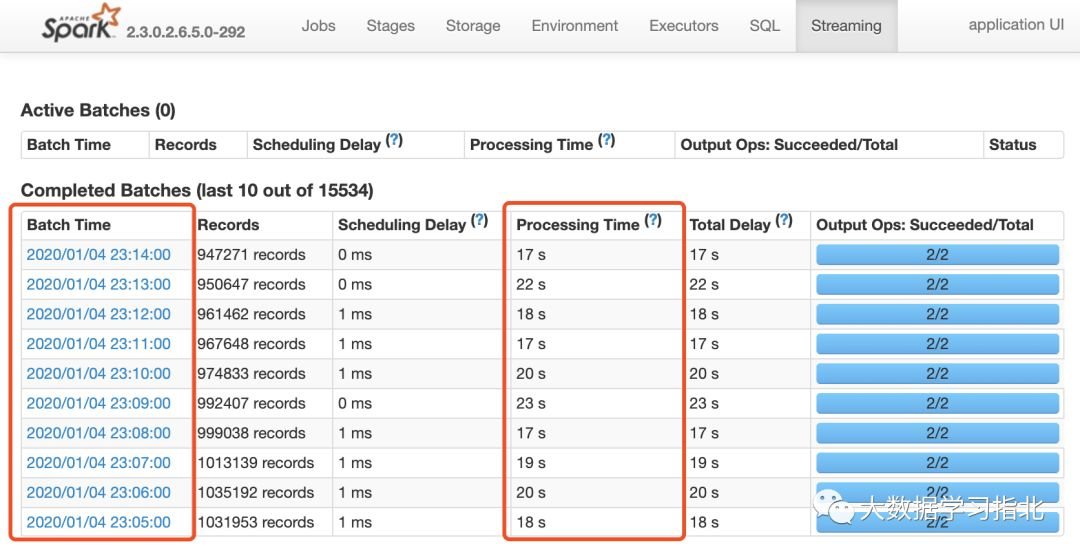

spark streaming 实时ETL任务的处理时间
问题的根源还是小文件的存在,解决方式自然在这里:
- batch time 延长
- 写入到一个文件,需改写写入 hdfs 方法(不展开)
- 写入文件可能需要使用 ORC 格式
- 保证文件大小接近 HDFS 文件系统的 Block Size
spark 写入 hdfs 均为小文件,可通过 repartition(1) , coalesce(1) 来实现写入到一个文件;
如果要保证文件接近HDFS,那必定需要知道 RDD 的大小
var rddSize = rdd.map(_.toString())
.map(_.getBytes("UTF-8").length.toLong)
.reduce(_+_)
或者根据 rdd 的数量再结合经验来估算文件大小:rdd.count();
再不济直接去HDFS遍历 文件大小,以确定是追加还是写入新文件。
如上问题让简单的 ETL 变得复杂起来:
事情一旦复杂,那么出错的概率就会大大增加;
+—————————————+
| Flink |
+—————————————+
苦于没有更合适的解决方案,换种架构可能是最好的方式,Flink 登场。
两三小时调研,寻得 HDFS connect 竟有设置写入文件大小的api,大喜,竟然还有文件定时自动翻滚,大喜过望,立马惊醒demo验证:
// 写入HDFS
val bucketingSink = new BucketingSink[String]("/tmp/test_flink")
// 设置以yyyyMMdd的格式进行切分目录,类似hive的日期分区
bucketingSink.setBucketer(new DateTimeBucketer("yyyy-MM-dd--HHmm", ZoneId.of("America/Los_Angeles")))
bucketingSink.setWriter(new SequenceFileWriter[IntWritable, Text])
// 设置文件块大小128M,超过128M会关闭当前文件,开启下一个文件
bucketingSink.setBatchSize(1024 * 1024 * 128L);
// 设置5分钟翻滚一次bucketingSink.setBatchRolloverInterval(5 * 60 * 1000L);
bucketingSink.setPartPrefix("node")
// 设置等待写入的文件前缀,默认是_
bucketingSink.setPendingPrefix("");
// 设置等待写入的文件后缀,默认是.pending
bucketingSink.setPendingSuffix("");
//设置正在处理的文件前缀,默认为_
bucketingSink.setInProgressPrefix(".");
如上设置只能让数据写入到固定的分区,需对数据做复杂处理,进一步调研发现可以 自定义 bucketer
bucketingSink.setBucketer(new InteractivePathBucketer());
InteractivePathBucketer 便是自定义的 bucketer,功能便是根据数据内容来定 hdfs 的路径;
public class InteractivePathBucketer extends BasePathBucketer<String> {
private static Gson gson = new Gson();
/** * 根据数据自定义路径 **/
@Override
public Path getBucketPath(Clock clock, Path basePath, String element){
String path = "-1";
if (element != null) {
try {
JsonObject jsonObject = gson.fromJson(element, JsonObject.class);
if (jsonObject != null && jsonObject.getAsJsonObject("data") != null && jsonObject.getAsJsonObject("data").get("type") != null) {
path = jsonObject.getAsJsonObject("data").get("type").getAsString();
}
} catch (Exception e) {
path = "-1";
}
}
return new Path(basePath + File.separator + path.trim());
}
}
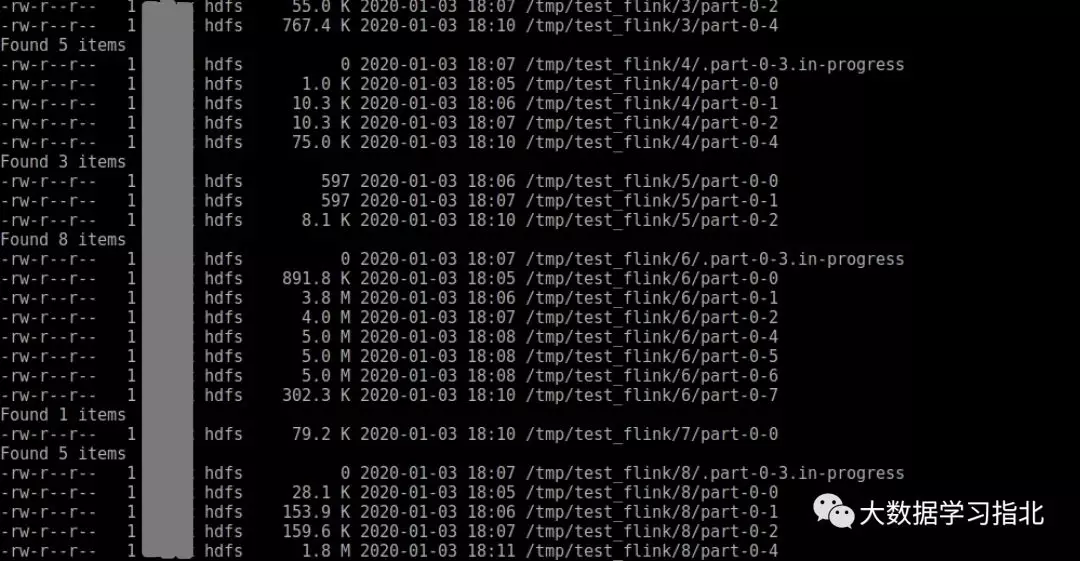
结果:
- 指定5M的文件大小;
- 每分钟分割一个文件,应对数据长时间达不到指定文件大小;
+—————————————+
| 写在最后 |
+—————————————+
Flink 显然解决了实时ETL写入过多小文件的问题,轮子用与不用,它都在那里,欢迎后台留言沟通交流。

欢迎订阅公众号「大数据学习指北」,
记住能力越大,薪资越高
💰
👆

若有收获,就点个赞吧
0 人点赞
