本篇详细说明merge的应用,join 和concatenate的拼接方法的与之相似。
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,left_index=False, right_index=False, sort=True,suffixes=('_x', '_y'), copy=True, indicator=False,validate=None)
参数如下:
left: 拼接的左侧DataFrame对象
right: 拼接的右侧DataFrame对象
on: 要加入的列或索引级别名称。 必须在左侧和右侧DataFrame对象中找到。 如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。
left_on:左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
right_on: 左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
left_index: 如果为True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 对于具有MultiIndex(分层)的DataFrame,级别数必须与右侧DataFrame中的连接键数相匹配。
right_index: 与left_index功能相似。
how: One of ‘left’, ‘right’, ‘outer’, ‘inner’. 默认inner。inner是取交集,outer取并集。比如left:[‘A’,‘B’,‘C’];right[’’A,‘C’,‘D’];inner取交集的话,left中出现的A会和right中出现的买一个A进行匹配拼接,如果没有是B,在right中没有匹配到,则会丢失。’outer’取并集,出现的A会进行一一匹配,没有同时出现的会将缺失的部分添加缺失值。
sort: 按字典顺序通过连接键对结果DataFrame进行排序。 默认为True,设置为False将在很多情况下显着提高性能。
suffixes: 用于重叠列的字符串后缀元组。 默认为(‘x’,’ y’)。
copy: 始终从传递的DataFrame对象复制数据(默认为True),即使不需要重建索引也是如此。
indicator:将一列添加到名为_merge的输出DataFrame,其中包含有关每行源的信息。 _merge是分类类型,并且对于其合并键仅出现在“左”DataFrame中的观察值,取得值为left_only,对于其合并键仅出现在“右DataFrame中的观察值为right_only,并且如果在两者中都找到观察点的合并键,则为left_only。
1、基础实例:
import pandas as pdleft = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']})right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']})result = pd.merge(left, right, on='key')# on参数传递的key作为连接键resultOut[4]:A B key C D0 A0 B0 K0 C0 D01 A1 B1 K1 C1 D12 A2 B2 K2 C2 D23 A3 B3 K3 C3 D3
2、传入的on的参数是列表:
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],'key2': ['K0', 'K1', 'K0', 'K1'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']})right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],'key2': ['K0', 'K0', 'K0', 'K0'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']})result = pd.merge(left, right, on=['key1', 'key2'])# 同时传入两个Key,此时会进行以['key1','key2']列表的形式进行对应,left的keys列表是:[['K0', 'K0'],['K0', 'K1'],['K1', 'K0'],['K2', 'K1']],left的keys列表是:[['K0', 'K0'],['K1', 'K0'],['K1', 'K0'],['K2', 'K0']],因此会有1个['K0', 'K0']、2个['K1', 'K0']对应。resultOut[6]:A B key1 key2 C D0 A0 B0 K0 K0 C0 D01 A2 B2 K1 K0 C1 D12 A2 B2 K1 K0 C2 D2
3、Merge method
如果组合键没有出现在左表或右表中,则连接表中的值将为NA。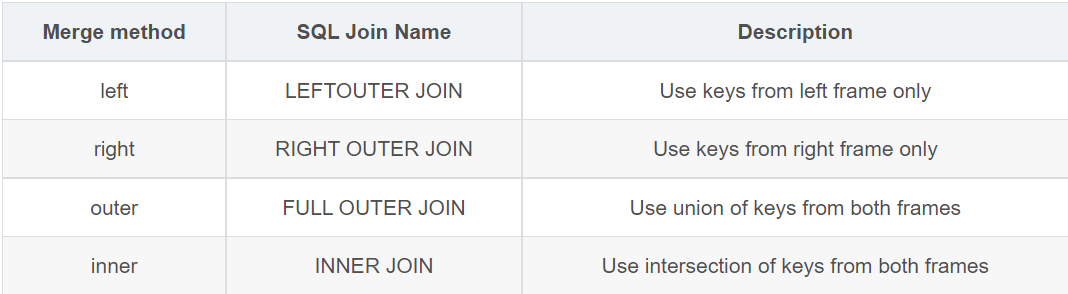
result = pd.merge(left, right, how='left', on=['key1', 'key2'])# Use keys from left frame onlyresultOut[34]:A B key1 key2 C D0 A0 B0 K0 K0 C0 D01 A1 B1 K0 K1 NaN NaN2 A2 B2 K1 K0 C1 D13 A2 B2 K1 K0 C2 D24 A3 B3 K2 K1 NaN NaNresult = pd.merge(left, right, how='right', on=['key1', 'key2'])# Use keys from right frame onlyresultOut[36]:A B key1 key2 C D0 A0 B0 K0 K0 C0 D01 A2 B2 K1 K0 C1 D12 A2 B2 K1 K0 C2 D23 NaN NaN K2 K0 C3 D3result = pd.merge(left, right, how='outer', on=['key1', 'key2'])# Use intersection of keys from both framesresultOut[38]:A B key1 key2 C D0 A0 B0 K0 K0 C0 D01 A1 B1 K0 K1 NaN NaN2 A2 B2 K1 K0 C1 D13 A2 B2 K1 K0 C2 D24 A3 B3 K2 K1 NaN NaN5 NaN NaN K2 K0 C3 D3-----------------------------------------------------left = pd.DataFrame({'A' : [1,2], 'B' : [2, 2]})right = pd.DataFrame({'A' : [4,5,6], 'B': [2,2,2]})result = pd.merge(left, right, on='B', how='outer')resultOut[40]:A_x B A_y0 1 2 41 1 2 52 1 2 63 2 2 44 2 2 55 2 2 6
4、传入indicator参数
merge接受参数指示符。 如果为True,则将名为_merge的Categorical类型列添加到具有值的输出对象: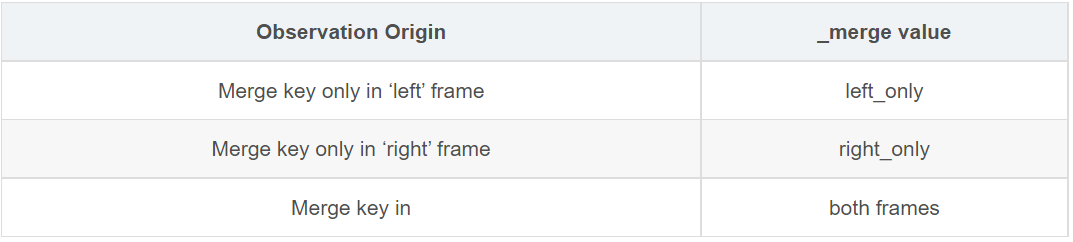
df1 = pd.DataFrame({'col1': [0, 1], 'col_left':['a', 'b']})df2 = pd.DataFrame({'col1': [1, 2, 2],'col_right':[2, 2, 2]})pd.merge(df1, df2, on='col1', how='outer', indicator=True)Out[44]:col1 col_left col_right _merge0 0.0 a NaN left_only1 1.0 b 2.0 both2 2.0 NaN 2.0 right_only3 2.0 NaN 2.0 right_only
指标参数也将接受字符串参数,在这种情况下,指标函数将使用传递的字符串的值作为指标列的名称。
pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column')Out[45]:col1 col_left col_right indicator_column0 0.0 a NaN left_only1 1.0 b 2.0 both2 2.0 NaN 2.0 right_only3 2.0 NaN 2.0 right_only
5、以index为链接键
需要同时设置left_index= True 和 right_index= True,或者left_index设置的同时,right_on指定某个Key。总的来说就是需要指定left、right链接的键,可以同时是key、index或者混合使用。
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],....: 'B': ['B0', 'B1', 'B2']},....: index=['K0', 'K1', 'K2'])....:right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],....: 'D': ['D0', 'D2', 'D3']},....: index=['K0', 'K2', 'K3'])....:# 只有K0、K2有对应的值pd.merge(left,right,how= 'inner',left_index=True,right_index=True)Out[51]:A B C DK0 A0 B0 C0 D0K2 A2 B2 C2 D2left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3'],'key': ['K0', 'K1', 'K0', 'K1']})right = pd.DataFrame({'C': ['C0', 'C1'],'D': ['D0', 'D1']},index=['K0', 'K1'])result = pd.merge(left, right, left_on='key', right_index=True, how='left', sort=False)# left_on='key', right_index=TrueresultOut[54]:A B key C D0 A0 B0 K0 C0 D01 A1 B1 K1 C1 D12 A2 B2 K0 C0 D03 A3 B3 K1 C1 D1
6、sort对链接的键值进行排序:
紧接着上一例,设置sort= Trueresult = pd.merge(left, right, left_on='key', right_index=True, how='left', sort=True)resultOut[57]:A B key C D0 A0 B0 K0 C0 D02 A2 B2 K0 C0 D01 A1 B1 K1 C1 D13 A3 B3 K1 C1 D1
对于多重索引,目前应用较少,就不做深入学习,以后有需要再加。
总的来说,merge的应用场景是针对链接键来进行操作的,链接键可以是index或者column。但是实际应用时一定注意的是left或者right的键值不要重复,这样引来麻烦。

若有收获,就点个赞吧
0 人点赞
