DataFrame的应用
数据分析
经过前面的学习,我们已经将数据准备就绪而且变成了我们想要的样子,接下来就是最为重要的数据分析阶段了。当我们拿到一大堆数据的时候,如何从数据中迅速的解读出有价值的信息,这就是数据分析要解决的问题。首先,我们可以获取数据的描述性统计信息,通过描述性统计信息,我们可以了解数据的集中趋势和离散趋势。
例如,我们有如下所示的学生成绩表。
import numpy as npimport pandas as pd#5和3的意思是5行3列,然后取随机数scores = np.random.randint(50, 101, (5, 3))names = ('关羽', '张飞', '赵云', '马超', '黄忠')courses = ('语文', '数学', '英语')df = pd.DataFrame(data=scores, columns=courses, index=names)print(df)
结果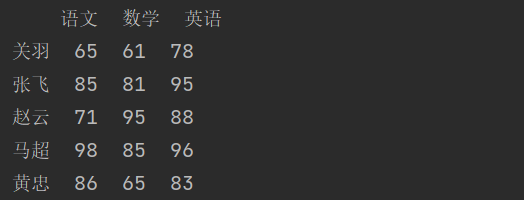
我们可以通过DataFrame对象的方法mean、max、min、std、var等方法分别获取每个学生或每门课程的平均分、最高分、最低分、标准差、方差等信息,也可以直接通过describe方法直接获取描述性统计信息,

若有收获,就点个赞吧
0 人点赞
