DataFrame的应用
dataframe的汉语意思是数据框,数据帧
创建DataFrame对象
通过二维数组创建DataFrame对象
代码:
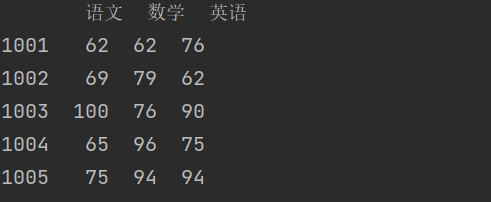
import pandas as pdimport numpy as npscores = np.random.randint(60, 101, (5, 3))courses = ['语文', '数学', '英语']ids = [1001, 1002, 1003, 1004, 1005]df1 = pd.DataFrame(data=scores, columns=courses, index=ids)print(df1)
通过字典创建DataFrame对象
代码
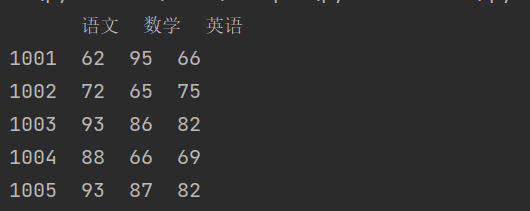
scores = {'语文': [62, 72, 93, 88, 93],'数学': [95, 65, 86, 66, 87],'英语': [66, 75, 82, 69, 82],}ids = [1001, 1002, 1003, 1004, 1005]df2 = pd.DataFrame(data=scores, index=ids)print(df2)
读取 CSV 文件创建DataFrame对象
可以通过pandas 模块的read_csv函数来读取 CSV 文件,read_csv函数的参数非常多,下面接受几个比较重要的参数。
- sep / delimiter:分隔符,默认是,。
- header:表头(列索引)的位置,默认值是infer,用第一行的内容作为表头(列索引)。
- index_col:用作行索引(标签)的列。
- usecols:需要加载的列,可以使用序号或者列名。
- true_values / false_values:哪些值被视为布尔值True / False。
- skiprows:通过行号、索引或函数指定需要跳过的行。
- skipfooter:要跳过的末尾行数。
- nrows:需要读取的行数。
- na_values:哪些值被视为空值。
代码:
import pandas as pd##这里encoding表示编码格式,不写的话默认按照UTF-8格式,在此例中UTF-8格式会报错df3 = pd.read_csv(r'C:\Users\wangjian\Desktop\test\test.csv',encoding = 'gb2312')print(df3)
结果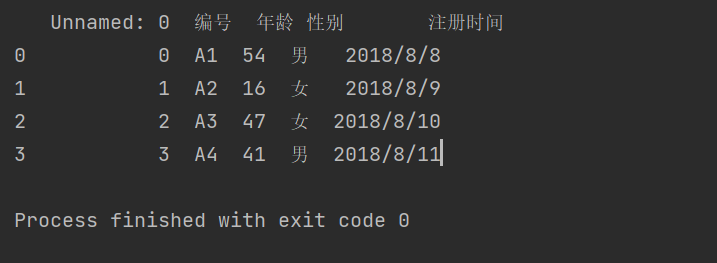
1.指定分隔符
read_csv()默认文件中的数据是以逗号作为分隔符的,有的文件不是用逗号分隔的,需要人为指定分隔符
代码:
import pandas as pddf3 = pd.read_csv(r'C:\Users\wangjian\Desktop\test\test.csv',sep=" ",encoding = 'gb2312')print(df3)
结果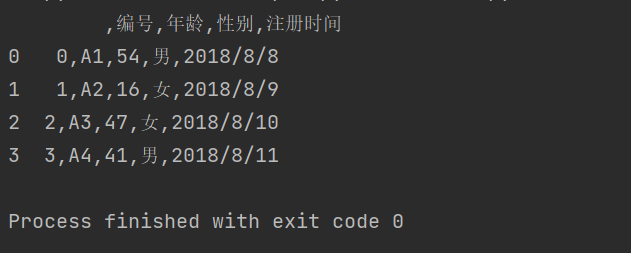
常见的分隔符有逗号,空格和制表符(\t)
2.指定读取行数
代码
import pandas as pddf3 = pd.read_csv(r'C:\Users\wangjian\Desktop\test\test.csv',nrows=2,encoding = 'gb2312')print(df3)
结果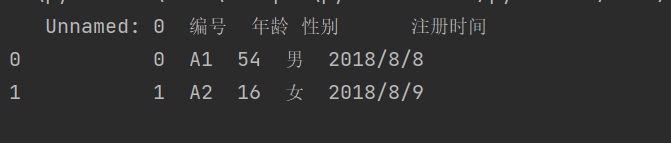
3.指定编码格式
常用的编码格式为UTF-8和gbk(gb2312)
4.engine指定
当文件路径或者文件名中出现中文时,之前的导入方式会报错。engine意思是发动机,引擎的意思。
代码为
import pandas as pd#csv文件编码格式为gbkdf3 = pd.read_csv(r'C:\Users\wangjian\Desktop\新建文件夹\test.csv',engine="python",encoding = 'gbk')print(df3)import pandas as pd#csv文件编码格式为utf-8df3 = pd.read_csv(r'C:\Users\wangjian\Desktop\新建文件夹\test.csv',engine="python",encoding = 'utf-8-sig')print(df3)
附件如下:
test.csv
读取Excel文件创建 DataFrame 对象
1.基本导入
代码:
import pandas as pddf = pd.read_excel(r'C:\Users\wangjian\Desktop\test\test1.xlsx')print(df)
结果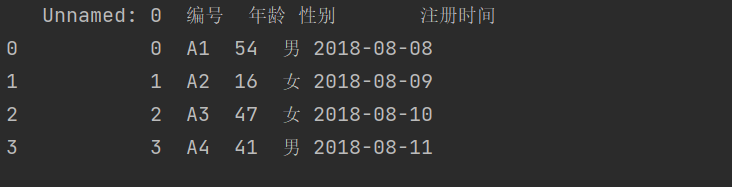
2.指定导入哪个sheet
除了可以指定传入sheet的顺序,还可以指定从0开始
import pandas as pddf = pd.read_excel(r'C:\Users\wangjian\Desktop\test\test1.xlsx',sheet_name="Sheet2")print(df)
结果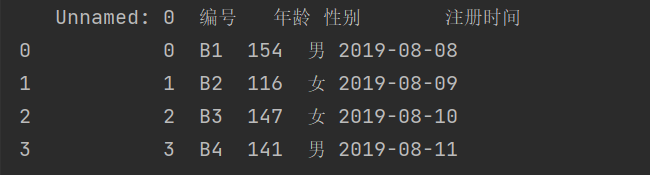
代码
import pandas as pddf = pd.read_excel(r'C:\Users\wangjian\Desktop\test\test1.xlsx',sheet_name=0)print(df)
结果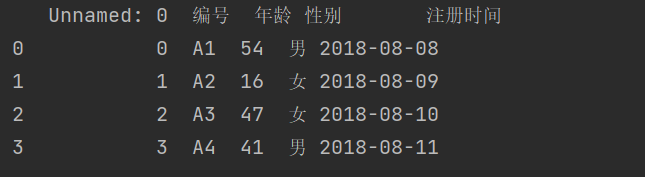
3.指定行索引和列索引
行索引index_col,列索引 header
行索引默认是从0开始的
代码
import pandas as pddf = pd.read_excel(r'C:\Users\wangjian\Desktop\test\test1.xlsx',sheet_name=0,index_col=0)print(df)
结果
代码
import pandas as pddf = pd.read_excel(r'C:\Users\wangjian\Desktop\test\test1.xlsx',sheet_name=0,index_col=1)print(df)
结果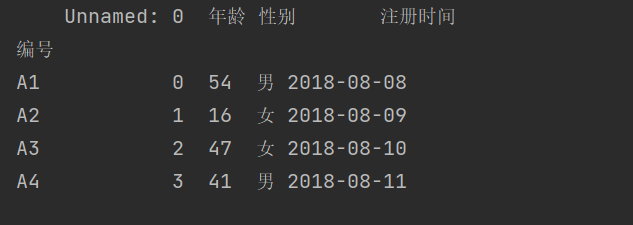
代码
import pandas as pddf = pd.read_excel(r'C:\Users\wangjian\Desktop\test\test1.xlsx',sheet_name=0,index_col=2)print(df)
结果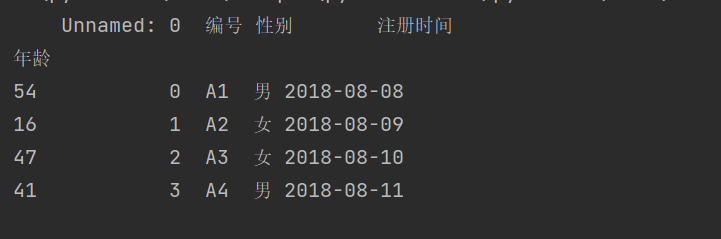
导入列索引:
列索引默认值为0
代码
import pandas as pddf = pd.read_excel(r'C:\Users\wangjian\Desktop\test\test1.xlsx',sheet_name=0,header=2)print(df)
结果
附件test1.xlsx
通过SQL从数据库读取数据创建 DataFrame 对象
pandas 模块的 read_sql 函数可以通过 SQL 语句从数据库中读取数据创建 DataFrame 对象,该函数的
第二个参数代表了需要连接的数据库。对于 MySQL 数据库,我们可以通过 pymysql 或 mysqlclient 来
创建数据库连接,得到一个 Connection 对象,而这个对象就是 read_sql 函数需要的第二个参数,代
码如下所示。
代码:
import pandas as pdimport pymysql# 创建一个MySQL数据库的连接对象conn = pymysql.connect( host='47.104.31.138', port=3306,user='guest', password='Guest.618',database='hrs', charset='utf8mb4' )# 通过SQL从数据库读取数据创建DataFramedf5 = pd.read_sql('select * from tb_emp', conn, index_col='eno')print(df5)
结果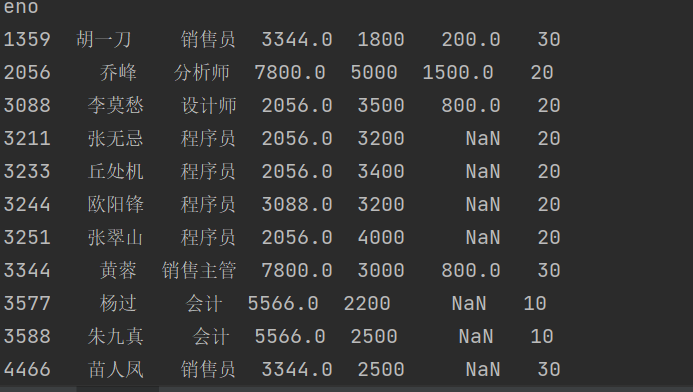
提示:执行上面的代码需要先安装 pymysql 库,如果尚未安装,可以先在 Notebook 的单元格中
先执行 !pip install pymysql ,然后再运行上面的代码。上面的代码连接的是我部署在阿里云
上的 MySQL 数据库,公网 IP 地址: 47.104.31.138 ,用户名: guest ,密码: Guest.618 ,
数据库: hrs ,表名: tb_emp ,字符集: utf8mb4 ,大家可以使用这个数据库,但是不要进行
恶意的访问。
基本属性和方法
在开始讲解 DataFrame 的属性和方法前,我们先从之前提到的 hrs 数据库中读取三张表的数据,创建出
三个 DataFrame 对象,代码如下所示。
import pandas as pdimport pymysqlconn = pymysql.connect( host='47.104.31.138', port=3306,user='guest', password='Guest.618',database='hrs', charset='utf8mb4' )dept_df = pd.read_sql('select * from tb_dept', conn, index_col='dno')emp_df = pd.read_sql('select * from tb_emp', conn, index_col='eno')emp2_df = pd.read_sql('select * from tb_emp2', conn, index_col='eno')print(dept_df)
部门表( dept_df ),其中 dno 是部门的编号, dname 和 dloc 分别是部门的名称和所在地。
员工表( emp_df ),其中 eno 是员工编号, ename 、 job 、 mgr 、 sal 、 comm 和 dno 分别代表员工
的姓名、职位、主管编号、月薪、补贴和部门编号。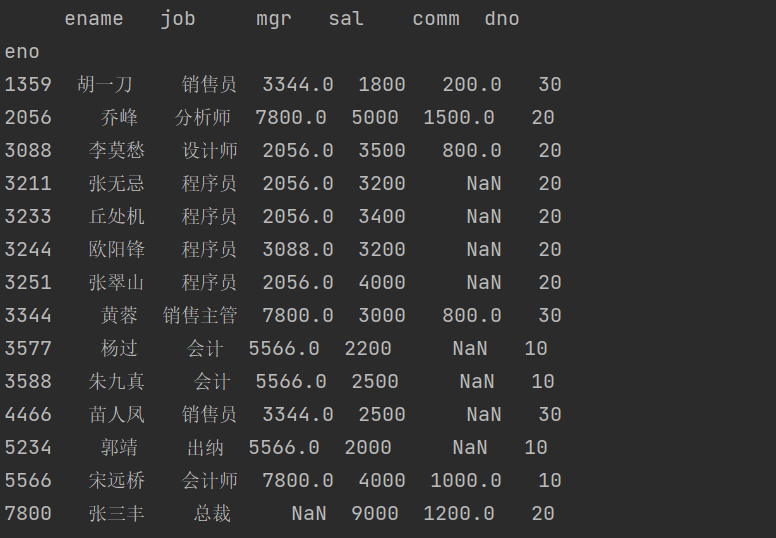
说明:在数据库中 mgr 和 comm 两个列的数据类型是 int ,但是因为有缺失值(空值),读取到
DataFrame 之后,列的数据类型变成了 float ,因为我们通常会用 float 类型的 NaN 来表示空
值。
员工表( emp2_df ),跟上面的员工表结构相同,但是保存了不同的员工数据。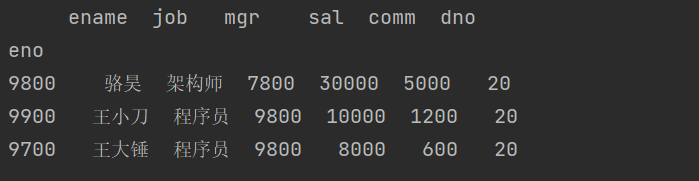
DataFrame 对象的属性如下表所示。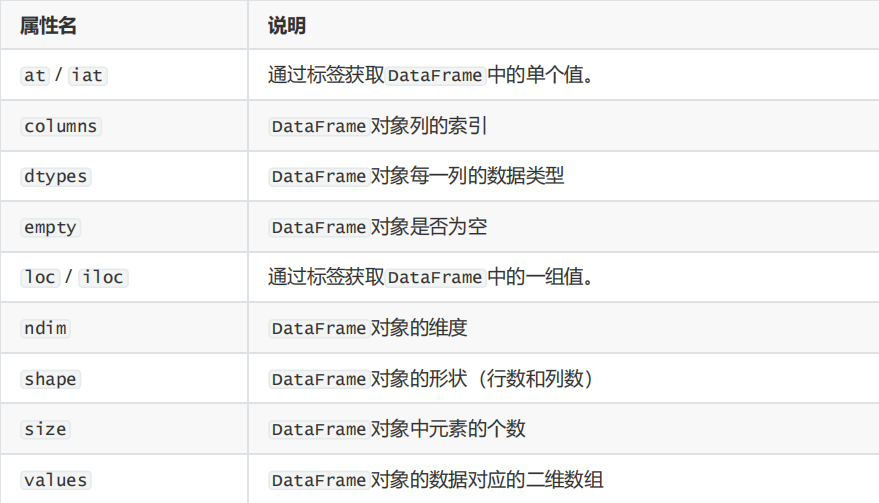
关于 DataFrame 的方法,首先需要了解的是 info() 方法,它可以帮助我们了解 DataFrame 的相关信
息,如下所示。
代码:
print(emp_df.info())
结果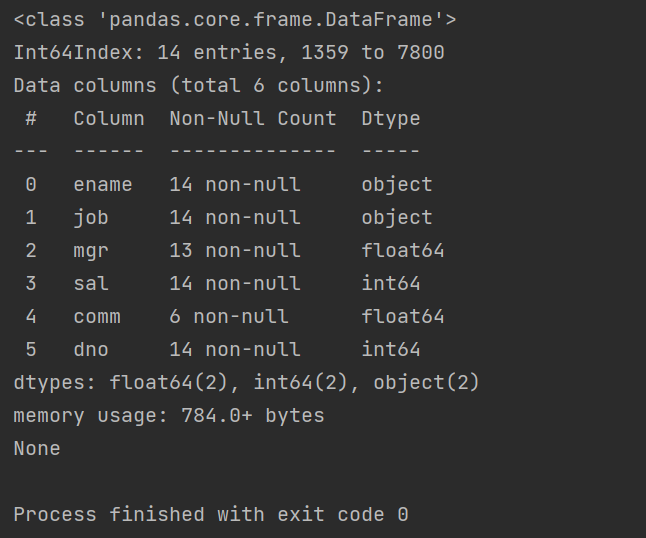
Pandas dataframe.info()函数用于获取 DataFrame 的简要摘要。在对数据进行探索性分析时,它非常方便。为了快速浏览数据集,我们使用dataframe.info()函数。(同类型参考python数据分析P70)
emp_df有14行,行索引index是1359-7800,总共6个行索引,两个是float类型,两个是int类型,两个是object类型,公用内存784bytes。
如果需要查看 DataFrame 的头部或尾部的数据,可以使用 head() 或 tail() 方法,这两个方法的默认参数是 5,表示获取 DataFrame 最前面5行或最后面5行的数据,如下所示。
代码
emp_df.head()
结果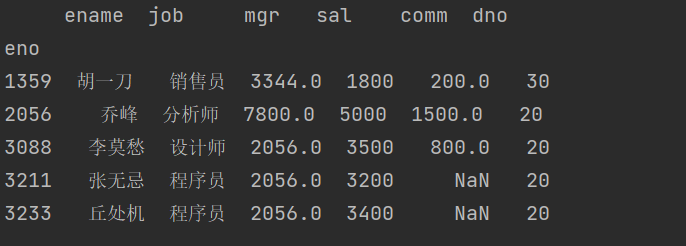
获取数据
索引和切片
如果要获取 DataFrame 的某一列,例如取出上面 emp_df 的 ename 列,可以使用下面的两种方式。
print(emp_df.ename)
或者
print(emp_df['ename'])
结果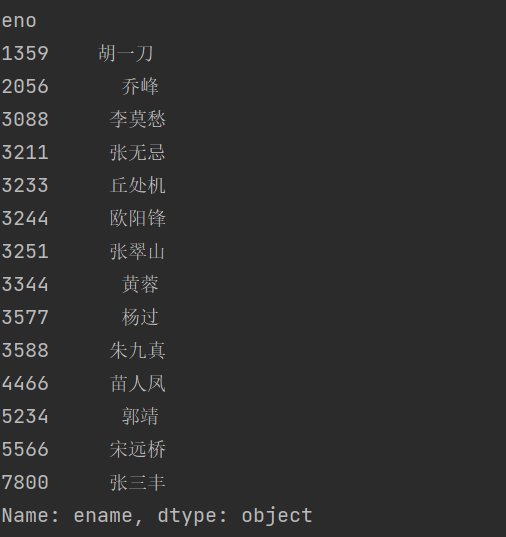
执行上面的代码可以发现,我们获得的是一个 Series 对象。事实上, DataFrame 对象就是将多个 Series 对象组合到一起的结果。
如果要获取 DataFrame 的某一行,可以使用整数索引或我们设置的索引,例如取出员工编号为 2056 的 员工数据,代码如下所示。
emp_df.iloc[1]
或者
emp_df.loc[2056]
结果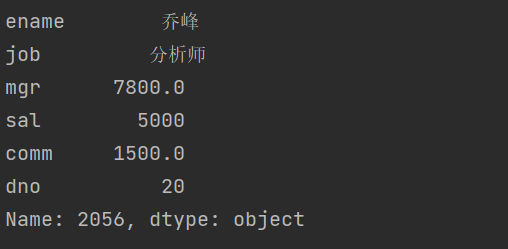
通过执行上面的代码我们发现,单独取 DataFrame 的某一行或某一列得到的都是 Series 对象。我们当
然也可以通过花式索引来获取多个行或多个列的数据,花式索引的结果仍然是一个 DataFrame 对象。
获取多个列:
print(emp_df[['ename', 'job']])
结果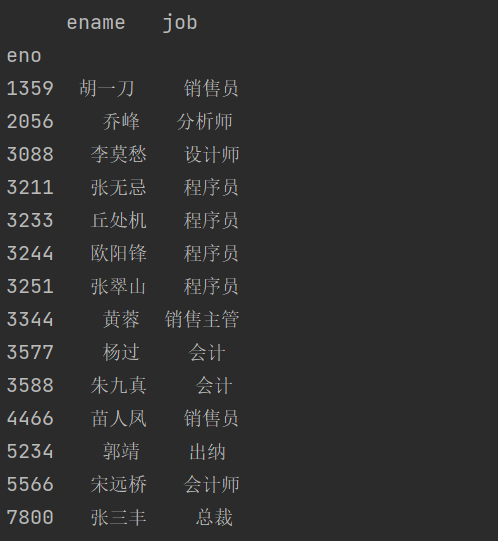
获取多个行:
emp_df.loc[[2056, 7800, 3344]]
结果: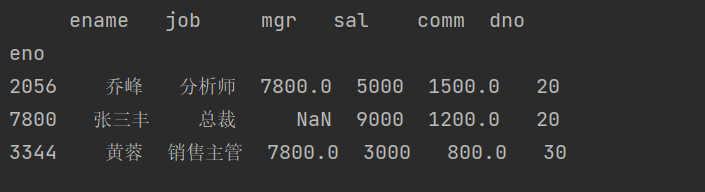
如果要获取或修改 DataFrame 对象某个单元格的数据,需要同时指定行和列的索引,例如要获取员工编号为 2056 的员工的职位信息,代码如下所示。
#方法1emp_df['job'][2056]#方法2emp_df.loc[2056]['job']#方法3emp_df.loc[2056, 'job']
我们推荐大家使用第三种做法,因为它只做了一次索引运算。如果要将该员工的职位修改为“架构师”,可以使用下面的代码。
emp_df.loc[2056, 'job'] = '架构师'print(emp_df)
结果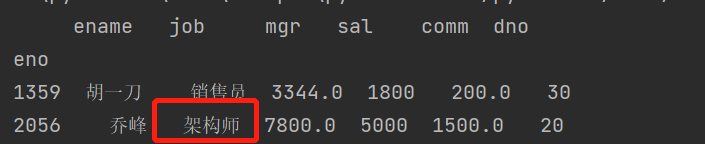
当然,我们也可以通过切片操作来获取多行多列,相信大家一定已经想到了这一点。
print(emp_df.loc[2056:3344])
结果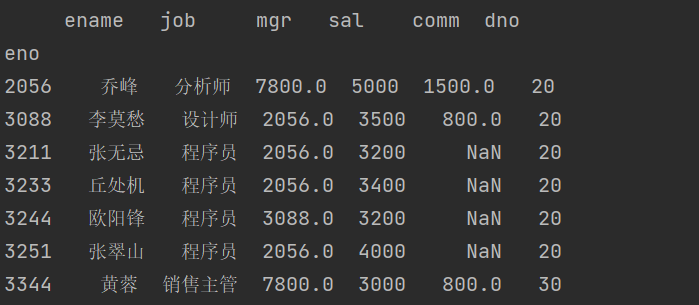
数据筛选
上面我们提到了花式索引,相信大家已经联想到了布尔索引。跟 ndarray 和 Series 一样,我们可以通
过布尔索引对 DataFrame 对象进行数据筛选,例如我们要从 emp_df 中筛选出月薪超过 3500 的员工,
代码如下所示。
print(emp_df[emp_df.sal > 3500])
结果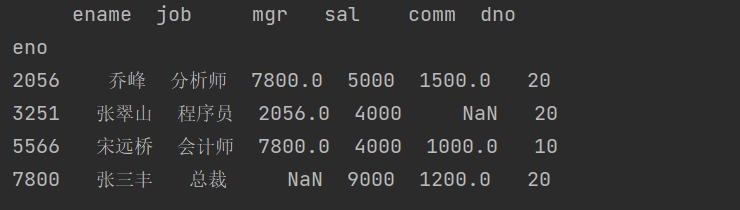
当然,我们也可以组合多个条件来进行数据筛选,例如从 emp_df 中筛选出月薪超过 3500 且部门编号为
20 的员工,代码如下所示。
emp_df[(emp_df.sal > 3500) & (emp_df.dno == 20)]或者emp_df.query('sal > 3500 and dno == 20')
结果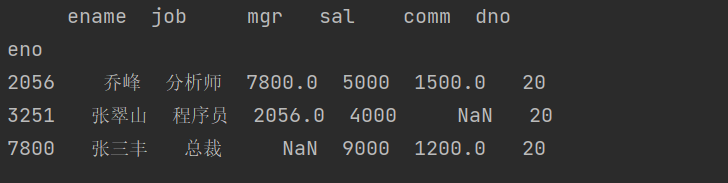
重塑数据
有的时候,我们做数据分析需要的原始数据可能并不是来自一个地方,就像上面的例子中,我们从关系
型数据库中读取了三张表,得到了三个 DataFrame 对象,但实际工作可能需要我们把他们的数据整合到
一起。例如: emp_df 和 emp2_df 其实都是员工的数据,而且数据结构完全一致,我们可以使用
pandas 提供的 concat 函数实现两个或多个 DataFrame 的数据拼接,代码如下所示。
all_emp_df = pd.concat([emp_df, emp2_df])print(all_emp_df)
结果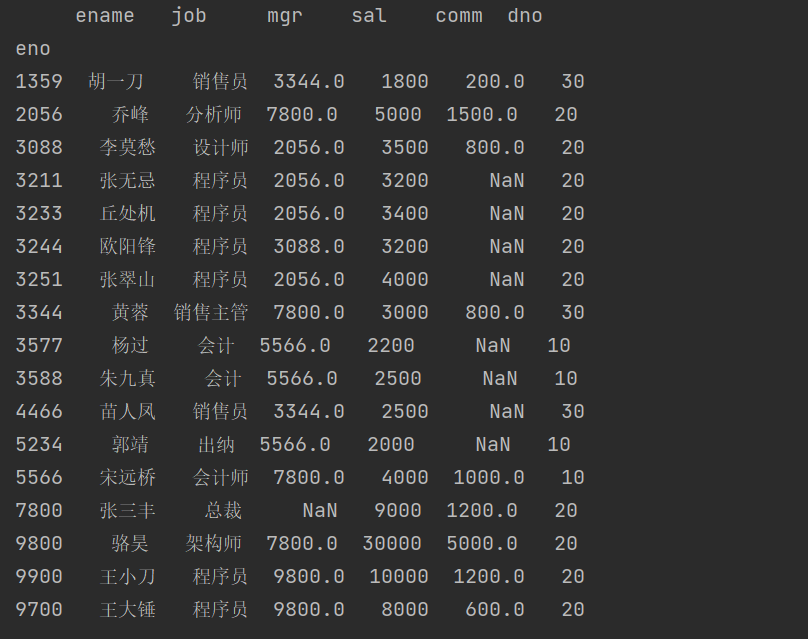
上面的代码将两个代表员工数据的 DataFrame 拼接到了一起,接下来我们使用 merge 函数将员工表和部
门表的数据合并到一张表中,代码如下所示。
dept_df = pd.read_sql('select * from tb_dept', conn, index_col='dno')emp_df = pd.read_sql('select * from tb_emp', conn, index_col='eno')emp2_df = pd.read_sql('select * from tb_emp2', conn, index_col='eno')all_emp_df = pd.concat([emp_df, emp2_df])all_emp_df.reset_index(inplace=True)#先使用 reset_index 方法重新设置 all_emp_df 的索引,这样 eno 不再是索引而是一个普通列,reset_index 方法的 inplace 参数设置为 True 表示,重置索引的操作直接在 all_emp_df 上执行,而不是返回修改后的新对象。print(pd.merge(dept_df, all_emp_df, how='inner', on='dno'))
结果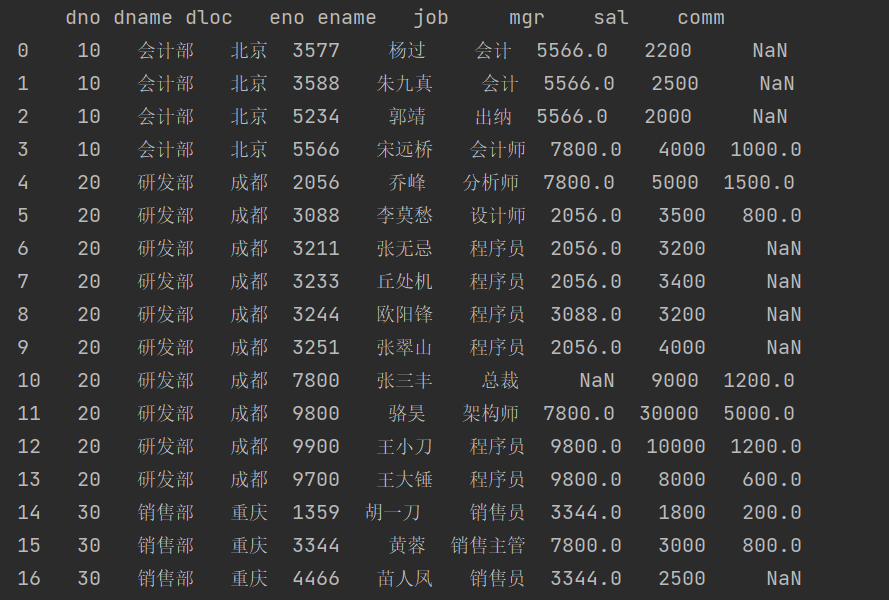
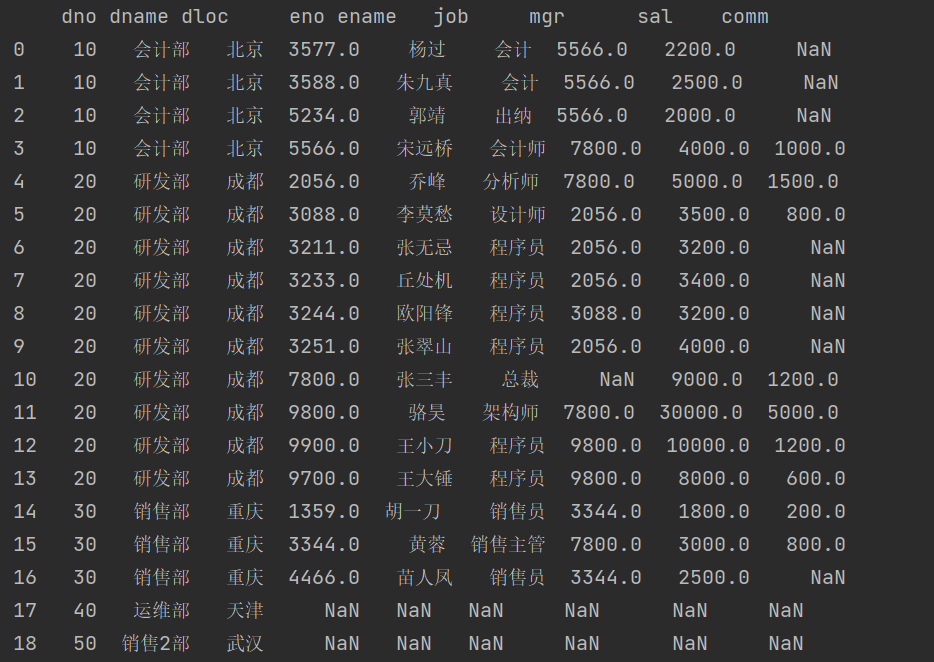
如果对上面的代码稍作修改,将 how 参数修改为 left ,大家可以思考一下代码执行的结果。
运行结果比之前的输出多出了如下所示的一行,这是因为 left 代表左外连接,也就意味着左表
dept_df 中的数据会被完整的查出来,但是在 all_emp_df 中又没有编号为 40 部门的员工,所以对应
的位置都被填入了空值。
print(pd.merge(dept_df, all_emp_df, how='left', on='dno'))

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}
{kind=link}
{kind=link}