Redux 正解
说起Flux,之前曾写过一篇《ReFlux细说》的文章,重点对比讲述了Flux的另外两种实现形式:『Facebook Flux vs Reflux』,有兴趣的同学可以一并看看。
时过境迁,现在社区里,Redux的风头早已盖过其他Flux,它与React的组合使用更是大家所推荐的。
Redux很火,很流行,并不是没有道理!!它本身灵感来源于Flux,但却不局限于Flux,它还带来了一些新的概念和思想,集成了immutability的同时,也促成了Redux自身生态圈。
笔者在看完redux和react-redux源码后,觉得它的一些思想和原理拿出来聊一聊,会更有利于使用者的了解和使用Redux。
(注:如果你是初学者,可以先阅读一下Redux中文文档,了解Redux基础知识。)
数据流
作为Flux的一种实现形式,Redux自然保持着数据流的单向性,用一张图来形象说明的话,可以是这样:
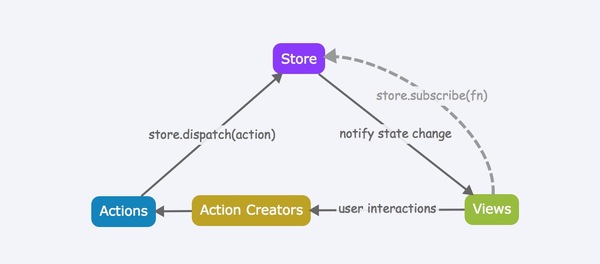
上面这张图,在展现单向数据流的同时,还为我们引出了几个熟悉的模块:Store、Actions、Action Creators、以及Views。
相信大家都不会陌生,因为它们就是Flux设计模式中所提到的几个重要概念,在这里,Redux沿用了它们,并在这基础之上,又融入了两个重要的新概念:Reducers和Middlewares(稍后会讲到)。
接下来,我们先说说Redux在已有概念上的一些变化,之后再聊聊Redux带来的几个新概念。
Store
Store — 数据存储中心,同时连接着Actions和Views(React Components)。
连接的意思大概就是:
Store需要负责接收Views传来的Action
然后,根据Action.type和Action.payload对Store里的数据进行修改
最后,Store还需要通知Views,数据有改变,Views便去获取最新的Store数据,通过
setState进行重新渲染组件(re-render)。
上面这三步,其实是Flux单向数据流所表达出来的思想,然而要实现这三步,才是Redux真正要做的工作。
下面,我们通过答疑的方式,来看看Redux是如何实现以上三步的?
问:Store如何接收来自Views的Action?
答:每一个Store实例都拥有dispatch方法,Views只需要通过调用该方法,并传入action对象作为形参,Store自然就就可以收到Action,就像这样:
store.dispatch({type: 'INCREASE'});
问:Store在接收到Action之后,需要根据Action.type和Action.payload修改存储数据,那么,这部分逻辑写在哪里,且怎么将这部分逻辑传递给Store知道呢?
答:数据修改逻辑写在Reducer(一个纯函数)里,Store实例在创建的时候,就会被传递这样一个reducer作为形参,这样Store就可以通过Reducer的返回值更新内部数据了,先看一个简单的例子(具体的关于reducer我们后面再讲):
// 一个reducerfunction counterReducer(state = 0, action) {switch (action.type) {case 'INCREASE':return state + 1;case 'DECREASE':return state - 1;default:return state;}}// 传递reducer作为形参let store = Redux.createStore(counterReducer);
问:Store通过Reducer修改好了内部数据之后,又是如何通知Views需要获取最新的Store数据来更新的呢?
答:每一个Store实例都提供一个subscribe方法,Views只需要调用该方法注册一个回调(内含setState操作),之后在每次dispatch(action)时,该回调都会被触发,从而实现重新渲染;对于最新的Store数据,可以通过Store实例提供的另一个方法getState来获取,就像下面这样:
let unsubscribe = store.subscribe(() =>console.log(store.getState()));
所以,按照上面的一问一答,Redux.createStore()方法的内部实现大概就是下面这样,返回一个包含上述几个方法的对象:
function createStore(reducer, initialState, enhancer) {var currentReducer = reducervar currentState = initialStatevar listeners = []// 省略若干代码//...// 通过reducer初始化数据dispatch({ type: ActionTypes.INIT })return {dispatch,subscribe,getState,replaceReducer}}
总结归纳几点:
Store的数据修改,本质上是通过Reducer来完成的。
Store只提供get方法(即getState),不提供set方法,所以数据的修改一定是通过
dispatch(action)来完成,即:action -> reducers -> storeStore除了存储数据之外,还有着
消息发布/订阅(pub/sub)的功能,也正是因为这个功能,它才能够同时连接着Actions和Views。dispatch方法 对应着 pub
subscribe方法 对应着 sub
Reducer
Reducer,这个名字来源于数组的一个函数 — reduce,它们俩比较相似的地方在于:接收一个旧的prevState,返回一个新的nextState。
在上文讲解Store的时候,得知:Reducer是一个纯函数,用来修改Store数据的。
这种修改数据的方式,区别于其他Flux,所以我们疑惑:通过Reducer修改数据给我们带来了哪些好处?
这里,我列出了两点:
数据拆解
数据不可变(immutability)
数据拆解
Redux有一个原则:单一数据源,即:整个React Web应用,只有一个Store,存储着所有的数据。
这个原则,其实也不难理解,倘若多个Store存在,且Store之间存在数据关联的情况,处理起来往往会是一件比较头疼的事情。
然而,单一Store存储数据,就有可能面临着另一个问题:数据结构嵌套太深,数据访问变得繁琐,就像下面这样:
let store = {a: 1,b: {c: true,d: {e: [2, 3]}}};// 增加一项: 4store.b.d.e = [...store.b.d.e, 4]; // es7 spreadconsole.log(store.b.d.e); // [2, 3, 4]
这样的store.b.d.e数据访问和修改方式,对于刚接手的项目,或者不清楚数据结构的同学,简直是晴天霹雳!!
为此,Redux提出通过定义多个reducer对数据进行拆解访问或者修改,最终再通过combineReducers函数将零散的数据拼装回去,将是一个不错的选择!
在JavaScript中,数据源其实就是一个object tree,object中的每一个key都可以认为是tree的一个节点,每一个叶子节点都含有一个value(非plain object),就像下面这张图所描述的:
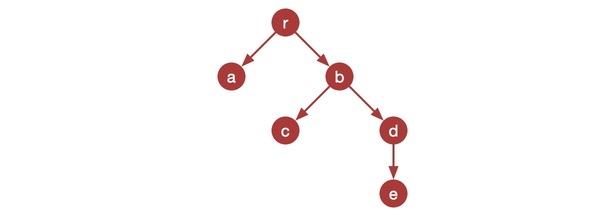
而我们对数据的修改,其实就是对叶子节点value的修改,为了避免每次都从tree的根节点r开始访问,可以为每一个叶子节点创建一个reducer,并将该叶子节点的value直接传递给该reducer,就像下面这样:
// state 就是store.b.d.e的值// [2, 3]为默认初始值function eReducer(state = [2, 3], action) {switch (action.type) {case 'ADD':return [...state, 4]; // 修改store.b.d.e的值default:return state;}}
如此,每一个reducer都将直接对应数据源(store)的某一个字段(如:store.b.d.e),这样的直接的修改方式会变得简单很多。
拆解之后,数据就会变得零散,要想将修改后的数据再重新拼装起来,并统一返回给store,首先要做的就是:将一个个reducer自上而下一级一级地合并起,最终得到一个rootReducer。
合并reducer时,需要用到Redux另一个api:combineReducers,下面这段代码,是对上述store的数据拆解:
import { combineReducers } from 'redux';// 叶子reducerfunction aReducer(state = 1, action) {/*...*/}function cReducer(state = true, action) {/*...*/}function eReducer(state = [2, 3], action) {/*...*/}const dReducer = combineReducers({e: eReducer});const bReducer = combineReducers({c: cReducer,d: dReducer});// 根reducerconst rootReducer = combineReducers({a: aReducer,b: bReducer});
这样的话,rootReducer的返回值就是整个object tree。
总结一点:Redux通过一个个reducer完成了对整个数据源(object tree)的拆解访问和修改。
数据不可变
React在利用组件(Component)构建Web应用时,其实无形中创建了两棵树:虚拟dom树和组件树,就像下图所描述的那样(原图):
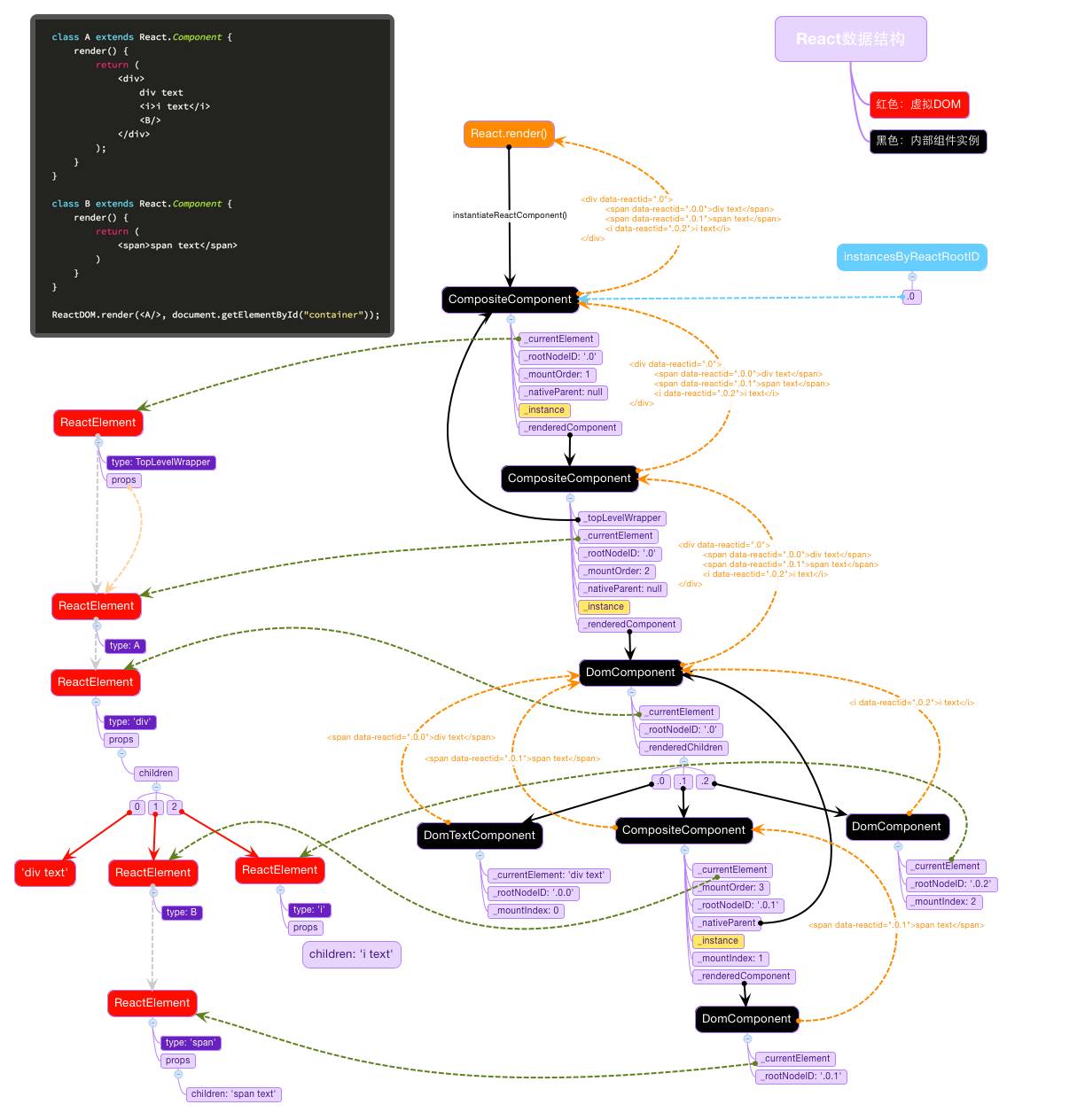
所以,针对这样的树状结构,如果有数据更新,使得某些组件应该得到重新渲染(re-render)的话,比较推荐的方式就是:自上而下渲染(top-down rendering),即顶层组件通过props传递新数据给子孙组件。
然而,每次需要更新的组件,可能就是那么几个,但是React并不知道,它依然会遍历执行每个组件的render方法,将返回的newVirtualDom和之前的prevVirtualDom进行diff比较,然后最后发现,计算结果很可能是:该组件所产生的真实dom无需改变!/(ㄒoㄒ)/~~(无用功导致的浪费性能)
所以,为了避免这样的性能浪费,往往我们都会利用组件的生命周期函数shouldComponentUpdate进行判断是否有必要进行对该组件进行更新(即,是否执行该组件render方法以及进行diff计算)?
就像这样:
shouldComponentUpdate(nextProps) {if (nextProps.e !== this.props.e) { // 这里的e是一个字段,可能是对象引用,也可能是数值,布尔值return true; // 需要更新}return false; // 无需更新}
但,往往这样的比较,对于字面值还行,对于对象引用(object,array),就糟糕了,因为:
let prevProps = {e: [2, 3]};let nextProps = prevProps;nextProps.e.push(4);console.log(prevProps.e === nextProps.e); // 始终为true
虽然你可以通过deepEqual来解决这个问题,但对嵌套较深的结构,性能始终会是一个问题。
所以,最后对于对象引用的比较,就引出了不可变数据(immutable data)这个概念,大体的意思就是:一个数据被创建了,就不可以被改变(mutation)。
如果你想改变数据,就得重新创建一个新的数据(即新的引用),就像这样:
let prevProps = {e: [2, 3]};let nextProps = {e:[...prevProps.e, 4] // es7 spread};console.log(prevProps.e === nextProps.e); // false
也许,你已经发现每个Reducer函数在修改数据的时候,正是这样做的,最后返回的都是一个新的引用,而不是直接修改引用的数据,就像这样:
function eReducer(state = [2, 3], action) {switch (action.type) {case 'ADD':return [...state, 4]; // 并没有直接地通过state.push(4),修改引用的数据default:return state;}}
最后,因为combineReducers的存在,之前的那个object tree的整体数据结构就会发生变化,就像下面这样:
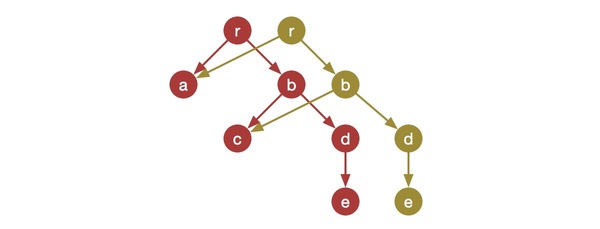
现在,你就可以在shouldComponentUpdate函数中,肆无忌惮地比较对象引用了,因为数据如果变化了,比较的就会是两个不同的对象!
总结一点:Redux通过一个个reducer实现了不可变数据(immutability)。
PS:当然,你也可以通过使用第三方插件(库)来实现immutable data,比如:React.addons.update、Immutable.js。(只不过在Redux中会显得那么没有必要)。
Middleware
Middleware — 中间件,最初的思想毫无疑问来自:Express。
中间件讲究的是对数据的流式处理,比较优秀的特性是:链式组合,由于每一个中间件都可以是独立的,因此可以形成一个小的生态圈。
在Redux中,Middlerwares要处理的对象则是:Action。
每个中间件可以针对Action的特征,可以采取不同的操作,既可以选择传递给下一个中间件,如:next(action),也可以选择跳过某些中间件,如:dispatch(action),或者更直接了当的结束传递,如:return。
标准的action应该是一个plain object,但是对于中间件而言,action还可以是函数,也可以是promise对象,或者一个带有特殊含义字段的对象,但不管怎样,因为中间件会对特定类型action做一定的转换,所以最后传给reducer的action一定是标准的plain object。
比如说:
[redux-thunk]里的action可以是一个函数,用来发起异步请求。
[redux-promise]里的action可以是一个promise对象,用来更优雅的进行异步操作。
[redux-logger]里的action就是一个标准的plain object,用来记录action和nextState的。
一个自定义中间件:延迟action的执行,这里就存在一个特殊字段:
action.meta.delay,具体如下:
// 用 { meta: { delay: N } } 来让 action 延迟 N 毫秒。const timeoutScheduler = store => next => action => {if (!action.meta || !action.meta.delay) {return next(action)}let timeoutId = setTimeout(() => next(action),action.meta.delay)return function cancel() {clearTimeout(timeoutId)}}
那么问题来了,这么多的中间件,如何使用呢?
先看一个简单的例子:
import { createStore, applyMiddleware } from 'redux';import thunk from 'redux-thunk';import createLogger from 'redux-logger';import rootReducer from '../reducers';// store扩展const enhancer = applyMiddleware(thunk,createLogger());const store = createStore(rootReducer, initialState, enhancer);// 触发actionstore.dispatch({type: 'ADD',num: 4});
注意:单纯的Redux.createStore(...)创建的Store实例,在执行store.dispatch(action)的时候,是不会执行中间件的,只是单纯的action分发。
要想给Store实例附加上执行中间件的能力,就必须改造createStore函数,最新版的Redux是通过传入store扩展(store enhancer)来解决的,而具有中间件功能的store扩展,则需要使用applyMiddleware函数生成,就像下面这样:
// store扩展const enhancer = applyMiddleware(thunk,createLogger());const store = createStore(rootReducer, initialState, enhancer);
上面的写法是新版Redux才有的,以前的写法则是这样的(新版兼容的哦):
// 旧写法const createStoreWithMiddleware = applyMiddleware(thunk,createLogger())(createStore);const store = createStoreWithMiddleware(reducer, initialState)
至于改造后的createStore方法为何拥有了执行中间件的能力,大家可以看一下appapplyMiddleware的源码。
最后,简单用一张图来验证一句话的正确性:中间件提供的是位于 action 被发起之后,到达 reducer 之前的扩展点。
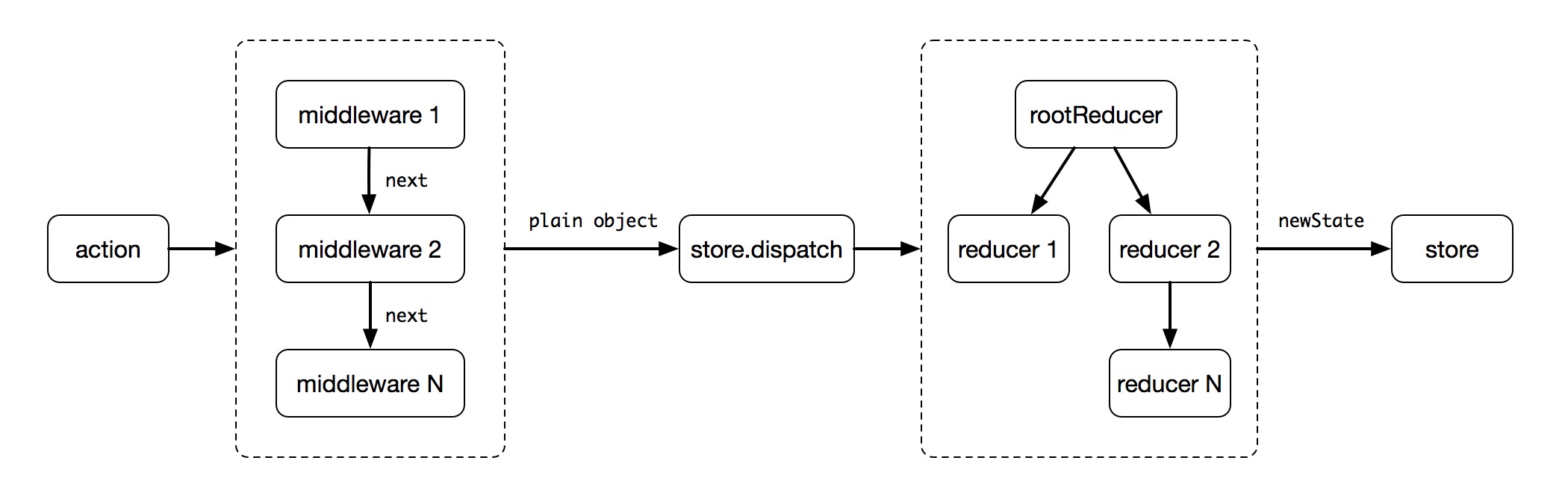
react-redux
为了让Redux能够更好地与React配合使用,react-redux库的引入就显得必不可少。
react-redux主要暴露出两个api:
Provider组件
connect方法
Provider
Provider存在的意义在于:想通过context的方式将唯一的数据源store传递给任意想访问的子孙组件。
比如,下面要说的connect方法在创建Container Component时,就需要通过这种方式得到store,这里就不展开说了。
不熟悉React context的同学,可以看看官方介绍。
connect
Redux中的connect方法,跟Reflux.connect方法有点类似,最主要的目的就是:让Component与Store进行关联,即Store的数据变化可以及时通知Views重新渲染。
下面这段源码(来自connect.js),能够说明上述观点:
trySubscribe() {if (shouldSubscribe && !this.unsubscribe) {// 跟store关联,消息订阅this.unsubscribe = this.store.subscribe(this.handleChange.bind(this))this.handleChange()}}handleChange() {if (!this.unsubscribe) {return}const prevStoreState = this.state.storeStateconst storeState = this.store.getState()if (!pure || prevStoreState !== storeState) {this.hasStoreStateChanged = truethis.setState({ storeState }) // 组件重新渲染}}
另外,connect方法,还引出了另外两个概念,即:容器组件(Container Component)和展示组件(Presentational Component)。
感兴趣的同学,可以看下这篇文章《Presentational and Container Components》,了解两者的区别,这里就不展开讨论了。

若有收获,就点个赞吧
0 人点赞
