HTTP 入门
HTTP,全称“超文本传输协议(HyperText Transfer Protocol)”,是构建今天所熟知的万维网的基础,也是在访问互联网时最常见的一种协议类型。
在打开一个网页的时候通常都会注意到网址的前面有一个统一的标识“http://”(或“https://”,本文不予讨论),这代表的就是“本次访问使用 HTTP 协议进行通信”。
那么问题来了:为什么在通信的时候要用到这个协议呢?
简单来讲,所谓“协议”其实就是一个规范、一个标准,大家共同遵守。通信双方通过使用统一的规范,能够有效地将信息结构化,让相应的信息各归其位,正是“上帝的归上帝,凯撒的归凯撒”。这样一来就可以大大地降低信息传输的成本。
1、协议的必要性
假设一下,如果在因特网上传输信息的时候不遵守某个协议,会出现什么情况呢?最直接的影响就是鸡同鸭讲。
设想几个简单的情况。
两个人交流的时候。A 说:“小B,你去帮我取一下资料,三楼档案室。” B 回复说:“好嘞哥,收到。”这段对话一切正常。
但机器之间通信,不像人类可以依靠双耳效应定位声源、可以靠音色来确定对象,机器的语言就是电流,准确地说就是高低电平。一段消息发出之后,这段信号就会淹没在电信号的汪洋大海中,再也无法直接确定它的发送者、接收者,如果在消息中不增加额外的信息,很显然这段消息就等于废了。
在其中增加一些可能需要的信息。
主机 A 说:“小 B 小 B,呼叫小 B。我是小 A,我是小 A。给我一下你这儿 /home 目录下面的图片justdo.png。小 B 你行不?”
主机 B 说:“小 B 收到,小 B 收到。小 A 你这也太小看我了,毫秒钟妥妥的。等下传给你啊。”
这两段对话对于人类来讲还算容易理解,其中的关键信息也很容易提取,比如第一条语句的发送者是小 A,接收者是小 B;第二条语句的发送者是小 B,接收者是小 A。
但是关心的是机器能够完整、准确地提取出这些信息吗?显然,即便是以当前的自然语言处理技术,也很难保证 100% 的准确率,因为不知道发出或者收到的会是一条长成什么样儿的消息。
有了协议就好办了。比如现在就可以规定一个 JUSTDO 协议:机器通信的时候,要按照“发送方:XX;接收方:XX;正文:XXXX”的格式来传输信息。因此上面那段机器之间的对话可以根据这个协议规范如下:
主机 A 说:“发送方:A;接收方:B;正文:B 中 /home 目录下的图片 justdo.png。”
主机 B 说:“发送方:B;接收方:A;正文:收到。稍后传送。”
对机器来说,这样规范过的信息就要友好多了。
编程时一个宏伟的愿景当然是“让写程序成为人类友好的趣事”;但在当前技术条件下,出于性能、安全等各方面的考虑,程序员们很多时候不得不向机器妥协。人类友好和机器友好的权衡取舍,称得上是计算机历史上自古以来的老大难问题了。
当然,大家都能看得出来,上面的例子中依然存在很多问题。这里只是举了一个简单的例子,以此来说明在通信中使用协议的必要性(相信学通信的同学深有体会),HTTP 本身比在这里举的一个不伦不类的协议要复杂和完善得多。
接下来让先来热个身。
2、什么是 URL
这一节与 HTTP 关系不大,但考虑到可能会有对 URL 不太清楚的读者阅读到这篇文章,因此略作讲解。懂的同学请跳过。
URL(Uniform Resource Locator)即“统一资源定位符”。就是字面意思,“统一”的意思就是普天之下,情同此理,人同此形,互联网上只要能被访问到的资源都有这么一个长得大同小异的符号标识。“资源”嘛,就更好理解了,只要是可以独立存在的集合都可以被称作是资源,什么文本、图片、音乐、视频,一逮一个准儿。“定位”嘛,就是定位的意思咯,给你一个“四川省成都市青羊区青华路 37 号”的地址,你能比划着找着杜甫草堂没?一样的嘛。
也就是说,无论你要访问互联网上的什么东西,只要给你这么一个对应的 URL,你都能把他给找出来。哈哈,是不是有种“天下英雄入吾彀中矣”的豪迈?
除了 URL,还有一个 URI(Uniform Resource Identifier,统一资源标识符)的概念。URL 是 URI 的真子集;也就是说一个 URL 一定是 URI,但一个 URI 不一定是 URL。在浏览器访问网页的时候,多数常见的情况下看到的 URI 都是 URL。
简单地说,如果某个 URL 指定的文件就在与客户端直接通信的主机上,那么只需使用文件在该主机上的绝对路径即可区别这个文件;此时的 URI 就可以是这个绝对路径,比对应的 URL 更加简短。但如果与客户端直接通信的主机仅仅是一个代理(简单理解为中转),此时只使用绝对路径是不够的,还需要指明是哪台主机,这样代理才能够找到这台主机进而找到这个文件;这种情况下,URI 和 URL 就是相等的了。
下面以自己的博客为例,具体讲解一下 URL。博客上有这么一个页面:
它对应的 URL 就是 http://www.justdopython.com/2019/04/04/writing-specifications/ ,按照 URL 的统一格式可以分解如下:
其中,第一部分的“http”表明使用的是 HTTP 协议进行通信。第三部分“www.justdopython.com”称为“域名”,可以简单地理解为互联网上的某一台主机(实际情况要更复杂),也就是一个跟你手头的电脑差不多的玩意儿。第四部分“/2019/04/04/writing-specifications/”就是请求的资源在这台主机上的路径了,可以看出其路径结构是 / -> 2019/ -> 04/ -> 04/ -> writing-specifications/,这一点容易理解,最后一级目录(Windows 文件夹)就是 writing-specifications。
但这个时候又有问题了:就定位了一个文件夹,那这网页显示的是个啥呀?文件夹不带这个功能啊?
答案很简单。实际上,根据各个 web 服务器设置的不同,它们可以指定某些文件作为不指定具体资源时的默认对象,一般是“index.html”。实际上可以试一试,在这个 URL 的后面加上“index.html”,即访问:http://www.justdopython.com/2019/04/04/writing-specifications/index.html,可以得到相同的结果。
3、HTTP 协议的格式
如前所述,作为一个协议,HTTP 对于消息的格式有严格的要求。
将整个协议划分为两个大类:请求,响应。
3.1 HTTP 请求
一般地,HTTP 协议格式主要分成四个部分:起始行、消息头、空行、消息体;如图所示。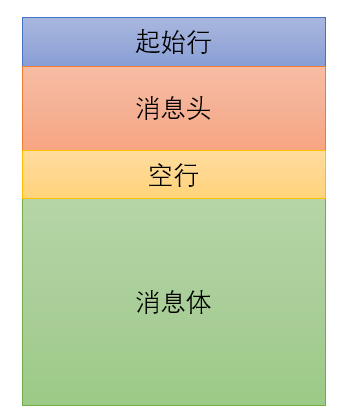
其中,起始行又包含三个信息:方法、URI、HTTP 协议版本。
“方法”指的是本次请求要执行的操作,有时也称“HTTP 谓词”或“HTTP 动词”。常见的方法是GET和POST这两个:GET表示客户端要从服务器获取资源;而POST则表示客户端要想服务器传输一些表单数据。
URI 在前面已经略作讲解,因此不再赘述。一般来说会是一个绝对路径,末尾可以跟上一个问号“?”和查询字符串;当使用代理时,就会是一个完整的 URL。
“HTTP 协议版本”也容易理解,就是字面意思,告知对方自己使用的 HTTP 协议是哪个版本,以免混乱。
起始行最常见的形式类似于下面这样:
GET /just/do/python/logo.png HTTP/1.1
当使用代理时则会变成(该 URL 为虚构):
GET http://www.justdopython.com/just/do/python/logo.png HTTP/1.1
协议格式的第二部分消息头包含一些对消息的描述信息,格式是
第三部分空行,起到的作用是提示消息头结束、消息体开始,不需要再花费笔墨。
第四部分消息体就是正主了,也就是一条 HTTP 消息要传输的主体。然而稍稍有些尴尬的是,对于有的方法而言并不需要传输其他信息,只需要有起始行和消息头就足够了(比如GET方法),因此这个部分不仅不一定是最长的,甚至可能是空的。
3.2 HTTP 响应
与请求消息比较类似,HTTP 响应消息也分为四个部分:状态行、消息头、空行、消息体,如图所示: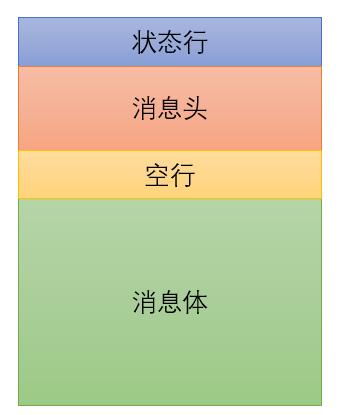
其中后三个部分与 HTTP 请求消息基本一致,因此仅仅着墨状态行。
状态行也由三个部分组成:HTTP 协议版本、状态码、状态文本。其中 HTTP 协议版本无需赘言。
状态码其实很熟悉。最典型的一个就是每当访问的某个 URL 不存在时,就会得到一个404的状态码。因此状态码实际上是用来标识请求成功与否的数字。除了404,典型的状态码还有200(请求成功)、301(资源被永久移动)、302(资源被临时移动)等。
根据第一位数字,状态码大概可以分为 5 种(下表来自《网络是怎样连接的》):
| 状态码 | 含义 |
|---|---|
| 1xx | 告知请求的处理进度和情况 |
| 2xx | 成功 |
| 3xx | 表示需要进一步操作 |
| 4xx | 客户端错误 |
| 5xx | 服务器错误 |
状态文本则是一条简短、纯粹的信息,描述的是状态码代表的实际状态,是为了便于人机交互。
因此一个典型的状态行可能长成这样:
HTTP/1.1 404 Not Found
当客户端使用GET方法向服务器请求了一个网页,此时如果请求成功,服务器的 HTTP 响应消息的消息体就会包含该网页的 HTML 文本。
3.3 HTTP/2
HTTP/2 仅仅是在 HTTP/1.x 的基础上附加了一个步骤,在使用时无需更改 HTTP/1.x 的协议格式。
4、参考资料

若有收获,就点个赞吧
0 人点赞
