分析
1.准备三台客户机(关闭防火墙、静态IP、主机名称)
2.安装jdk
3.安装Hadoop
4.配置环境变量
5.配置集群
6.单点启动
7.配置ssh
8.群起并测试集群
1、虚拟机准备
2、安装包分发脚本
分发的文件和操作
1.分发的文件
/opt/目录下的Software(JDK的安装包和Hadoop的安装包)和Module(解压的JDK和Hadoop)
/etc/profile系统环境变量的配置文件
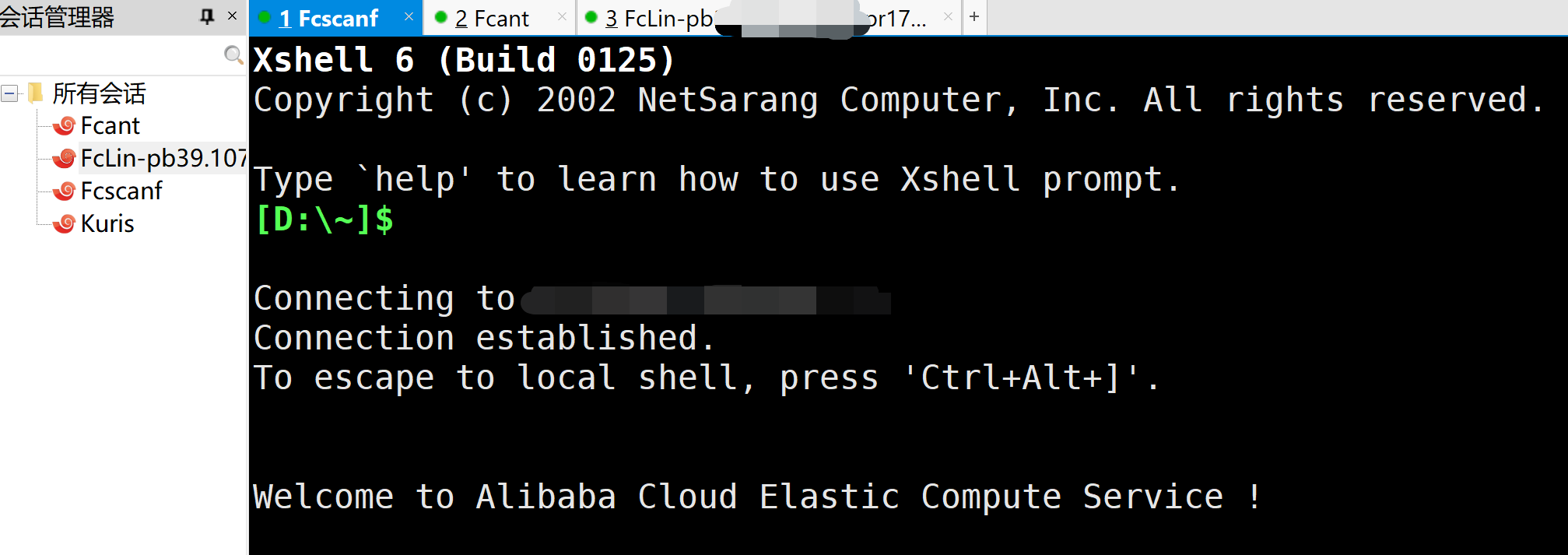
# 使用一台机器进行配置文件的分发[root@iZuligp6e1dyzfZ ~]# scp -r /etc/profile root@39.107.49.210:/etc/profileroot@39.107.49.210's password:profile 100% 2090 2.0KB/s 00:00[root@iZuligp6e1dyzfZ ~]#
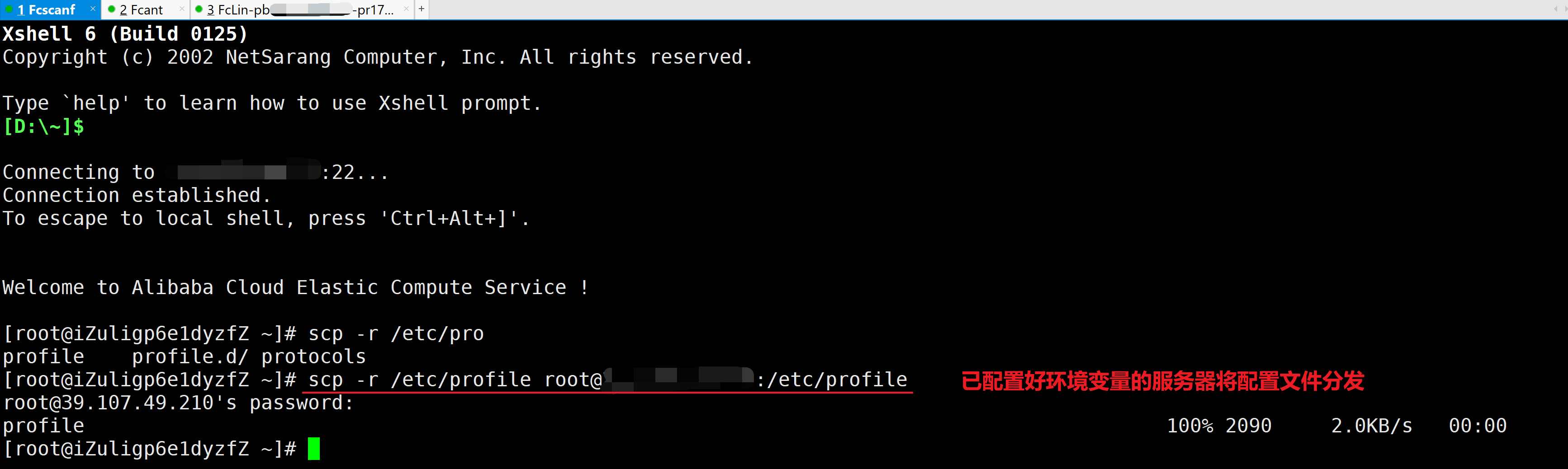
2.对分发的文件进行授权
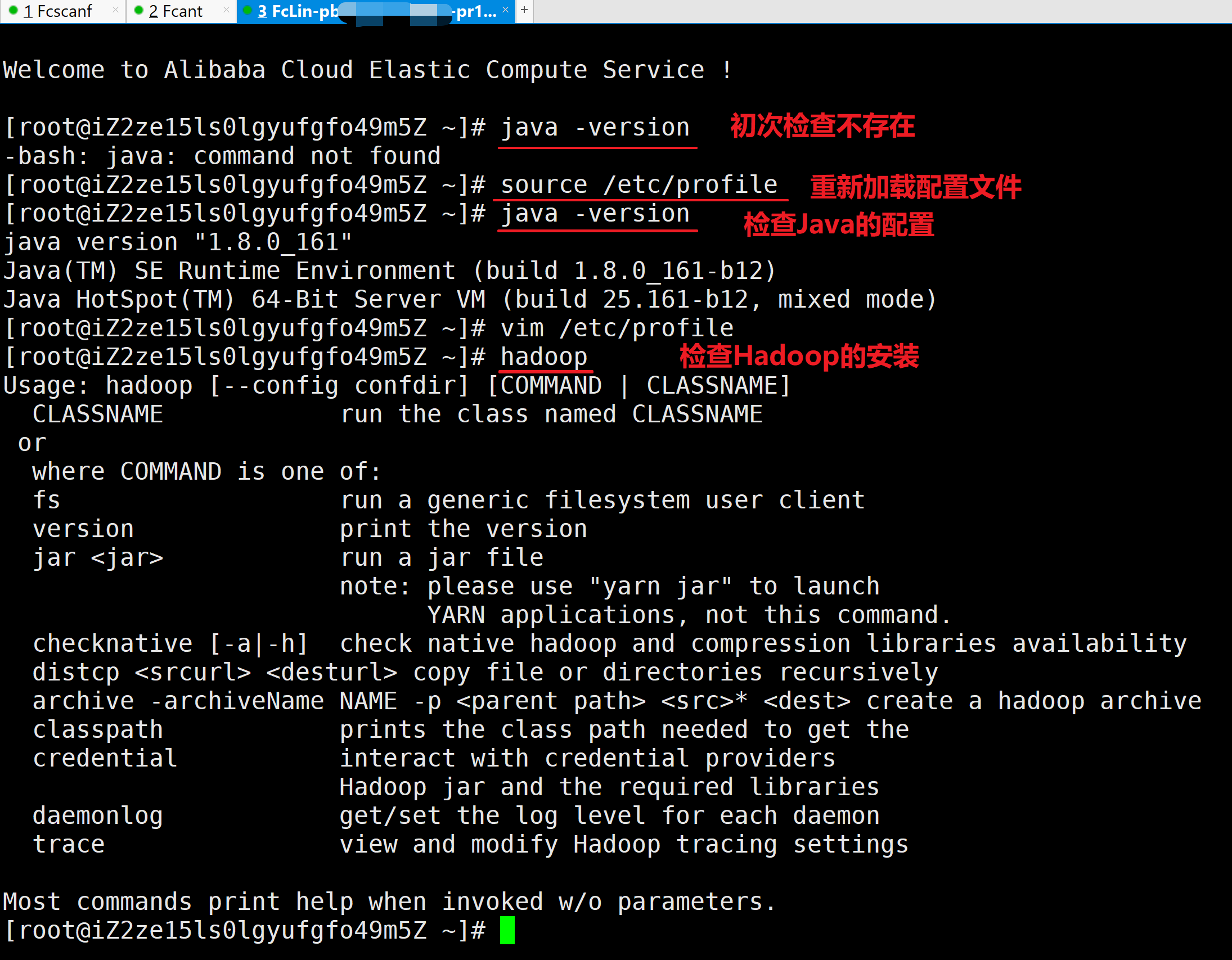
3.生效配置文件和检查安装
通过source /etc/profile来使配置文件生效,并使用Java和Hadoop命令检查安装配置
# 另外两台服务器重新加载配置文件并检查环境变量
[root@iZ2ze15ls0lgyufgfo49m5Z ~]# java -version
-bash: java: command not found
[root@iZ2ze15ls0lgyufgfo49m5Z ~]# source /etc/profile
[root@iZ2ze15ls0lgyufgfo49m5Z ~]# java -version
java version "1.8.0_161"
Java(TM) SE Runtime Environment (build 1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
[root@iZ2ze15ls0lgyufgfo49m5Z ~]# vim /etc/profile
[root@iZ2ze15ls0lgyufgfo49m5Z ~]# hadoop
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar <jar> run a jar file
note: please use "yarn jar" to launch
YARN applications, not this command.
checknative [-a|-h] check native hadoop and compression libraries availability
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
credential interact with credential providers
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
trace view and modify Hadoop tracing settings
Most commands print help when invoked w/o parameters.
[root@iZ2ze15ls0lgyufgfo49m5Z ~]#
A.文件的分发-scp命令的使用
I.scp(secure copy)安全拷贝
II.基本语法
root@Fcant:/# scp -r $pdir/$fname $user@$host:$pdir/$fname

1.从本机将文件分发
[root@iZzvx8pr0tamavZ /]# scp -r /opt/module/ root@39.107.49.210:/opt/module

2.从其他主机拉取文件
[root@iZzvx8pr0tamavZ opt]# scp -r root@120.79.178.68:/opt/module ./

3.从一台主机到另一台主机
[root@iZ2ze15ls0lgyufgfo49m5Z module]# scp -r root@101.132.167.127:/etc/profile root@120.79.178.68:/etc/profile

B.rsync远程同步工具
1.rsync的介绍
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
2.rsync和scp的区别
rsync和scp的区别:用rsync做文件的复制要比scp的速度快,rsync只对文件差异做更新,scp是把所有文件都复制过去。
3.基本语法
root@Fcant:/# rsync -rvl $pdir/$fname $user@$host:$pdir/$fname

| 选项 | 功能 |
|---|---|
| -r | 递归 |
| -v | 显示复制过程 |
| -l | 拷贝符号链接 |
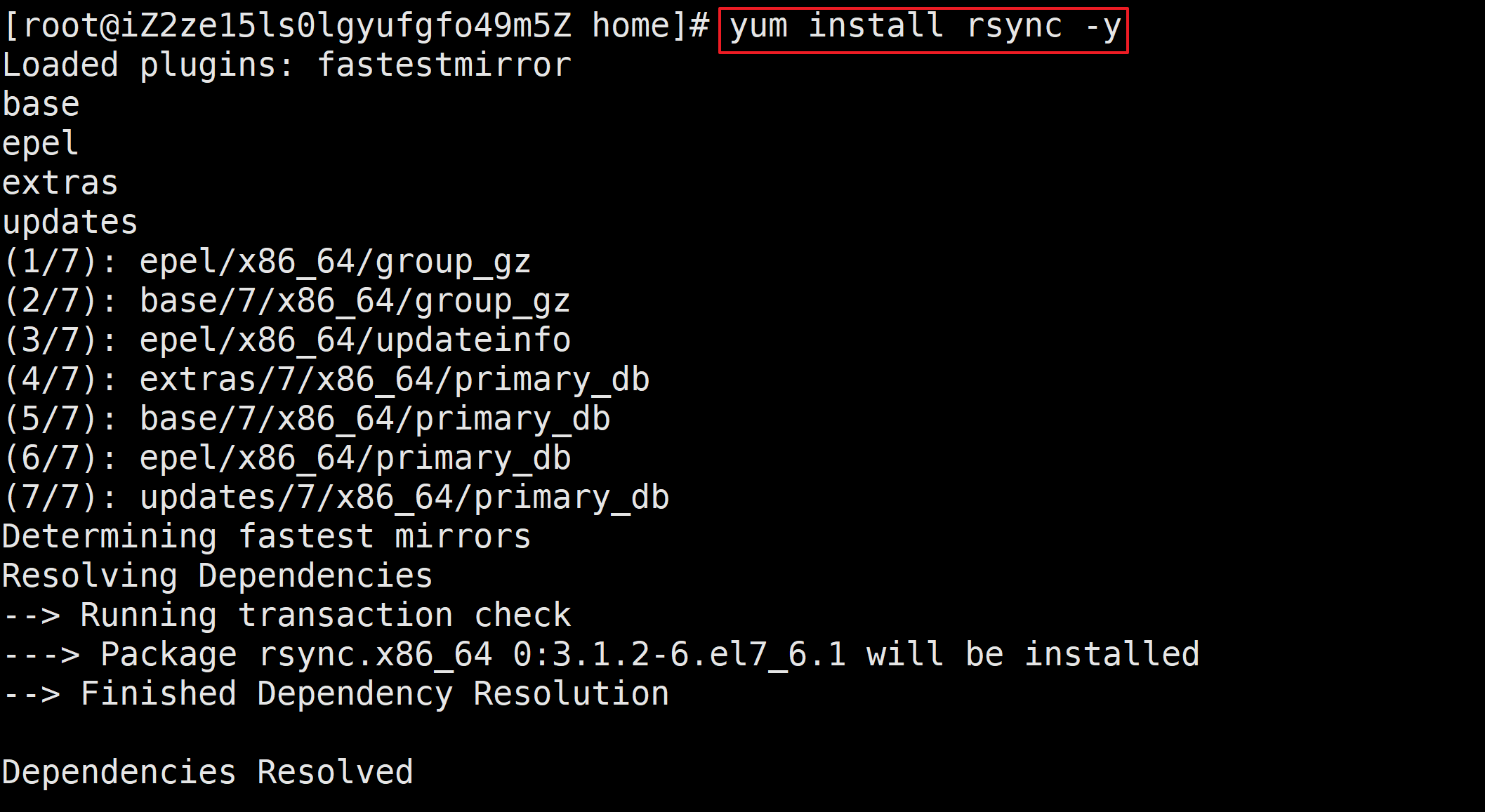
4.rsync下载
[root@iZ2ze15ls0lgyufgfo49m5Z home]# yum install rsync -y
C.xsync集群分发脚本
1.xsync的介绍
2.基本语法
root@Fcant:~# rsync -rvl /opt/module root@$host:/opt/

3.集群分发脚本的内容
#!/bin/bash
#1获取输入参数的个数,如果没有参数,直接退出
pcount=$#
if((pcount==0));then
echo no args;
exit
fi
#2获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4获取当前用户名称
user=`whoami`
#5循环
for((host=103; host<105; host++)); do
echo --------------hadoop$host---------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
#!/bin/bash
#1获取输入参数的个数,如果没有参数,直接退出
pcount=$#
if((pcount==0));then
echo no args;
exit
fi
#2获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4获取当前用户名称
user=`whoami`
#5执行分发
echo ----------------脚本开始分发-----------------
rsync -rvl $pdir/$fname $user@$host:$pdir
echo -----主机Fcant@$host已分发完毕-----
rsync -rvl $pdir/$fname $user@$host:$pdir
echo -----主机FcLin@$host已分发完毕-----
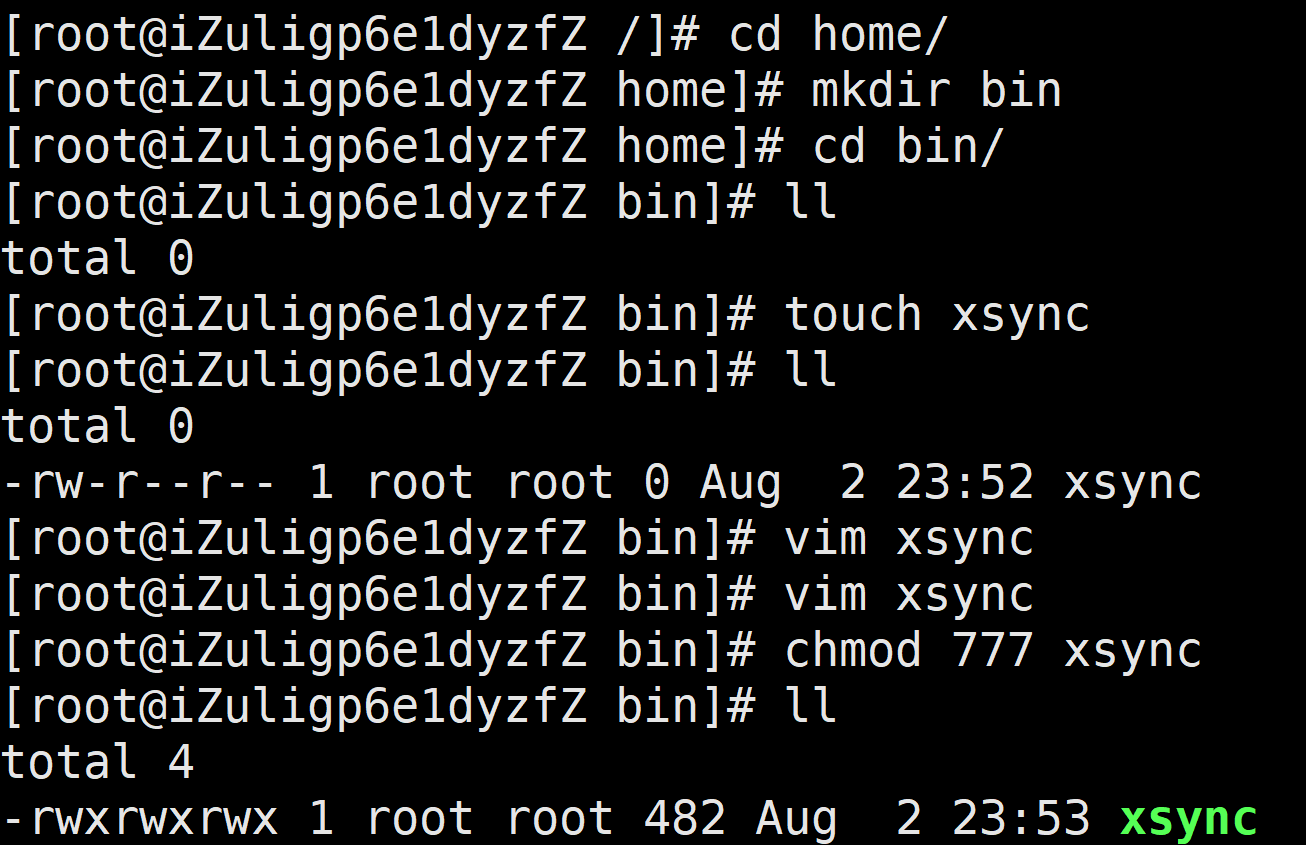
4.修改脚本xsync具有执行权限
[root@iZuligp6e1dyzfZ bin]# chmod 777 xsync

5.调用脚本形式:xsync 文件名称
[root@iZuligp6e1dyzfZ bin]# xsync /home/admin/bin

注意:如果将xsync放到/home/root/bin目录下仍然不能实现全局使用,可以将xsync移动到/usr/local/bin目录下,因为该目录已经挂载在系统的环境变量中
6.执行流程如下
[root@iZuligp6e1dyzfZ /]# cd home/
[root@iZuligp6e1dyzfZ home]# mkdir bin
[root@iZuligp6e1dyzfZ home]# cd bin/
[root@iZuligp6e1dyzfZ bin]# ll
total 0
[root@iZuligp6e1dyzfZ bin]# touch xsync
[root@iZuligp6e1dyzfZ bin]# ll
total 0
-rw-r--r-- 1 root root 0 Aug 2 23:52 xsync
[root@iZuligp6e1dyzfZ bin]# vim xsync
[root@iZuligp6e1dyzfZ bin]# vim xsync
[root@iZuligp6e1dyzfZ bin]# chmod 777 xsync
[root@iZuligp6e1dyzfZ bin]# ll
total 4
-rwxrwxrwx 1 root root 482 Aug 2 23:53 xsync
[root@iZuligp6e1dyzfZ local]# xsync bin/
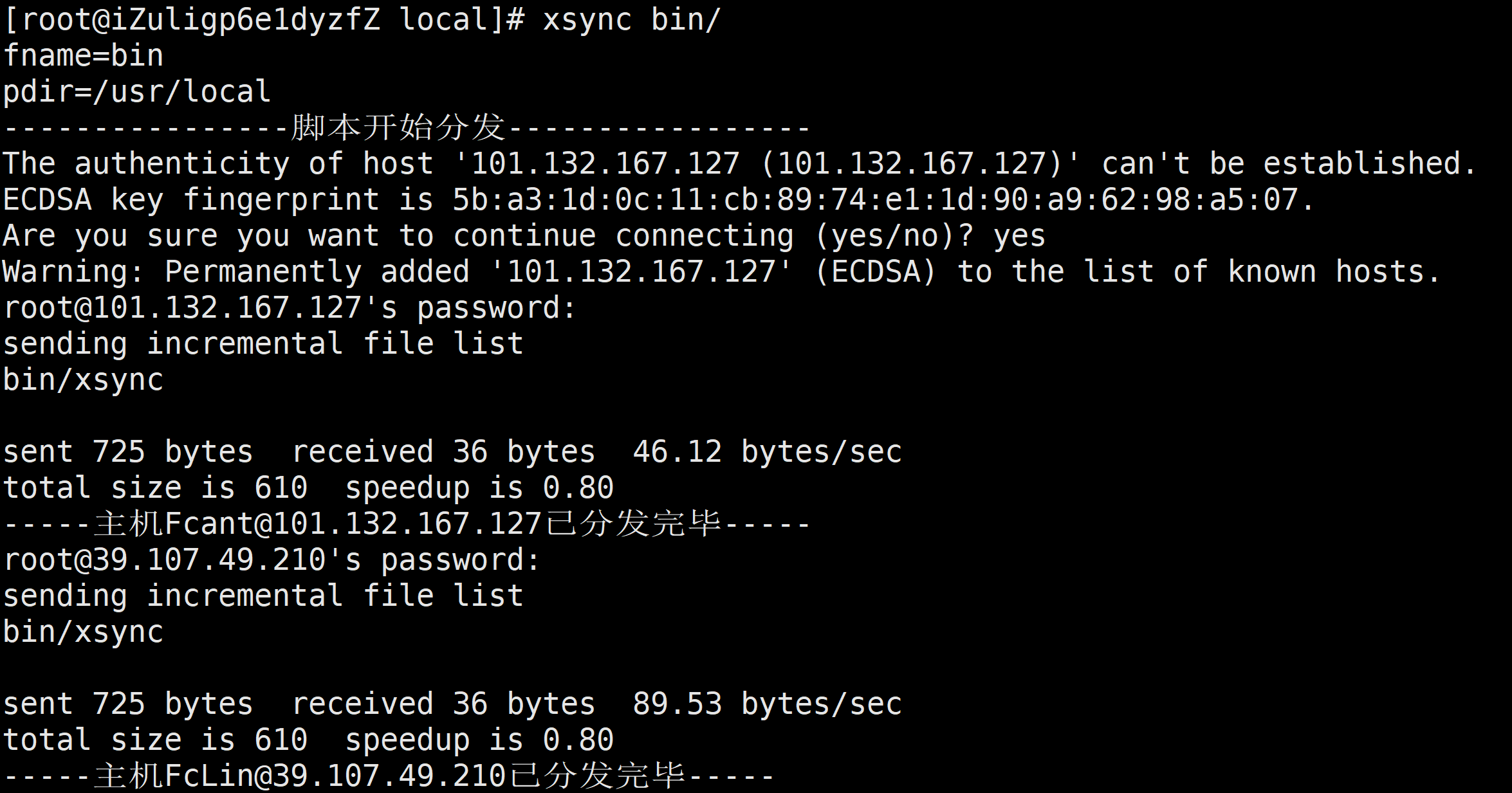
3、集群配置
3.1集群的部署规化
| 主机1 | 主机2 | 主机3 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN | NodeManager |
ResourceManager NodeManager |
NodeManager |
3.2配置集群
1.核心配置文件-主机二进行操作
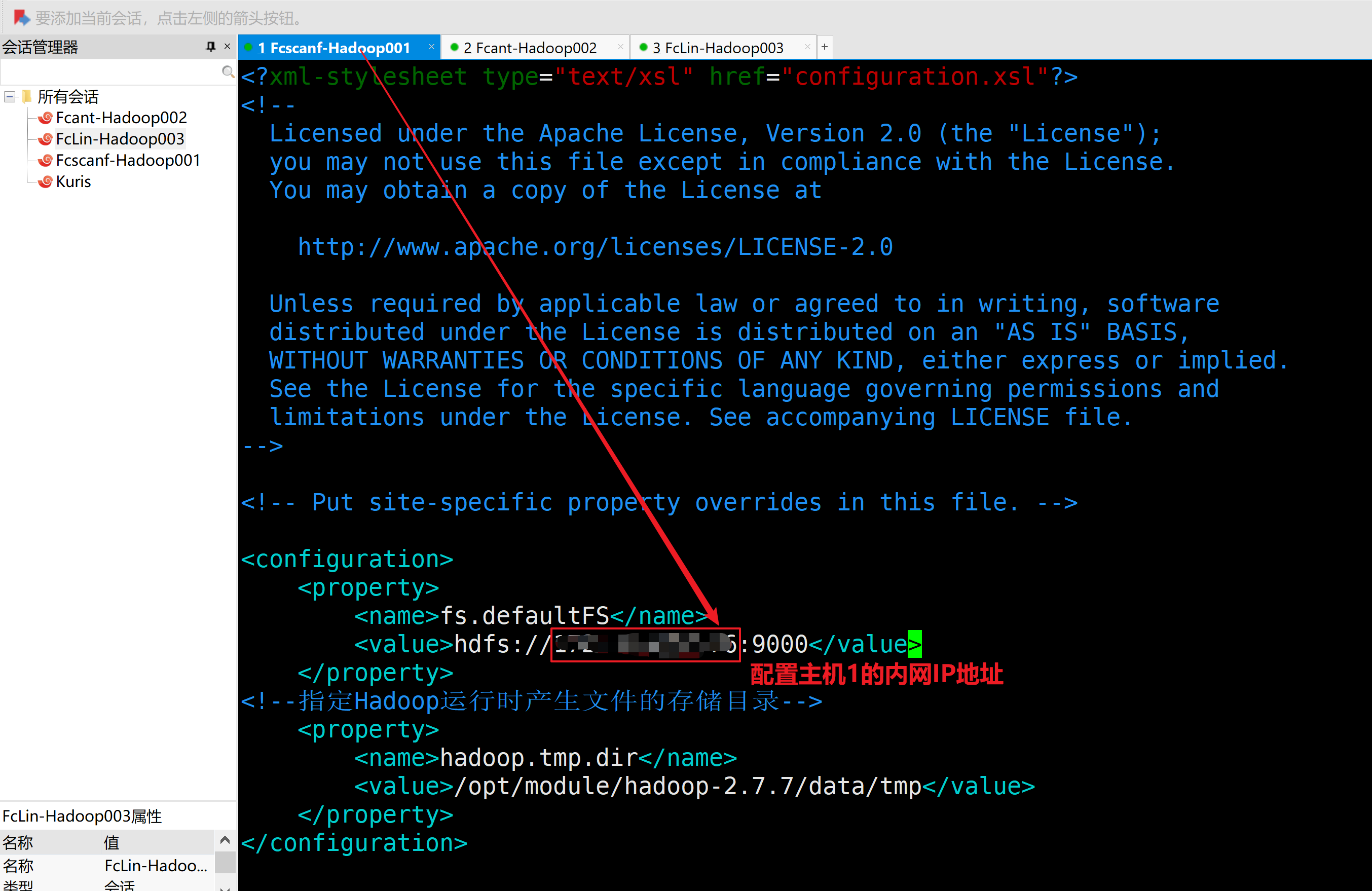
a.配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!--指定Hadoop运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.7/data/tmp</value>
</property>
</configuration>
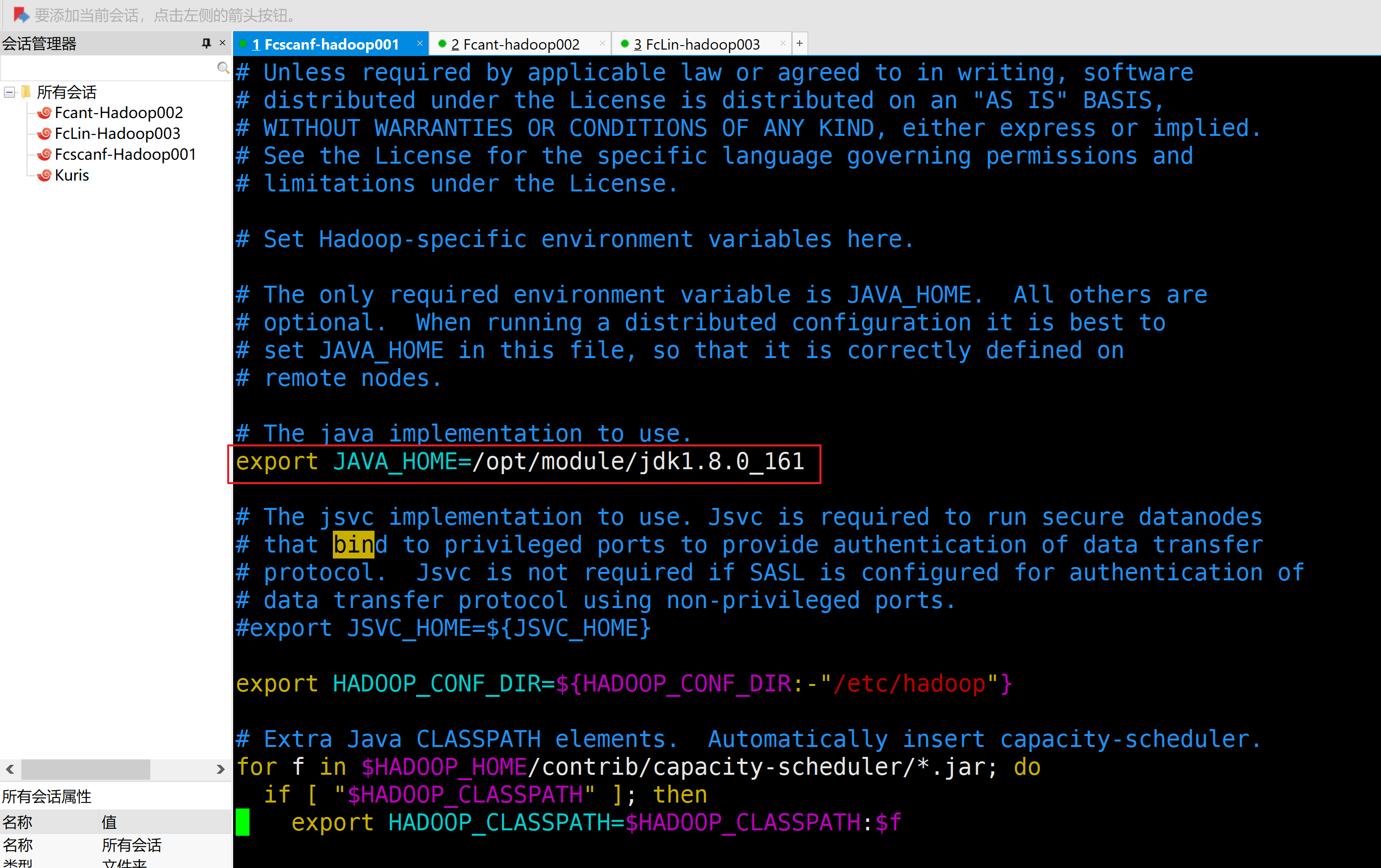
2.HDFS配置文件
a.配置hadoop-env.sh
[root@iZzvx8pr0tamavZ hadoop]# vim hadoop-env.sh
因为此项是从伪分布式拷贝过来的,配置一致,一般检查一下就行
export JAVA_HOME=/opt/module/jdk1.8.0_161
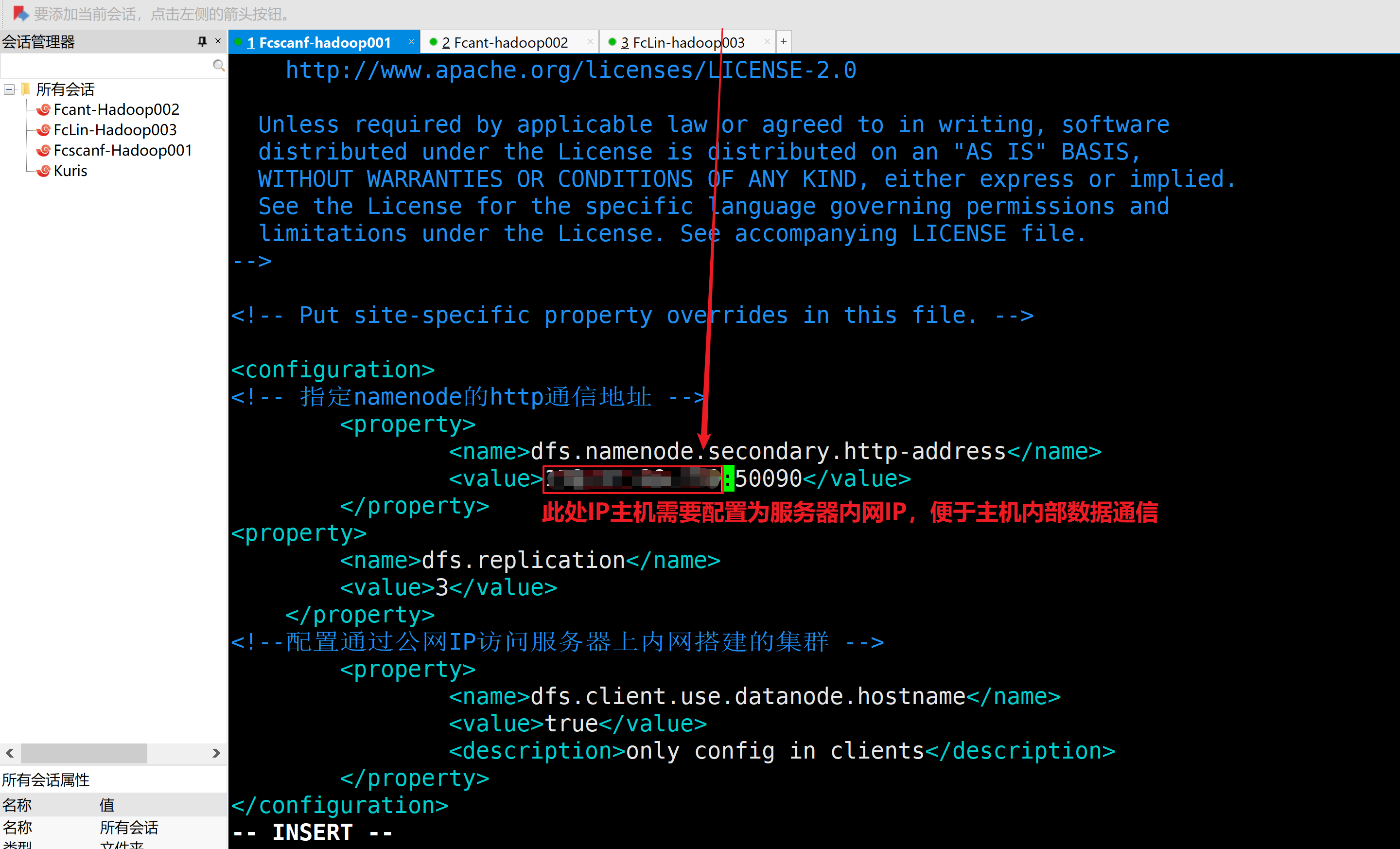
b.配置hdfs-site.xml
<configuration>
<!-- 指定namenode的http通信地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>127.0.0.1:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--配置通过公网IP访问服务器上内网搭建的集群 -->
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
<description>only config in clients</description>
</property>
</configuration>
3.YARN配置文件
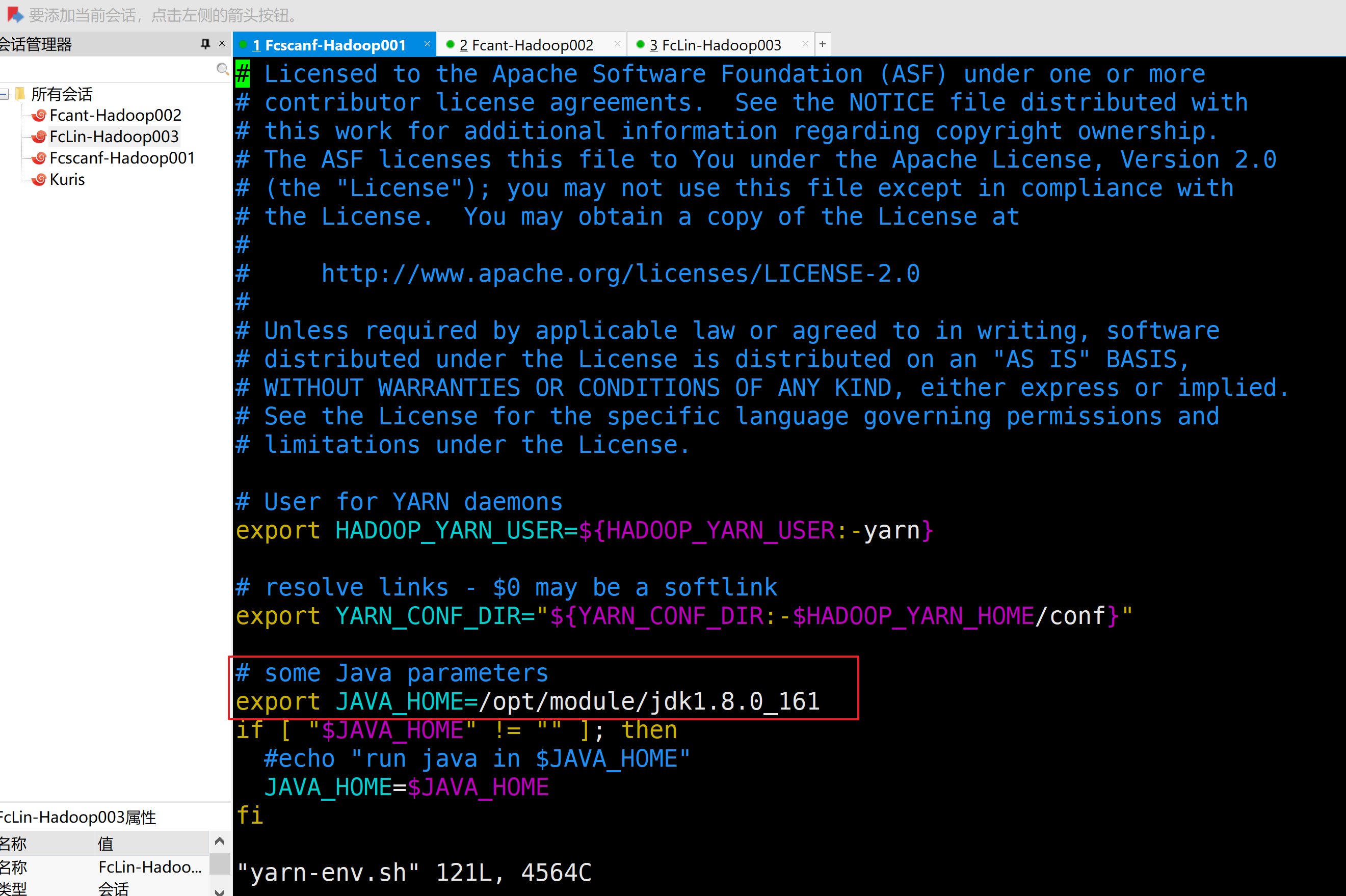
a.配置yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_161
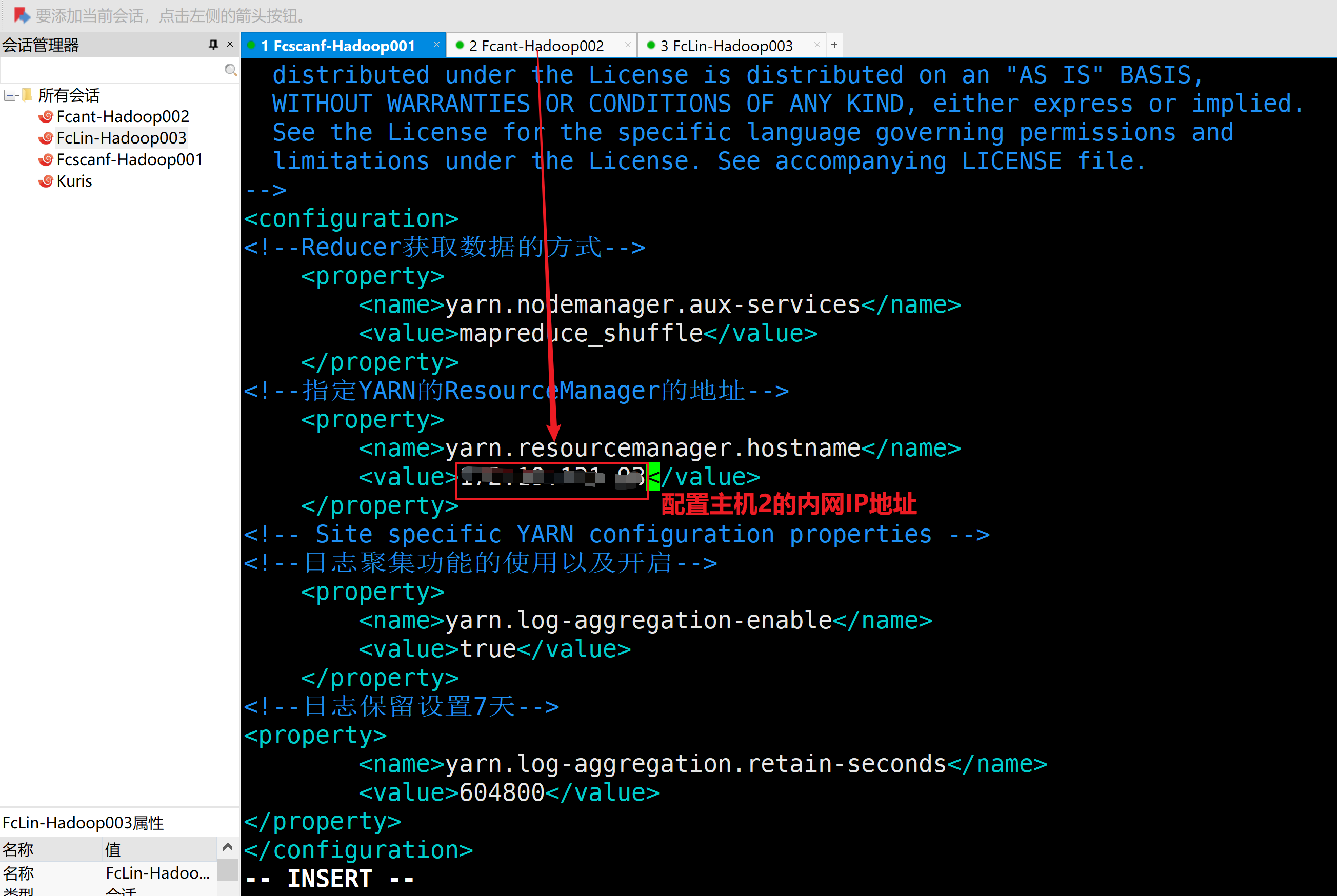
b.配置yarn-site.xml
<configuration>
<!--Reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定YARN的ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<!-- Site specific YARN configuration properties -->
<!--日志聚集功能的使用以及开启-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--日志保留设置7天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
4.MapReduce配置文件
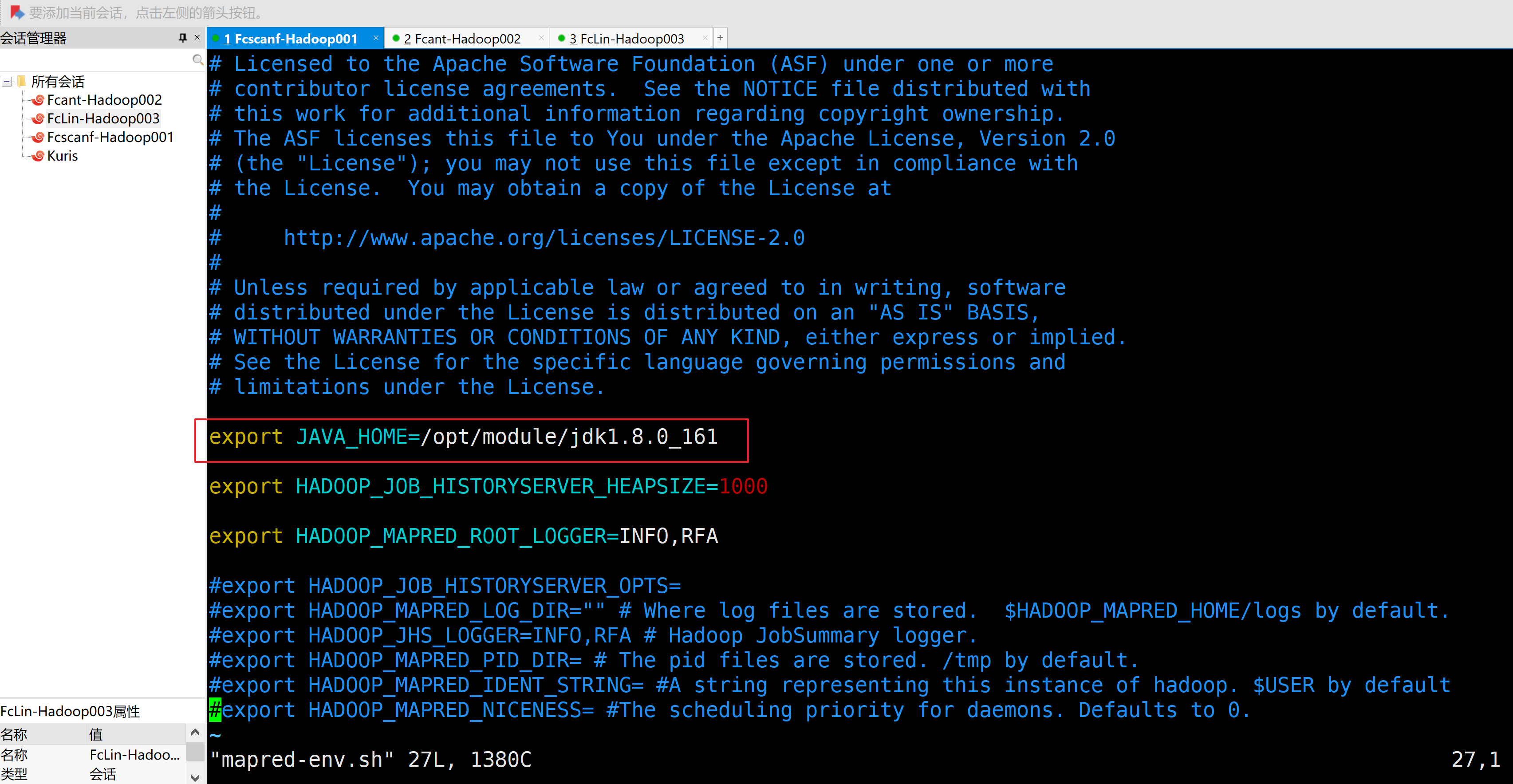
a.配置mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_161
b.配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
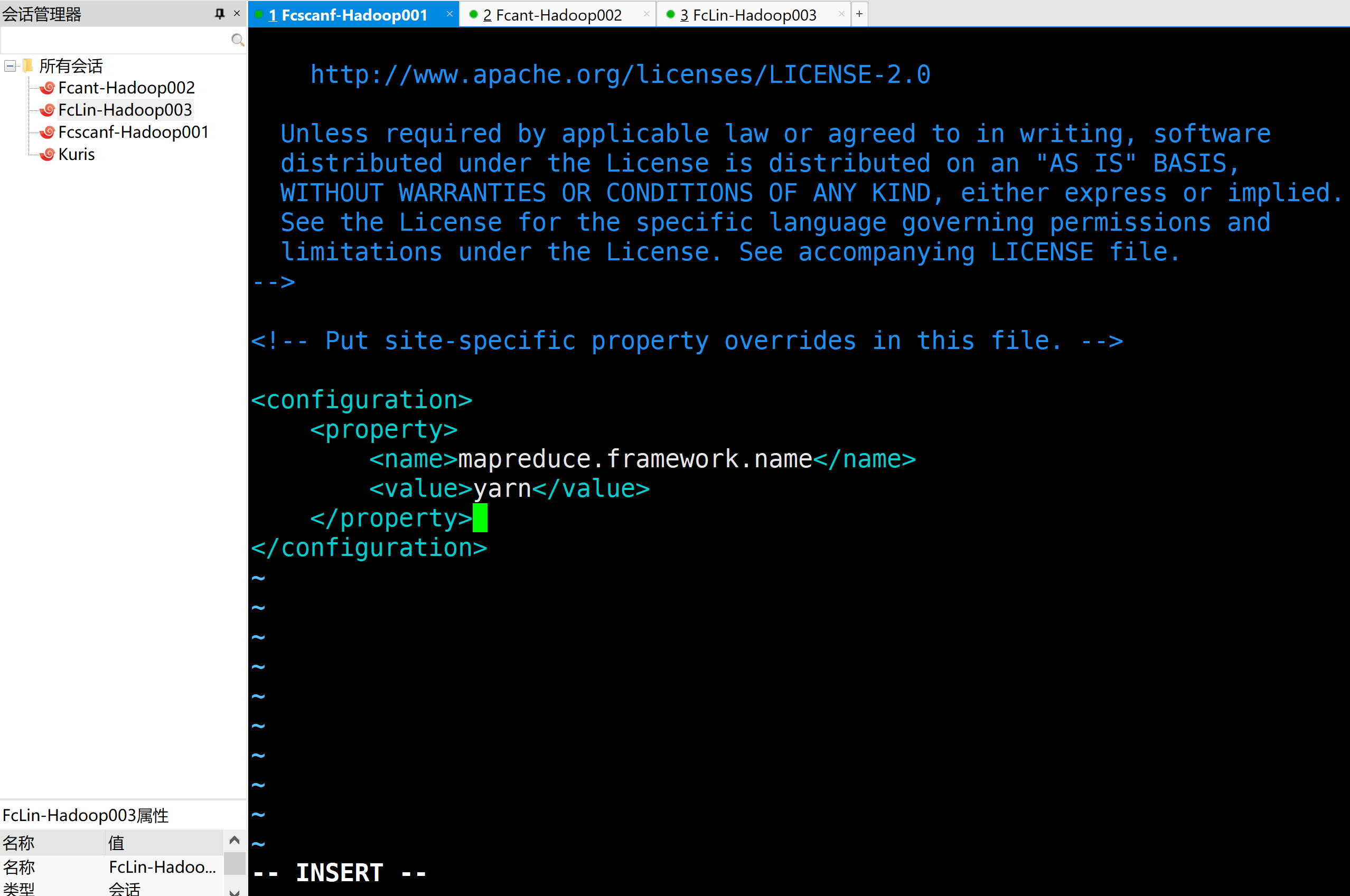
5.在集群上分发配置好的Hadoop文件
[root@iZuligp6e1dyzfZ etc]# xsync hadoop/
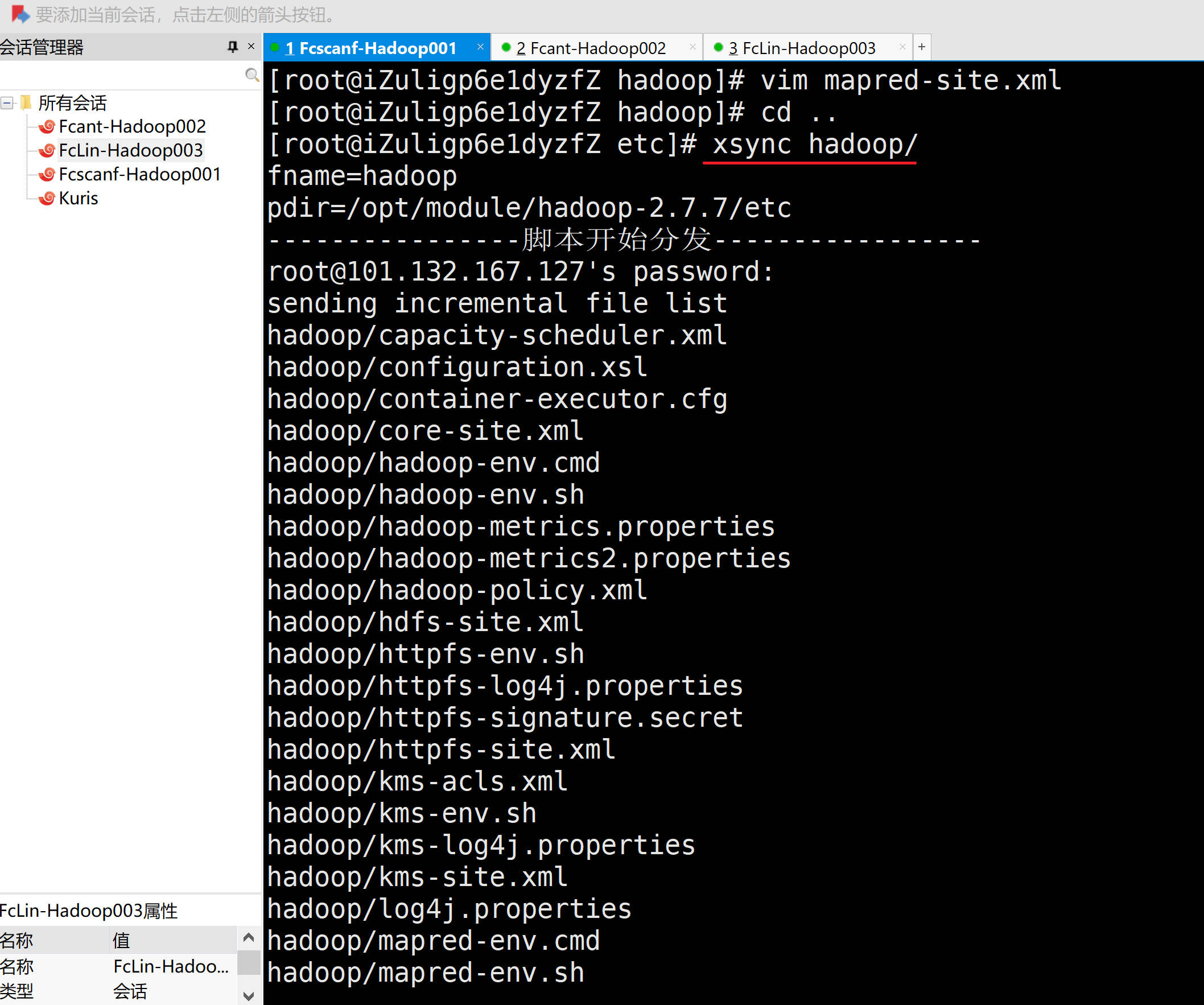
4、集群单点启动
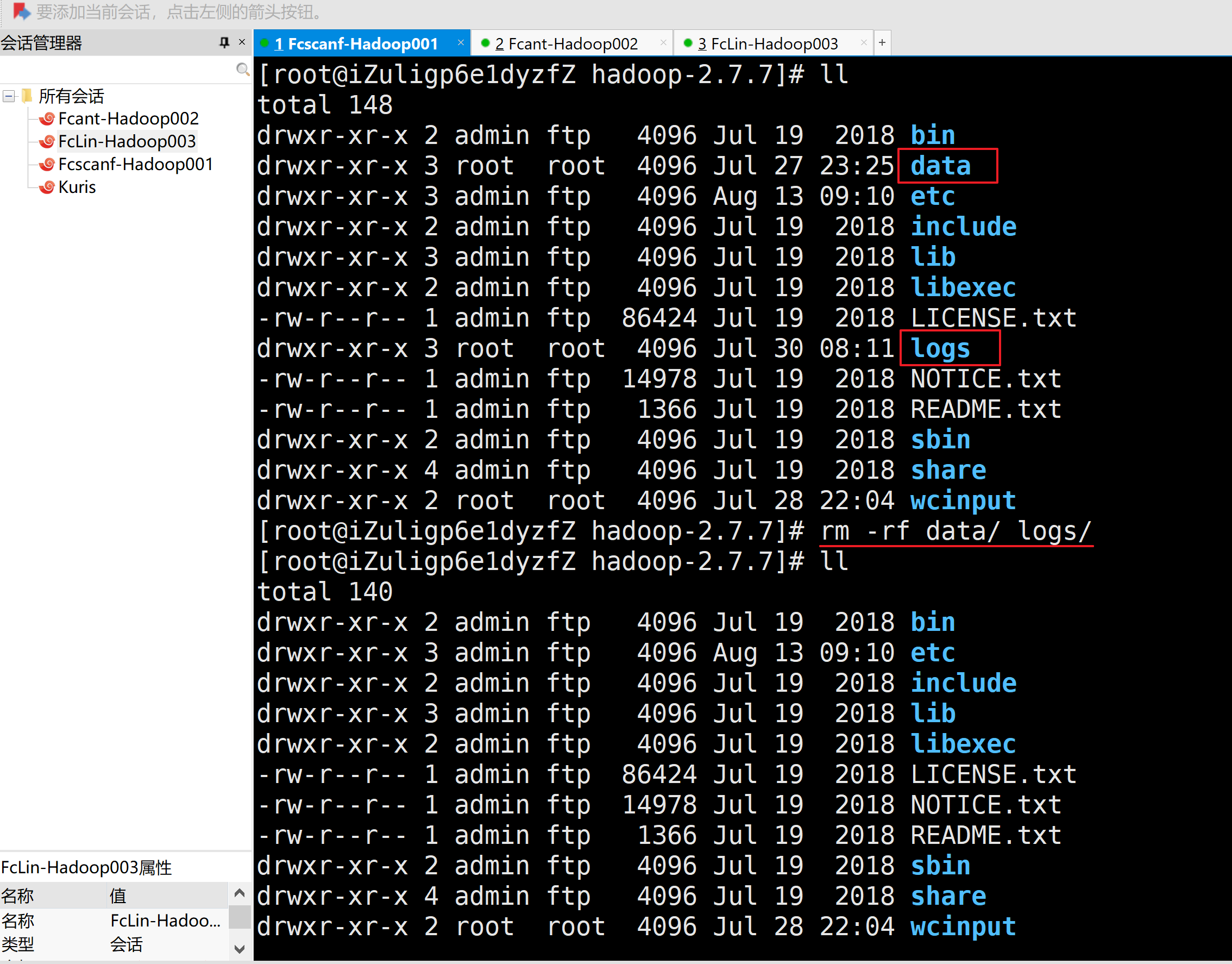
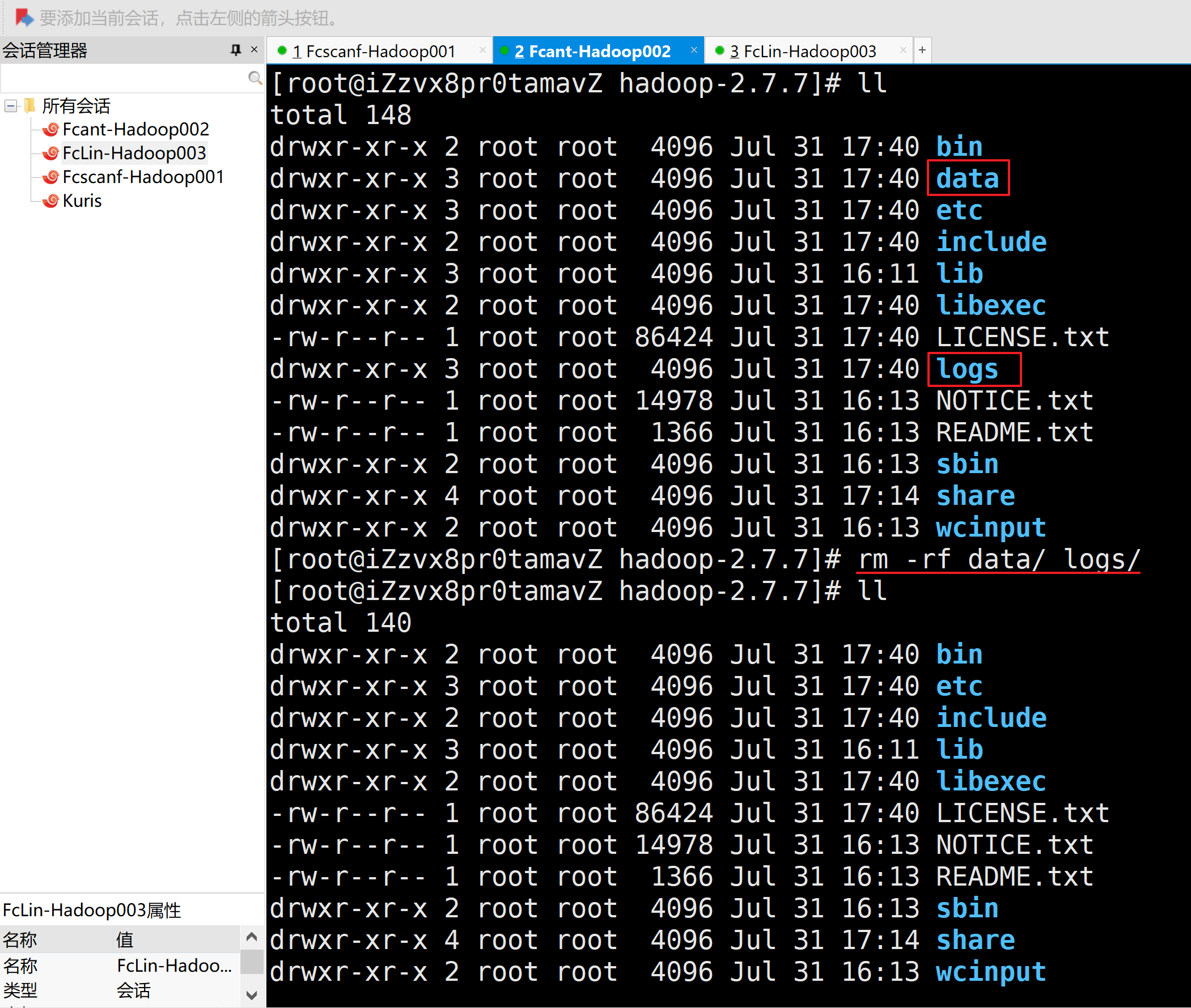
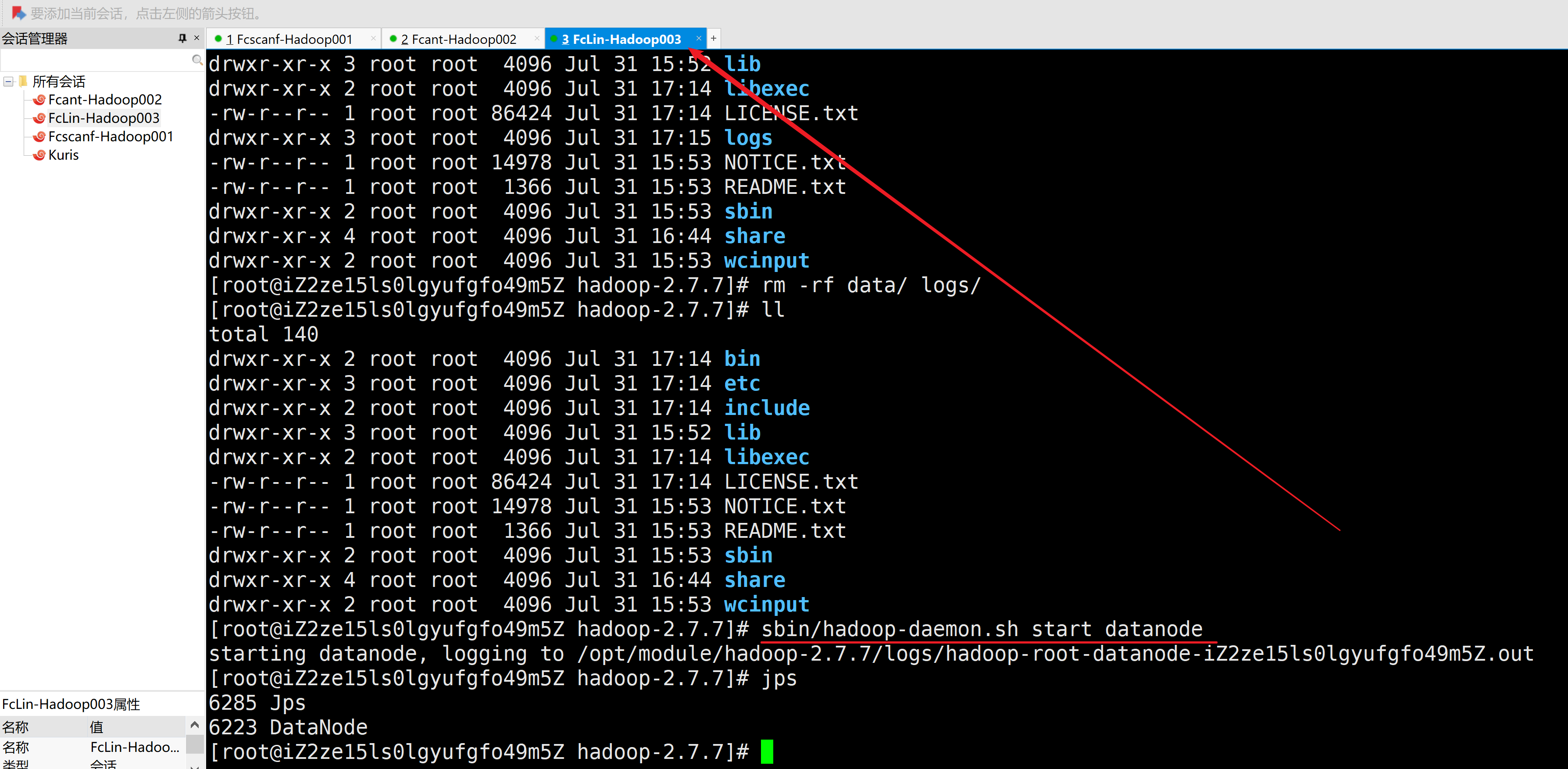
1.删除每个拷贝集群的数据data/目录和日志logs/目录
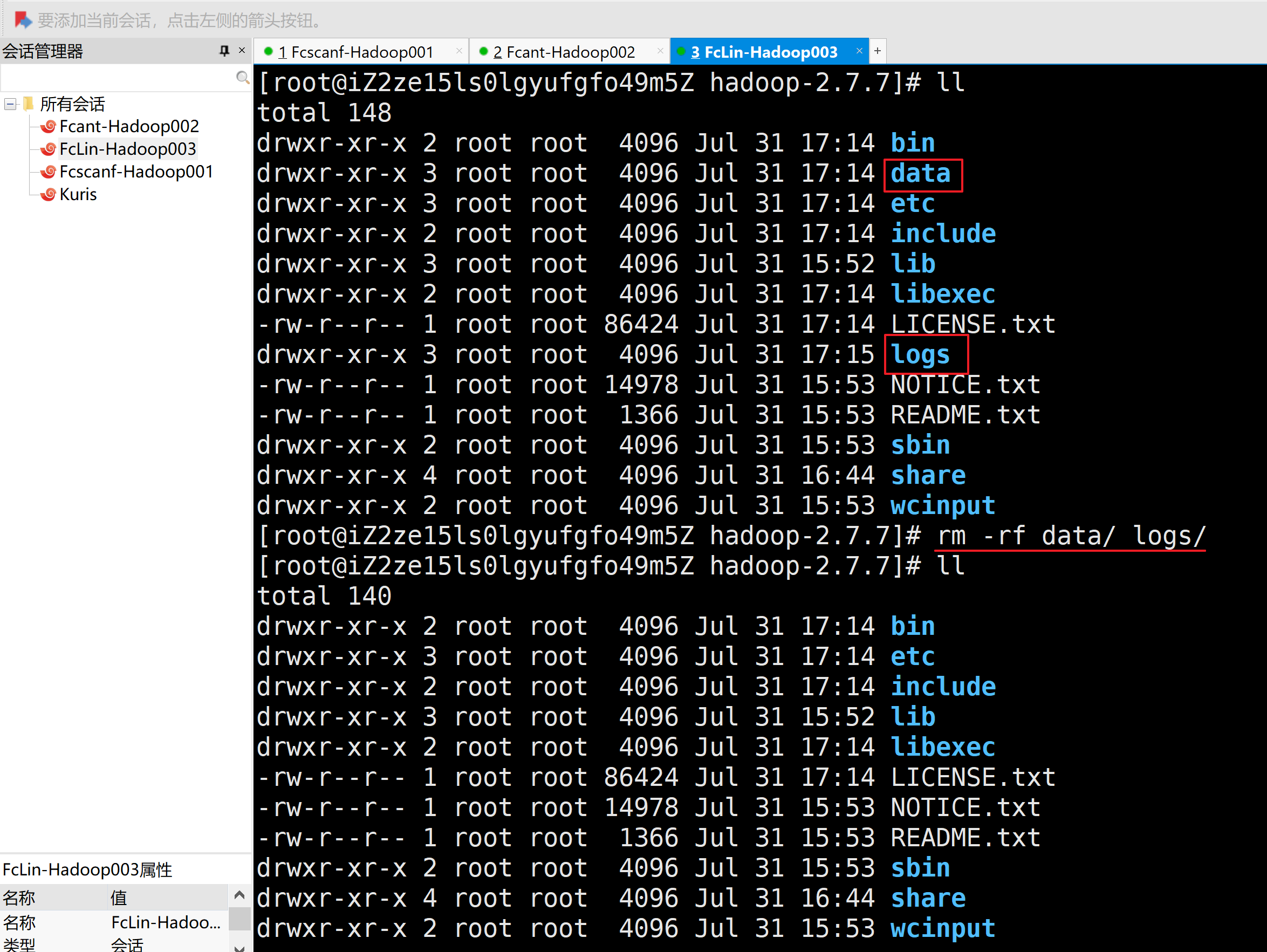
2.在主机1格式化NameNode
[root@iZuligp6e1dyzfZ hadoop-2.7.7]# bin/hdfs namenode -format
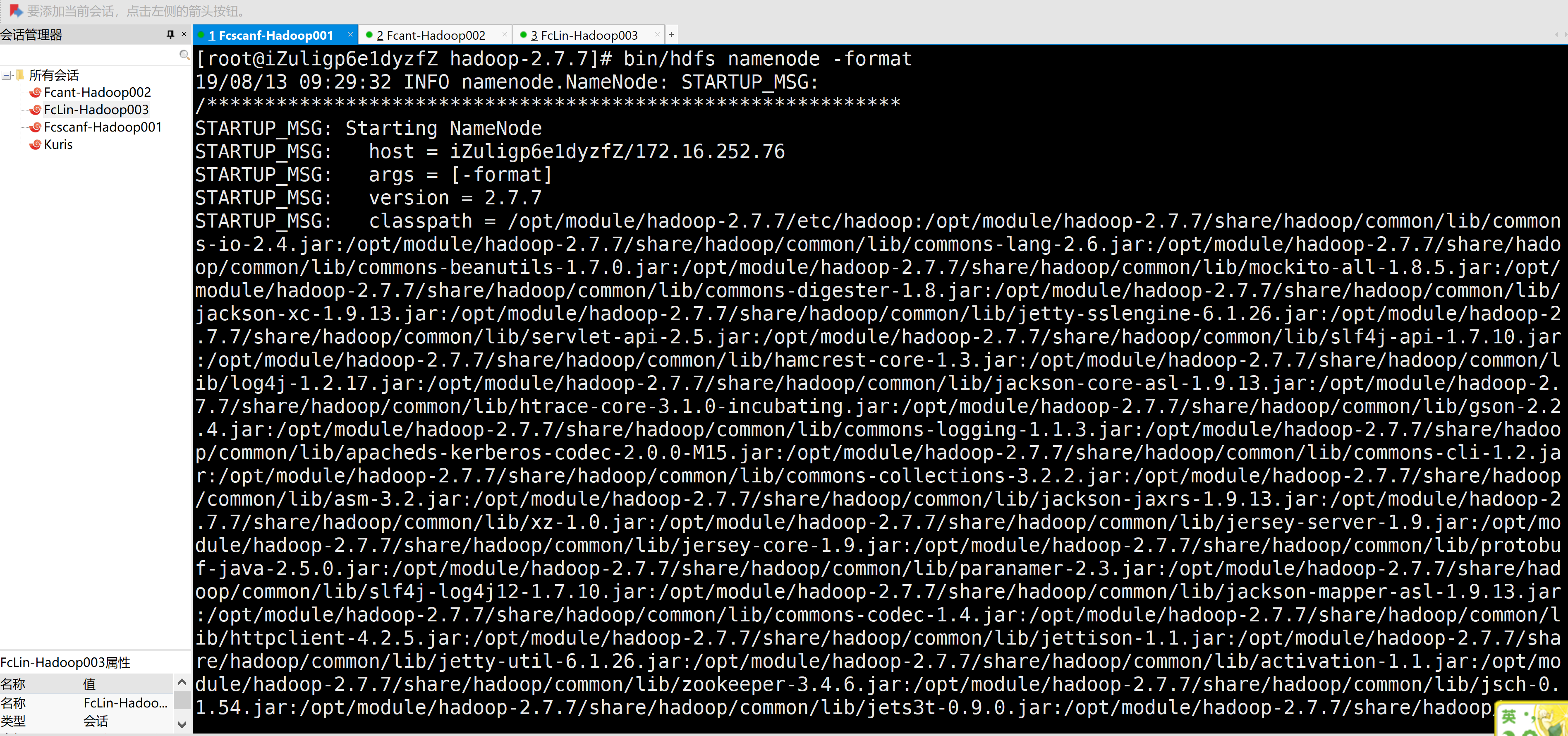
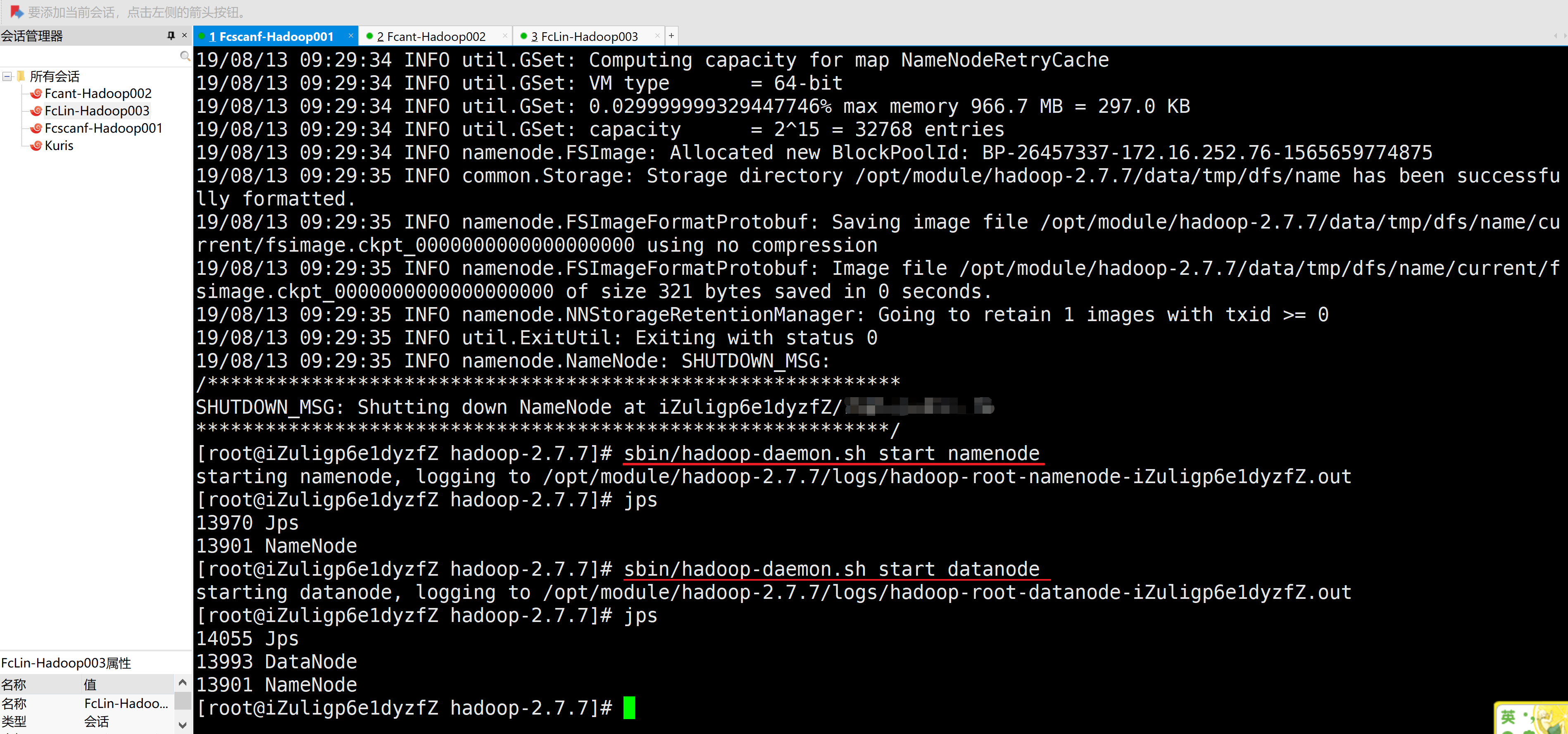
3.在主机1启动NameNode、DataNode
[root@iZuligp6e1dyzfZ hadoop-2.7.7]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.7.7/logs/hadoop-root-namenode-iZuligp6e1dyzfZ.out
[root@iZuligp6e1dyzfZ hadoop-2.7.7]# jps
13970 Jps
13901 NameNode
[root@iZuligp6e1dyzfZ hadoop-2.7.7]# sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop-2.7.7/logs/hadoop-root-datanode-iZuligp6e1dyzfZ.out
[root@iZuligp6e1dyzfZ hadoop-2.7.7]# jps
14055 Jps
13993 DataNode
13901 NameNode
[root@iZuligp6e1dyzfZ hadoop-2.7.7]#
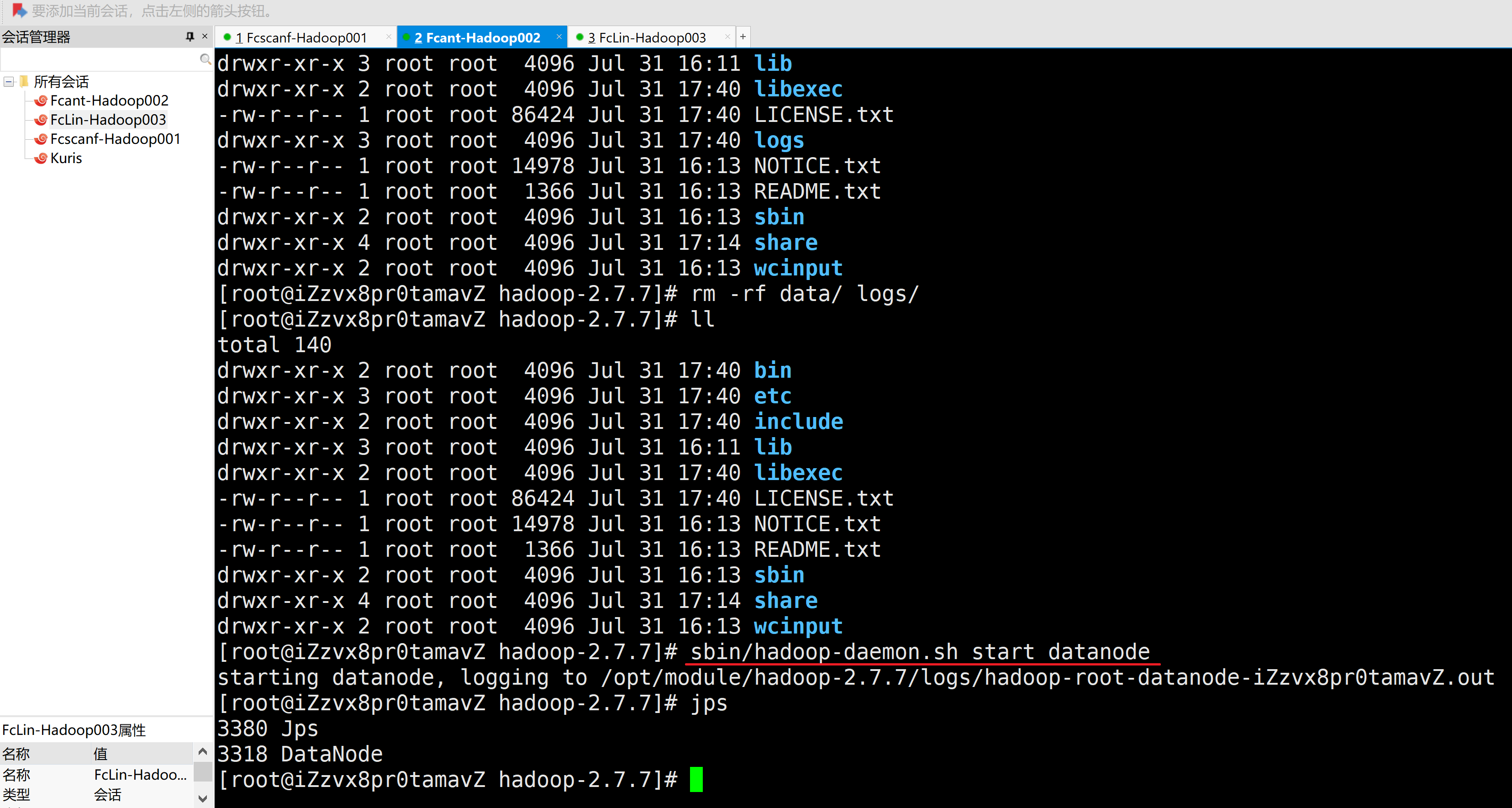
4.在主机2启动DataNode
[root@iZzvx8pr0tamavZ hadoop-2.7.7]# sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop-2.7.7/logs/hadoop-root-datanode-iZzvx8pr0tamavZ.out
[root@iZzvx8pr0tamavZ hadoop-2.7.7]# jps
3380 Jps
3318 DataNode
[root@iZzvx8pr0tamavZ hadoop-2.7.7]#
5.在主机3启动DataNode
[root@iZ2ze15ls0lgyufgfo49m5Z hadoop-2.7.7]# sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop-2.7.7/logs/hadoop-root-datanode-iZ2ze15ls0lgyufgfo49m5Z.out
[root@iZ2ze15ls0lgyufgfo49m5Z hadoop-2.7.7]# jps
6285 Jps
6223 DataNode
[root@iZ2ze15ls0lgyufgfo49m5Z hadoop-2.7.7]#
5、SSH无密登录配置
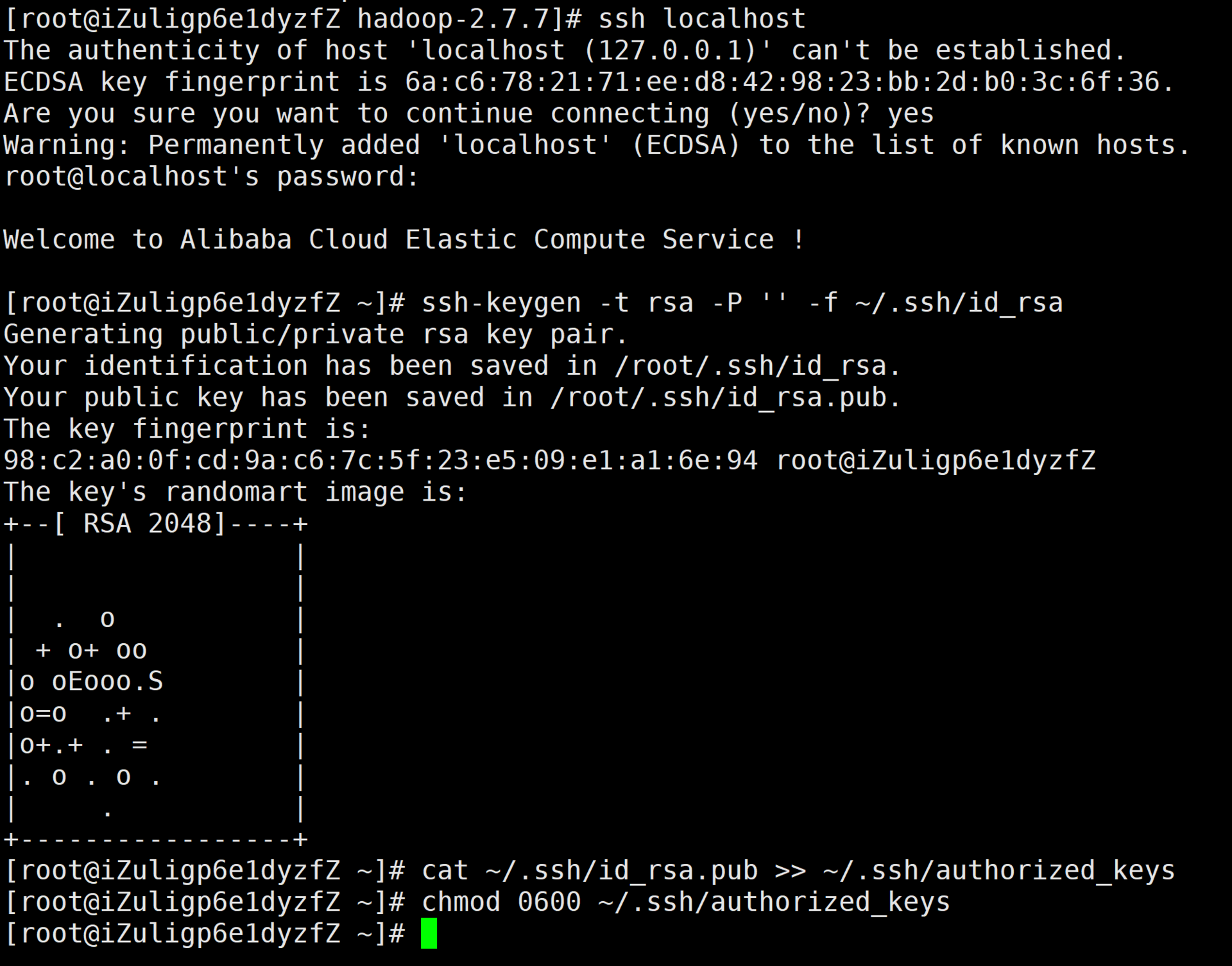
A.生成密钥
[root@iZuligp6e1dyzfZ ~]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
Generating public/private rsa key pair.
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
98:c2:a0:0f:cd:9a:c6:7c:5f:23:e5:09:e1:a1:6e:94 root@iZuligp6e1dyzfZ
The key's randomart image is:
+--[ RSA 2048]----+
| |
| |
| . o |
| + o+ oo |
|o oEooo.S |
|o=o .+ . |
|o+.+ . = |
|. o . o . |
| . |
+-----------------+
[root@iZuligp6e1dyzfZ ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[root@iZuligp6e1dyzfZ ~]# chmod 0600 ~/.ssh/authorized_keys
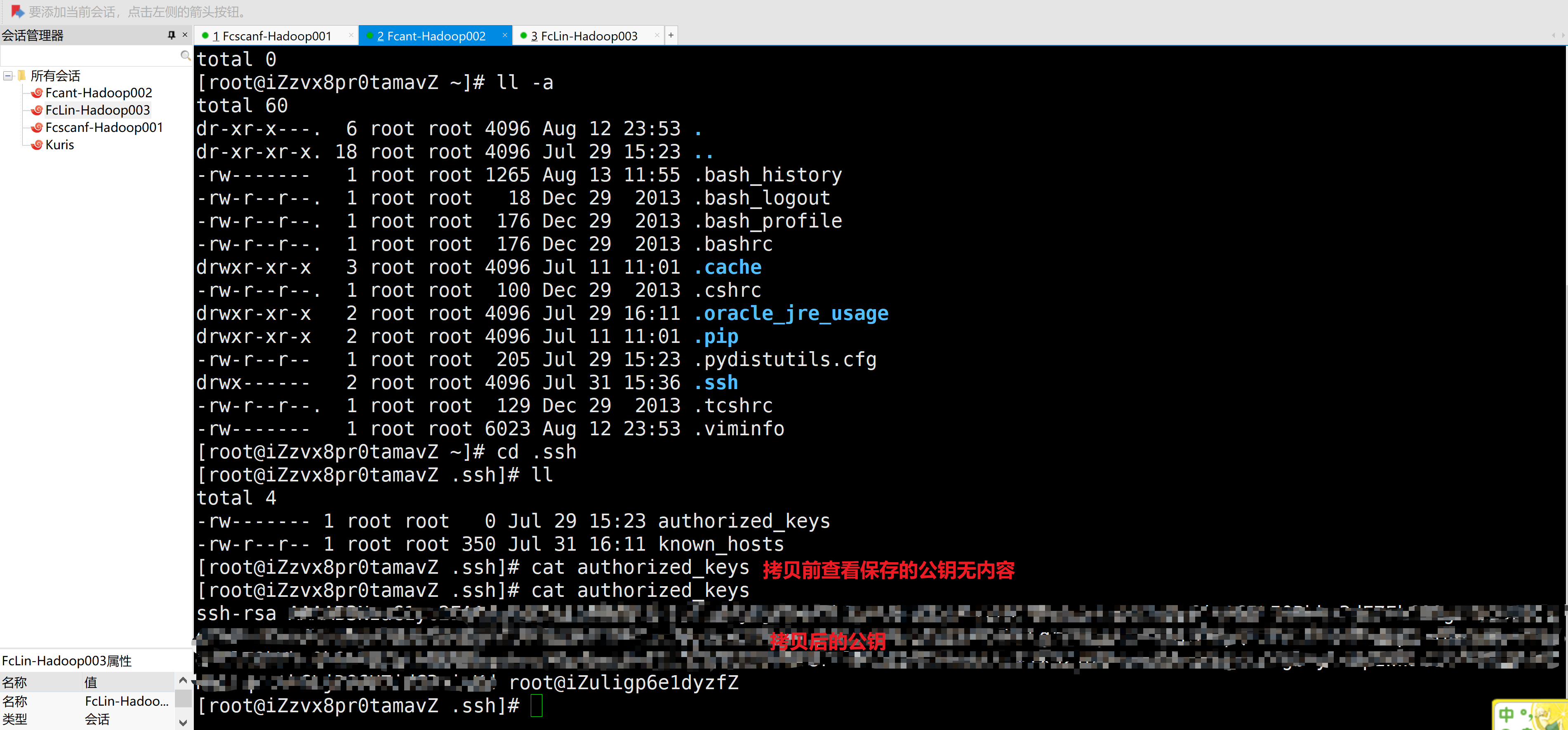
B.在主机1、2上生成ssh密钥并分别拷贝至部署Hadoop的三台服务器上authorized_keys中
此操作为了方便NameNode和**ResourceManager进行管理,如果当前操作的为子用户,须为root用户也生成并分发密钥至自己(便于自己内部数据传输)和其他主机的
authorized_keys中**
[root@iZuligp6e1dyzfZ .ssh]# ssh-copy-id 127.0.0.1
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@101.132.167.127's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh '127.0.0.1'"
and check to make sure that only the key(s) you wanted were added.
[root@iZuligp6e1dyzfZ .ssh]#

6、群起集群
A.配置slaves-配置文件不能用空格和空行
[root@iZuligp6e1dyzfZ ~]# cd /opt/module/hadoop-2.7.7/etc/hadoop/
添加数据节点DataNode的IP地址(服务器ssh通信外网IP地址)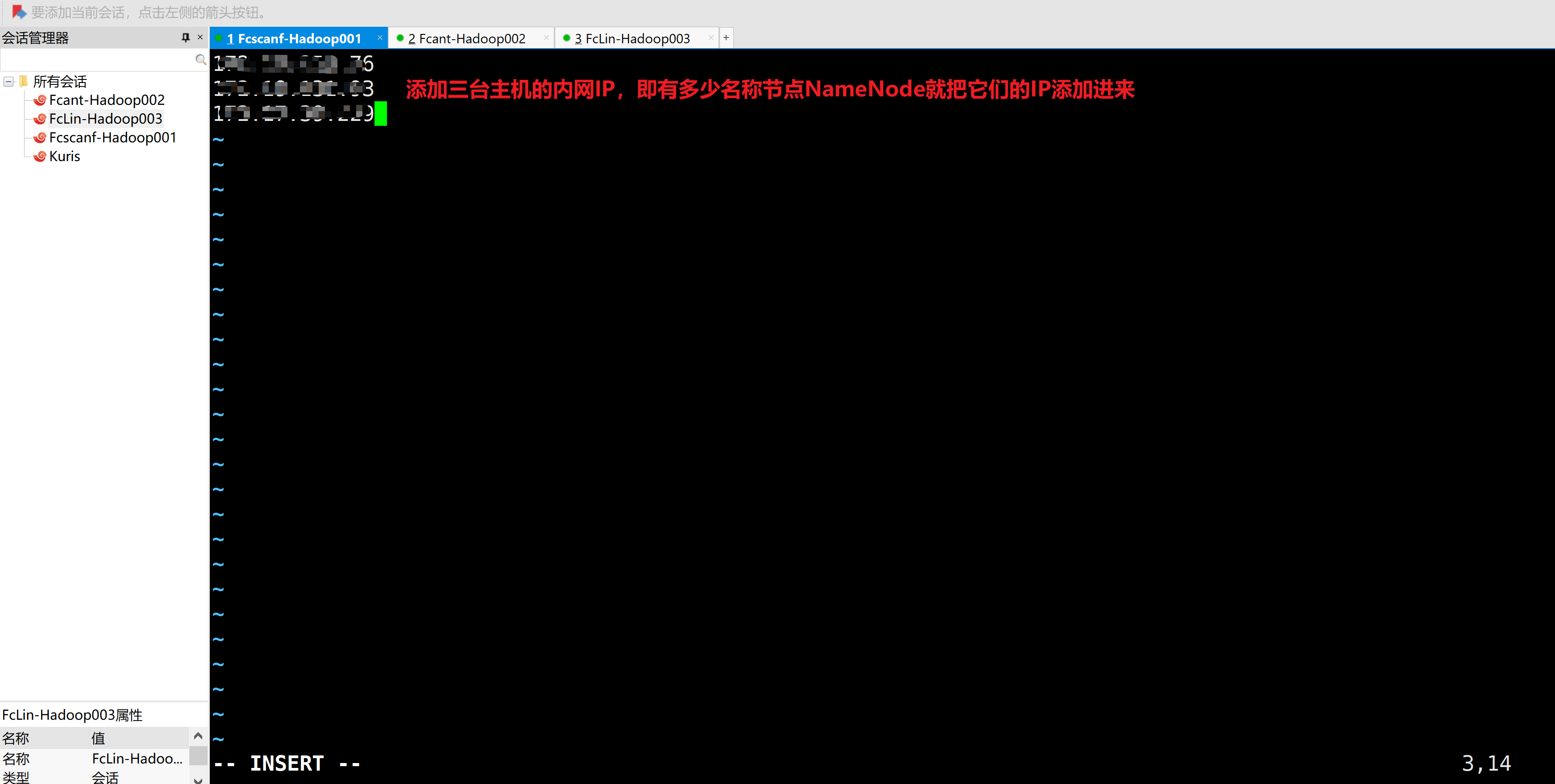
B.将配置好的slaves文件进行分发
[root@iZuligp6e1dyzfZ hadoop]# xsync slaves
C.群起集群前先关闭三台主机上的所有节点
1.Stop主机1上的DataNode和NameNode
[root@iZuligp6e1dyzfZ hadoop]# jps
16099 Jps
13993 DataNode
13901 NameNode
[root@iZuligp6e1dyzfZ hadoop]# cd ../..
[root@iZuligp6e1dyzfZ hadoop-2.7.7]# sbin/hadoop-daemon.sh stop datanode
stopping datanode
[root@iZuligp6e1dyzfZ hadoop-2.7.7]# sbin/hadoop-daemon.sh stop namenode
stopping namenode
[root@iZuligp6e1dyzfZ hadoop-2.7.7]# jps
16147 Jps
[root@iZuligp6e1dyzfZ hadoop-2.7.7]#

2.Stop主机2上的DataNode
[root@iZzvx8pr0tamavZ .ssh]# cd /opt/module/hadoop-2.7.7/
[root@iZzvx8pr0tamavZ hadoop-2.7.7]# jps
4976 Jps
3318 DataNode
[root@iZzvx8pr0tamavZ hadoop-2.7.7]# sbin/hadoop-daemon.sh stop datanode
stopping datanode
[root@iZzvx8pr0tamavZ hadoop-2.7.7]# jps
5007 Jps
[root@iZzvx8pr0tamavZ hadoop-2.7.7]#
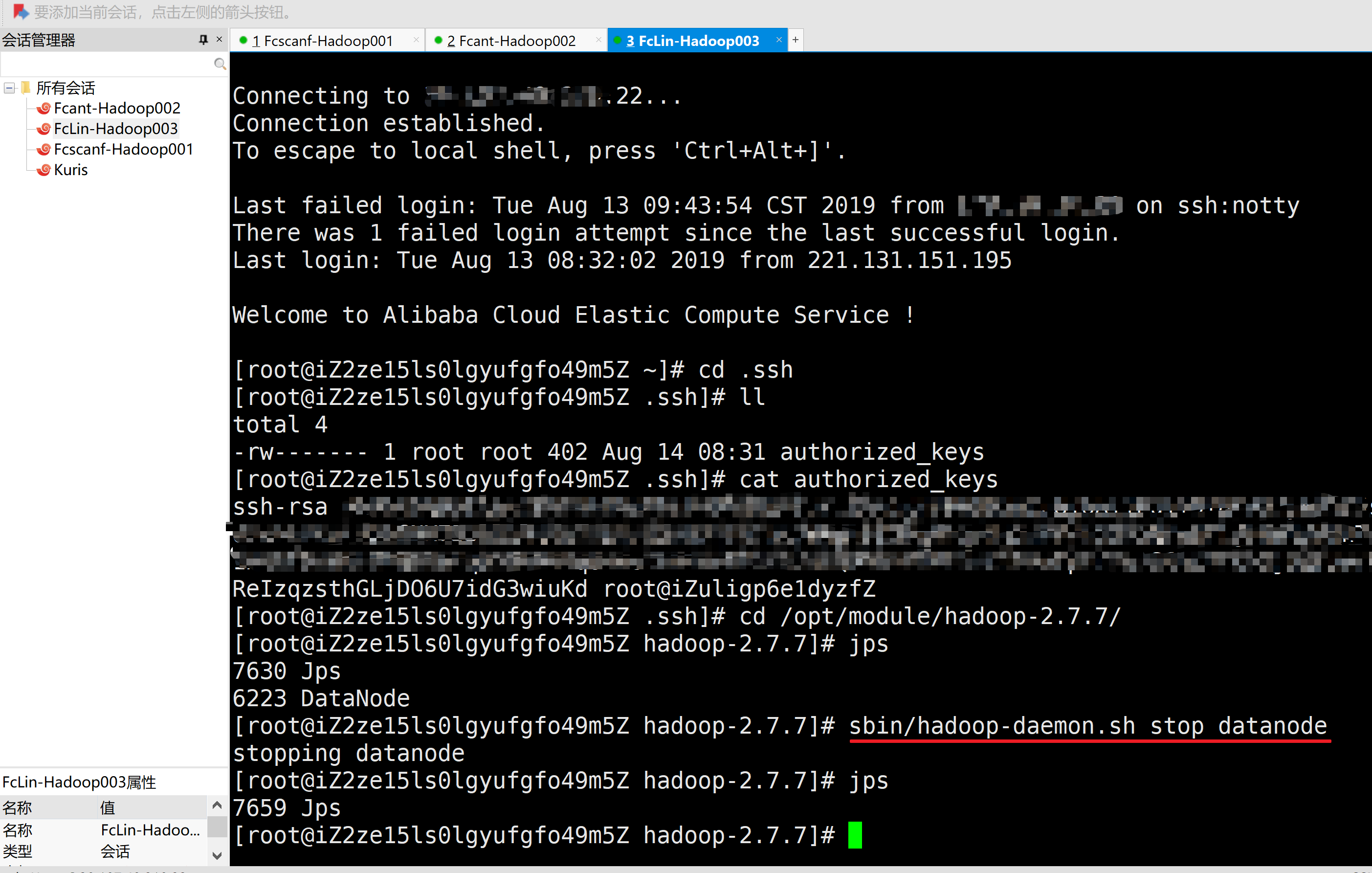
3.Stop主机3上的DataNode
[root@iZ2ze15ls0lgyufgfo49m5Z .ssh]# cd /opt/module/hadoop-2.7.7/
[root@iZ2ze15ls0lgyufgfo49m5Z hadoop-2.7.7]# jps
7630 Jps
6223 DataNode
[root@iZ2ze15ls0lgyufgfo49m5Z hadoop-2.7.7]# sbin/hadoop-daemon.sh stop datanode
stopping datanode
[root@iZ2ze15ls0lgyufgfo49m5Z hadoop-2.7.7]# jps
7659 Jps
[root@iZ2ze15ls0lgyufgfo49m5Z hadoop-2.7.7]#
D.群起集群
[root@iZuligp6e1dyzfZ hadoop-2.7.7]# sbin/start-dfs.sh
7、集群启动/停止方式总结
8、集群时间同步

若有收获,就点个赞吧
0 人点赞
