1 概要
1.1 简介
Prometheus是基于go语⾔开发的⼀套开源的监控、报警和时间序列数据库的组合,是由SoundCloud公司开发的开源监控系统,Prometheus于2016年加⼊CNCF(Cloud Native Computing Foundation,云原⽣计算基⾦
会),2018年8⽉9⽇prometheus成为CNCF继kubernetes 之后毕业的第⼆个项⽬,prometheus在容器和微服务领域中得到了⼴泛的应⽤,其特点主要如下:
使⽤key-value的多维度(多个⻆度,多个层⾯,多个⽅⾯)格式保存数据数据不使⽤MySQL这样的传统数据库,⽽是使⽤时序数据库,⽬前是使⽤的TSDB⽀持第三⽅dashboard实现更⾼的图形界⾯,如grafana(Grafana 2.5.0版本及以上)组件模块化不需要依赖存储,数据可以本地保存也可以远程保存平均每个采样点仅占3.5 bytes,且⼀个Prometheus server可以处理数百万级别的的metrics指标数据。⽀持服务⾃动化发现(基于consul等⽅式动态发现被监控的⽬标服务)强⼤的数据查询语句功(PromQL,Prometheus Query Language)数据可以直接进⾏算术运算易于横向伸缩众多官⽅和第三⽅的exporter实现不同的指标数据收集
1.2 架构图
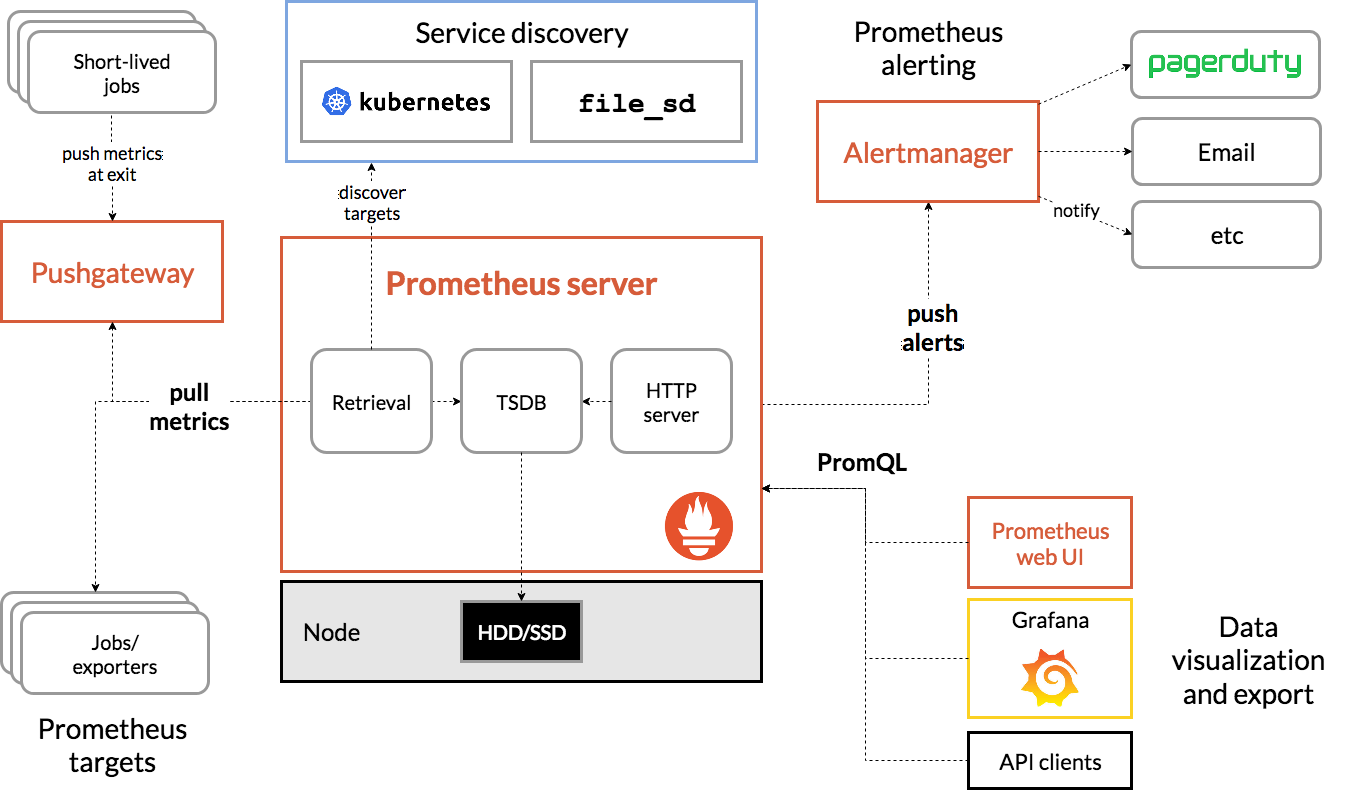
- prometheus server: 主服务,接受外部http请求,收集、存储与查询数据等
- prometheus targets: 静态收集的⽬标服务数据
- service discovery: 动态发现服务
- prometheus alerting: 报警通知
- push gateway: 数据收集代理服务器(类似于zabbix proxy)
- data visualization and export: 数据可视化与数据导出(访问客户端)
1.3 为什么要用Prometheus
容器监控的实现⽅对⽐虚拟机或者物理机来说⽐⼤的区别,⽐如容器在k8s环境中可以任意横向扩容与缩容,那么就需要监控服务能够⾃动对新创建的容器进⾏监控,当容器删除后⼜能够及时的从监控服务中删除,⽽传统的zabbix的监控⽅式需要在每⼀个容器中安装启动agent,并且在容器⾃动发现注册及模板关联⽅⾯并没有⽐较好的实现⽅式。2 安装部署
2.1 二进制安装部署
2.1.1 Prometheus安装
安装包可以到https://github.com/prometheus/prometheus/releases这个链接去下载
1、将Prometheus安装包上传至节点目录并解压 ```shell创建软件安装目录
mkdir /app/prometheus/切换至安装目录
cd /app/prometheus/将prometheus安装包上传至该目录下面
解压文件
tar xf prometheus-2.33.4.linux-amd64.tar.gz
创建软链接
ln -sv prometheus-2.33.4.linux-amd64 prometheus
文件解读
[root@monitor prometheus]# ll -rwxr-xr-x 1 3434 3434 104419379 Feb 23 00:54 prometheus #prometheus服务可执⾏程序 -rw-r—r— 1 3434 3434 934 Feb 23 00:59 prometheus.yml #prometheus配置⽂件 -rwxr-xr-x 1 3434 3434 96326544 Feb 23 00:57 promtool #测试⼯具,⽤于检测配置prometheus配置⽂件、检测metrics数据等
**2、创建prometheus的service文件**<br />vim /usr/lib/systemd/system/prometheus.service
```shell
[Unit]
Description=https://prometheus.io
[Service]
Restart=on-failure
ExecStart=/app/prometheus/prometheus/prometheus --config.file=/app/prometheus/prometheus/prometheus.yml --storage.tsdb.path=/app/prometheus/data
[Install]
WantedBy=multi-user.target
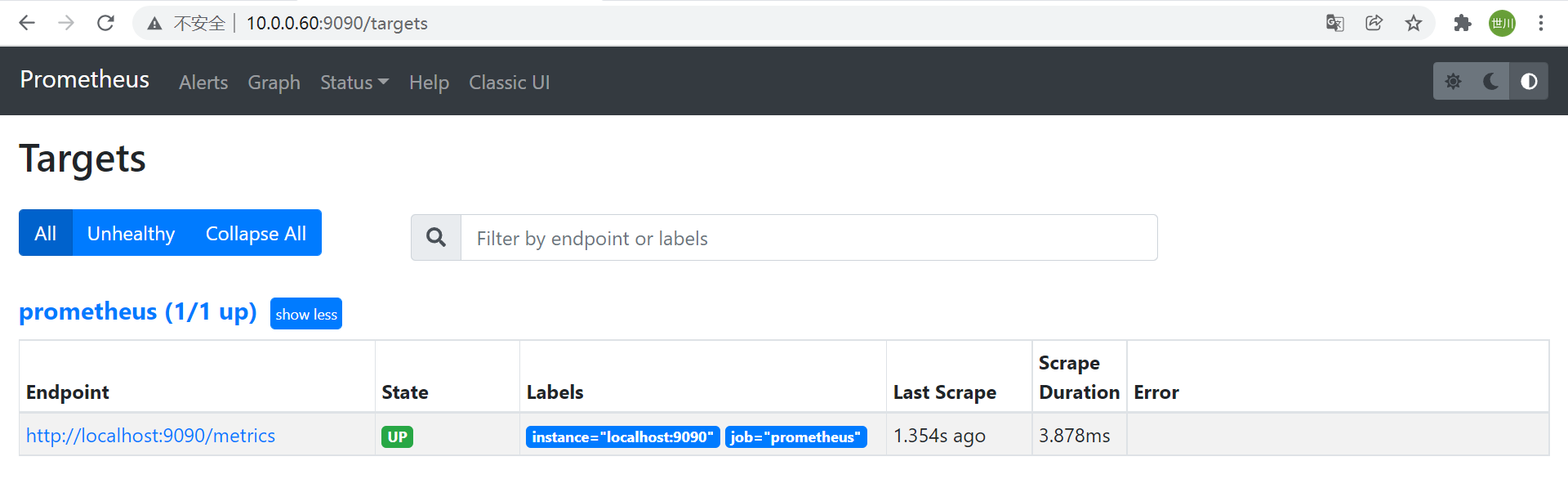
3、启动Prometheus并验证web界面
启动Prometheus
systemctl daemon-reload systemctl enable prometheus.service systemctl start prometheus.service访问prometheus的web界面
2.1.2 Node-exporter安装
node_exporter安装每一个物理机或虚拟机的宿主机节点,用于收集节点数据
安装包可以到https://github.com/prometheus/node_exporter/releases这个链接下载
1、将node-exporter安装包上传至节点目录并解压
#创建软件安装目录
mkdir /app/node_exporter/
#切换至安装目录
cd /app/node_exporter/
#将node-exporter安装包上传至该目录下面
#解压文件
tar xf node_exporter-1.3.1.linux-amd64.tar.gz
#创建软链接
ln -sv node_exporter-1.3.1.linux-amd64 node_exporter
2、创建node_exporter的service文件
vim /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=Prometheus node_exporter
[Service]
User=nobody
ExecStart=/app/node_exporter/node_exporter/node_exporter --log.level=error
ExecStop=/usr/bin/killall node_exporter
[Install]
WantedBy=default.target
3、启动node_exporter并验证web界面
启动node_exporter
systemctl daemon-reload systemctl enable node_exporter.service systemctl start node_exporter.service访问node_exporter的web界面

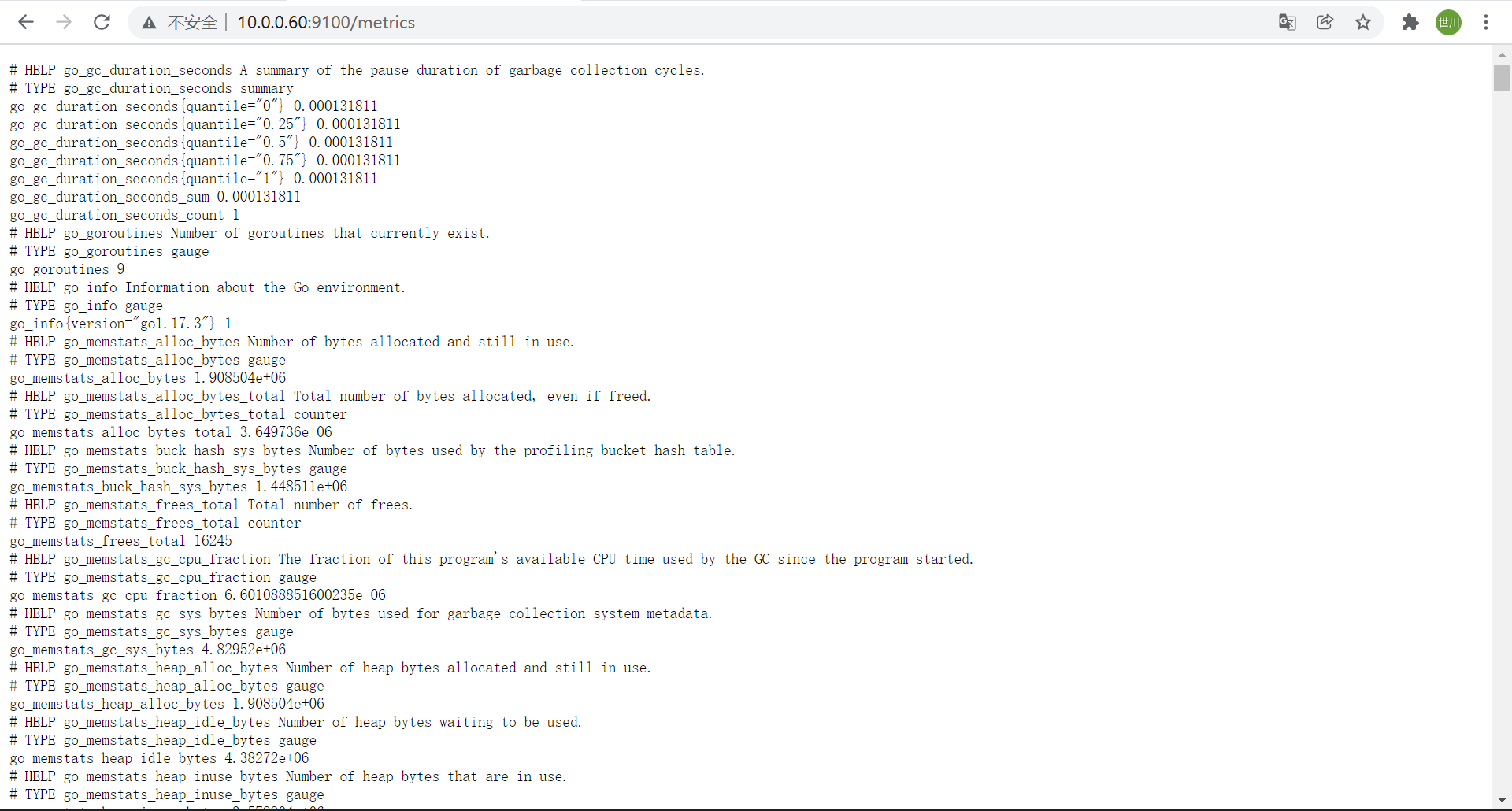
4、node_exporter指标数据
# node-export默认的监听端⼝为9100,可以使⽤浏览器或curl访问数据
curl 10.0.0.60:9100/metrics
#常⻅的指标
node_boot_time: 系统⾃启动以后的总结时间
node_cpu: 系统CPU使⽤量
nodedisk*: 磁盘IO
nodefilesystem*:系统⽂件系统⽤量
node_load1: 系统CPU负载
nodememeory*: 内存使⽤量
nodenetwork*: ⽹络带宽指标
node_time: 当前系统时间
go_*: node exporter中go相关指标
process_*: node exporter⾃身进程相关运⾏指标
2.1.3 配置prometheus收集node-exporter指标数据
1、Prometheus默认配置文件简介
# my global config
global:
#数据收集间隔时间,如果不配置默认为⼀分钟
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
#规则扫描间隔时间,如果不配置默认为⼀分钟
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
#报警通知配置
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
#规则配置
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
#数据采集⽬标配置
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
2、编辑Prometheus配置文件,添加node节点数据收集
- job_name: "prometheus_node_exporter"
static_configs:
- targets: ["10.0.0.60:9100"]
3、重启Prometheus服务,并在界面查看targets
重启服务
systemctl restart prometheus.service界面验证
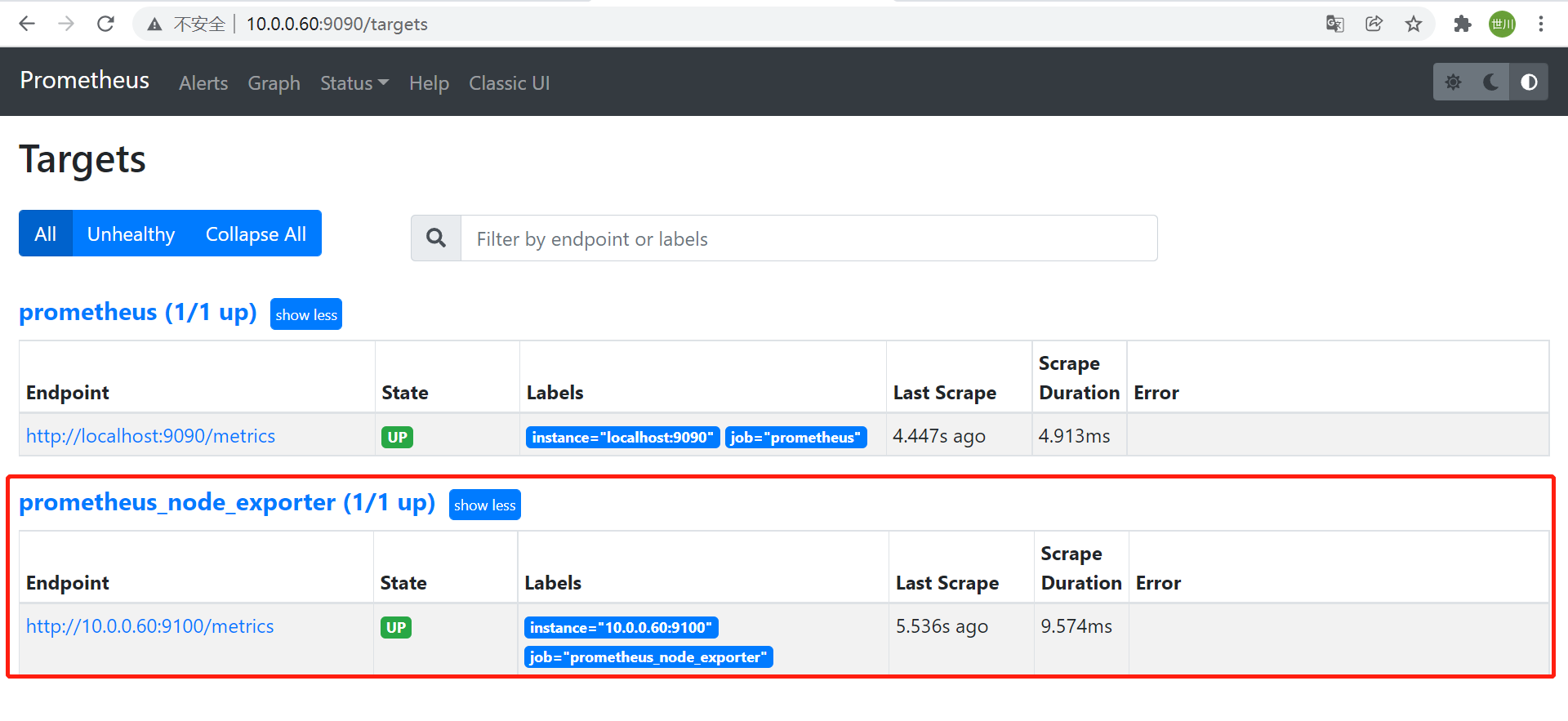
- node数据验证
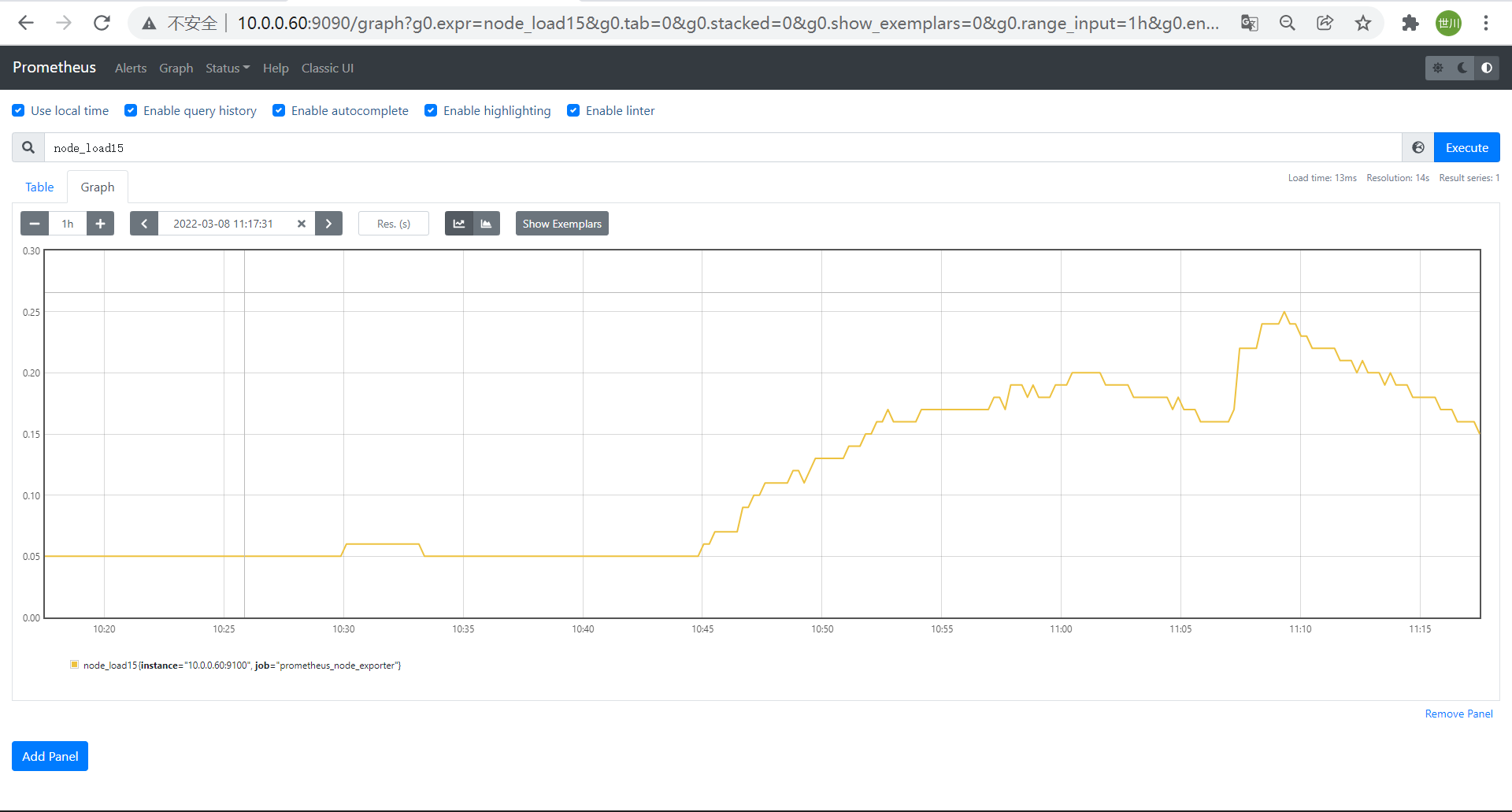
2.1.4 安装grafana
1、简介
grafana是⼀个可视化组件,⽤于接收客户端浏览器的请求并连接到prometheus查询数据,最后经过渲染并在浏览器进⾏体系化显示,需要注意的是,grafana查询数据类似于zabbix⼀样需要⾃定义模板,模板可以⼿动制作也可以导⼊已有模板。
https://grafana.com/ #官⽹
https://grafana.com/grafana/dashboards/ #模板下载
2、下载安装
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-8.4.3-1.x86_64.rpm
sudo yum install grafana-enterprise-8.4.3-1.x86_64.rpm
3、修改配置文件
vim /etc/grafana/grafana.ini,可根据情况自定义修改一些参数设置
[server]
# Protocol (http, https, socket)
protocol = http
# The ip address to bind to, empty will bind to all interfaces
http_addr = 0.0.0.0
# The http port to use
http_port = 3000
4、启动
systemctl enable grafana-server.service
systemctl start grafana-server.service
5、登录
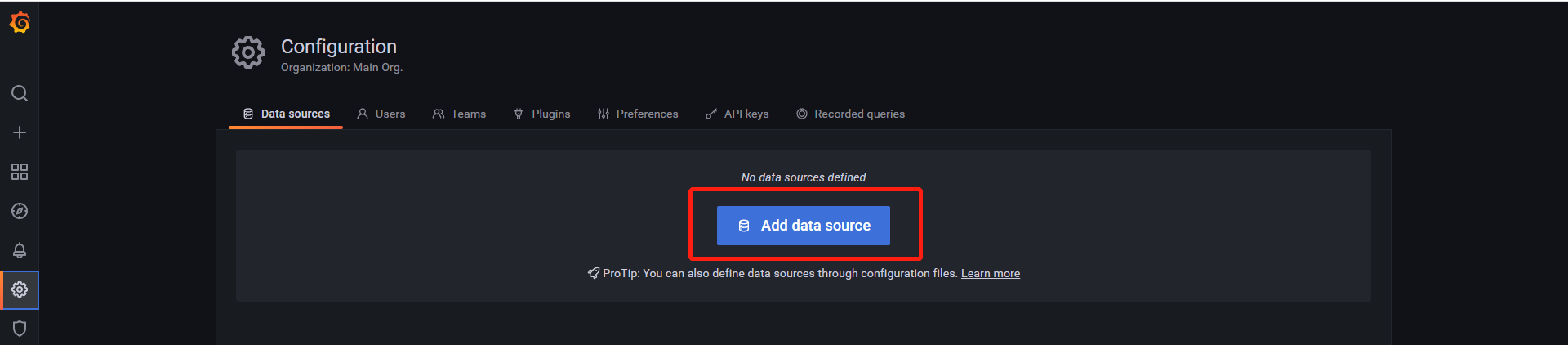
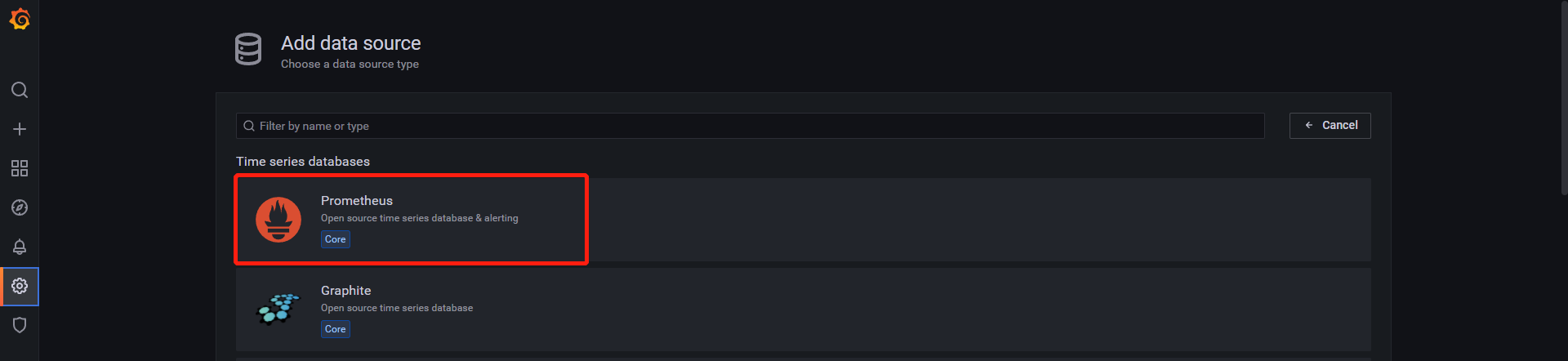
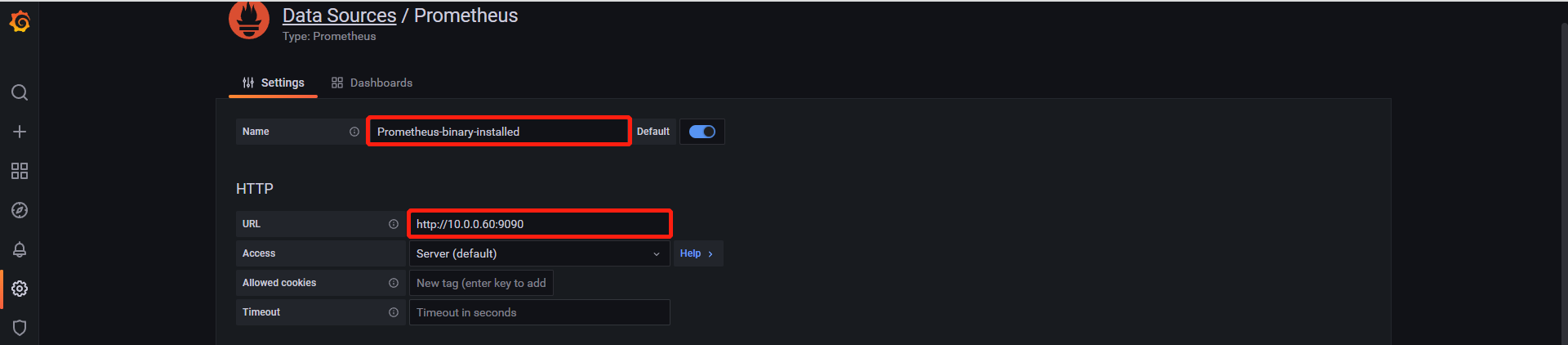
6、添加数据源

7、导入模板
- https://grafana.com/grafana/dashboards/在这个链接上查找需要的模板文件
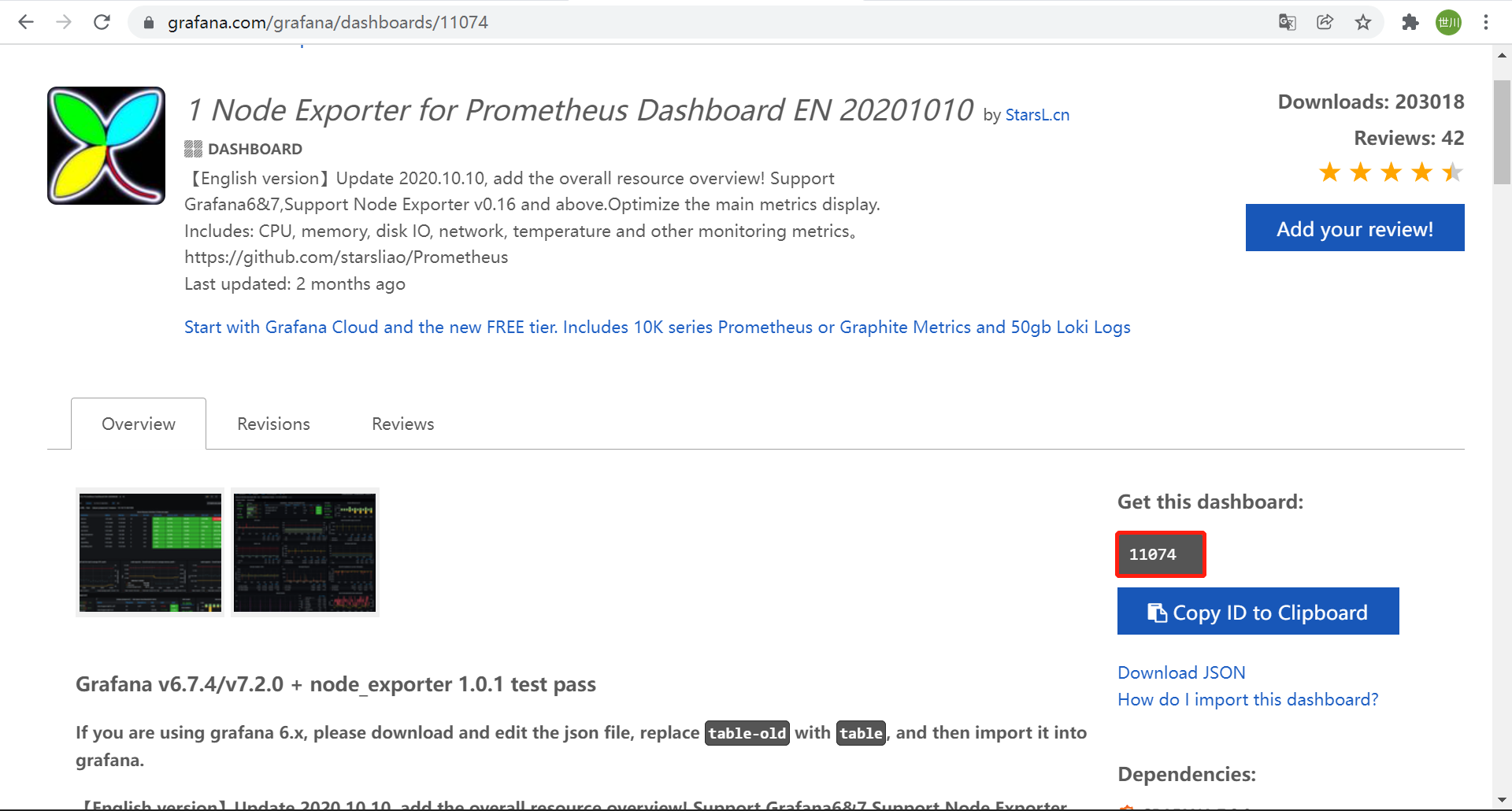
- 根据模板的id号进行导入,也可以用json file的方式进行离线导入
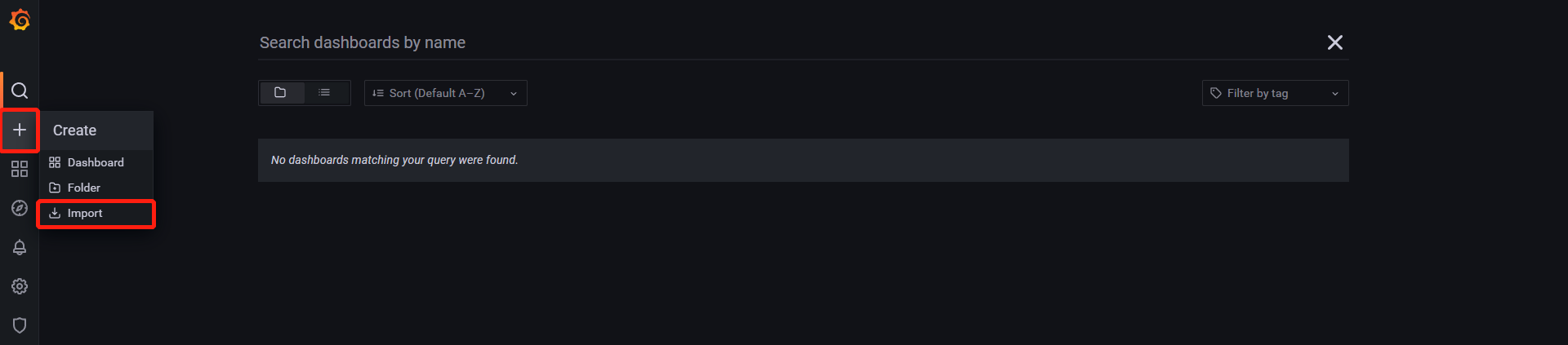
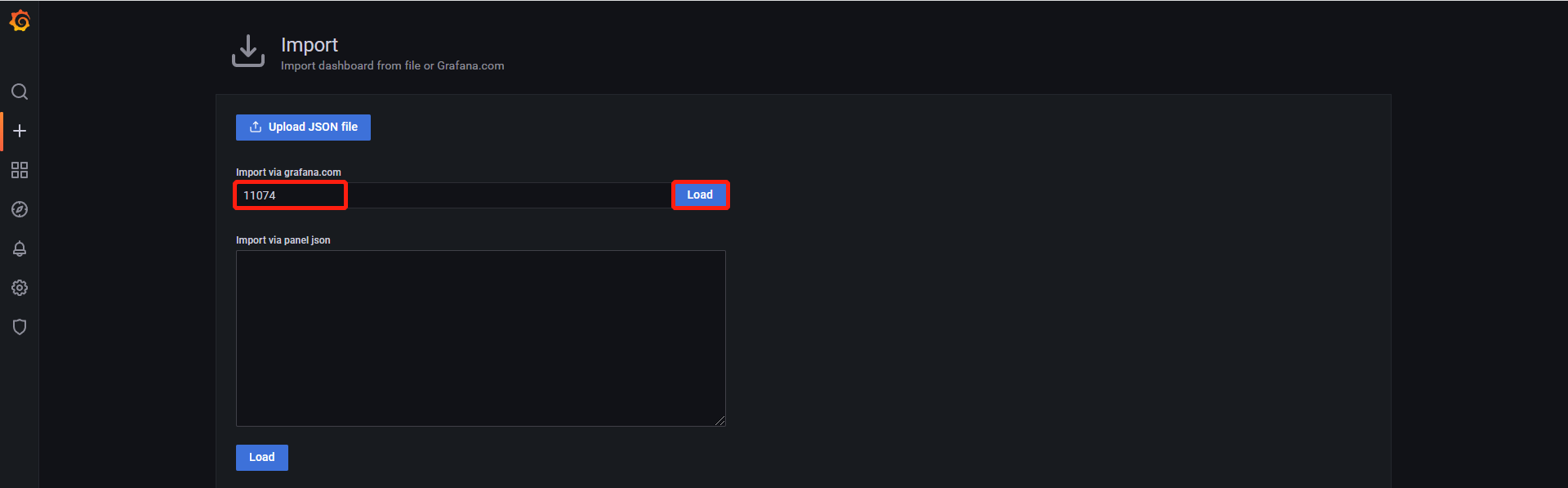
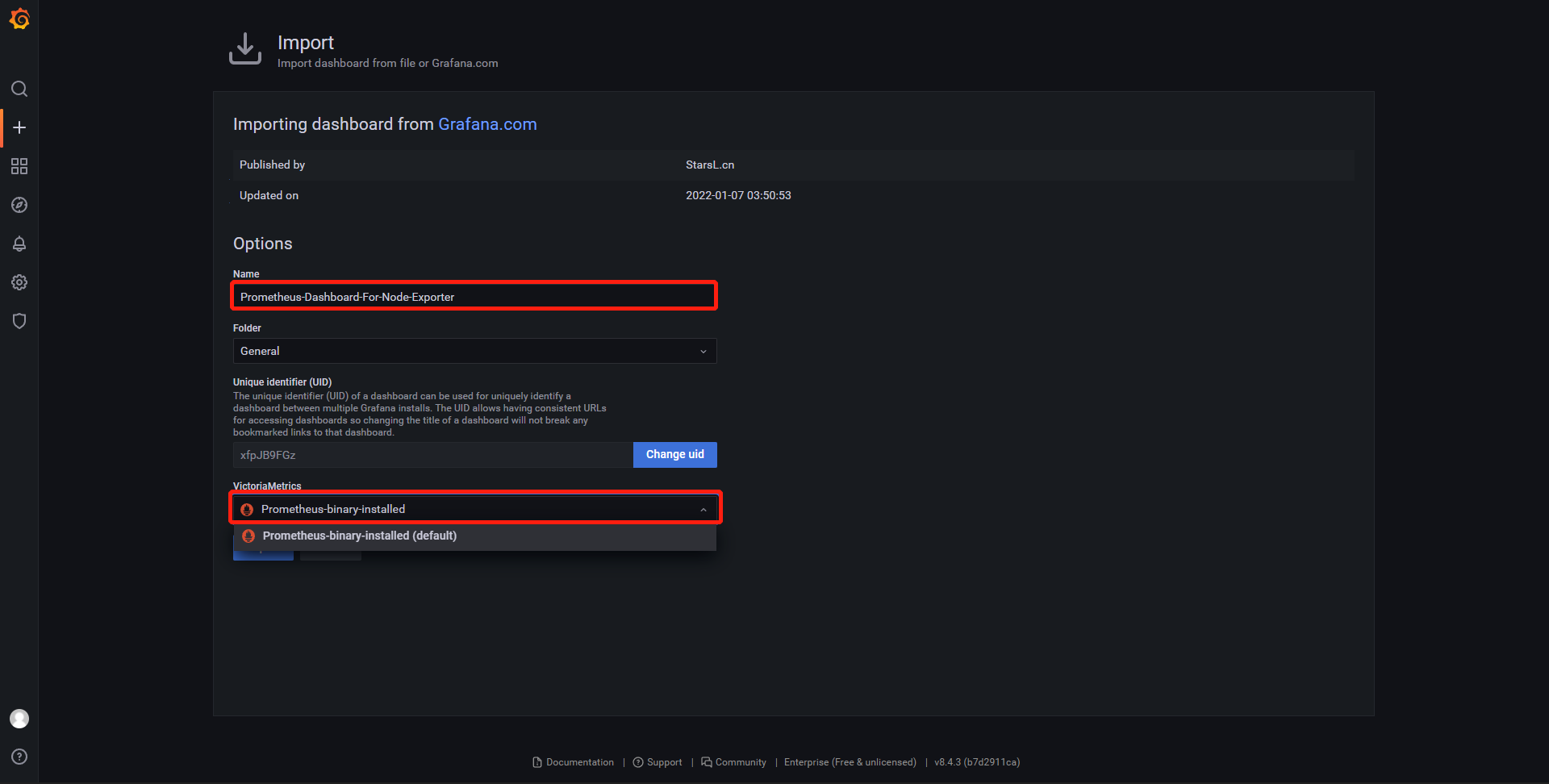
- 修改模板名字和添加需要显示的数据
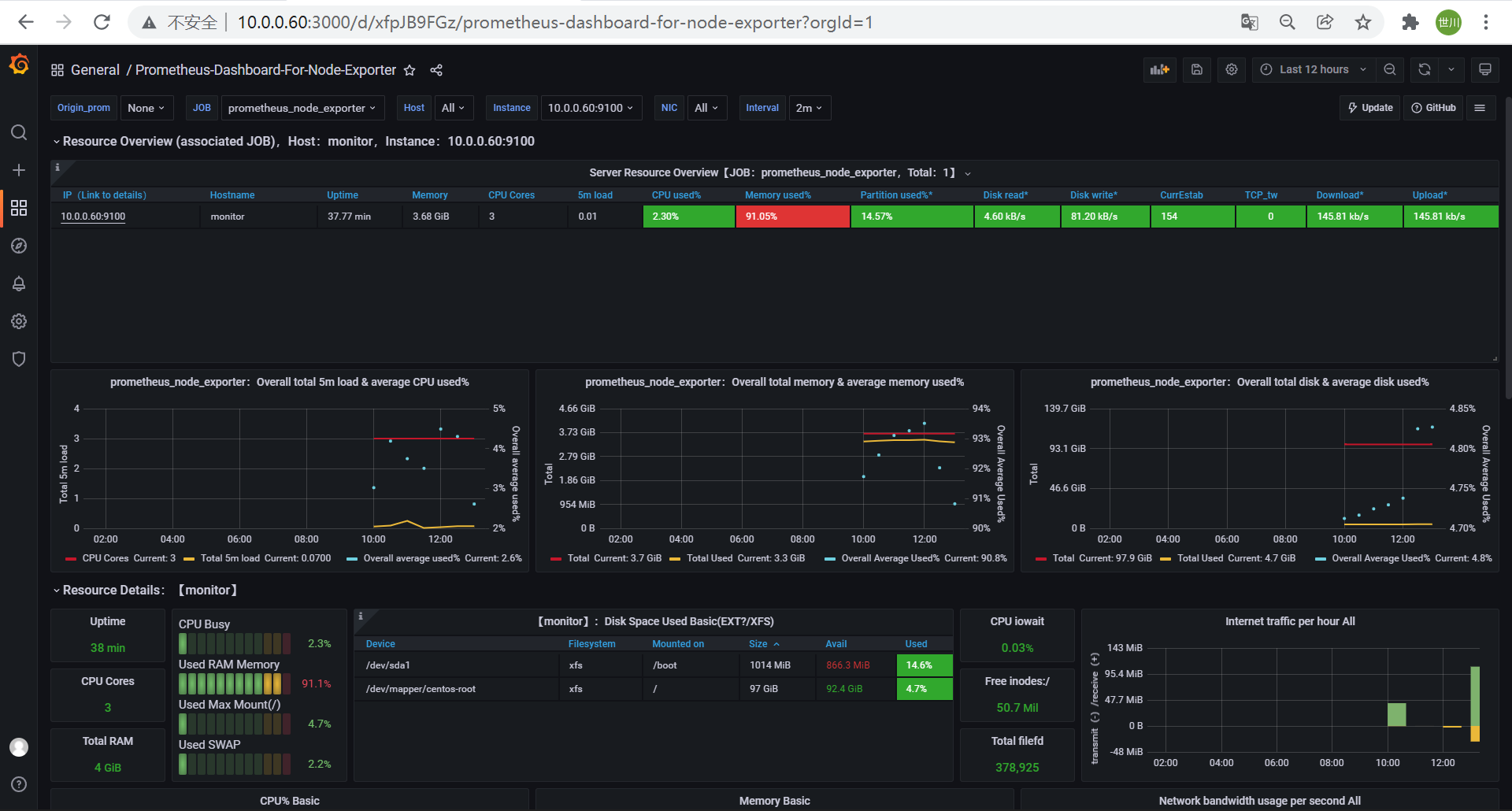
- 数据图形展示
2.2 在k8s上安装部署
2.2.1 Node-Exporter安装
1、安装node-exporter
kubectl apply -f daemonset-deploy-node-exporter.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitoring
labels:
k8s-app: node-exporter
spec:
selector:
matchLabels:
k8s-app: node-exporter
template:
metadata:
labels:
k8s-app: node-exporter
spec:
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
containers:
- image: prom/node-exporter:v1.3.1
imagePullPolicy: IfNotPresent
name: prometheus-node-exporter
ports:
- containerPort: 9100
hostPort: 9100
protocol: TCP
name: metrics
volumeMounts:
- mountPath: /host/proc
name: proc
- mountPath: /host/sys
name: sys
- mountPath: /host
name: rootfs
args:
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
- --path.rootfs=/host
volumes:
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
hostNetwork: true
hostPID: true
---
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: "true"
labels:
k8s-app: node-exporter
name: node-exporter
namespace: monitoring
spec:
type: NodePort
ports:
- name: http
port: 9100
nodePort: 39100
protocol: TCP
selector:
k8s-app: node-exporter


2.2.2 Prometheus安装
1、创建configmap
kubectl apply -f prometheus-cfg.yaml
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-node-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
2、将prometheus运行在node1上,提前准备好数据目录并授权
mkdir -p /data/prometheusdata
chmod 777 /data/prometheusdata
3、创建监控账号
kubectl create serviceaccount monitor -n monitoring
4、对monitor账号进行授权
kubectl create clusterrolebinding monitor-clusterrolebinding -n monitoring --clusterrole=cluster-admin --serviceaccount=monitoring:monitor
5、部署prometheus
kubectl apply -f prometheus-deployment.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server
namespace: monitoring
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: server
#matchExpressions:
#- {key: app, operator: In, values: [prometheus]}
#- {key: component, operator: In, values: [server]}
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false'
spec:
nodeName: 10.0.0.19
serviceAccountName: monitor
containers:
- name: prometheus
image: prom/prometheus:v2.31.2
imagePullPolicy: IfNotPresent
command:
- prometheus
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/prometheus
- --storage.tsdb.retention=720h
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus/prometheus.yml
name: prometheus-config
subPath: prometheus.yml
- mountPath: /prometheus/
name: prometheus-storage-volume
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
items:
- key: prometheus.yml
path: prometheus.yml
mode: 0644
- name: prometheus-storage-volume
hostPath:
path: /data/prometheusdata
type: Directory
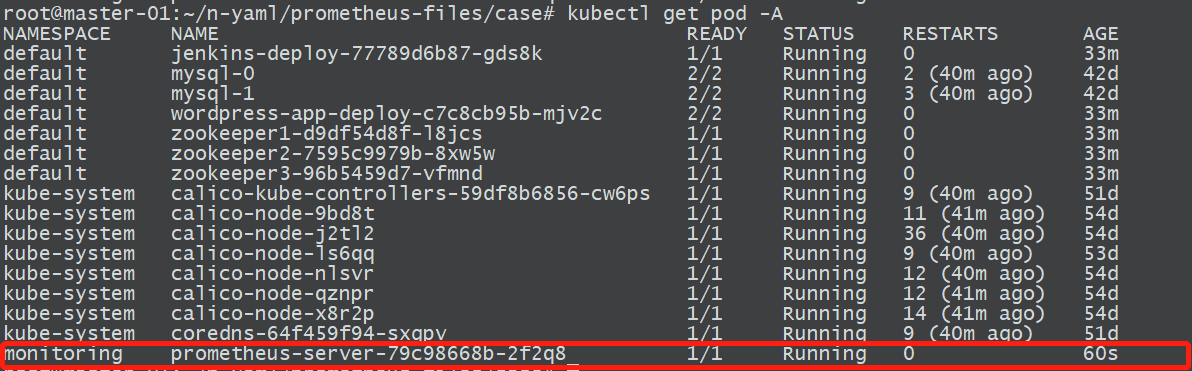
6、创建service
kubectl apply -f prometheus-svc.yaml
---
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitoring
labels:
app: prometheus
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
nodePort: 30090
protocol: TCP
selector:
app: prometheus
component: server

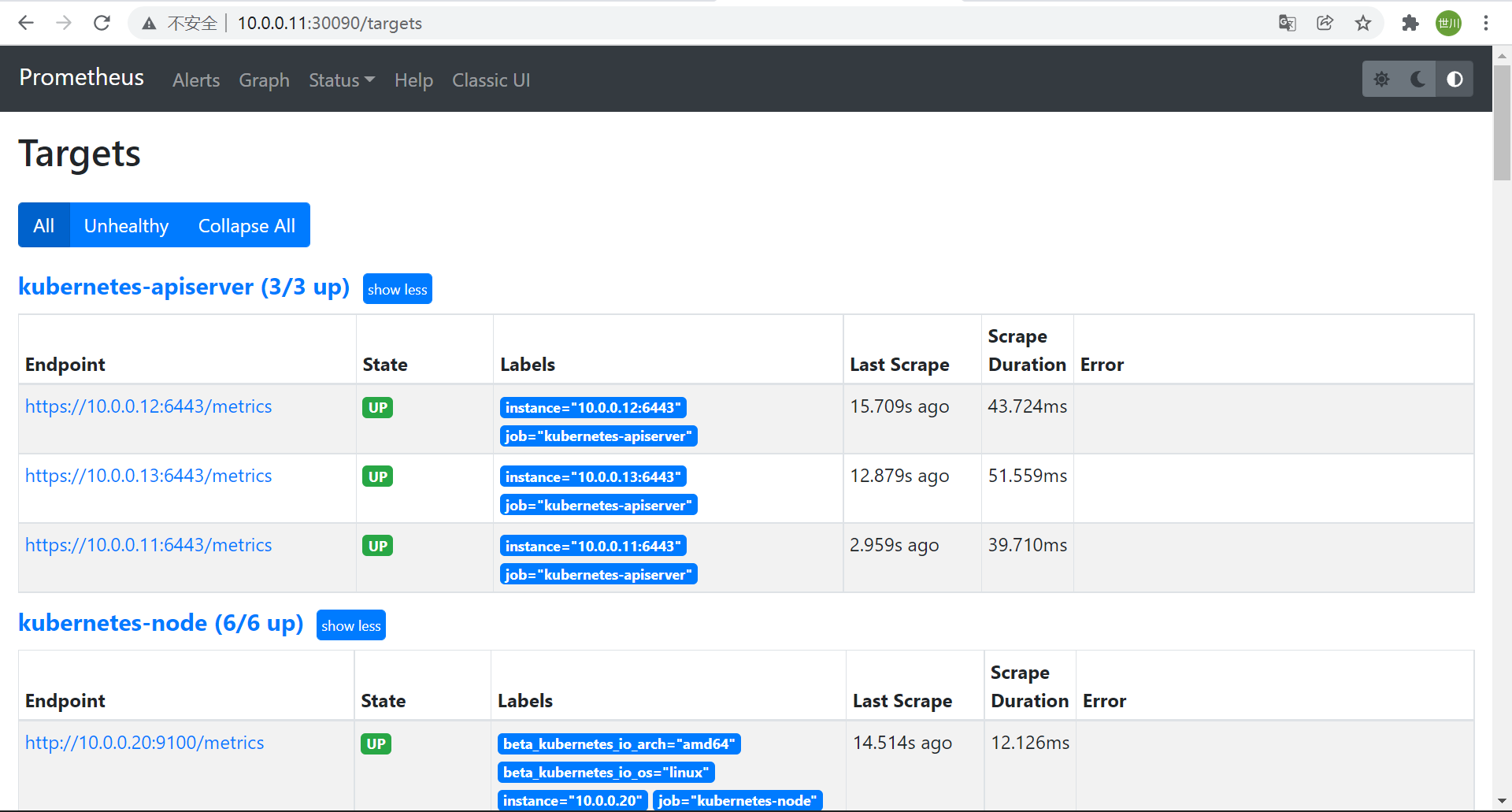
2.2.3 安装cadvisor
监控Pod指标数据需要使⽤cadvisor,cadvisor由⾕歌开源,cadvisor不仅可以搜集⼀台机器上所有运⾏的容器信息,还提供基础查询界⾯和http接⼝,⽅便其他组件如Prometheus进⾏数据抓取,cAdvisor可以对节点机器上的资源及容器进⾏实时监控和性能数据采集,包括CPU使⽤情况、内存使⽤情况、⽹络吞吐量及⽂件系统使⽤情况。
cAdvisor(容器顾问)让容器⽤户了解其运⾏容器的资源使⽤情况和性能状态,cAdvisor⽤于收集、聚合、处理和导出有关正在运⾏的容器的信息,具体来说,对于每个容器都会保存资源隔离参数、历史资源使⽤情况、完整历史资源使⽤情况的直⽅图和⽹络统计信息,此数据按容器和机器范围导出。
https://github.com/google/cadvisor
1、导入cAdvisor镜像
docker pull google/cadvisor
docker tag google/cadvisor harbor.xsc.org/pub-images/cadvisor
docker push harbor.xsc.org/pub-images/cadvisor
2、部署
kubectl apply -f daemonset-deploy-cadvisor.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: cadvisor
namespace: monitoring
spec:
selector:
matchLabels:
app: cAdvisor
template:
metadata:
labels:
app: cAdvisor
spec:
tolerations: #污点容忍,忽略master的NoSchedule
- effect: NoSchedule
key: node-role.kubernetes.io/master
hostNetwork: true
restartPolicy: Always # 重启策略
containers:
- name: cadvisor
image: harbor.xsc.org/pub-images/cadvisor
imagePullPolicy: IfNotPresent # 镜像策略
ports:
- containerPort: 8080
volumeMounts:
- name: root
mountPath: /rootfs
- name: run
mountPath: /var/run
- name: sys
mountPath: /sys
- name: docker
mountPath: /var/lib/docker
volumes:
- name: root
hostPath:
path: /
- name: run
hostPath:
path: /var/run
- name: sys
hostPath:
path: /sys
- name: docker
hostPath:
path: /var/lib/docker
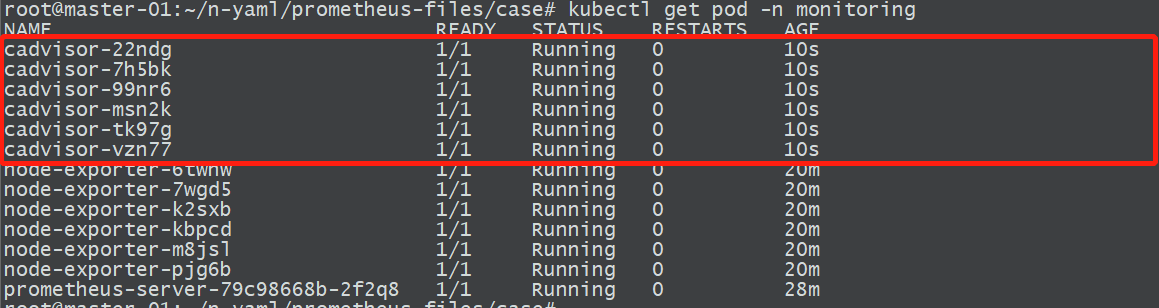
2.2.4 配置prometheus采集cadvisor数据
1、编辑Prometheus配置文件,二进制方式部署的服务器上
vim /app/prometheus/prometheus/prometheus.yml
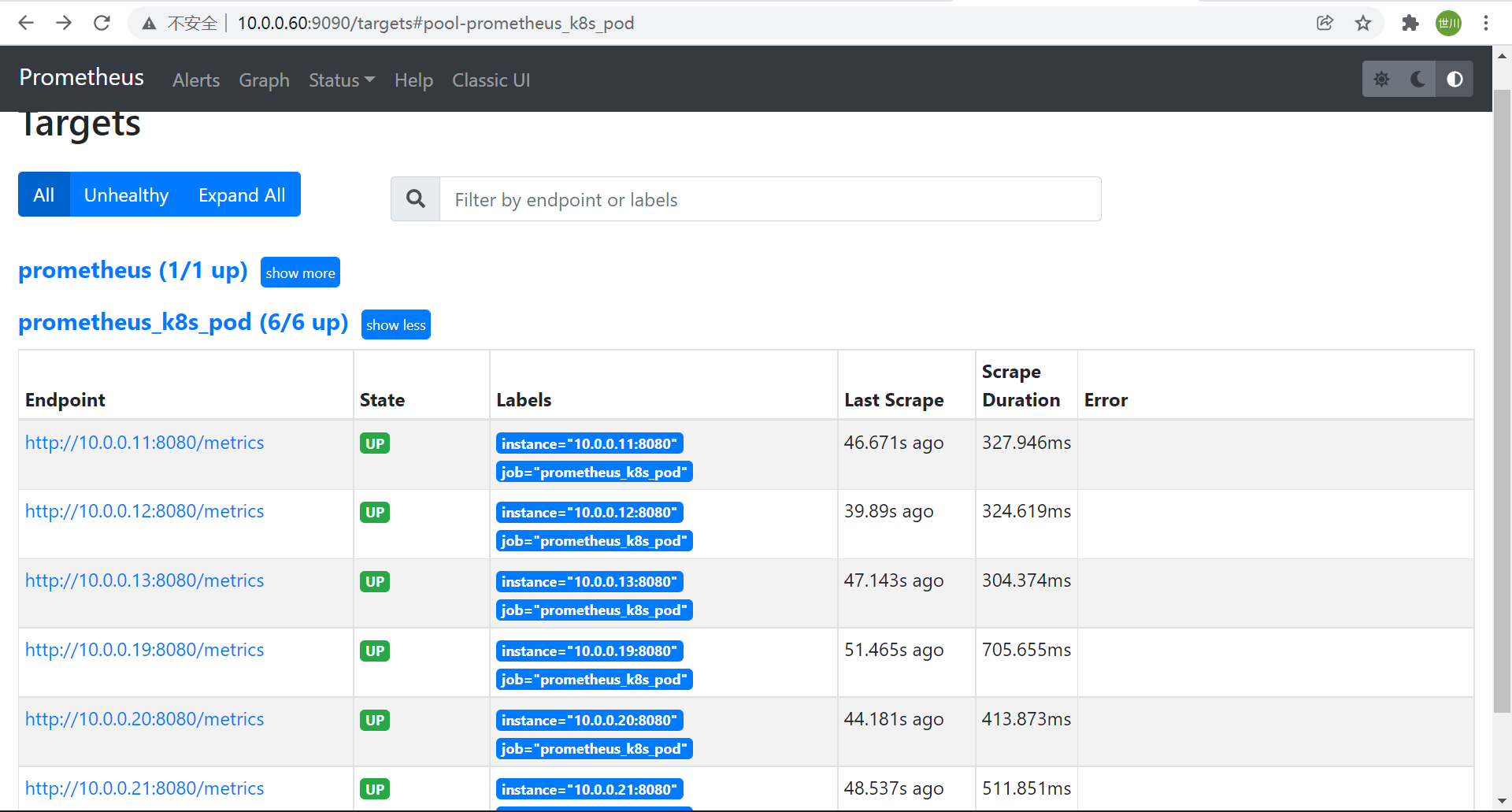
- job_name: "prometheus_k8s_pod"
static_configs:
- targets: ["10.0.0.11:8080","10.0.0.12:8080","10.0.0.13:8080","10.0.0.19:8080","10.0.0.20:8080","10.0.0.21:8080"]
2、重启Prometheus
systemctl restart prometheus.service
2.2.5 grafana添加pod监控模板
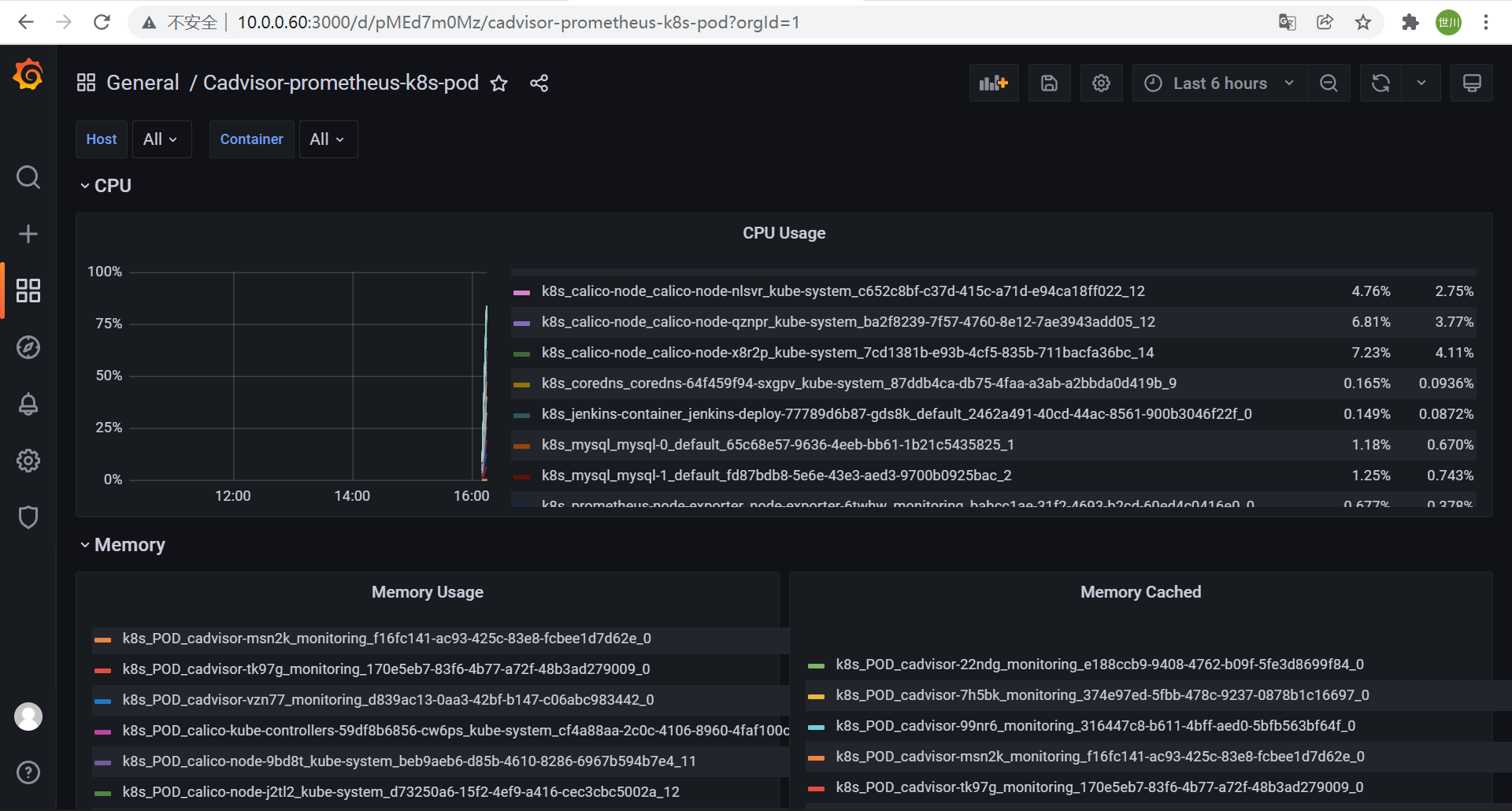
3 PromQL简介
Prometheus提供⼀个函数式的表达式语⾔PromQL (Prometheus Query Language),可以使⽤户实时地查找和聚合时间序列数据,表达式计算结果可以在图表中展示,也可以在Prometheus表达式浏览器中以表格形式展示,或者作为数据源, 以HTTP API的⽅式提供给外部系统使⽤
3.1 PromQL数据基础
3.1.1 数据分类
- 瞬时向量、瞬时数据(instant vector):是⼀组时间序列,每个时间序列包含单个数据样本,例如node_memory_MemTotal_bytes查询当前剩余内存就是⼀个瞬时向量,该表达式的返回值中只会包含该时间序列中的最新的⼀个样本值,⽽相应的这样的表达式称之为瞬时向量表达式,例如:prometheus_http_requests_tota
- 范围向量、范围数据(range vector):是指在任何⼀个时间范围内,抓取的所有度量指标数据,⽐如最近⼀天的⽹卡流量趋势图,例如:prometheus_http_requests_total[5m]
- 标量、纯量数据(scalar):是⼀个浮点数类型的数据值,使⽤node_load1获取到时⼀个瞬时向量,但是可⽤使⽤内置函数scalar()将瞬时向量转换为标量,例如:scalar(sum(node_load1))
-
3.1.2 数据类型
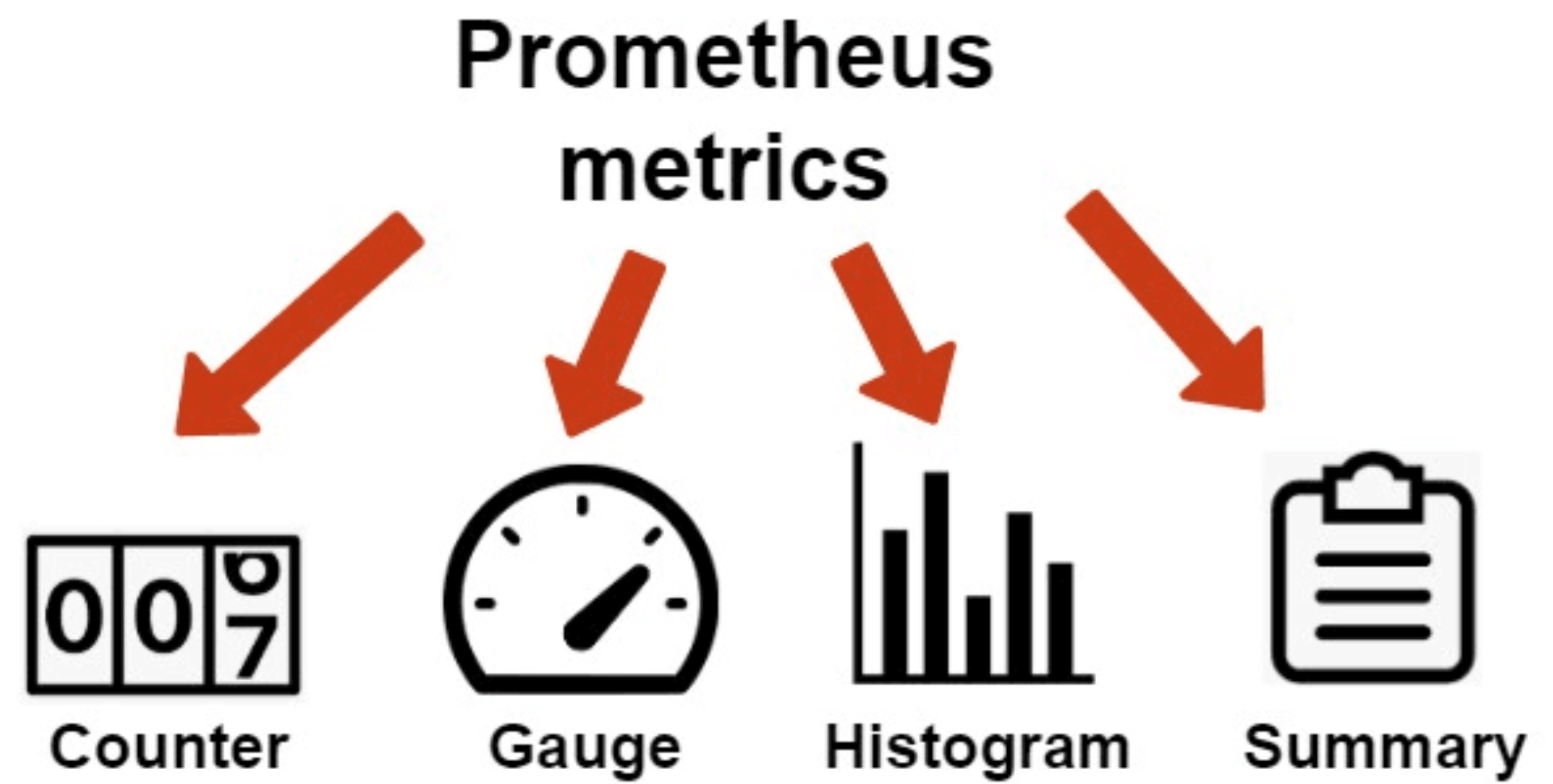
Counter:计数器,Counter类型代表⼀个累积的指标数据,在没有被重置的前提下只增不减,⽐如磁盘I/O总数、nginx的请求总数、⽹卡流经的报⽂总数等。
Gauge:仪表盘,Gauge类型代表⼀个可以任意变化的指标数据,值可以随时增⾼或减少,如带宽速率、CPU负载、内存利⽤率、nginx 活动连接数等。
Histogram:累积直⽅图,Histogram会在⼀段时间范围内对数据进⾏采样(通常是请求持续时间或响应⼤⼩等),假如每分钟产⽣⼀个当前的活跃连接数,那么⼀天就会产⽣1440个数据,查看数据的每间隔的绘图跨度为2⼩时,那么2点的柱状图(bucket)会包含0点到2点即两个⼩时的数据,⽽4点的柱状图(bucket)则会包含0点到4点的数据,⽽6点的柱状图(bucket)则会包含0点到6点的数据。
Summary:摘要,也是⼀组数据,统计的不是区间的个数⽽是统计分位数,从0到1,表示是0%~100%,如下统计的是0、0.25、0.5、0.75、1的数据量分别是多少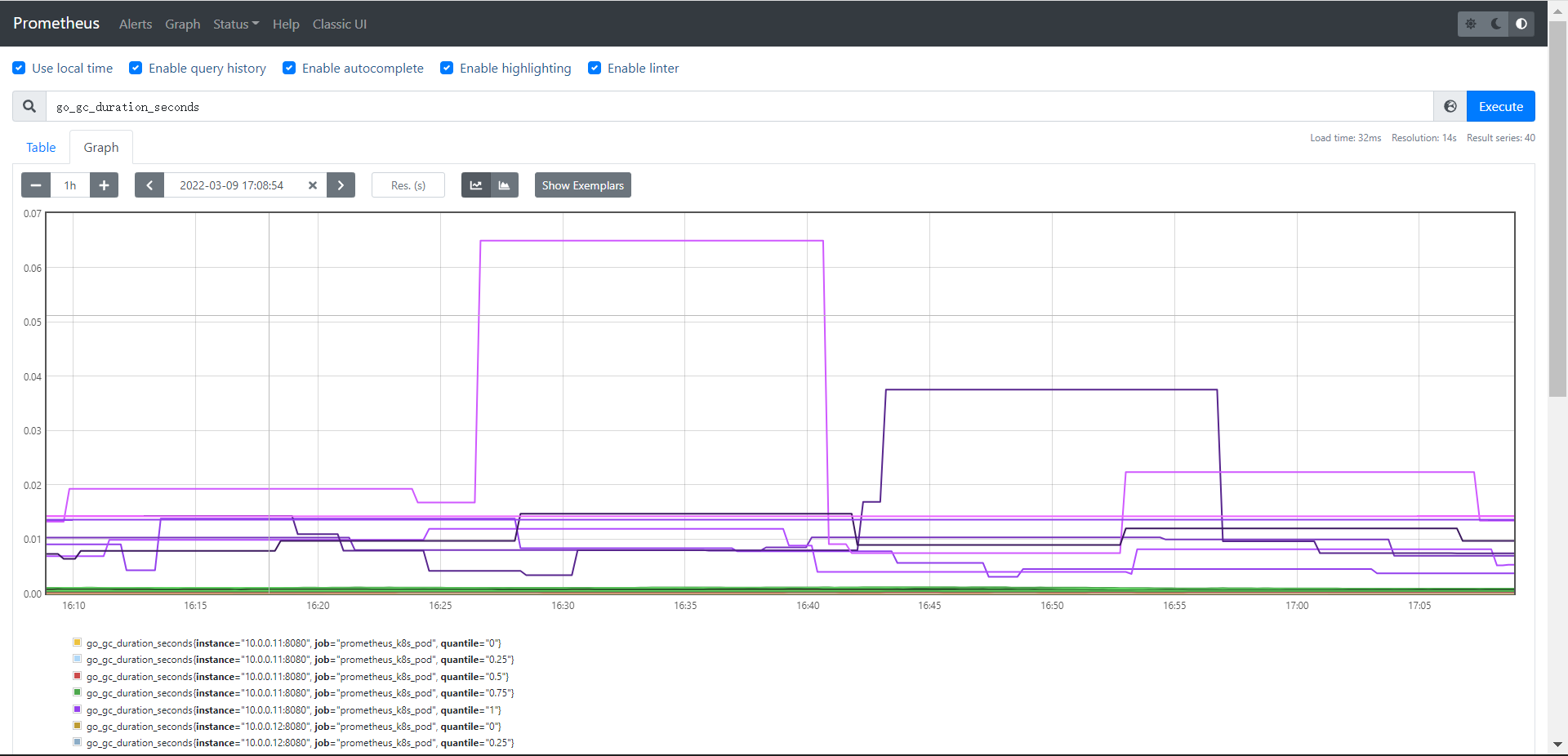
3.2 PromQL-常见指标数据
node_memory_MemTotal_bytes #查询node节点总内存⼤⼩ node_memory_MemFree_bytes #查询node节点剩余可⽤内存 node_memory_MemTotal_bytes{instance="10.0.0.60:9100"} #基于标签查询指定节点的总内存 node_memory_MemFree_bytes{instance="10.0.0.60:9100"} #基于标签查询指定节点的可⽤内存 node_disk_io_time_seconds_total{device="sda"} #查询指定磁盘的每秒磁盘io node_filesystem_free_bytes{device="/dev/sda1",fstype="xfs",mountpoint="/"} #查看指定磁盘的磁盘剩余空间3.3 PromQL-匹配器
= 选择与提供的字符串完全相同的标签,精确匹配。
- != 选择与提供的字符串不相同的标签,去反。
- =~ 选择正则表达式与提供的字符串(或⼦字符串)相匹配的标签。
- !~ 选择正则表达式与提供的字符串(或⼦字符串)不匹配的标签。
查询格式{
node_load1{instance="10.0.0.60:9100"}
node_load1{job="promethues-node"}
node_load1{job="promethues-node",instance="10.0.0.60:9100"} #精确匹配
node_load1{job="promethues-node",instance!="10.0.0.60:9100"} #取反
node_load1{instance=~"10.0.0.*:9100$"} #包含正则且匹配
node_load1{instance!~"10.0.0.60:9100"} #包含正则且取反
3.4 PromQL-时间范围
s 秒
m 分钟
h ⼩时
d 天
w 周
y 年
#瞬时向量表达式,选择当前最新的数据
node_memory_MemTotal_bytes{}
#区间向量表达式,选择以当前时间为基准,查询所有节点node_memory_MemTotal_bytes指标5分钟内的数据
node_memory_MemTotal_bytes{}[5m]
#区间向量表达式,选择以当前时间为基准,查询指定节点node_memory_MemTotal_bytes指标5分钟内的数据
node_memory_MemTotal_bytes{instance="10.0.0.60:9100"}[5m]
3.5 PromQL运算符
+ 加法
- 减法
* 乘法
/ 除法
% 模
^ 幂等
node_memory_MemFree_bytes/1024/1024 #将内存进⾏单位从字节转⾏为兆
node_disk_read_bytes_total{device="sda"} + node_disk_written_bytes_total{device="sda"} #计算磁盘读写数据量
3.6 PromQL聚合函数
3.6.1 max、min、avg
max() #最⼤值
min() #最⼩值
avg() #平均值
计算每个节点的最⼤的流量值:
max(node_network_receive_bytes_total) by (instance)
计算每个节点最近五分钟每个device的最⼤流量
max(rate(node_network_receive_bytes_total[5m])) by (device)
3.6.2 sum、count
sum() #求数据值相加的和(总数)
sum(prometheus_http_requests_total){} 2495 #最近总共请求数为2495次,⽤于计算返回值的总数(如http请求次数)
count() #统计返回值的条数
count(node_os_version){} 2 #⼀共两条返回的数据,可以⽤于统计节点数、pod数量等
count_values() #对value的个数(⾏数)进⾏计数
count_values("node_version",node_os_version) #统计不同的系统版本节点有多少
3.6.3 abs、absent
abs() #返回指标数据的值
abs(sum(prometheus_http_requests_total{handler="/metrics"}))
absent() #如果监指标有数据就返回空,如果监控项没有数据就返回1,可⽤于对监控项设置告警通知
absent(sum(prometheus_http_requests_total{handler="/metrics"}))
3.6.4 stddev、stdvar
stddev() #标准差
stddev(prometheus_http_requests_total) #5+5=10,1+9=10,1+9这⼀组的数据差异就⼤,在系统是数据波动较⼤,不稳定
stdvar() #求⽅差
stdvar(prometheus_http_requests_total)
3.6.5 topk、bottomk
topk() #样本值排名最⼤的N个数据
#取从⼤到⼩的前6个
topk(6, prometheus_http_requests_total)
bottomk() #样本值排名最⼩的N个数据
#取从⼩到⼤的前6个
bottomk(6, prometheus_http_requests_total)
3.6.6 rate、irate
rate() #函数是专⻔搭配counter数据类型使⽤函数,功能是取counter数据类型在这个时间段中平均每秒的增量
平均数
rate(prometheus_http_requests_total[5m])
rate(node_network_receive_bytes_total[5m])
irate() #函数是专⻔搭配counter数据类型使⽤函数,功能是取counter数据类型在这个时间段中平均每秒的峰值
irate(prometheus_http_requests_total[5m])
irate(node_network_receive_bytes_total[5m])
3.6.7 by、without
#by,在计算结果中,只保留by指定的标签的值,并移除其它所有的
sum(rate(node_network_receive_packets_total{instance=~".*"}[10m])) by (instance)
sum(rate(node_memory_MemFree_bytes[5m])) by (increase)
#without,从计算结果中移除列举的instance,job标签,保留其它标签
sum(prometheus_http_requests_total) without (instance,job)
4 Prometheus的服务发现
prometheus 默认是采用pull 方式拉取监控数据的,也就是定时去目标主机上抓取metrics数据,每一个被抓取的目标需要暴露一个HTTP 接口,prometheus通过这个暴露的接口就可以获取到相应的指标数据,这种方式需要由目标服务决定采集的目标有哪些,通过配置在scrape_configs 中的各种job 来实现,无法动态感知新服务,如果后面增加了节点或者组件信息,就得手动修promrtheus配置,并重启promethues,很不方便,所以出现了动态服务发现,动态服务发现能够自动发现集群中的新端点,并加入到配置中,通过服务发现,Prometheus能查询到需要监控的Target 列表,然后轮询这些Target 获取监控数据。
prometheus 获取数据源target 的方式有多种,如静态配置和服务发现配置,prometheus 支持多种服务发现,prometheus 目前支持的服务发现有很多种,如常见的kubernetes_sd_configs、static_configs、dns_sd_configs、consul_sd_configs、file_sd_configs
4.1 kubernetes_sd_configs
Prometheus 与Kubernetes 的API 进行交互,动态的发现Kubernetes 中部署的所有可监控的目标资源,kubernetes_sd_configs发现类型可以配置以下类型之一来发现目标。
- node
- service
- pod
- endpoints
- Endpointslice #对endpoint 进行切片
-
4.1.1 配置文件字段解释
scrape_configs: - job_name: 'kubernetes-node' kubernetes_sd_configs: #基于kubernetes_sd_configs实现服务发现 - role: node #发现node relabel_configs: #重新修改标签label配置configs - source_labels: [__address__] #源标签 regex: '(.*):10250' #匹配__address__,将host部分留下 replacement: '${1}:9100' #将端口换为9100,其中${1}是正则表达式(.*)从__address__捕获到的内容留下host target_label: __address__#目标 action: replace #定义了修改标签后的具体动作 - action: labelmap #赋予新label regex: __meta_kubernetes_node_label_(.+) #正则匹配__meta_kubernetes_node_label_promethues 的relabeling(重新修改标签)功能很强大,它能够在抓取到目标实例之前把目标实例的元数据标签动态重新修改,动态添加或者覆盖标签,prometheus 加载target 成功之后,在Target 实例中,都包含一些Metadata 标签信息,
4.1.1.1 默认的标签
address: 以
: 格式显示目标targets 的地址 - scheme: 采集的目标服务地址的Scheme 形式,HTTP 或者HTTPS
-
4.1.1.2 修改标签字段
为了更好的识别监控指标,便于后期调用数据绘图、告警等需求,prometheus 支持对发现的目标进行label 修改,在两个阶段可以重新标记
relabel_configs:在采集之前(比如在采集数据之前重新定义元标签),可以使relabel_configs 添加一些标签、也可以只采集特定目标或过滤目标。
metric_relabel_configs:如果是已经抓取到指标数据时,可以使用metric_relabel_configs 做最后的重新标记和过滤。
4.1.1.3 标签字段
source_labels:源标签,没有经过relabel 处理之前的标签名字
- target_label:通过action 处理之后的新的标签名字
- regex:正则表达式,匹配源标签
replacement:通过分组替换后标签(target_label)对应的值
4.1.1.4 action动作
replace:替换标签值,根据regex 正则匹配到源标签的值,使用replacement 来引用表达式匹配的分组
- keep:满足regex 正则条件的实例进行采集,把source_labels 中没有匹配到regex 正则内容的Target实例丢掉,即只采集匹配成功的实例。
- drop:满足regex 正则条件的实例不采集,把source_labels 中匹配到regex 正则内容的Target 实例丢掉,即只采集没有匹配到的实例。
- hashmod:使用hashmod 计算source_labels 的Hash 值并进行对比,基于自定义的模数取模,以实现对目标进行分类、重新赋值等功能
- labelmap:匹配regex 所有标签名称,然后复制匹配标签的值进行分组,通过replacement 分组引用(${1},${2},…)替代
- labelkeep:匹配regex 所有标签名称,其它不匹配的标签都将从标签集中删除
- labeldrop:匹配regex 所有标签名称,其它匹配的标签都将从标签集中删除
4.1.2 案例
4.1.2.1 监控api-server
apiserver 作为Kubernetes 最核心的组件,它的监控也是非常有必要的,对于apiserver 的监控,我们可以直接通过kubernetes 的service 来获取
1、configmap文件 ```shell
kind: ConfigMap apiVersion: v1 metadata: labels: app: prometheus name: prometheus-config namespace: monitoring data: prometheus.yml: | global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 1m scrape_configs:
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
**2、重新apply configmap和Prometheus应用**<br />**3、在Prometheus界面查看targets**<br />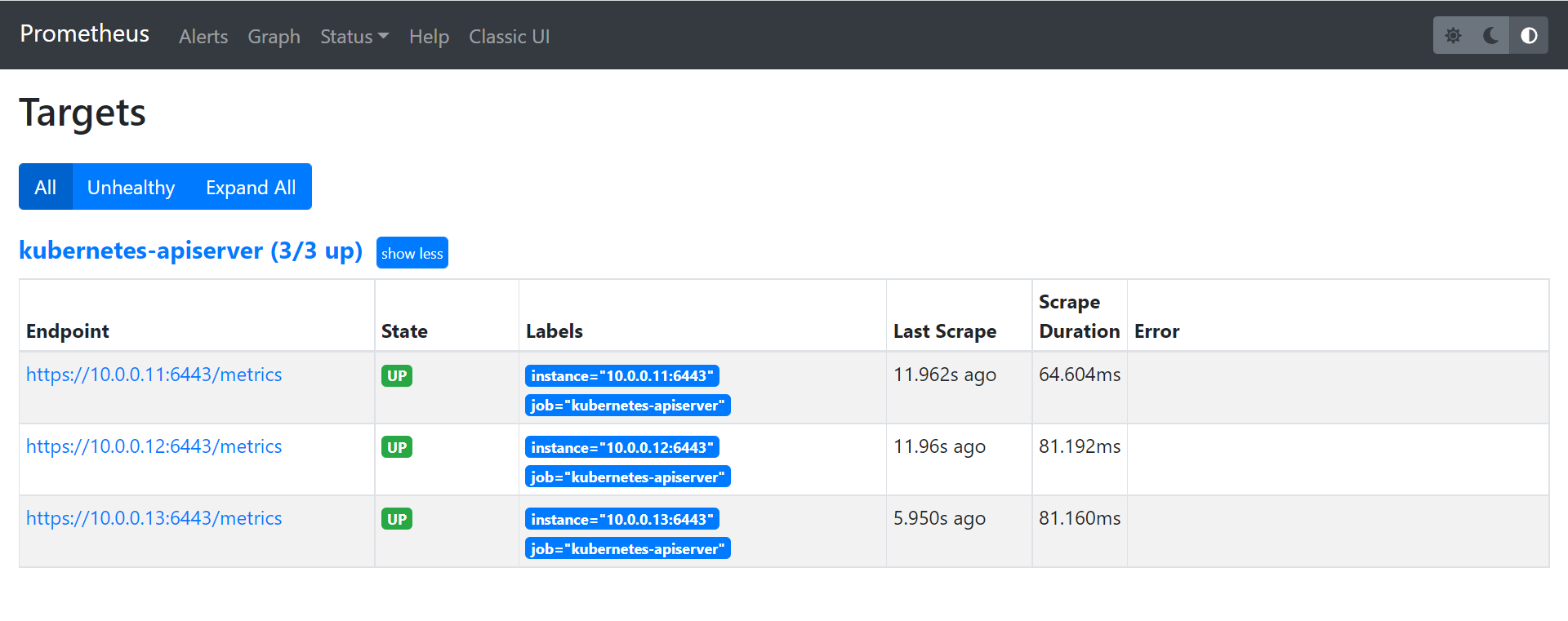
<a name="uNFcQ"></a>
#### 4.1.2.2 node和cadvisor发现
**1、configmap文件**
```shell
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-node-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
2、重新apply configmap和Prometheus应用
3、在Prometheus界面查看targets
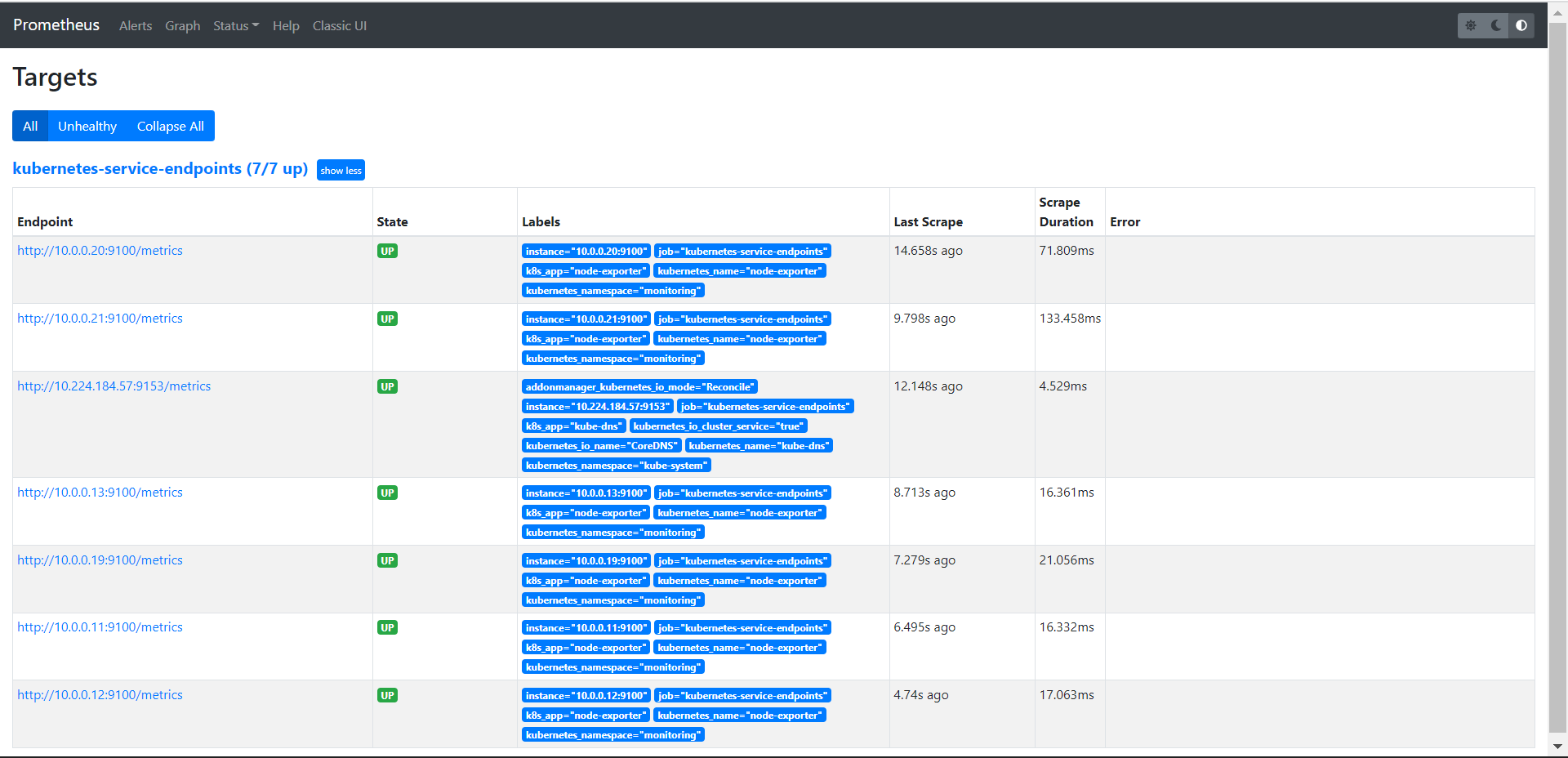
4.1.2.3 发现endpoint
1、configmap文件
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
2、重新apply configmap和Prometheus应用
3、在Prometheus界面查看targets
4.1.3 Prometheus部署在非K8S环境对服务的发现
1、prometheus.yml配置文件
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
- job_name: 'kubernetes-apiservers-monitor'
kubernetes_sd_configs:
- role: endpoints
api_server: https://10.0.0.248:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /app/prometheus/prometheus/k8s.token
scheme: https
tls_config:
insecure_skip_verify: true
bearer_token_file: /app/prometheus/prometheus/k8s.token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- target_label: __address__
replacement: 10.0.0.248:6443
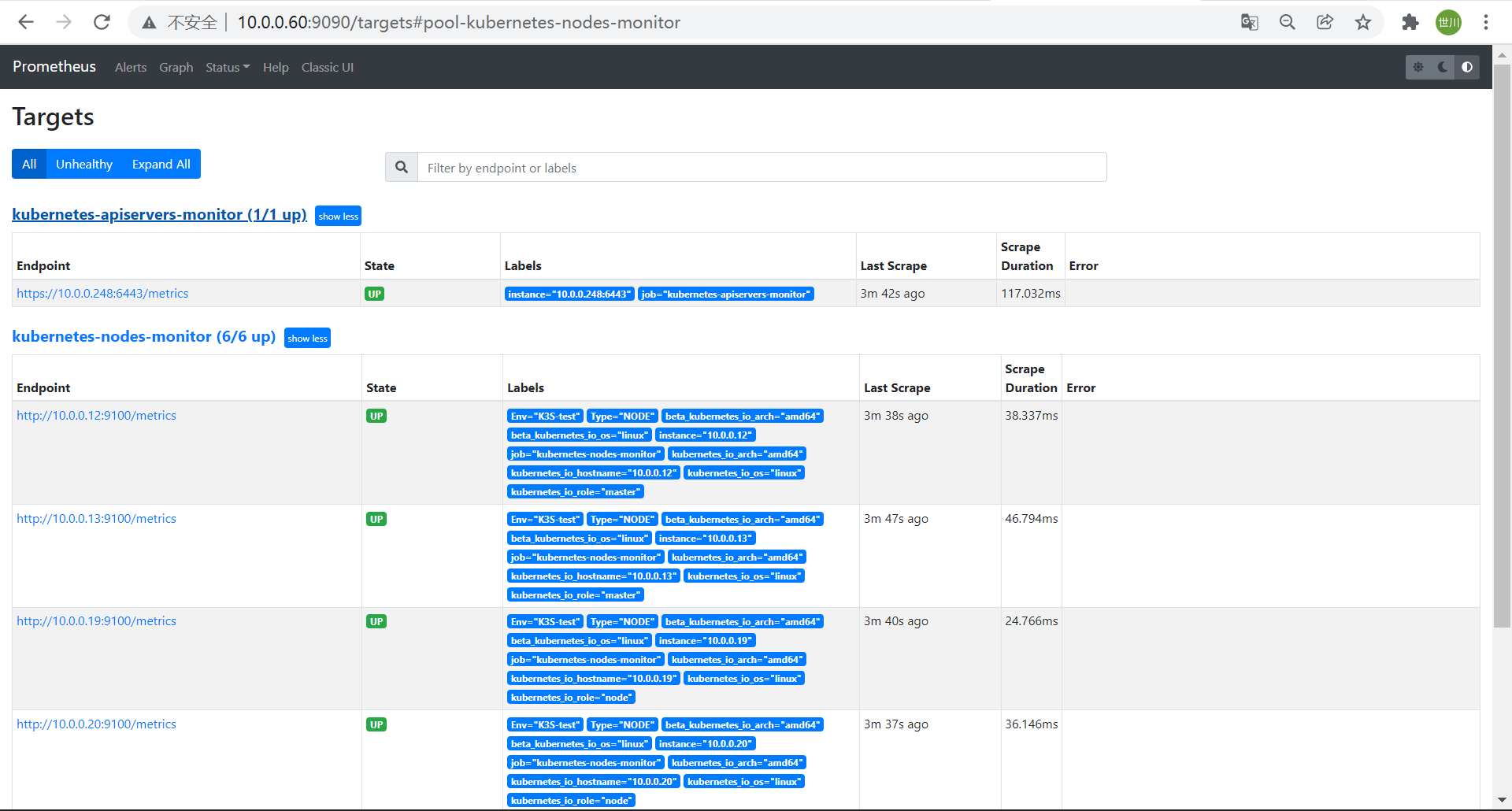
- job_name: 'kubernetes-nodes-monitor'
scheme: http
tls_config:
insecure_skip_verify: true
bearer_token_file: /app/prometheus/prometheus/k8s.token
kubernetes_sd_configs:
- role: node
api_server: https://10.0.0.248:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /app/prometheus/prometheus/k8s.token
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- source_labels: [__meta_kubernetes_node_label_failure_domain_beta_kubernetes_io_region]
regex: '(.*)'
replacement: '${1}'
action: replace
target_label: LOC
- source_labels: [__meta_kubernetes_node_label_failure_domain_beta_kubernetes_io_region]
regex: '(.*)'
replacement: 'NODE'
action: replace
target_label: Type
- source_labels: [__meta_kubernetes_node_label_failure_domain_beta_kubernetes_io_region]
regex: '(.*)'
replacement: 'K3S-test'
action: replace
target_label: Env
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-pods-monitor'
kubernetes_sd_configs:
- role: pod
api_server: https://10.0.0.248:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /app/prometheus/prometheus/k8s.token
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- source_labels: [__meta_kubernetes_pod_label_pod_template_hash]
regex: '(.*)'
replacement: 'K8S-test'
action: replace
target_label: Env
2、创建一个sa账号和集群角色并绑定,拿到secret的token信息,保存至/app/prometheus/prometheus/k8s.token处。
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
#apiVersion: rbac.authorization.k8s.io/v1beta1
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitoring
4.2 static_configs
每当有一个新的目标实例需要监控,都需要手动修改配置文件配置目标target,并重启Prometheus服务
prometheus.yml配置示例:
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "prometheus_node_exporter"
static_configs:
- targets: ["10.0.0.60:9100"]
- job_name: "prometheus_k8s_pod"
static_configs:
- targets: ["10.0.0.11:8080","10.0.0.12:8080","10.0.0.13:8080","10.0.0.19:8080","10.0.0.20:8080","10.0.0.21:8080"]
4.3 consul_sd_configs
Prometheus 一直监视consul 服务,当发现在consul中注册的服务有变化,prometheus 就会自动监控到所有注册到consul 中的目标资源
4.3.1 consul简介及部署
Consul 是分布式k/v 数据存储集群,目前常用于服务的服务注册和发现。官网https://www.consul.io/
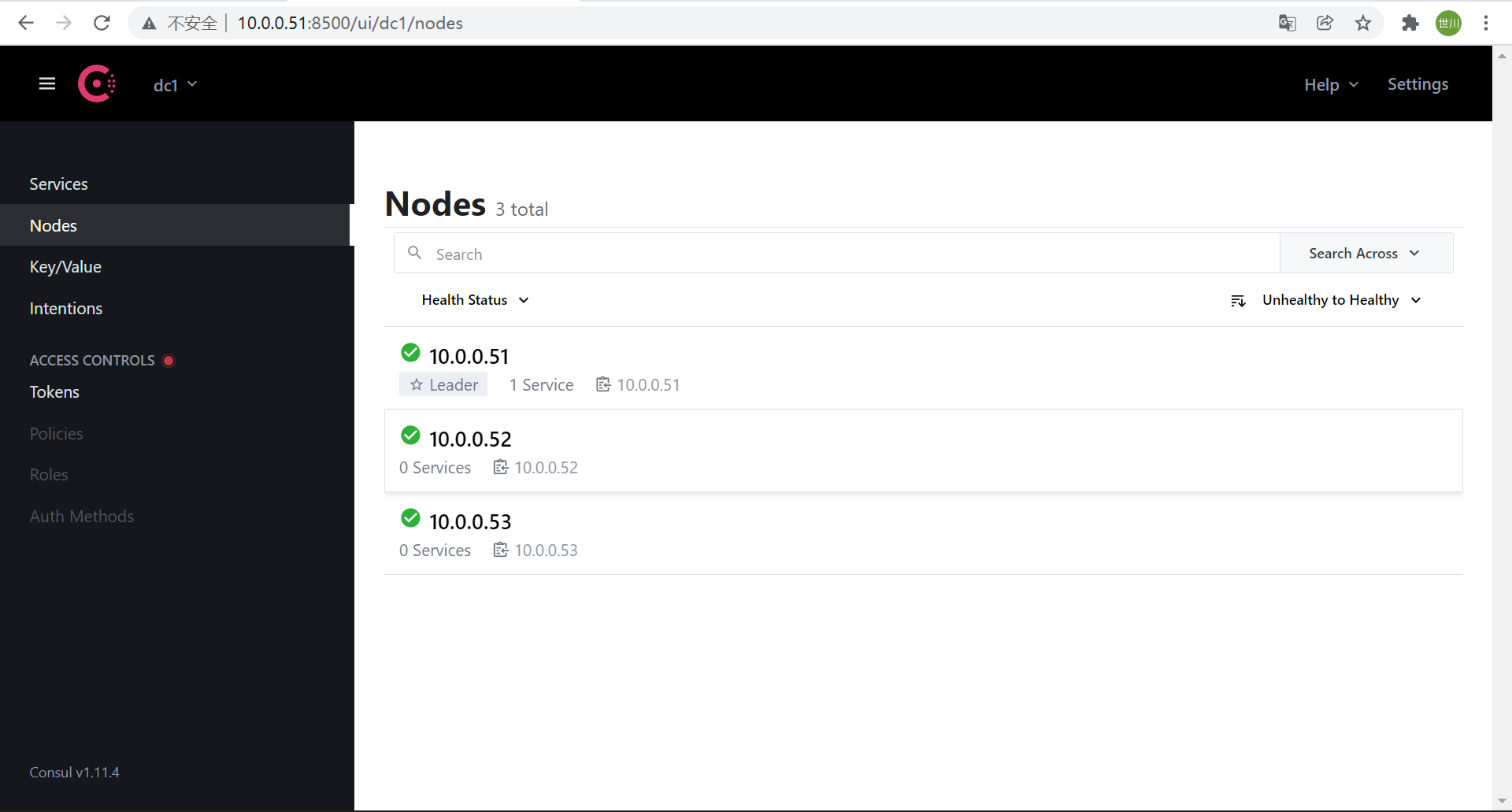
部署consul三节点集群环境
部署节点:10.0.0.51,10.0.0.52,10.0.0.53
1、上传安装包、解压并拷贝至另外两个节点目录
[root@kafka-01 ~]# unzip consul_1.11.4_linux_amd64.zip
[root@kafka-01 ~]# ll
total 140480
-rwxr-xr-x 1 root root 105445918 Mar 1 02:44 consul
-rw-r--r-- 1 root root 38403268 Mar 11 14:29 consul_1.11.4_linux_amd64.zip
[root@kafka-01 ~]# cp consul /usr/local/bin/
[root@kafka-01 ~]# scp consul 10.0.0.52:/usr/local/bin/ 100% 101MB 76.4MB/s 00:01
[root@kafka-01 ~]# scp consul 10.0.0.53:/usr/local/bin/
2、创建数据目录
mkdir /data/consul/ -p
3、启动
node1:
nohup consul agent -server -bootstrap -bind=10.0.0.51 -client=10.0.0.51 -data-dir=/data/consul -ui -node=10.0.0.51 &
node2:
nohup consul agent -bind=10.0.0.52 -client=10.0.0.52 -data-dir=/data/consul -node=10.0.0.52 -join=10.0.0.51 &
node3:
nohup consul agent -bind=10.0.0.53 -client=10.0.0.53 -data-dir=/data/consul -node=10.0.0.53 -join=10.0.0.51 &
4.3.2 consul_sd_config服务发现
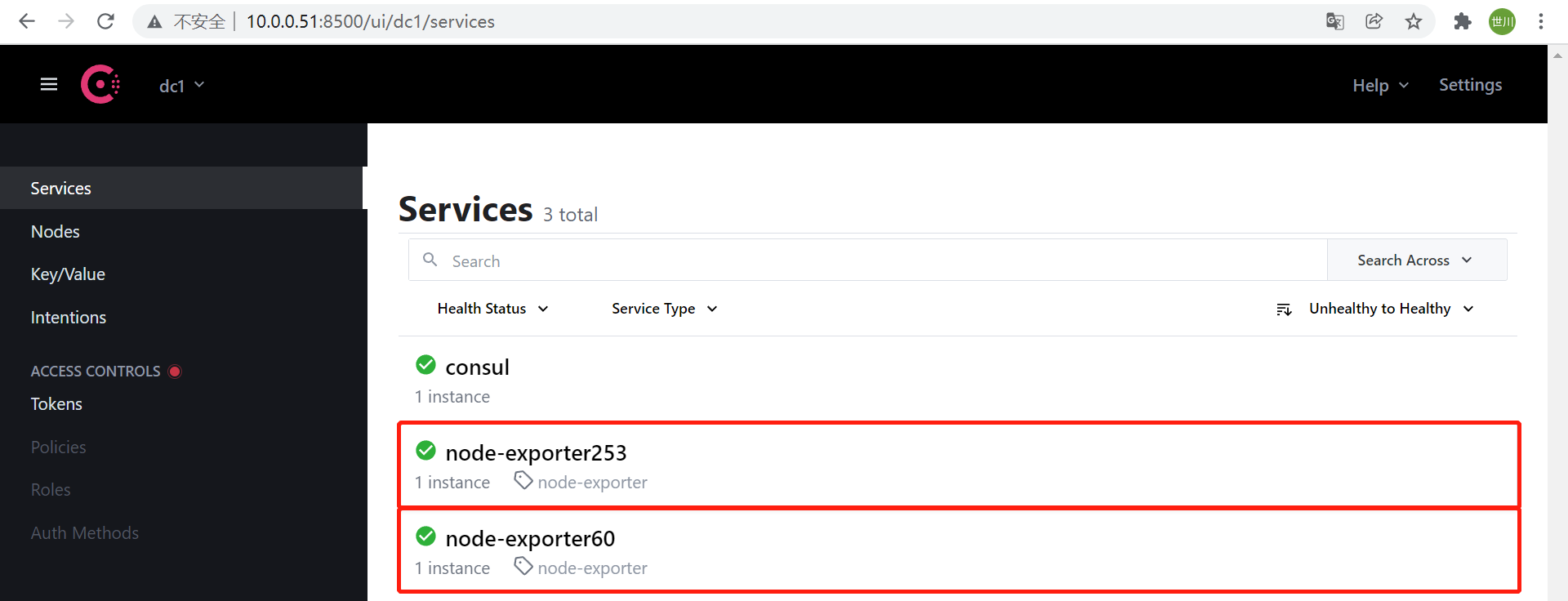
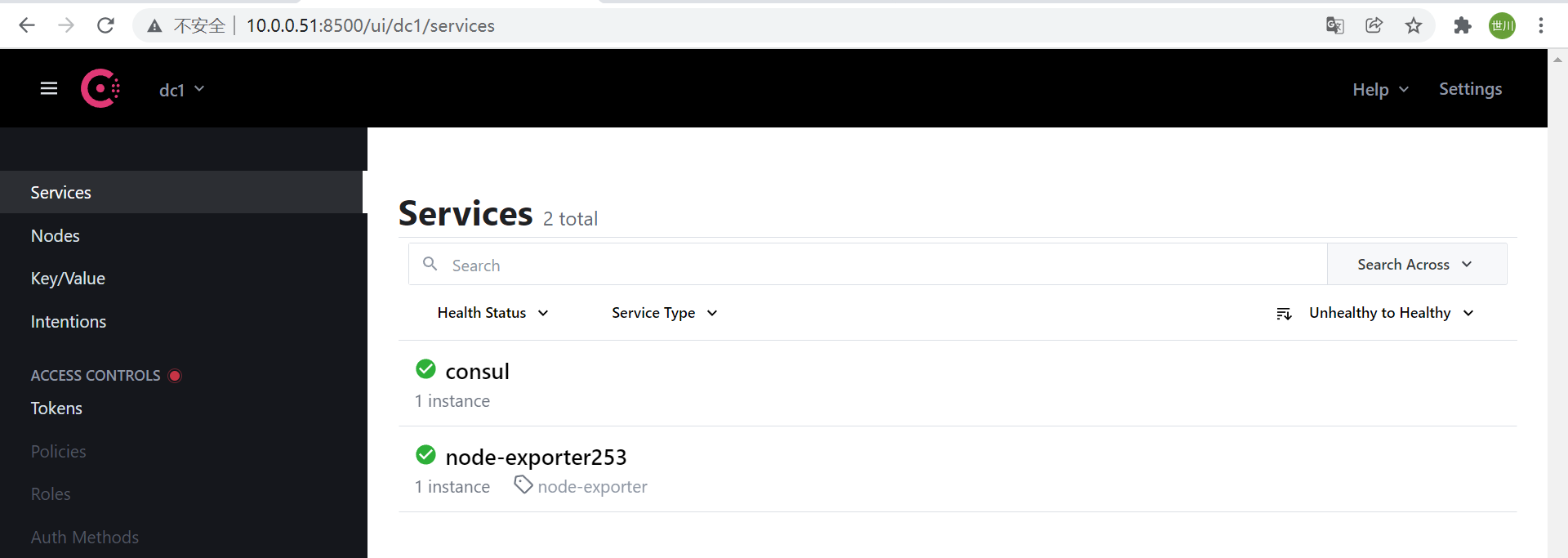
1、通过命令行手动将node节点注册到consul
curl -X PUT -d '{"id": "node-exporter253","name": "node-exporter253","address": "10.0.0.253","port":9100,"tags": ["node-exporter"],"checks": [{"http": "http://10.0.0.253:9100/","interval": "5s"}]}' http://10.0.0.51:8500/v1/agent/service/register
curl -X PUT -d '{"id": "node-exporter60","name": "node-exporter60","address": "10.0.0.60","port":9100,"tags": ["node-exporter"],"checks": [{"http": "http://10.0.0.60:9100/","interval": "5s"}]}' http://10.0.0.51:8500/v1/agent/service/register
2、配置Prometheus配置文件
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
- job_name: consul
honor_labels: true
metrics_path: /metrics
scheme: http
consul_sd_configs:
- server: 10.0.0.51:8500
services: [] #发现的目标服务名称,空为所有服务,可以写servicea,servcieb,servicec
- server: 10.0.0.52:8500
services: []
- server: 10.0.0.53:8500
services: []
relabel_configs:
- source_labels: ['__meta_consul_tags']
target_label: 'product'
- source_labels: ['__meta_consul_dc']
target_label: 'idc'
- source_labels: ['__meta_consul_service']
regex: "consul"
action: drop
3、重启Prometheus服务并验证界面
systemctl restart prometheus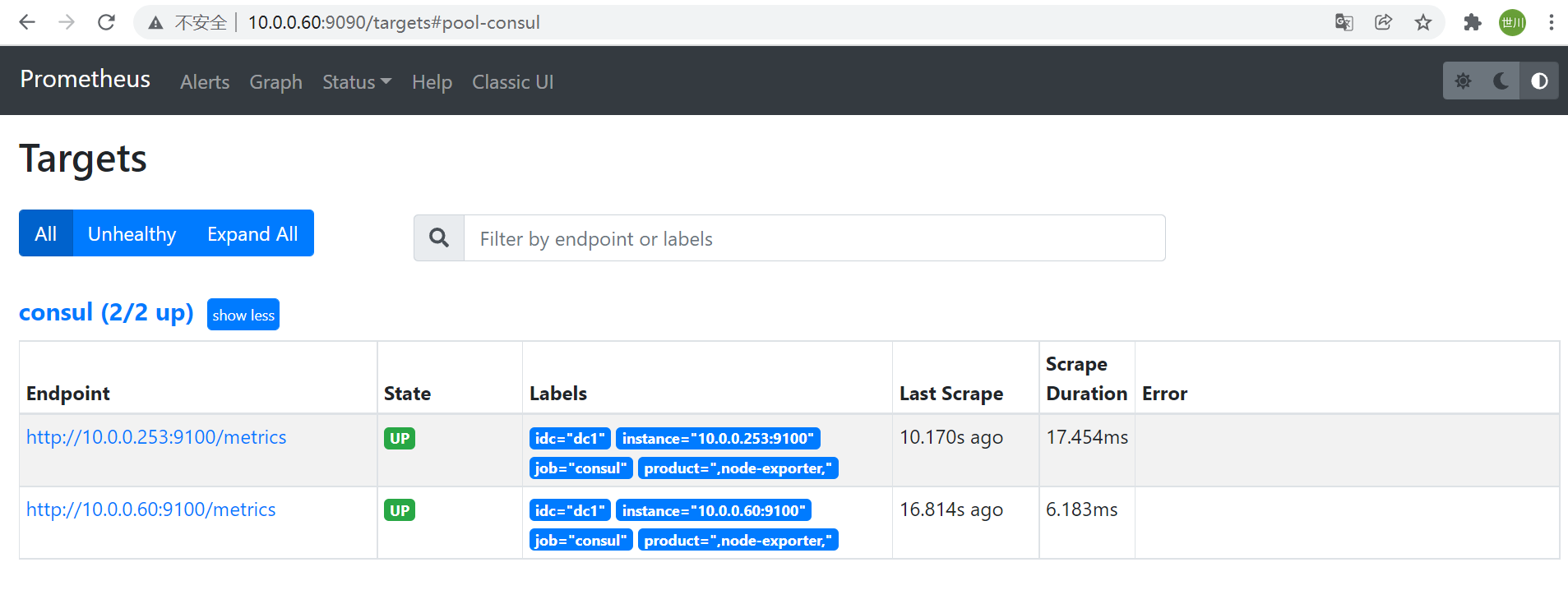
4、删除注册
curl --request PUT http://10.0.0.51:8500/v1/agent/service/deregister/node-exporter60
4.4 file_sd_configs
1、file_sd文件
vim sd_my_server.json
[
{
"targets": ["10.0.0.60:9100","10.0.0.253:9100"]
}
]
2、Prometheus配置文件
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
- job_name: 'file_sd_my_server'
file_sd_configs:
- files:
- /app/prometheus/sd_file/sd_my_server.json
refresh_interval: 10s
3、重启Prometheus服务,界面验证
systemctl restart prometheus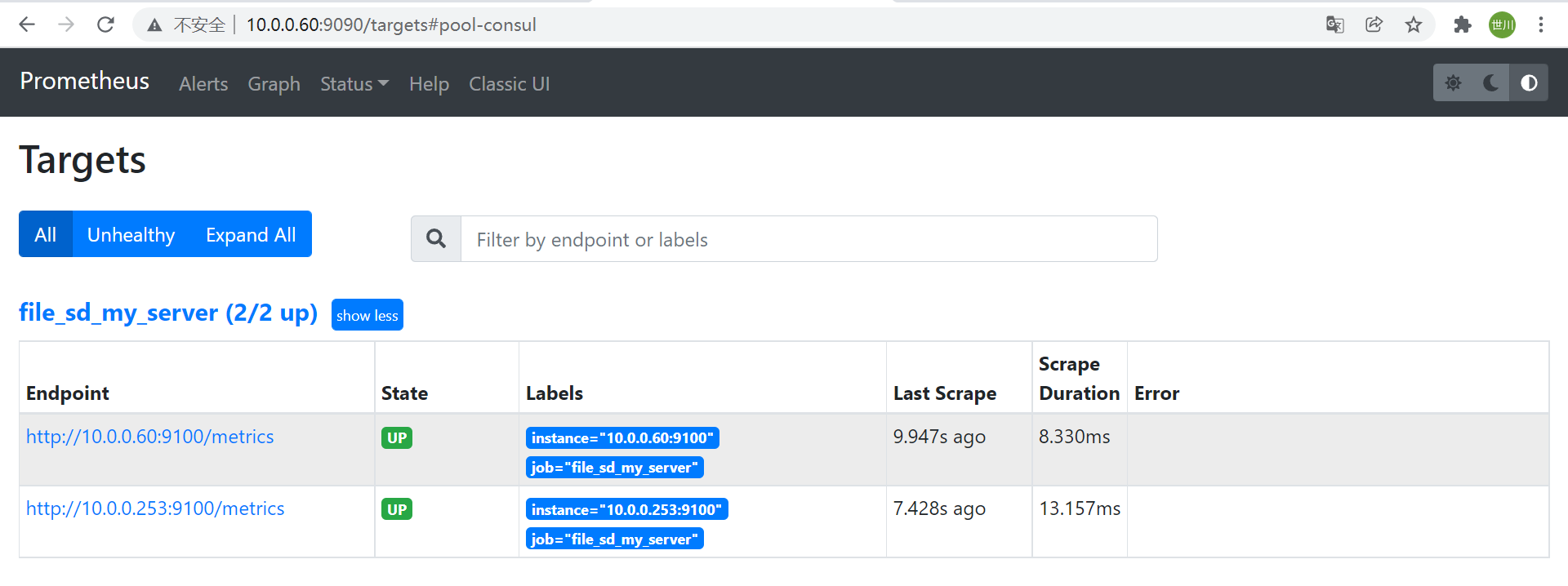
4.5 dns_sd_configs
基于DNS 的服务发现允许配置指定一组DNS 域名,这些域名会定期查询以发现目标列表,域名需要可以被配置的DNS 服务器解析为IP,此服务发现方法仅支持基本的DNS A、AAAA 和SRV 记录查询。
- A 记录: 域名解析为IP
SRV:SRV 记录了哪台计算机提供了具体哪个服务,格式为:自定义的服务的名字.协议的类型.域名(例如:_example-server._tcp.www.mydns.com)
prometheus 会对收集的指标数据进行重新打标,重新标记期间,可以使用以下元标签: __meta_dns_name: 产生发现目标的记录名称 __meta_dns_srv_record_target: SRV 记录的目标字段 __meta_dns_srv_record_port: SRV 记录的端口字段1、配置域名解析
在DNS服务上配置好相应的域名解析,经过个人实验,将域名解析配置在/etc/hosts文件中无效,还得使用DNS服务器才可以
2、Prometheus配置文件- job_name: "prometheus" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. - job_name: 'dns-server-name-monitor' metrics_path: "/metrics" dns_sd_configs: - names: ["infra.xsc.org","monitor.xsc.org"] type: A port: 91005 Kube-state-metrics
Kube-state-metrics通过监听API Server 生成有关资源对象的状态指标,比如Deployment、Node、Pod,需要注意的是kube-state-metrics 只是简单的提供一个metrics 数据,并不会存储这些指标数据,所以我们可以使用Prometheus 来抓取这些数据然后存储,主要关注的是业务相关的一些元数据,比如Deployment、Pod、副本状态等;调度了多少个replicas,现在可用的有几个,多少个Pod是running/stopped/terminated 状态,Pod 重启了多少次,有多少job 在运行中。
https://github.com/kubernetes/kube-state-metrics5.1 部署
kubectl apply -f kube-state-metrics-deployment.yaml ```yaml apiVersion: apps/v1 kind: Deployment metadata: name: kube-state-metrics namespace: kube-system spec: replicas: 1 selector: matchLabels:
app: kube-state-metricstemplate: metadata:
labels: app: kube-state-metricsspec:
serviceAccountName: kube-state-metrics containers: - name: kube-state-metrics image: bitnami/kube-state-metrics:2.2.4 ports: - containerPort: 8080
—-
apiVersion: v1 kind: ServiceAccount metadata: name: kube-state-metrics
namespace: kube-system
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: kube-state-metrics rules:
- apiGroups: [“”] resources: [“nodes”, “pods”, “services”, “resourcequotas”, “replicationcontrollers”, “limitranges”, “persistentvolumeclaims”, “persistentvolumes”, “namespaces”, “endpoints”] verbs: [“list”, “watch”]
- apiGroups: [“extensions”] resources: [“daemonsets”, “deployments”, “replicasets”] verbs: [“list”, “watch”]
- apiGroups: [“apps”] resources: [“statefulsets”] verbs: [“list”, “watch”]
- apiGroups: [“batch”] resources: [“cronjobs”, “jobs”] verbs: [“list”, “watch”]
- apiGroups: [“autoscaling”] resources: [“horizontalpodautoscalers”] verbs: [“list”, “watch”]
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: kube-state-metrics roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kube-state-metrics subjects:
- kind: ServiceAccount name: kube-state-metrics namespace: kube-system
apiVersion: v1 kind: Service metadata: annotations: prometheus.io/scrape: ‘true’ name: kube-state-metrics namespace: kube-system labels: app: kube-state-metrics spec: type: NodePort ports:
- name: kube-state-metrics
port: 8080
targetPort: 8080
nodePort: 31666
protocol: TCP
selector:
app: kube-state-metrics
```
kube metrics界面查看

5.2 Prometheus采集数据
```yaml - job_name: “kube-state-metrics”
static_configs:
- targets: [“10.0.0.11:31666”]
service文件**重启Prometheus并验证状态**<br />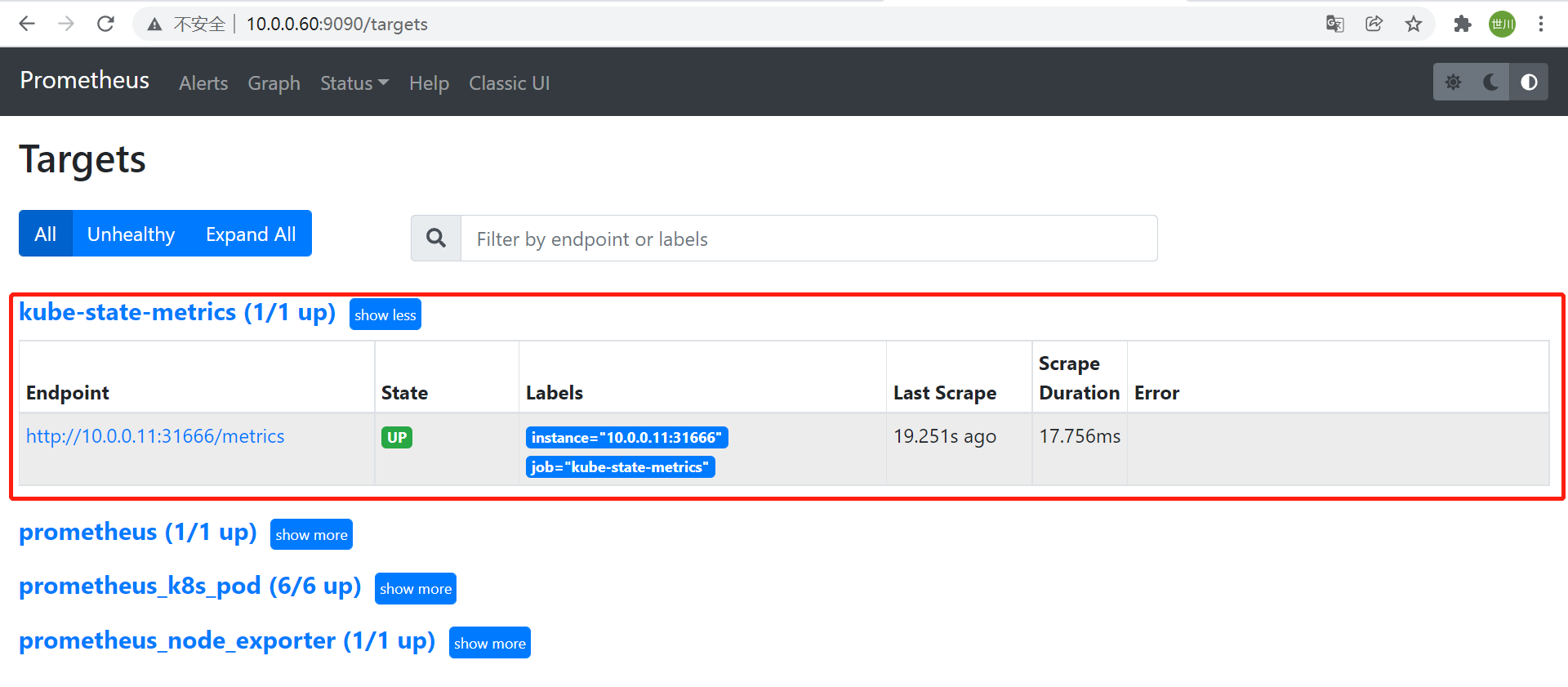 <a name="P5sHO"></a> ## 5.3 grafana导入模板 13332<br />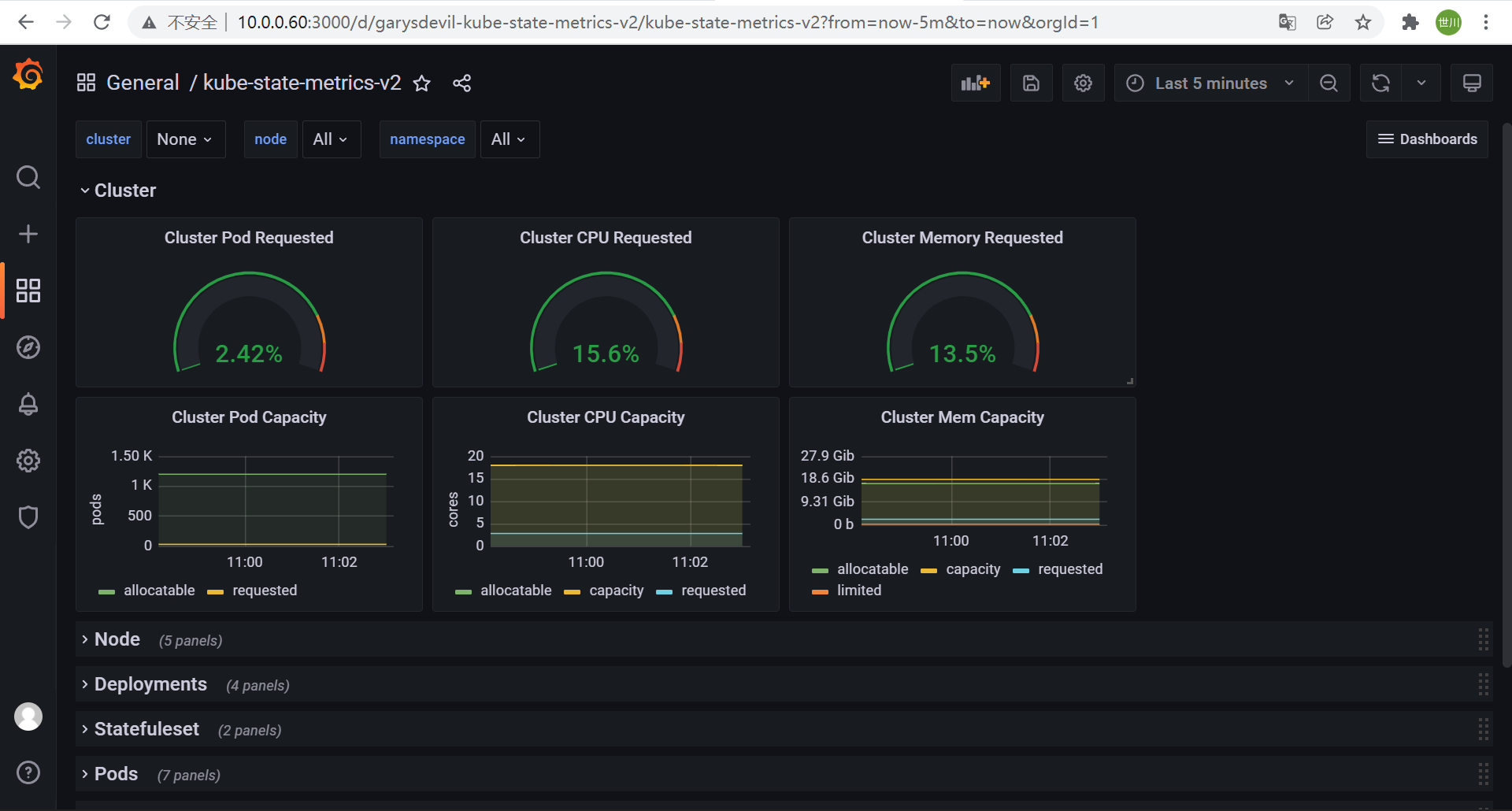 <a name="grUWm"></a> # 6 扩展监控 <a name="pNDd7"></a> ## 6.1 监控mysql <a name="ViSAq"></a> ### 6.1.1 部署mysqld-exporter [https://prometheus.io/download/#mysqld_exporter](https://prometheus.io/download/#mysqld_exporter)<br />mysqld-exporter并非一定要部署在mysql所在节点上,只要可访问即可 ```sql tar xf mysqld_exporter-0.14.0.linux-amd64.tar.gz mv mysqld_exporter-0.14.0.linux-amd64 /app/mysqld_exporter
创建my.cnf文件[Unit] Description=Prometheus Node Exporter After=network.target [Service] ExecStart=/app/mysqld_exporter/mysqld_exporter --config.my-cnf=/app/mysqld_exporter/my.cnf [Install] WantedBy=multi-user.target
创建mysql监控用户[client] host=10.0.0.191 user=mysql_exporter password=abc123.. port=3307
启动mysqld_exporter并验证CREATE USER 'mysql_exporter'@'10.0.0.%' IDENTIFIED BY 'abc123..'; GRANT PROCESS,REPLICATION CLIENT,SELECT ON *.* TO 'mysql_exporter'@'10.0.0.%';
systemctl start mysqld_exporter
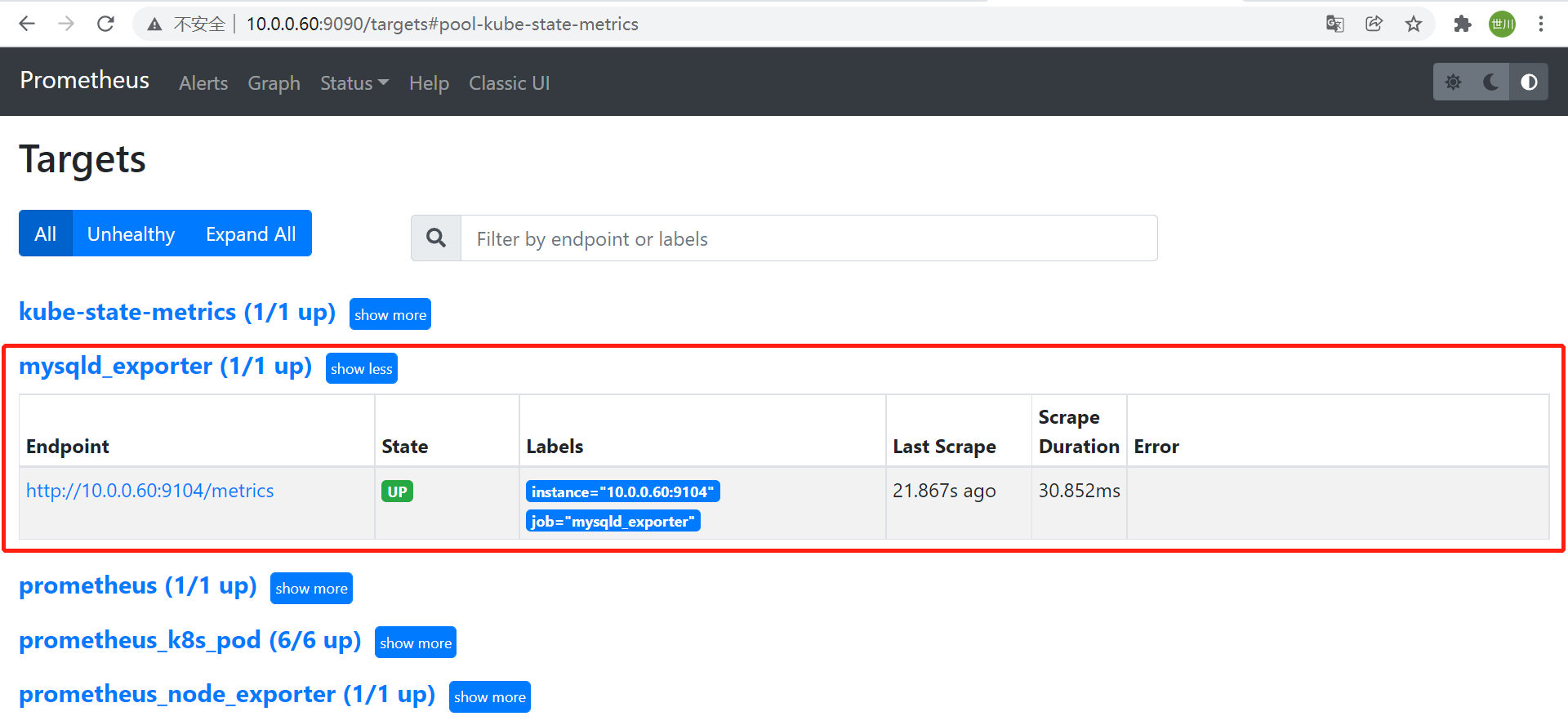
6.1.2 配置Prometheus监控
```shell
- targets: [“10.0.0.11:31666”]
- job_name: “mysqld_exporter”
static_configs:
- targets: [“10.0.0.60:9104”]
```
重启Prometheus并验证
grafana导入模板
11323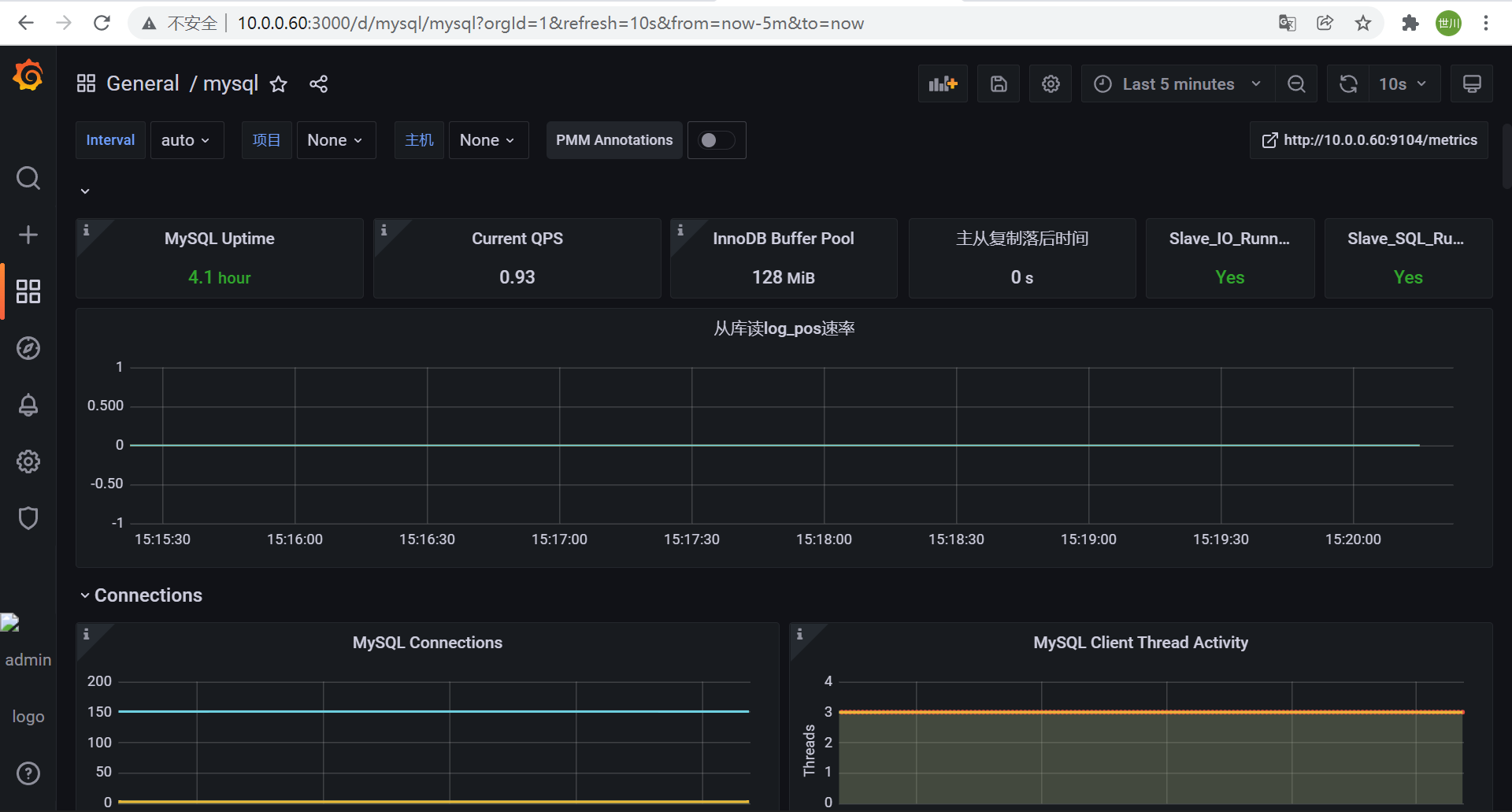
- targets: [“10.0.0.60:9104”]
```
重启Prometheus并验证
6.2 监控redis
6.2.1 部署redis以及exporter
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
namespace: app
spec:
replicas: 1
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
spec:
containers:
- name: redis
image: redis:4.0.14
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 6379
- name: redis-exporter
image: oliver006/redis_exporter:latest
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 9121
---
kind: Service #service 类型
apiVersion: v1
metadata:
# annotations:
# prometheus.io/scrape: 'false'
name: redis-redis-service
namespace: app
spec:
selector:
app: redis
ports:
- nodePort: 31081
name: redis
port: 6379
protocol: TCP
targetPort: 6379
type: NodePort
---
kind: Service #service 类型
apiVersion: v1
metadata:
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: "9121"
name: redis-exporter-service
namespace: app
spec:
selector:
app: redis
ports:
- nodePort: 31082
name: prom
port: 9121
protocol: TCP
targetPort: 9121
type: NodePort
验证
Prometheus采集数据
- job_name: "redis_exporter"
static_configs:
- targets: ["10.0.0.11:31082"]
重启Prometheus并验证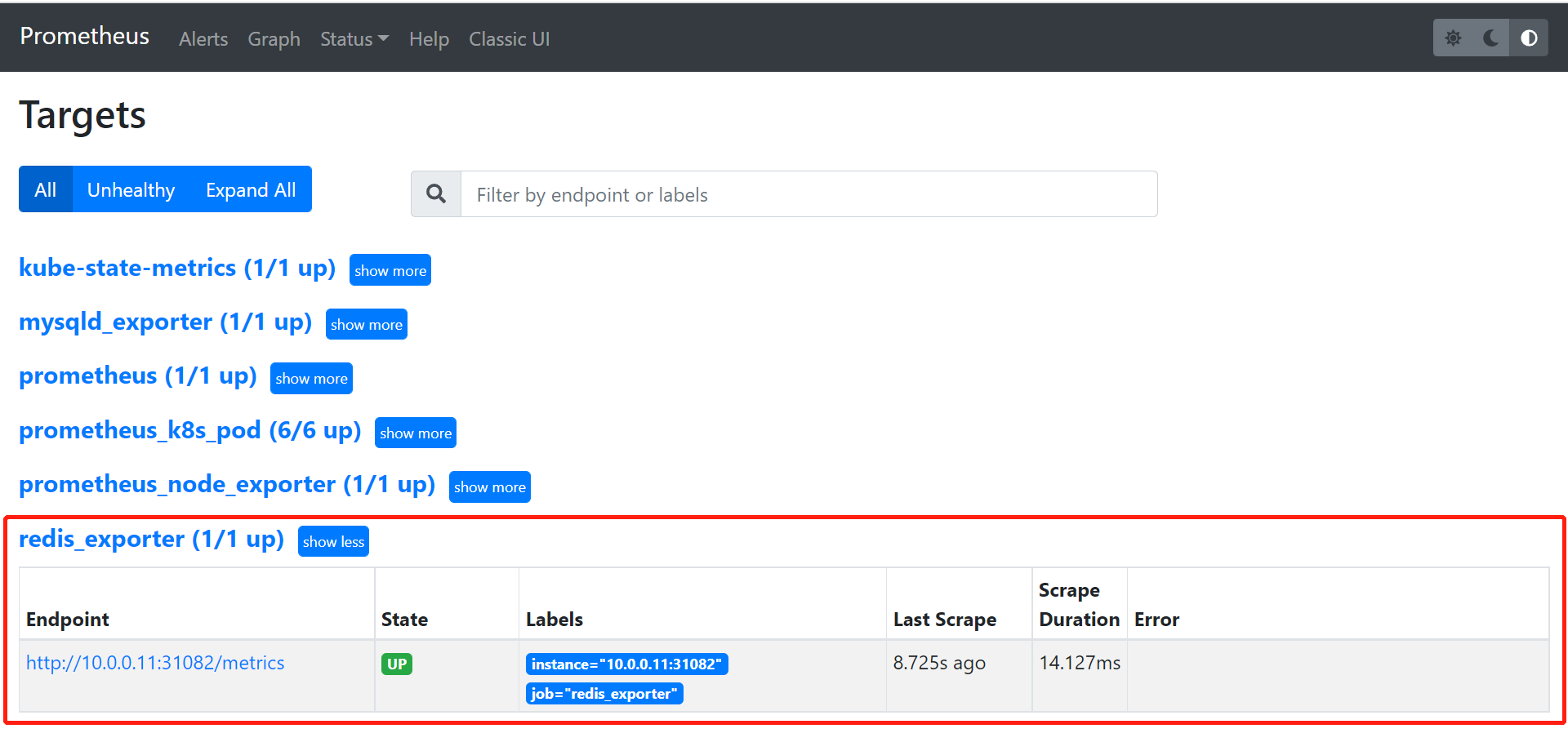
导入grafana模板
6.3 监控tomcat
6.4 监控haproxy
6.5 监控nginx

若有收获,就点个赞吧
0 人点赞
