常用命令
创建项目:scrapy startproject xxx创建爬虫:scrapy genspider xxx(爬虫名) xxx.com (爬取域)运行爬虫:scrapy crawl XXX生成文件:scrapy crawl xxx -o xxx.json (生成某种类型的文件)列出所有爬虫:scrapy list获得配置信息:scrapy settings [options]
环境
pip3 install pywin32 pip3 install Twisted pip3 install Scrapy
项目结构
scrapy.cfg: 项目的配置文件tutorial/: 该项目的python模块。在此放入代码(核心)tutorial/items.py: 项目中的item文件.(这是创建容器的地方,爬取的信息分别放到不同容器里)tutorial/pipelines.py: 项目中的pipelines文件.tutorial/settings.py: 项目的设置文件.(我用到的设置一下基础参数,比如加个文件头,设置一个编码)tutorial/spiders/: 放置spider代码的目录. (放爬虫的地方)
官方架构图
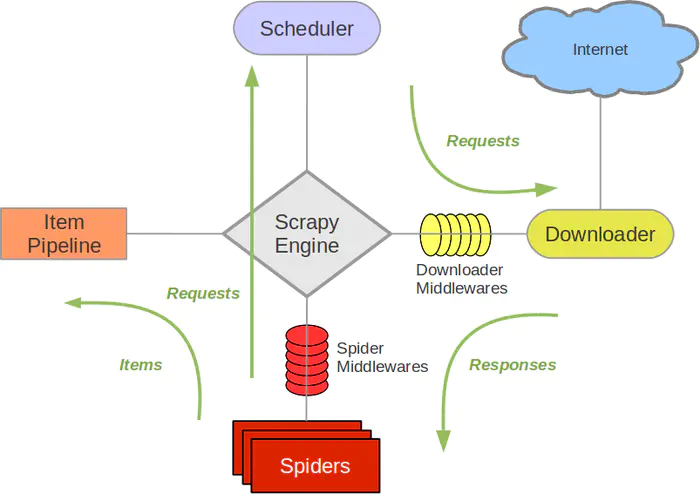
程序执行链
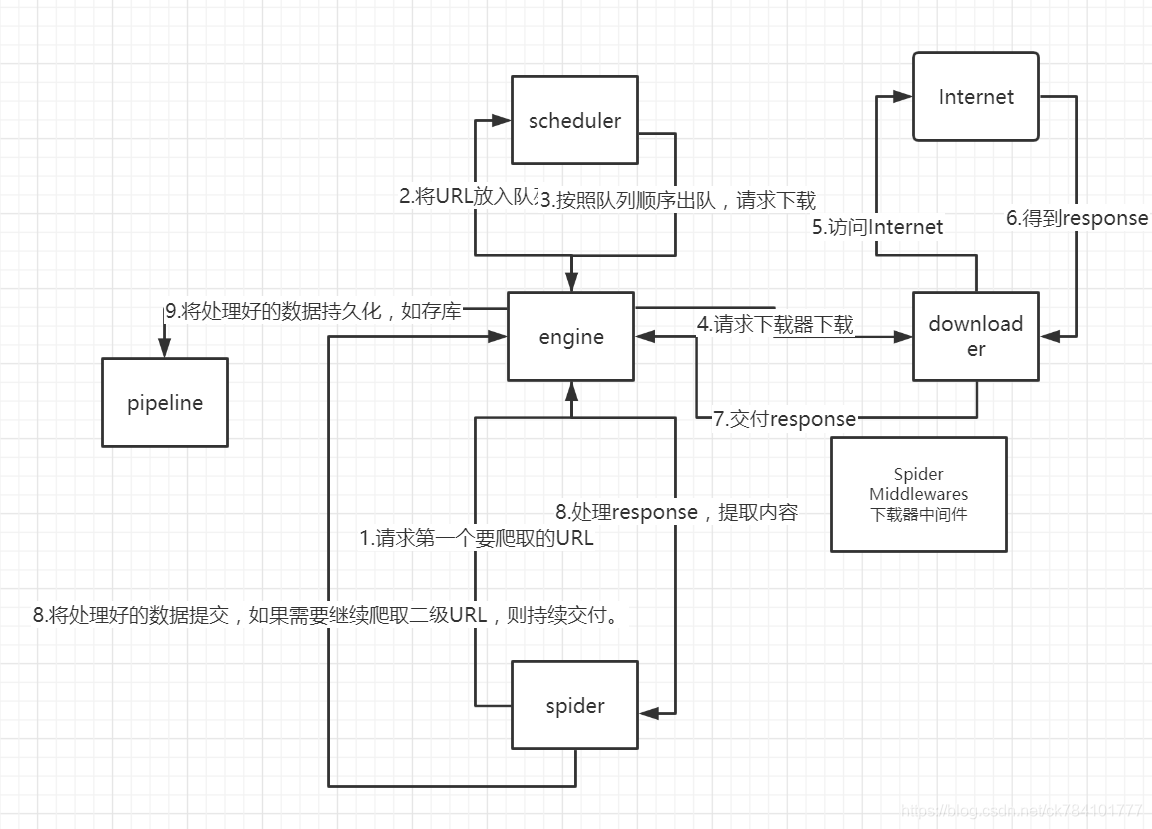
1.spider的yeild将request发送给engine 2.engine对request不做任何处理发送给scheduler 3.scheduler,生成request交给engine
4.engine拿到request,通过middleware发送给downloader
5.downloader在\获取到response之后,又经过middleware发送给engine
6.engine获取到response之后,返回给spider,spider的parse()方法对获取到的response进行处理,解析出items或者requests
7.将解析出来的items或者requests发送给engine
8.engine获取到items或者requests,将items发送给ItemPipeline,将requests发送给scheduler(ps,只有调度器中不存在request时,程序才停止,及时请求失败scrapy也会重新进行请求)
模块介绍


若有收获,就点个赞吧
0 人点赞
