lambda表达式是对函数接口的简化
函数式接口:它是一个接口,但是只有一个抽象方法
一、Lambda表达式的格式
1.Lambda表达式它是一段匿名函数,Lambda的是为了简化匿名内部类的写法
学习Lambda表达式思想的转变:我们使用Lambda表达式直接代替的接口实现类的对象,所以我们不需要new关键字而是直接写一个Lambda表达式来代替一个对象,也就是说我们写的Lambda表达式就是一个实现了接口中抽象方法的对象
2.注意Lambda表达式本质还是一个匿名内部类,所以在Lambda中使用的局部变量必须是final的
小技巧:对于处理相同的业务逻辑但是参数不同的冗余代码我们可以采用定义接口的方式进行过滤
public class LambdaTest {public static void main(String[] args) {//匿名内部类Comparator<Integer> comparator=new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return Integer.compare(o1,o2);}};//Lambda表达式简化匿名内部类Comparator<Integer> comparator1=(o1,o2)->Integer.compare(o1,o2);}}
二、Lambda的语法规则
1.Java8引入了一个新的操作符“->”箭头操作符或者叫Lambda操作符,他将Lambda表达式拆分成两个部分:
左侧:Lambda表达式的参数
右侧:Lambda表达式所需要执行的功能,Lambda体
注意Lambda表达式实际是对接口中(只有一个抽象方法)抽象方法的实现,所以Lambda表达的参数就是方法的形参,Lambda体就是方法体
2.函数式接口:接口中只有一个抽象方法的接口我们称为函数式接口,Lambda表达式需要函数式接口的支持
3.Lambda表达式的格式
函数式接口是无参无返回值的(左边参数列表没有参数就用括号替代)
//格式:()->System.out.println();//方法体//例:Test01 test=()-> System.out.println(a);
有一个参数但是没有返回值的(如果有多个参数格式也是这样的,但是括号不能省略)
//格式(e)->System.out.println();//如果只有一个参数小括号可以不写//e->System.out.println();
如果有返回值(当有返回值,但是只有一个语句那么return和发方法体的大括号都可以省略) ```java //有返回值,且有多个语句 /格式:(x,y)-> { System.out.println(); return “”; } / //有返回值但是只有一条语句 //格式: e->””;
//有返回值只有一条语句 ManyParamAndReturn manyParamAndReturn = (o1, o2) -> o1 + o2; //有返回值但是有多条语句 ManyParamAndReturn manyParamAndReturn1 = (o1,o2)->{ System.out.println(“1111”); return o1+o2; };
<a name="ZIHBe"></a>### 三、Java内置的四大核心函数式接口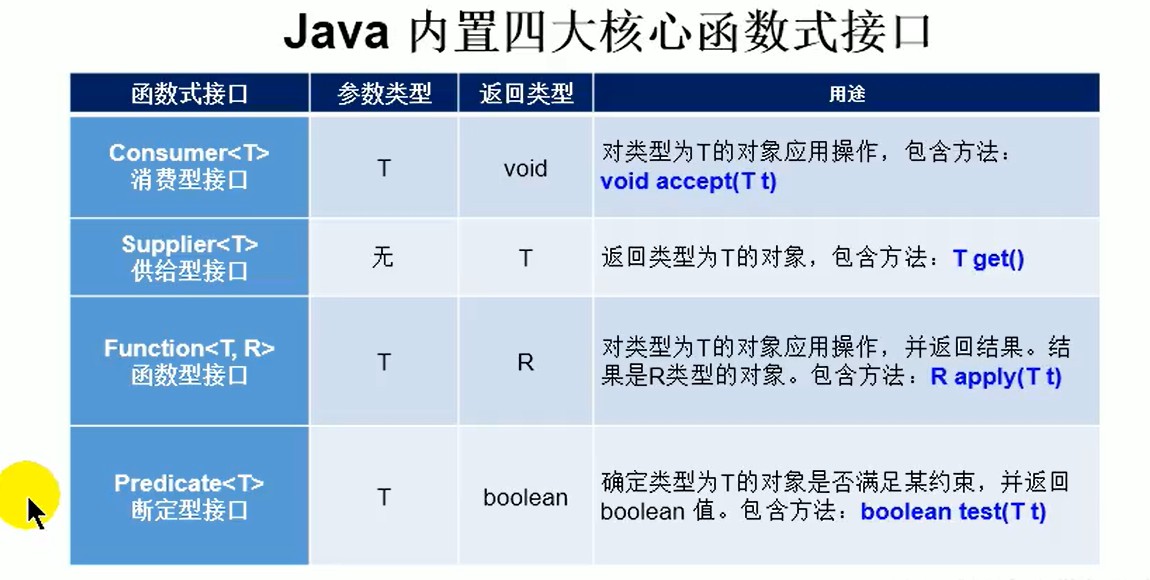<br />1.消费型接口Consumer<T>:传递一个T对象但是没有返回值<br />2.供给型接口Supplier<T>:不传递参数会返回一个T对象<br />3.函数型接口Function<T,R>:传一个T对象返回一个R对象<br />4.断言型接口Predicate<T>:传递一个T对象返回boolean类型<br />在开发中可能会遇到一些方法需要传递这些接口的实现类,我们可以根据这些接口的特性来使用Lambda表达式替代```javapackage com.study;import org.junit.Test;import java.util.function.Consumer;import java.util.function.Function;import java.util.function.Predicate;import java.util.function.Supplier;public class InbuiltFunction {//测试消费性函数式接口:传递一个泛型类型参数,不返回@Testpublic void testCustomer(){Consumer<String> customer=e-> System.out.println(e);}//测试供给型函数式接口:不传递参数返回一个泛型类型对象@Testpublic void testSupplier(){Supplier<String> stringSupplier=()->"aa";}//测试函数式接口:传递泛型的key,返回value类型对象public void testFunction(){Function<String, Integer> function=e-> Integer.parseInt(e);}//测试断言型函数是接口:传递一个泛型参数,返回true或者falsepublic void testPredicate(){Predicate<String> predicate=e->true;}}
四、方法的引用和构造器引用
考虑场景:当我们写Lambda表达式的方法体时,如果有和我们要写的方法同样功能的我们可以直接使用方法引用而不用自己再次去写
使用要求:我们要写的lambda表达式参数列表和返回值类型与我们要引用的方法的参数列表和返回值类型相同(针对格式一和格式二)
4.1方法引用
当传递给lambda体的操作已经有实现方法了,那我们就可以使用方法引用(相当于对Lambda表达式更深一层的简化)
格式:类名(当方法是静态方法时)或对象名 :: 方法名
使用情景:方法引用是对原有的Lambda表达式的方法体的一种简化替换,我们要写的lambda表达式参数列表和返回值类型与我们要引用的方法的参数列表和返回值类型相同,那么就可以用方法体替换(因为参数个数也是一样的所以参数也要省略)
格式主要有三种
1.对象::非静态方法
2.类::静态方法
3.类::非静态方法(特殊)
例如:格式一对象::非静态方法
@Test
public void testCustomer(){
//这是一个消费型接口,它的lambda体格式是传递一个参数,没有返回值,那么我们就可以使用其他传递一个参数 不返回的方法进行引用替换
Consumer<String> customer=e-> System.out.println(e);
//方法引用替换
Consumer<String> customer=ps::println;
}
格式二类::静态方法
public void test2(){
//通过类来引用静态方法
Collections.sort(new ArrayList<Integer>(),Integer::compareTo);
}
格式三:类::非静态方法(这个很特殊,当有两个参数,第一参数作为调用者出现可以这样使用)
public void test3(){
//正常情况的Lambda表达式
Comparator<String> comparator=(s1,s2)->s1.compareTo(s2);
//方法引用替换
Comparator<String> comparator1=String::compareTo;
}
4.2:构造器引用,我们需要造对象,可以引用已经存在的构造器
格式:类::new(如果是数组那么就用类名[]::new 来调用)
public void testConstructor(){
Supplier<String> supplier=String::new;
Function<Integer,String[]> function=String[]::new;
}
五、Stream流API
Stream流他就是对Java提供四种函数式接口的一种使用
5.1、它是JDK8提供一种新特性,我们可以更加便捷的操作集合
注意:
- Stream流它自己本身不会存储数据,存储数据的是集合,Stream只是操作集合
- Stream流不会改变源对象,它会返回一个操作过后的新对象
- Stream流的操作时延迟执行的,这意味着只有等我需要结果的时候它才会执行(也就是我们没有进行终止操作,中间操作就不会执行)
5.2、Stream流的操作的三个步骤
1.通过数据源(集合或数组),来获取一个流
2.中间操作,处理数据
3.终止操作,产生结果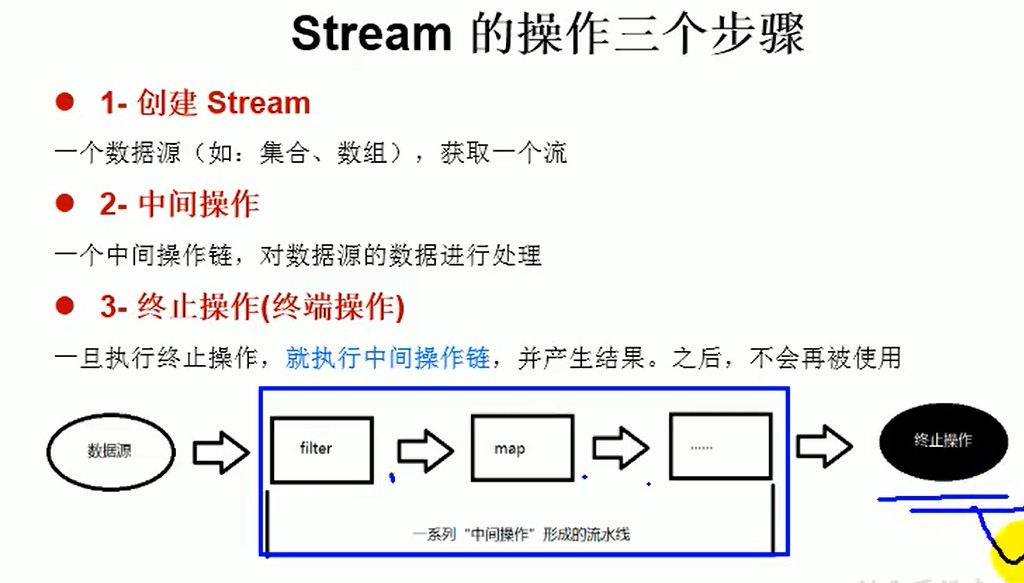
5.3获取Stream的方式
public class StreamTest {
public static void main(String[] args) {
//获取Stream流的方法
//方法一、通过Collection 一系列集合提供的stream()方法或parallelStream()
ArrayList<String> list = new ArrayList<String>();
Stream<String> stream = list.stream();
//这个是获取一个并行流,这个流和上面获取的是同一个类型,只是这个流它是通过多个线程一起去处理的方式
//在取集合中的元素时就不会按照顺序去取而是多个线程一起去取
Stream<String> stringStream = list.parallelStream();
//Arrays提供的静态方法stream(T[] t)来获取数组的流
Integer[] array=new Integer[12];
Stream<Integer> stream1 = Arrays.stream(array);
//方式三、通过Stream提供的静态方法of(),获取流
Stream<String> stream2 = Stream.of("aa", "bb");
//创建一个无限流即没有上线,第一个参数是起始值,第二个参数是Lambda表达式对第一个参数进行处理
//无限流方式一:迭代
Stream<Integer> iterate = Stream.iterate(0, x -> x + 2);
iterate.forEach(System.out::println);
//无限流方式二:生成
Stream<Double> stream4 = Stream.generate(() -> Math.random());
//limit是中间操作,目的是只产生4个
stream4.limit(4).forEach(System.out::println);
}
}
5.4Stream流的中间操作
Stream流的中间操作:筛选和切片
1.filter()—他的参数是接受Lambda表达式,里面的参数是一个断言即传递一个参数返回一个boolean的值 过滤
注意:filter()方法就是用来过滤集合中的元素的,我们只需要用Lambda表达式写过滤条件,即返回true,就会吧
//Stream流的中间操作
public class StreamTest03 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
//第一步获取流:filter(//这里的参数是一个断言,即函数式接口,传递一个参数返回true,或者false)
//具体的方法体我们可以通过Lambda表达式进行实现,但是实现逻辑必须是返回boolean值,从而实现
//集合元素的过滤,这是中间操作不会有结果,必须要终止操作,例如forE
Stream<Integer> integerStream = list.stream().filter(item -> item > 3);
//进行终止操作,没有终止操作中间操作是不会执行的,这样叫做惰性求值
integerStream.forEach(System.out::println);
}
}
2.中间操作流——>截断流 limit()//使其元素不超过给定的数量,即不超过给定的参数 成为短路
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
//Stream流的中间操作
public class StreamTest03 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
//中间操作2:截断流(它是中间操作也需要终止流)
list.stream().filter(item->item>1).limit(2).foreach(System.out::println);
}
}
3.skip()表示跳过和limit相反,limit表示取前几个,skip表示跳过前几个
4.去重distinct()表示去重,他是通过hashcode和equals进行去重,要想可以去重,需要重写hashcode和equals方法
5.映射map(),接收Lambda将元素转换成其他形式,并提取信息。接受一个函数作为参数,该函数会被应用到每一个元素上面,并将其映射成一个新元素
flatMap接收一个函数作为参数,将流中的每一个值都转换成一个新流,然后把所有流连接成一个新流
映射是可以对集合中的元素进行相关操作然后重新收集成流,这个返回的流的泛型取决于你传递函数的返回值
//Stream流的中间操作
public class StreamTest03 {
public static void main(String[] args) {
List<String> strings = Arrays.asList("aa", "bb", "cc", "dd");
strings.stream().map(str->str.toUpperCase()).forEach(System.out::println);
}
}
6.中间操作排序
自然排序—-sorted()//Comparable,所谓自然排序就是按照Comparable的方式进行排序,该类是实现Comparable接口
sorted(Comparator com)— 定制排序(Comparator)
7.Stream的终止操作:直接返回结果不返回流
7.1查找与匹配
allMatch(Function)检查是否匹配所有元素:传递带一个参数的函数式接口函数体也是返回true,这是终止操作,不返回流直接返回boolean结果
anyMatch(Function)检查是否至少匹配一个元素
noneMatch():如果没有所有元素都没有匹配的那么返回
一下两个会返回Optional对象,这个对象是用来解决空指针异常的,可以通过get()方法来获取集合中过滤的元素
findFirst()返回第一个元素
findAny()返回当前流中的任意元素:即满足条件就返回
count()返回流中的总数
max()获取最小值
min()获取最大值
public class StreamTest04 {
public static void main(String[] args) {
//Stream的终止操作
//allMatch--检查是不是所有元素都匹配,传递一个只带一个参数的函数接口(接口写匹配规则)
//返回boolean
List<String> strings = Arrays.asList("aa", "bb", "cc", "dd");
boolean result = strings.stream().allMatch(e -> e.equals("cc"));
System.out.println(result);
}
}
8.reduce():归约,可以将流中的元素返回结合起来返回一个新的值
public class StreamTest05 {
public static void main(String[] args) {
//Stream流的终止操作:归约
//reduce
Integer[] intgers={1,2,3,4,5};
List<Integer> list = Arrays.asList(intgers);
//reduce(),参数一传递一个起始值,参数二传递一个集合中元素的结合规则,首先是将起始值赋值给x,然后从集合中取出元素作为y,然后计算出结果作为x,在从集合中取出元素作为y,(x是由起始值和计算结果,y是从集合中取出的元素值)
Integer result = list.stream().reduce(0, (x, y) -> x + y);
//reduce()一个参数的时候传递一个函数是接口返回Optional对象,通过get()获取结果
}
}
map-reduce模式Google用来做搜索的,通过map进行过滤,通过reduce进行结果处理
9.收集
collect将流转换成其他形式,接收一个Collector接口的实现,用于给Stream流做汇总
collect需要传一个收集器,通过Collectors提供的静态方法来创建各种收集器
public class StreamTest06 {
public static void main(String[] args) {
//收集
String[] strs={"aa","bbb","cccc"};
//通过Collectors中提供的静态方法来进行收集
Arrays.stream(strs).filter(x -> x.length() > 2).collect(Collectors.toList())
.forEach(System.out::println);
//如果没有提供对应类型的静态方法,可以通过方法进行收集
Arrays.stream(strs).filter(x->x.length()>2).collect(Collectors.toCollection(HashSet::new));
//Collectors中提供的其他的静态方法
Collectors.counting()//收集总数返回Long类型
//获取平均值
Arrays.stream(strs).collect(Collectors.averagingInt(item->Integer.parseInt(item)));
//获取总和
Arrays.stream(strs).collect(Collectors.summarizingInt(item->Integer.parseInt(item)));
//求最大值maxBy(Comparator)
//获取最小值minBy(Comparator)
//分组groupingBy(Function):传递参数一个按照什么进行分组,返回值一个是一个Map,key是分组的类型,value是一个List,泛型是流中元素的泛型
//多级分组,第一个参数传递Function,第二个参数还可以是一个Collector再次调用groupingBy方法再次分组实现多级分组
}
}
六、并行流和串行流的使用场景
并行流就是把内容分割成多个数据块,每个数据块对应一个流,然后用多个线程分别处理每个数据块中的流,并不一定使用并行流就快
对于一些计算量比较大的任务,使用并行流可能极大的提升效率,对于数据量比较小的建议使用串行流

若有收获,就点个赞吧
0 人点赞
