一、关系型数据库和ES的对比
ElasticSearch是一个搜索服务器,就是用来做大量查询。
- 关系型数据库做查询的弊端
1.我们在查询数据量比较的多的数据时,如果我们使用模糊查询,这样将会使索引失效,这个时候就会进行全表扫描,查询效率非常低
2.我们在使用关系型数据库的时候,没办法对查询条件进行分词查询
总结:就是关系型数据库做查询的弊端就是性能低,功能弱
- ES存储数据的特点
ES将数据存储在index中(索引库,类似于关系型数据库的db),而所以ES中的数据以文档(document,类似于关系型数据库的表一条记录)的形式存储到索引库中,文档的数据格式就是JSON的数据格式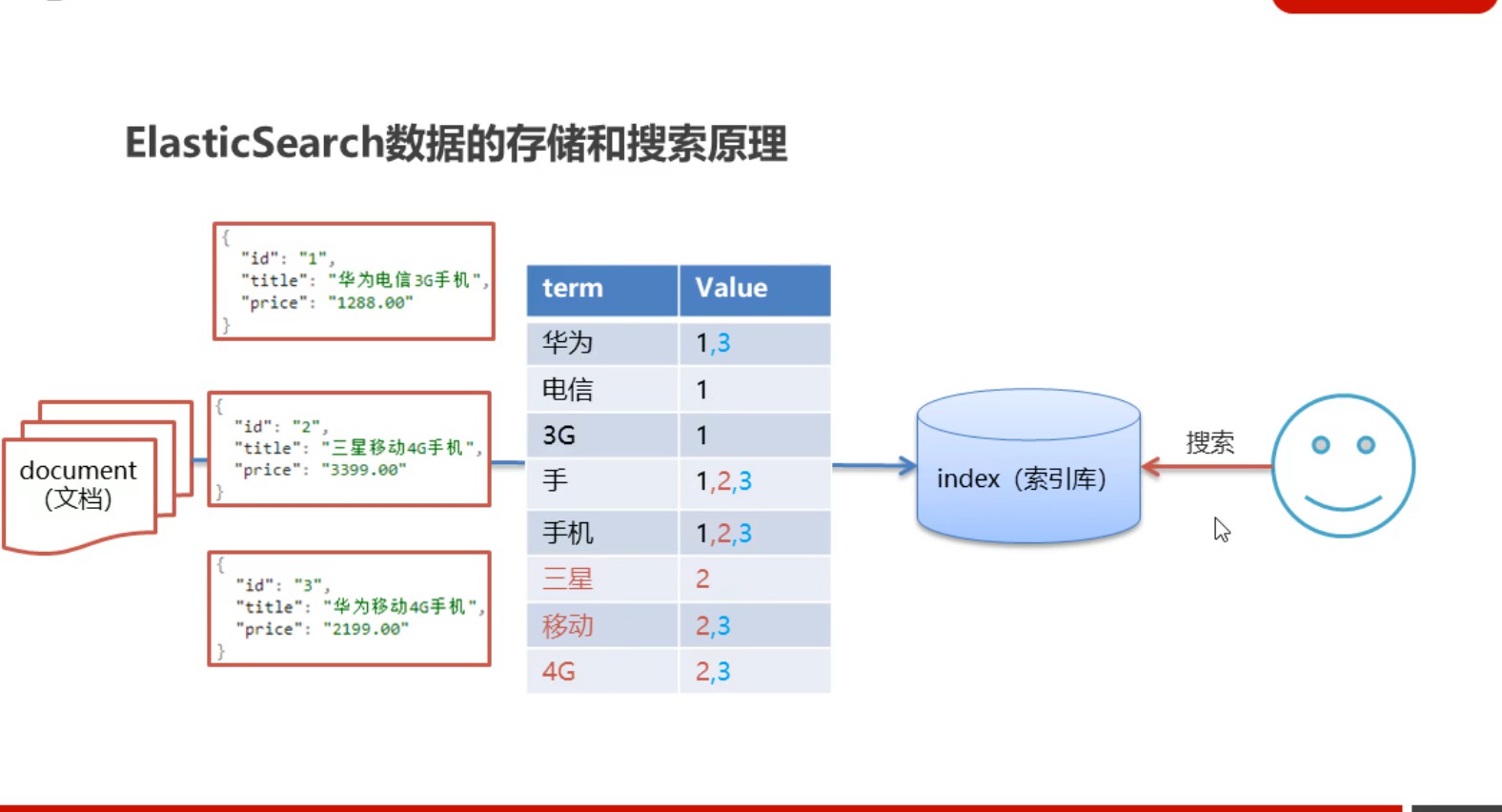
ES来解决关系型数据库查询效率低功能弱的问题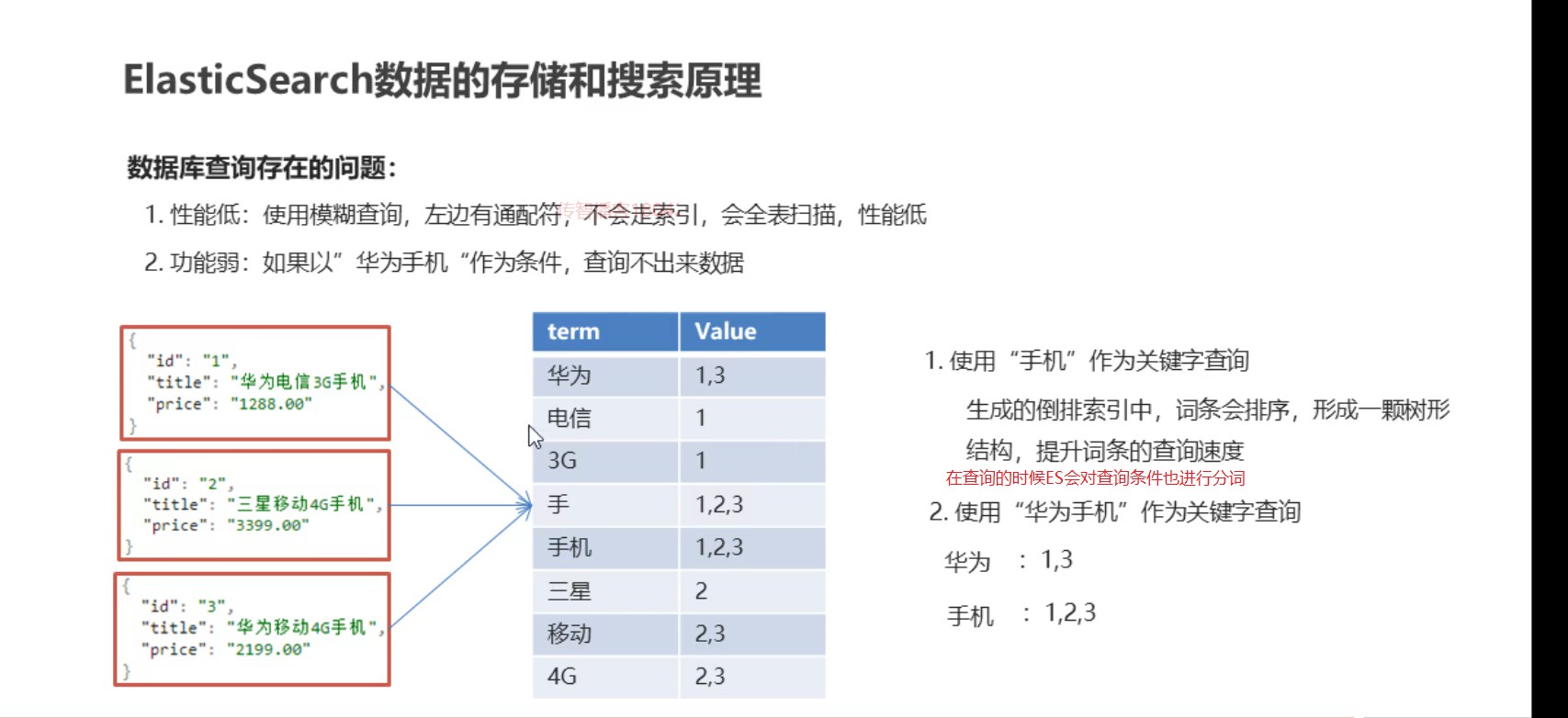
ES查询效率高原因:首先会对文档进行分词,形成倒排索引,这些分词ES会对他们进行排序形成树形结构,这样查询分词的时候就会很快,不需要向关系型数据库那样进行全表扫描
ES查询功能强的原因:对于查询条件,ES首先会先进行分词,然后根据这些词条进行匹配查询
二、倒排索引
- 正向索引
在人的存储思维中,我们存储数据信息时采用的是正向索引,即用数据的唯一标识来对应文本内容,我们大脑在查找数据时,现根据数据的唯一标识然后去找对应的文本内容,反过来通过文本内容信息来找唯一标识就很难
- 倒排索引
首先对文本信息按照一定的规则拆分成不同的词条,将这些词条作为查找的条件,通过这些分词就行查到对象的数据,但是这样的缺点就是同一个分词可能会对应多个数据,导致数据量很大所以查找起来还是慢,这个时候我们可以进行优化,将数据位置不存储具体数据还是数据的唯一标识,即数据的索引,通过分词来对应索引,通过索引来找对应的数据,从而提高查询效率
倒排索引的解释:将各个文档的内容进行分词,形成词条。然后记录词条和数据唯一标识的(一般是ID)的对应关系,形成的产物
三、ES的介绍
- ES是一个基于Lucene的搜索服务器,Lucene是一套搜索的API(用于搜索的Jar包),ES是对Lucene的一个实现,ES内部提供了分词的操作,另一个对Lucene比较好的实现是solr,ES是后出来的搜索产品,性能方面比solr更好,在做实时搜索更好(即一边存储,一边搜索)
- ES是一个分布式(分布式说明ES是一个天然支持分布式的,搭建集群很方便),高扩展,高实时的搜索与数据分析引擎
- 它是基于restful Web 的接口(即通过发送RestFul风格的http请求来实现搜索)、
- ES是Java语言开发的(ES安装包内置了JDK,所以即使没有配置JDK也可以使用),它是一种开源的流行的企业级搜索引擎
- 官网是:https://www.elastic.co/
重点:ES 的应用场景
1.海量数据的搜索
2.日志数据分析
3.实时数据的分析
注意:有了ES我们依然需要关系型数据库,首先关系型数据库是有事务的,但是ES是没有事务的,所以我们删了数据是没有办法恢复的
MYSQL是有物理外键的,ES没有物理外键,所以对数据一致性要求比较高的话慎用ES
总结:两种类型的数据库只是分工不同,MYSQL数据库负责存储数据,而ES负责查询数据
四、安装ES
- 9200:使用http请求,所以我们的rest方式的client要使用这个端口进行访问
- 9300:使用tcp请求,是系统预留给es内部组件之间的通信方式
注意:启动ES不能通过root用户否则会报错,所以我们要创建非root用户 ```shell useradd test # 新增itheima用户 passwd zhubowen # 为itheima用户设置密码 //更改文件夹的所有者, chown -R test:test /opt/elasticsearch-7.4.0 #文件夹所有者#第一步:到官网下载Linux版本的压缩包,上传到Linux服务器上#第二步:将压缩包进行解压,由于我们下载的是tar包,所以使用tar命令tar -zxvf 压缩包名 -C 需要解压到那个目录#第三步:修改配置,在ES的安装目录下的config目录下有一个elasticseach.yml配置文件cluster.name: application(配置ES集群的名称,默认是elasticsearch)node.name: node-1(集群节点名,ES默认会随机给一个名字,我们可以修改成有意义的名字)network.host: 0.0.0.0 :这里配置是可以被外网访问(这个配置是将两个配置合二为一:network.host将设置network.bind_host和network.publish_host为相同的值)http.port: 9200(默认端口号)cluster.initial_master_nodes: ["node-1"](初始化新的集群时,通过此配置来选取master)
新创建的test用户最大可创建文件数太小,最大虚拟内存太小,切换到root用户,编辑下列配置文件, 添加类似如下内容
切换到root用户
su root1. ===最大可创建文件数太小=======
vim /etc/security/limits.conf在文件末尾中增加下面内容
test soft nofile 65536 testhard nofile 65536=====
vim /etc/security/limits.d/20-nproc.conf在文件末尾中增加下面内容
test soft nofile 65536 test hard nofile 65536
2. ===最大虚拟内存太小=======
vim /etc/sysctl.conf
在文件中增加下面内容
vm.max_map_count=655360
重新加载,输入下面命令:
sysctl -p
运行ES出现的错误即解决:
```java
错误:
Caused by: org.elasticsearch.ElasticsearchException: Failure running machine learning native code. This could be due to running on an unsupported OS or distribution, missing OS libraries, or a problem with the temp directory. To bypass this problem by running Elasticsearch without machine learning functionality set [xpack.ml.enabled: false].
这个错误是因为在Centos中运行了Macos下的es安装包,换成linux的包,正常启动
解决:进入config目录下在elasticsearch.yml添加一条配置:xpack.ml.enabled: false
启动成功:可以访问IP:9200
五、ES的核心概念
- index(索引)
ES存储数据的地方
- mapping(映射)
用来定义每个字段的数据类型,字段所使用的分词器。相当于关系型数据库的表结构
- document(文档)
ES中的最小数据单元,常以JSON格式显示,一个document相当于关系型数据库的一行数据
- 倒排索引
一个倒排索引由文档中所有不重复,对于其中的每一个词,对应它包含的文档ID列表
六、操作ES
1.通过脚本操作ES,由于ES是一个服务器,支持RestFul风格请求,我们可以通过发送Http请求操作ES

6.1:索引的操作(创建数据库)
- 创建索引
使用put请求:ip:端口/索引库名 :表示创建索引库
- 删除索引
使用delete请求:ip:端口/索引库名
- 查询索引
使用get请求:ip:端口/索引库名 :查询创建的索引库信息,如果想查询多个索引库,后面的索引库名用逗号拼接即可
使用ip:端口/_all表示查询所有索引库,下划线开头的表示ES提供好的命令
//查询索引库返回的结果
{
"test": {//索引库名
"aliases": {},//索引库别名
"mappings": {},//映射
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "test",
"creation_date": "1622313127279",
"number_of_replicas": "1",
"uuid": "u8sR0H1nTTODlm392sVWXg",
"version": {
"created": "7130099"
}
}
}
}
}
- 关闭索引:索引没有删除,只是不能用
使用POST请求:ip:端口/索引库名/_close 来关闭索引库
- 打开索引
使用POST请求:ip:端口/索引库名/_open 来打开索引库
6.2:操作映射(创建表)
ES中的数据类型
- 简单数据类型
- 字符串
- text:这种数据类型,会分词,但是不支持聚合(这个聚合就相当于关系型数据库的聚合函数如:sum等)
- keyword:不支持分词,将全部内容作为词条,支持聚合
- 数值
- byte:带符号8位整数,范围是[-128,127]
- short:带符号16位整数,范围是[-32768,32767]
- integer:带符号32位整数,范围是[-231232,231231]
- long:带符号64位整数,范围是[-263263,263262]
- half_float:单精度16位IEEE754浮点数,
- float:单精度32位IEEE754浮点数,
- double:双精度64位IEEE754浮点数,
- scaled_float:有a支持的有限浮点数long,由固定double比例因子缩放
- 布尔
- boolean
- 二进制
- binary
- 范围存储:integer_range,long_range,float_range,double_range,date_range
- 我们可以设置一个字段为一个范围,在这个范围内可以存储
- 日志
- date
- 字符串
- 复杂数据类型
- 数组
- []
- 对象
- {}
- 数组

添加映射
要指定索引来添加映射:
发送put请求:http://IP:端口/索引(给那个索引添加映射)/_mapping(ES提供的添加映射的指令)
请求体内携带JSON格式参数
{
"properties":{//来指定属性
"name":{"type":"keyword"},//创建name属性,数据类型为keyword
"age":{"type":"integer"}//创建age属性,数据类型为integer
}
}
也可以在创建索引库的时候添加映射信息
发送put请求:http://IP:端口/索引(给那个索引添加映射)
请求体内携带JSON格式参数
{
"mappings":{
"properties":{//来指定属性
"name":{"type":"keyword"},//创建name属性,数据类型为keyword
"age":{"type":"integer"}//创建age属性,数据类型为integer
}
}
}
查询映射
使用get请求:http://IP:端口/索引/_mapping
添加字段
添加映射和创建映射一样
发送put请求:http://IP:端口/索引(给那个索引添加映射)/_mapping(ES提供的添加映射的指令)
请求体内携带JSON格式参数
{
"properties":{//来指定属性
"address":{
"type":"keyword",
"analyzer":"ik_max_word"//指定分词器
}
}
}
6.3操作文档(增删改查表中的数据)
添加文档
添加文档有两种方式: 方式一:指定ID,使用put方式http://IP:端口/索引库/_doc/id { "name":"张三", "age":20, "address":"合肥" } 方式二:不指定Id,只能用post请求,http://IP:端口/索引库/_doc { "name":"李四", "age":20, "address":"合肥" } //这里的Id是ES中提供的_id属性,如果我们提供就是我们提供的,如果我们不提供就是ES随机生成的一个字符串 //对于文档中我们也可以添加自己的Id属性列,对应数据库中表的主键查询文档
查询指定ID,使用get方式http://IP:端口/索引库/_doc/id 查询所有文档:使用get方式http://IP:端口/索引库/_search删除文档
根据Id删除文档:使用DELETE请求方式http://IP:端口/索引库/_doc/id修改文档
修改和添加文档一样:ID存在则修改ID不存在则添加 方式一:指定ID,使用put方式http://IP:端口/索引库/_doc/id
注意:ES中支持的请求类型是put、get、delete,ES中提供的指令都是下划线开头的例如_doc,_search等,而且每次操作我们基本都要携带索引库的名字,所以我们可以大致来记住操作ES索引库,映射和文档的请求格式都是ip:端口/索引库/加指令(_mapping,_doc,_search)
七、分词器

IK分词器
IK分词器的官网是:https://github.com/medcl/elasticsearch-analysis-ik/releases,根据ES的版本来下载IK分词器的版本,这个版本一定要对应ES的版本
jar包的移动
将下载好的ES进行解压,然后使用maven命令进行打包,打包好了,进入target目录
package执行完毕后会在当前目录下生成target/releases目录,将其中的elasticsearch-analysis-ik-7.4.0.zip。拷贝到elasticsearch目录下的新建的目录plugins/analysis-ik,并解压
拷贝词典
将elasticsearch-analysis-ik-7.4.0目录下的config目录中的所有文件 拷贝到elasticsearch的config目录
cp -R /opt/ik/elasticsearch-analysis-ik-7.13.0/config/* /opt/elasticsearch/elasticsearch-7.13.0/config/
*表示该目录下的所有文件
八、IK分词器的使用
1.IK分词器有两种分词模式:ik_max_word(细粒度,细粒度分词更细,比如可以手机可以分为手和手机)和ik_smart(粗粒度)模式,粗粒度和细粒度的区别是细粒度会在分过的词上在进行分词,比如华为手机会分成华为,手机,手机也会进行分词,但是粗粒度在分过词后不会再分过的词上继续分词
//分词器测试:
发送get请求http://IP:端口/_analyze
请求体是
{
"analyzer":"ik_max_word",//选择分词器,这里选择IK的细粒度分词器
"text":"分词内容"
}
九、查询ES文档的语法
脚本查询文档
词条查询:term(词条查询不会对查询条件进行分词,只有当词条和查询字符串完全匹配才能查出来)
查询使用的是get请求: http://ip:端口/索引库/_search //携带的请求参数是 { "query":{//这个属性表示查询 "term":{//这里表示使用词条查询 "address":{//查询的字段 "value":"查询条件"//字段对应的值 } } } }全文查询:match(全文查询会对查询条件进行分词,然后进行查询,最后求并集)
查询使用的是get请求: http://ip:端口/索引库/_search //携带的请求参数是 { "query":{//这个属性表示查询 "match":{//这里表示使用全文查询 "address":"查询的字段属性值"//这里指定查询那个字段 } } }
十、通过Java代码的方式操作ES
这里总结两种方式操作ES:
方式一:通过ES提供的API
1.使用SpringBoot整合ES(由于SPring没有提供单独的启动坐标,所以我们要引入,使用Spring的话也是这些坐标)
<!--导入这个坐标注意使用的ES的版本,我测试使用的ES 7.13.0 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.13.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.13.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.13.0</version>
</dependency>
2.Java代码来操作索引
package com.study.elasticsearchtest;
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.IndicesClient;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import org.elasticsearch.cluster.metadata.MappingMetadata;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Map;
@SpringBootTest
public class ElasticsearchtestApplicationTests {
@Autowired
private RestHighLevelClient client;
@Test
public void test1() {
//创建ES客户端对象
RestHighLevelClient restHighLevelClient=new RestHighLevelClient(RestClient.builder(
new HttpHost("182.92.71.236",9200,"http")
));//创建HttpHost()对象需要三个参数IP,端口,协议
}
/**
* 添加索引
*/
@Test
public void addIndex() throws Exception{
//创建索引对象
IndicesClient indices = client.indices();
//通过索引对象来操作索引,
CreateIndexRequest createRequest=new CreateIndexRequest("test1");//索引名称
//create这个方法有两个重载的方法,这个方法第一个参数所在的包不一样,有一个方法是过时的
CreateIndexResponse createIndexResponse = indices.create(createRequest, RequestOptions.DEFAULT);//第二参数是请求选项,这里用默认选项
//true表示创建成功,创建失败抛异常
boolean acknowledged = createIndexResponse.isAcknowledged();
System.out.println(acknowledged);
}
/**
* 添加索引同时指定mapping,(即初始化索引的相关参数)
*/
@Test
public void addIndexAndMapping() throws Exception{
//创建索引对象
IndicesClient indices = client.indices();
/*通过索引对象来操作索引,注意createRequest是用来初始化索引的相关参数,采用链式编程
* CreateIndexRequest的对象,可以用来给索引添加映射,起别名等,
* 进行一些初始化索引的操作
* */
CreateIndexRequest createRequest=new CreateIndexRequest("test2");//索引名称
//添加mapping,这里的mapping我们用JSON格式创建和使用请求携带请求创建格式一样,
String mapping="{\n" +
" \"properties\":{\n" +
" \"name\":{\"type\":\"text\"},\n" +
" \"age\":{\"type\":\"integer\"}\n" +
" }\n" +
"}";
createRequest.mapping(mapping, XContentType.JSON);
//create这个方法有两个重载的方法,这个方法第一个参数所在的包不一样,有一个方法是过时的
CreateIndexResponse createIndexResponse = indices.create(createRequest, RequestOptions.DEFAULT);//第二参数是请求选项,这里用默认选项
//true表示创建成功,创建失败抛异常
boolean acknowledged = createIndexResponse.isAcknowledged();
System.out.println(acknowledged);
}
/**
* 查询索引(查询索引的相关配置):步骤和创建索引类似
*/
@Test
public void queryIndex()throws Exception{
//创建索引对象
IndicesClient indices = client.indices();
GetIndexRequest getIndexRequest = new GetIndexRequest("test2");
GetIndexResponse response = indices.get(getIndexRequest, RequestOptions.DEFAULT);
//这里的GetIndexResponse,不仅可以获取索引信息,还可以获取索引的其他信息
Map<String, MappingMetadata> mappings = response.getMappings();
for (String s : mappings.keySet()) {
System.out.println(mappings.get(s).getSourceAsMap());
}
}
/**
* 删除索引
*/
@Test
public void deleteIndex()throws Exception{
//创建索引对象
IndicesClient indices = client.indices();
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("test1");
AcknowledgedResponse response = indices.delete(deleteIndexRequest, RequestOptions.DEFAULT);
//返回true说明删除成功
boolean acknowledged = response.isAcknowledged();
System.out.println(acknowledged);
}
/**
* 判断索引是否存在
*/
@Test
public void existIndex()throws Exception{
//创建索引对象
IndicesClient indices = client.indices();
GetIndexRequest getIndexRequest = new GetIndexRequest("test","test1");
boolean exists = indices.exists(getIndexRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
}
3.Java 代码来操作文档
package com.study.elasticsearchtest;
import com.alibaba.fastjson.JSON;
import com.study.elasticsearchtest.domain.Person;
import org.elasticsearch.action.DocWriteResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.HashMap;
import java.util.Map;
//ES对文档的基本操作:增删改查
@SpringBootTest
public class ElasticsearchDocApplicationTest {
@Autowired
private RestHighLevelClient client;
/**
* 添加或者修改(不存在添加,存在就是修改)文档(使用Map添加)
*/
@Test
public void addDocByMap() throws Exception{
HashMap map = new HashMap<>();
//注意这里设置的值要和ES的类型进行对应
map.put("age",12);
map.put("name","中国");
IndexRequest request=new IndexRequest("test2").id("3").source(map);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response.getId());
}
/**
* 添加或修改(不存在添加,存在就是修改)文档(使用JSON串)
*/
@Test
public void addDocByJSON() throws Exception{
//一般我们都是使用对象,将对象转换成JSON放入ES
Person person = new Person();
person.setAge(12);
person.setName("ceshi");
String personString = JSON.toJSONString(person);
IndexRequest request=new IndexRequest("test2").id("4").source(personString, XContentType.JSON);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response.getId());
}
/**
* 根据Id查询
*/
@Test
public void getDocById()throws Exception{
GetRequest request=new GetRequest("test2","3");
//或者可以调用方法指定ID,request.id();
GetResponse response = client.get(request, RequestOptions.DEFAULT);
String sourceAsString = response.getSourceAsString();
// Map<String, Object> sourceAsMap = response.getSourceAsMap();
System.out.println(sourceAsString);
}
/**
* 根据Id删除
*/
@Test
public void deleteDoc()throws Exception{
DeleteRequest request=new DeleteRequest("test2").id("3");
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
System.out.println(response.getId());
}
}
4.批量操作ES
4.1脚本操作ES
4.2Java代码批量操作ES
package com.study.elasticsearchtest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.HashMap;
import java.util.Map;
@SpringBootTest
public class ElasticsearchBulkApplicationTests {
@Autowired
private RestHighLevelClient client;
//使用Java代码批量操作ES
@Test
public void testBulk() throws Exception{
//创建批量操作对象
BulkRequest bulkRequest=new BulkRequest();
//进行批量操作
//删除操作
DeleteRequest deleteRequest=new DeleteRequest().index("test2").id("3");
bulkRequest.add(deleteRequest);
//添加操作
IndexRequest indexRequest=new IndexRequest();
Map map = new HashMap();
map.put("age",12);
map.put("name","test11212");
indexRequest.index("test2").id("7").source(map);
bulkRequest.add(indexRequest);
//修改操作
Map map2 = new HashMap();
map2.put("age",12);
map2.put("name","test11212");
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.index("test2").id("7").doc(map2);
bulkRequest.add();
//执行批量操作,返回结果封装在Response对象中
BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(response.status());
}
}
注意:在我们使用java代码操作ES导入数据的时候,特别注意插入的字符串的格式(即JSON格式是否正确),否者可能会导致不报错但是ES里没有数据,追查原因可以在返回的Response对象中打断点,尝试在对象中查看异常信息
十一、ES中的常用查询
1.查询所文档
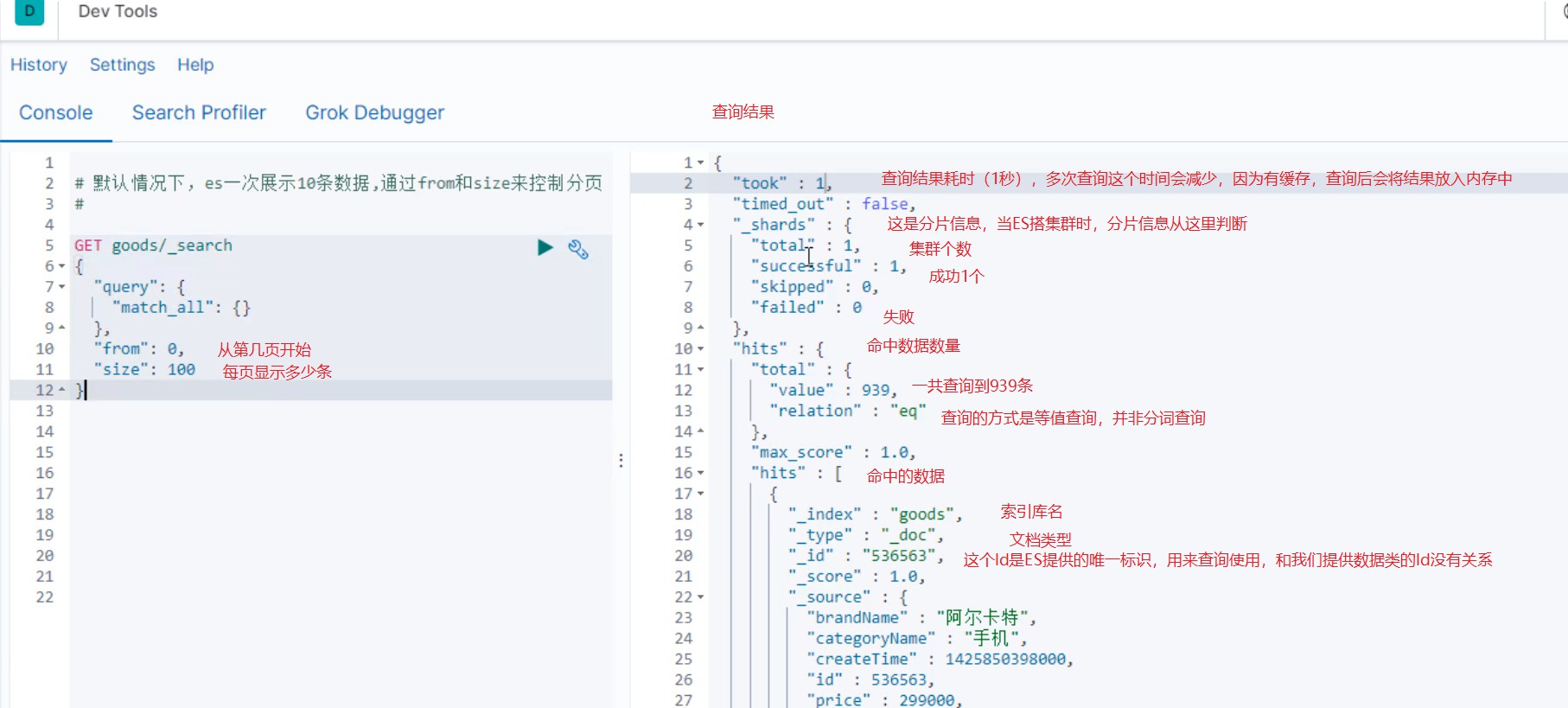
查询结果中的max-score是得分,ES会更具这个得分进行排序
2.term查询(不会对查询条件进行分词,它会将查询条件和词条进行全匹配)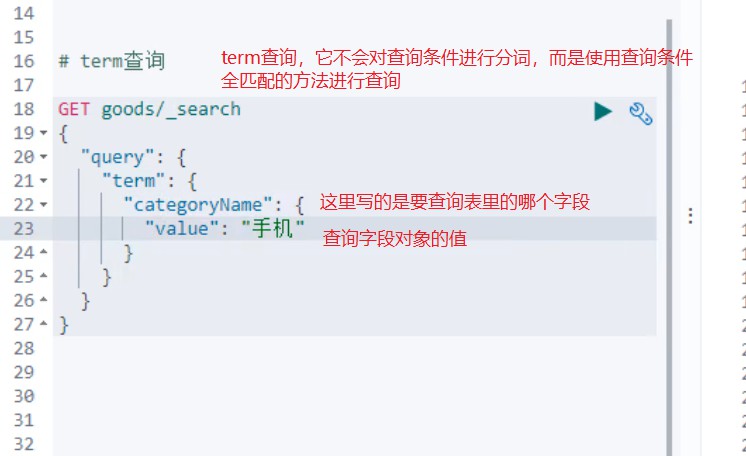
对于term查询,一般我们进行term查询的时候,最好映射列也是不分词的列,这样效率更高
3.match查询(它会对查询条件进行分词)

4.模糊查询(它会对查询条件分词,然后进行模糊查询,可以通过通配符来进行通配查询)
5.正则查询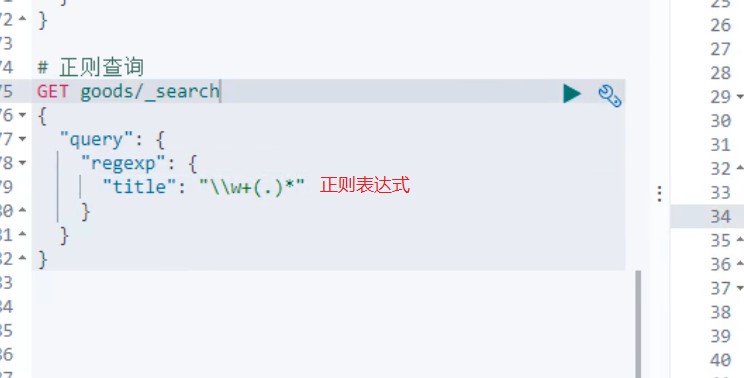
6.前缀查询:(即以什么开头的,这个查询对映射为keyword类型的支持的比较好)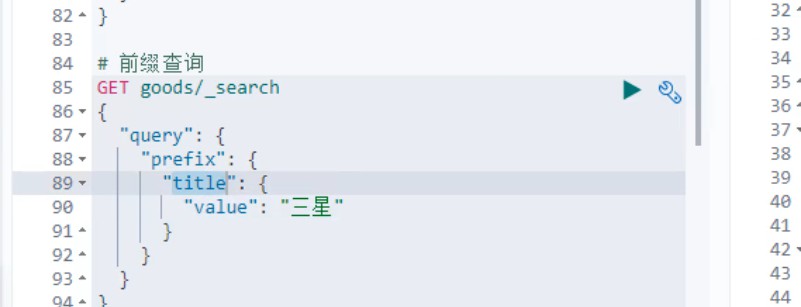
7.范围查询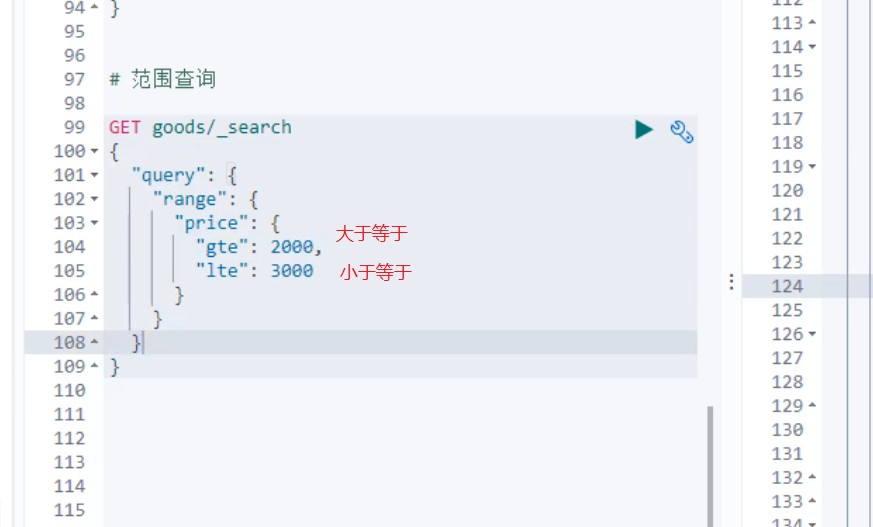
8.对查询结果记性排序(任何查询结果都可以进行排序)
9.多字段匹配查询(和match查询很类似,但是同时匹配多个字段分词,这里的查询条件也可以写多个,可以取交集或者并集,例如华为or手机,表示字段中有华为或者手机,如果是华为and手机表示字段中既有华为又有手机才可以出现)

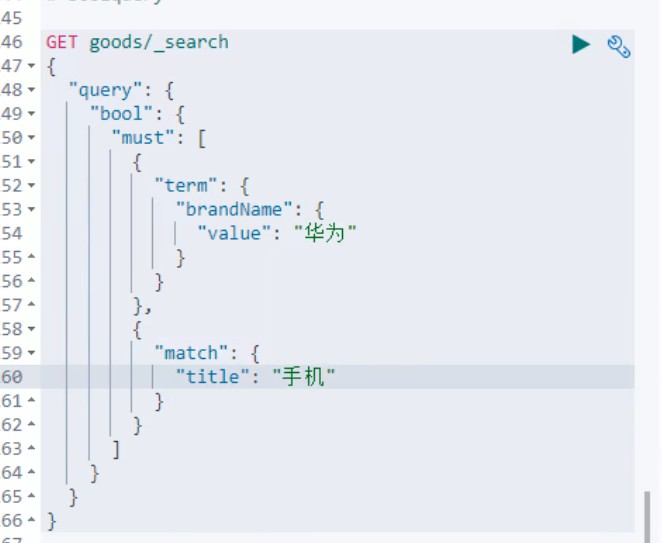
10.布尔查询:它是同时进行多个查询,将查询结果连接
2.常用查询之Java代码操作**
@SpringBootTest
class ElasticsearchDemo2ApplicationTests {
@Autowired
private RestHighLevelClient client;
@Autowired
private GoodsMapper goodsMapper;
/**
* 批量导入
*/
@Test
public void importData() throws IOException {
//1.查询所有数据,mysql
List<Goods> goodsList = goodsMapper.findAll();
//System.out.println(goodsList.size());
//2.bulk导入
BulkRequest bulkRequest = new BulkRequest();
//2.1 循环goodsList,创建IndexRequest添加数据
for (Goods goods : goodsList) {
//2.2 设置spec规格信息 Map的数据 specStr:{}
//goods.setSpec(JSON.parseObject(goods.getSpecStr(),Map.class));
String specStr = goods.getSpecStr();
//将json格式字符串转为Map集合
Map map = JSON.parseObject(specStr, Map.class);
//设置spec map
goods.setSpec(map);
//将goods对象转换为json字符串
String data = JSON.toJSONString(goods);//map --> {}
IndexRequest indexRequest = new IndexRequest("goods");
indexRequest.id(goods.getId()+"").source(data, XContentType.JSON);
bulkRequest.add(indexRequest);
}
BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(response.status());
}
/**
* 查询所有
* 1. matchAll
* 2. 将查询结果封装为Goods对象,装载到List中
* 3. 分页。默认显示10条
*/
@Test
public void testMatchAll() throws IOException {
//2. 构建查询请求对象,指定查询的索引名称
SearchRequest searchRequest = new SearchRequest("goods");
//4. 创建查询条件构建器SearchSourceBuilder
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//6. 查询条件
QueryBuilder query = QueryBuilders.matchAllQuery();//查询所有文档
//5. 指定查询条件
sourceBuilder.query(query);
//3. 添加查询条件构建器 SearchSourceBuilder
searchRequest.source(sourceBuilder);
// 8 . 添加分页信息
sourceBuilder.from(0);
sourceBuilder.size(100);
//1. 查询,获取查询结果
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//7. 获取命中对象 SearchHits
SearchHits searchHits = searchResponse.getHits();
//7.1 获取总记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
//7.2 获取Hits数据 数组
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
//获取json字符串格式的数据
String sourceAsString = hit.getSourceAsString();
//转为java对象
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}
/**
* termQuery:词条查询
*/
@Test
public void testTermQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
QueryBuilder query = QueryBuilders.termQuery("title","华为");//term词条查询
sourceBulider.query(query);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}
/**
* matchQuery:词条分词查询
*/
@Test
public void testMatchQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
MatchQueryBuilder query = QueryBuilders.matchQuery("title", "华为手机");
query.operator(Operator.AND);//求并集
sourceBulider.query(query);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}
/**
* 模糊查询:WildcardQuery
*/
@Test
public void testWildcardQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
WildcardQueryBuilder query = QueryBuilders.wildcardQuery("title", "华*");
sourceBulider.query(query);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}
/**
* 模糊查询:regexpQuery
*/
@Test
public void testRegexpQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
RegexpQueryBuilder query = QueryBuilders.regexpQuery("title", "\\w+(.)*");
sourceBulider.query(query);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}
/**
* 模糊查询:perfixQuery
*/
@Test
public void testPrefixQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
PrefixQueryBuilder query = QueryBuilders.prefixQuery("brandName", "三");
sourceBulider.query(query);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}
/**
* 1. 范围查询:rangeQuery
* 2. 排序
*/
@Test
public void testRangeQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
//范围查询
RangeQueryBuilder query = QueryBuilders.rangeQuery("price");
//指定下限
query.gte(2000);
//指定上限
query.lte(3000);
sourceBulider.query(query);
//排序
sourceBulider.sort("price", SortOrder.DESC);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}
/**
* queryString
*/
@Test
public void testQueryStringQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
//queryString
QueryStringQueryBuilder query = QueryBuilders.queryStringQuery("华为手机").field("title").field("categoryName").field("brandName").defaultOperator(Operator.AND);
sourceBulider.query(query);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}
/**
* 布尔查询:boolQuery
* 1. 查询品牌名称为:华为
* 2. 查询标题包含:手机
* 3. 查询价格在:2000-3000
*/
@Test
public void testBoolQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
//1.构建boolQuery
BoolQueryBuilder query = QueryBuilders.boolQuery();
//2.构建各个查询条件
//2.1 查询品牌名称为:华为
QueryBuilder termQuery = QueryBuilders.termQuery("brandName","华为");
query.must(termQuery);
//2.2. 查询标题包含:手机
QueryBuilder matchQuery = QueryBuilders.matchQuery("title","手机");
query.filter(matchQuery);
//2.3 查询价格在:2000-3000
QueryBuilder rangeQuery = QueryBuilders.rangeQuery("price");
((RangeQueryBuilder) rangeQuery).gte(2000);
((RangeQueryBuilder) rangeQuery).lte(3000);
query.filter(rangeQuery);
//3.使用boolQuery连接
sourceBulider.query(query);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}
/**
* 聚合查询:桶聚合,分组查询
* 1. 查询title包含手机的数据
* 2. 查询品牌列表
*/
@Test
public void testAggQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
// 1. 查询title包含手机的数据
MatchQueryBuilder query = QueryBuilders.matchQuery("title", "手机");
sourceBulider.query(query);
// 2. 查询品牌列表
/*
参数:
1. 自定义的名称,将来用于获取数据
2. 分组的字段
*/
AggregationBuilder agg = AggregationBuilders.terms("goods_brands").field("brandName").size(100);
sourceBulider.aggregation(agg);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
// 获取聚合结果
Aggregations aggregations = searchResponse.getAggregations();
Map<String, Aggregation> aggregationMap = aggregations.asMap();
//System.out.println(aggregationMap);
Terms goods_brands = (Terms) aggregationMap.get("goods_brands");
List<? extends Terms.Bucket> buckets = goods_brands.getBuckets();
List brands = new ArrayList();
for (Terms.Bucket bucket : buckets) {
Object key = bucket.getKey();
brands.add(key);
}
for (Object brand : brands) {
System.out.println(brand);
}
}
/**
*
* 高亮查询:
* 1. 设置高亮
* * 高亮字段
* * 前缀
* * 后缀
* 2. 将高亮了的字段数据,替换原有数据
*/
@Test
public void testHighLightQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
// 1. 查询title包含手机的数据
MatchQueryBuilder query = QueryBuilders.matchQuery("title", "手机");
sourceBulider.query(query);
//设置高亮
HighlightBuilder highlighter = new HighlightBuilder();
//设置三要素
highlighter.field("title");
highlighter.preTags("<font color='red'>");
highlighter.postTags("</font>");
sourceBulider.highlighter(highlighter);
// 2. 查询品牌列表
/*
参数:
1. 自定义的名称,将来用于获取数据
2. 分组的字段
*/
AggregationBuilder agg = AggregationBuilders.terms("goods_brands").field("brandName").size(100);
sourceBulider.aggregation(agg);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
// 获取高亮结果,替换goods中的title
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField HighlightField = highlightFields.get("title");
Text[] fragments = HighlightField.fragments();
//替换
goods.setTitle(fragments[0].toString());
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
// 获取聚合结果
Aggregations aggregations = searchResponse.getAggregations();
Map<String, Aggregation> aggregationMap = aggregations.asMap();
//System.out.println(aggregationMap);
Terms goods_brands = (Terms) aggregationMap.get("goods_brands");
List<? extends Terms.Bucket> buckets = goods_brands.getBuckets();
List brands = new ArrayList();
for (Terms.Bucket bucket : buckets) {
Object key = bucket.getKey();
brands.add(key);
}
for (Object brand : brands) {
System.out.println(brand);
}
}
}
十二、ES集群
1.ES集群的介绍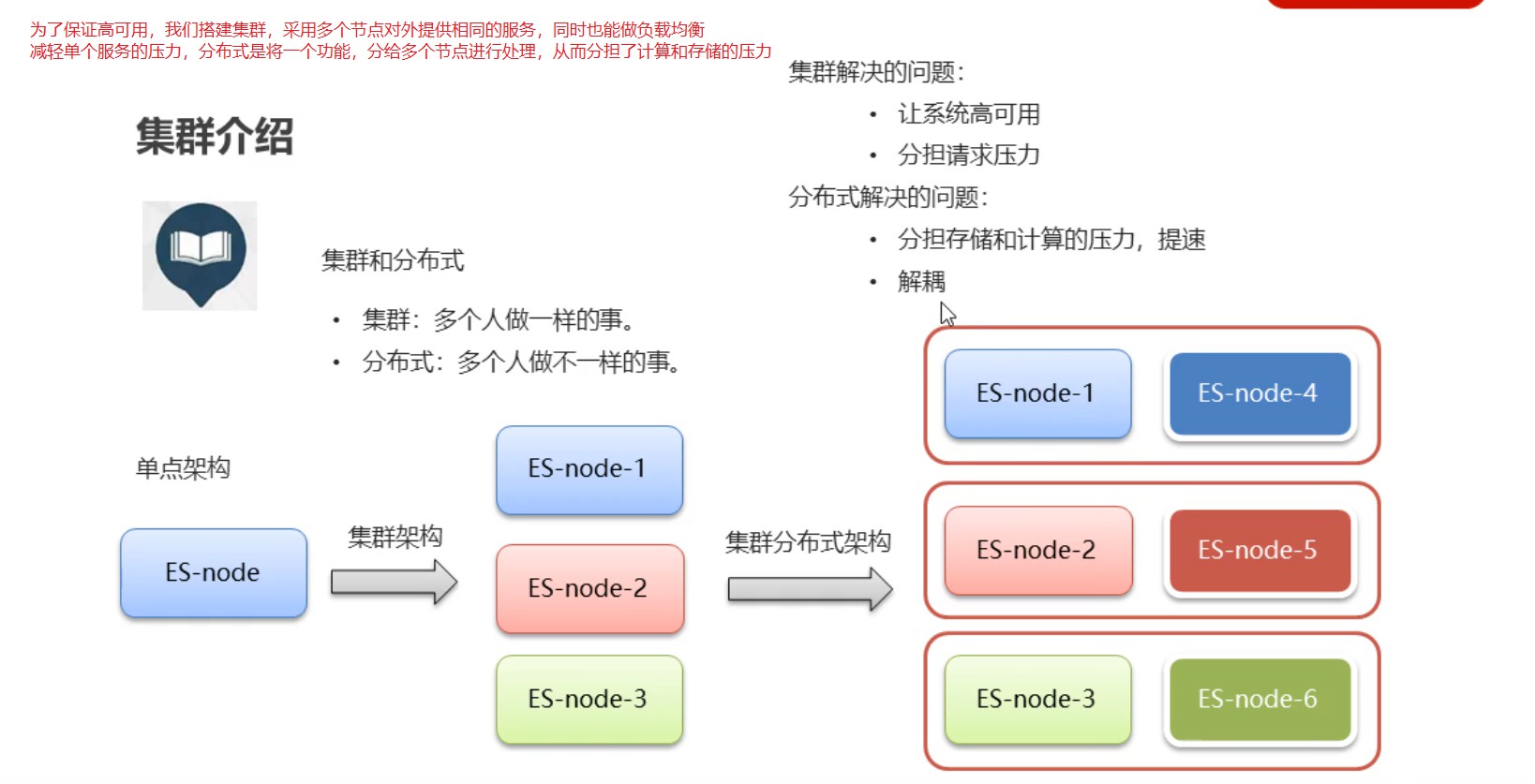
ES是天然的分布式的,隐藏了内部集群的复杂度,也就是说,我们可以通过简单的配置就可以实现集群的搭建,同时会负载均衡一些处理内部都已经处理好了
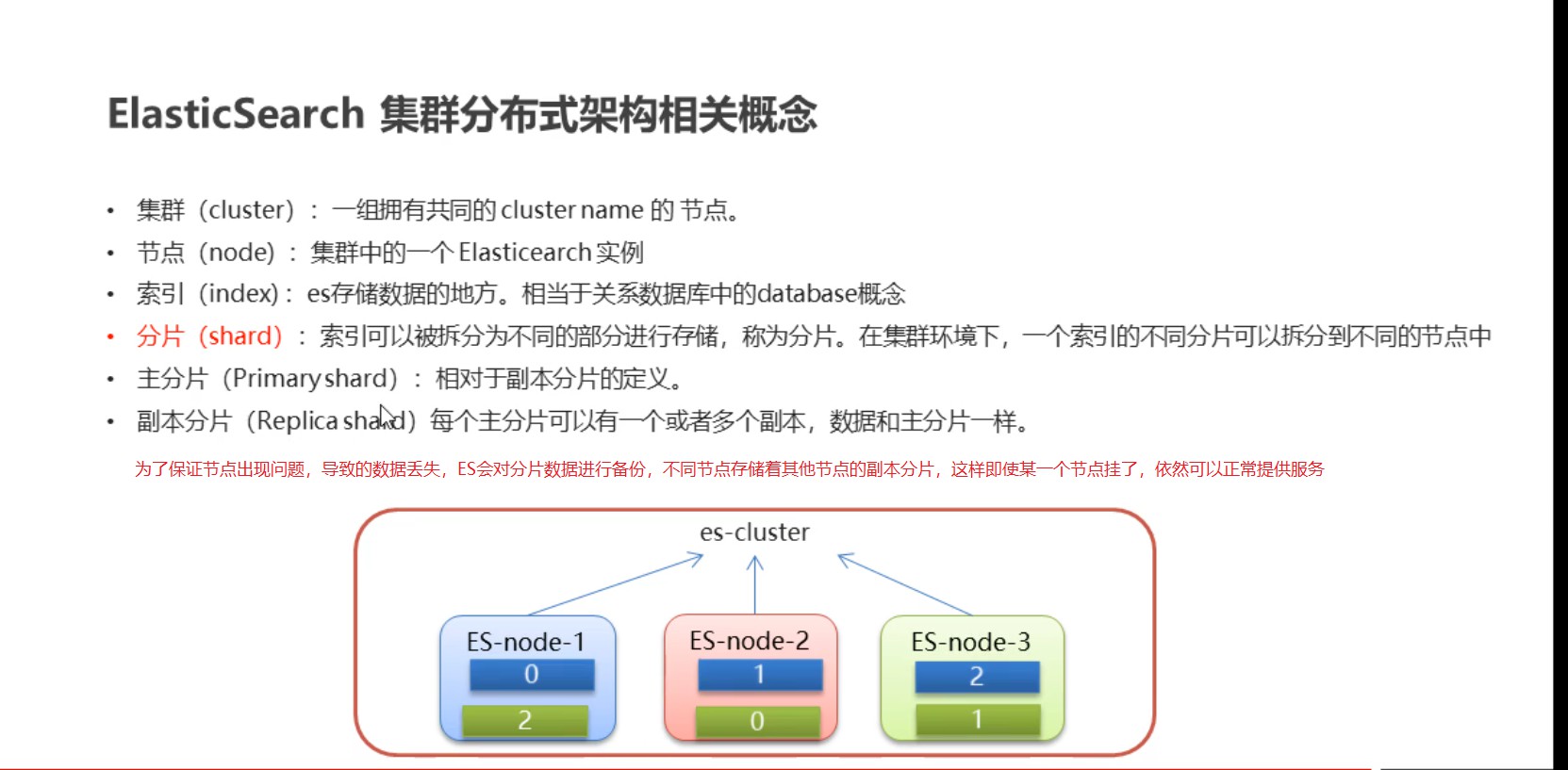
2.集群的相关概念
3.ES集群的搭建
Elasticsearch如果做集群的话Master节点至少三台服务器或者三个Master实例加入相同集群,三个Master节点最多只能故障一台Master节点,如果故障两个Master节点,Elasticsearch将无法组成集群.会报错,Kibana也无法启动,因为Kibana无法获取集群中的节点信息。
由于,我们使用只有一台虚拟机,所以我们在虚拟机中安装三个ES实例,搭建伪集群,而ES启动比较耗内存,所以先设置虚拟机的内存3G和CPU个数4个
1.1.1 整体步骤
步骤如下:
- 拷贝opt目录下的elasticsearch-7.4.0安装包3个,分别命名:
elasticsearch-7.4.0-itcast1
elasticsearch-7.4.0-itcast2
elasticsearch-7.4.0-itcast3 - 然后修改elasticsearch.yml文件件。
- 然后启动启动itcast1、itcast2、itcast3三个节点。
- 打开浏览器输⼊:http://192.168.149.135:9200/_cat/health?v ,如果返回的node.total是3,代表集 群搭建成功
在此,需要我们特别注意的是,像本文这样单服务器多节点( 3 个节点)的情况,仅供测试使用,集群环境如下:
| cluster name | node name | IP Addr | http端口 / 通信端口 |
| itcast-es | itcast1 | 192.168.149.135 | 9201 / 9700 |
| itcast-es | itcast2 | 192.168.149.135 | 9202 / 9800 |
| itcast-es | itcast3 | 192.168.149.135 | 9203 / 9900 |
1.1.2 拷贝副本
拷贝opt目录下的elasticsearch-7.4.0安装包3个,打开虚拟机到opt目录
执行 拷贝三份
cd /opt
cp -r elasticsearch-7.4.0 elasticsearch-7.4.0-itcast1
cp -r elasticsearch-7.4.0 elasticsearch-7.4.0-itcast2
cp -r elasticsearch-7.4.0 elasticsearch-7.4.0-itcast3
1.1. 3 修改elasticsearch.yml配置文件
1)、创建日志目录
cd /opt
mkdir logs
mkdir data
# 授权给itheima用户
chown -R itheima:itheima ./logs
chown -R itheima:itheima ./data
chown -R itheima:itheima ./elasticsearch-7.4.0-itcast1
chown -R itheima:itheima ./elasticsearch-7.4.0-itcast2
chown -R itheima:itheima ./elasticsearch-7.4.0-itcast3
打开elasticsearch.yml配置,分别配置下面三个节点的配置文件
vim /opt/elasticsearch-7.4.0-itcast1/config/elasticsearch.yml
vim /opt/elasticsearch-7.4.0-itcast2/config/elasticsearch.yml
vim /opt/elasticsearch-7.4.0-itcast3/config/elasticsearch.yml
2)、下面是elasticsearch-7.4.0-itcast1配置文件
cluster.name: itcast-es
node.name: itcast-1
node.master: true
node.data: true
node.max_local_storage_nodes: 3
network.host: 0.0.0.0
http.port: 9201
transport.tcp.port: 9700
discovery.seed_hosts: [“localhost:9700”,”localhost:9800”,”localhost:9900”]
cluster.initial_master_nodes: [“itcast-1”, “itcast-2”,”itcast-3”]
path.data: /opt/data
path.logs: /opt/logs
#集群名称
cluster.name: itcast-es
#节点名称
node.name: itcast-1
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#ip地址
network.host: 0.0.0.0
#端口
http.port: 9201
#内部节点之间沟通端口
transport.tcp.port: 9700
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: [“localhost:9700”,”localhost:9800”,”localhost:9900”]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: [“itcast-1”, “itcast-2”,”itcast-3”]
#数据和存储路径
path.data: /opt/data
path.logs: /opt/logs
3)、下面是elasticsearch-7.4.0-itcast2配置文件
cluster.name: itcast-es
node.name: itcast-2
node.master: true
node.data: true
node.max_local_storage_nodes: 3
network.host: 0.0.0.0
http.port: 9202
transport.tcp.port: 9800
discovery.seed_hosts: [“localhost:9700”,”localhost:9800”,”localhost:9900”]
cluster.initial_master_nodes: [“itcast-1”, “itcast-2”,”itcast-3”]
path.data: /opt/data
path.logs: /opt/logs
#集群名称
cluster.name: itcast-es
#节点名称
node.name: itcast-2
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#ip地址
network.host: 0.0.0.0
#端口
http.port: 9202
#内部节点之间沟通端口
transport.tcp.port: 9800
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: [“localhost:9700”,”localhost:9800”,”localhost:9900”]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: [“itcast-1”, “itcast-2”,”itcast-3”]
#数据和存储路径
path.data: /opt/data
path.logs: /opt/logs
4)、下面是elasticsearch-7.4.0-itcast3 配置文件
cluster.name: itcast-es
node.name: itcast-3
node.master: true
node.data: true
node.max_local_storage_nodes: 3
network.host: 0.0.0.0
http.port: 9203
transport.tcp.port: 9900
discovery.seed_hosts: [“localhost:9700”,”localhost:9800”,”localhost:9900”]
cluster.initial_master_nodes: [“itcast-1”, “itcast-2”,”itcast-3”]
path.data: /opt/data
path.logs: /opt/logs
#集群名称
cluster.name: itcast-es
#节点名称
node.name: itcast-3
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#ip地址
network.host: 0.0.0.0
#端口
http.port: 9203
#内部节点之间沟通端口
transport.tcp.port: 9900
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: [“localhost:9700”,”localhost:9800”,”localhost:9900”]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: [“itcast-1”, “itcast-2”,”itcast-3”]
#数据和存储路径
path.data: /opt/data
path.logs: /opt/logs
1.1.4 执行授权
在root用户下执行
chown -R itheima:itheima /opt/elasticsearch-7.4.0-itcast1
chown -R itheima:itheima /opt/elasticsearch-7.4.0-itcast2
chown -R itheima:itheima /opt/elasticsearch-7.4.0-itcast3
如果有的日志文件授权失败,可使用(也是在root下执行)
cd /opt/elasticsearch-7.4.0-itcast1/logs
chown -R itheima:itheima ./
cd /opt/elasticsearch-7.4.0-itcast2/logs
chown -R itheima:itheima ./
cd /opt/elasticsearch-7.4.0-itcast3/logs
chown -R itheima:itheima ./*
1.1.5 启动三个节点
启动之前,设置ES的JVM占用内存参数,防止内存不足错误
vim /opt/elasticsearch-7.4.0-itcast1/bin/elasticsearch
可以发现,ES启动时加载/config/jvm.options文件
vim /opt/elasticsearch-7.4.0-itcast1/config/jvm.options
默认情况下,ES启动JVM最小内存1G,最大内存1G
-xms:最小内存
-xmx:最大内存
修改为256m
启动成功访问节点一:
可以从日志中看到:master not discovered yet。还没有发现主节点
访问集群状态信息 http://192.168.149.135:9201/_cat/health?v 不成功
启动成功访问节点二:
可以从日志中看到:master not discovered yet。还没有发现主节点master node changed.已经选举出主节点itcast-2
访问集群状态信息 http://192.168.149.135:9201/_cat/health?v 成功
健康状况结果解释:
cluster 集群名称
status 集群状态
green代表健康;
yellow代表分配了所有主分片,但至少缺少一个副本,此时集群数据仍旧完整;
red 代表部分主分片不可用,可能已经丢失数据。
node.total代表在线的节点总数量
node.data代表在线的数据节点的数量
shards 存活的分片数量
pri 存活的主分片数量 正常情况下 shards的数量是pri的两倍。
relo迁移中的分片数量,正常情况为 0
init 初始化中的分片数量 正常情况为 0
unassign未分配的分片 正常情况为 0
pending_tasks准备中的任务,任务指迁移分片等 正常情况为 0
max_task_wait_time任务最长等待时间
active_shards_percent正常分片百分比 正常情况为 100%
启动成功访问节点三
访问集群状态信息 http://192.168.149.135:9201/_cat/health?v 成功
十三 使用Kibana配置和管理集群
1.2.1 集群配置
因为之前我们在单机演示的时候也使用到了Kibana,我们先复制出来一个Kibana,然后修改它的集群配置
cd /opt/
cp -r kibana-7.4.0-linux-x86_64 kibana-7.4.0-linux-x86_64-cluster
# 由于 kibana 中文件众多,此处会等待大约1分钟的时间
修改Kibana的集群配置
vim kibana-7.4.0-linux-x86_64-cluster/config/kibana.yml
加入下面的配置
elasticsearch.hosts: [“http://localhost:9201","http://localhost:9202","http://localhost:9203“]
启动Kibana
sh kibana —allow-root
1.2.2 管理集群
1、打开Kibana,点开 Stack Monitoring 集群监控
2、点击【Nodes】查看节点详细信息
在上图可以看到,第一个红框处显示【Green】,绿色,表示集群处理健康状态
第二个红框是我们集群的三个节点,注意,itcast-3旁边是星星,表示是主节点

若有收获,就点个赞吧
0 人点赞
