背景:
基本就是这样的环境:TKE 1.20.6搭建Kube-Prometheus(prometheus-oprator,做了一个cronjob:
Kubernetes Cronjob的第一次使用。更新版本时候job发生了异常。但是后来都恢复了。可是alertmanager一直报警:
相当惹人烦。该怎么处理呢?
Kubernetes prometheus Job误报解决
1. 暴力方式-删除失败的job!
[root@k8s-master-01 manifests]# kubectl get job -n develop-layaverseNAME COMPLETIONS DURATION AGExxxx-worldmap-job-27468560 0/1 13d 13dxxxx-worldmap-job-27487460 1/1 1s 11mxxxx-worldmap-job-27487465 1/1 1s 6m57sxxxx-worldmap-job-27487470 1/1 1s 117s[root@k8s-master-01 manifests]# kubectl get cronjob -n develop-layaverseNAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGExxxx-worldmap-job */5 * * * * False 0 2m15s 79d
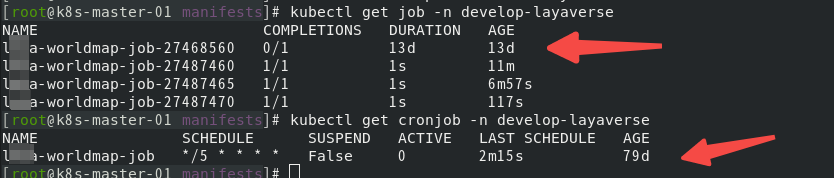
默认应该是显示三个job的。这个失败的还一直在…..按照正常的理解删除调失败的job就可以了吧?当然了,还想打破砂锅问到底的其解决一下的。这个简单方式先列在这里,最后去尝试!
2.修改elert规则
1. prometheus web 确认报警的elerts
登陆prometheus控制台首先确认报警的两个alerts是KubeJobCompletion and KubeJobFailed.正常理解下应该是从这两个elerts入手吧?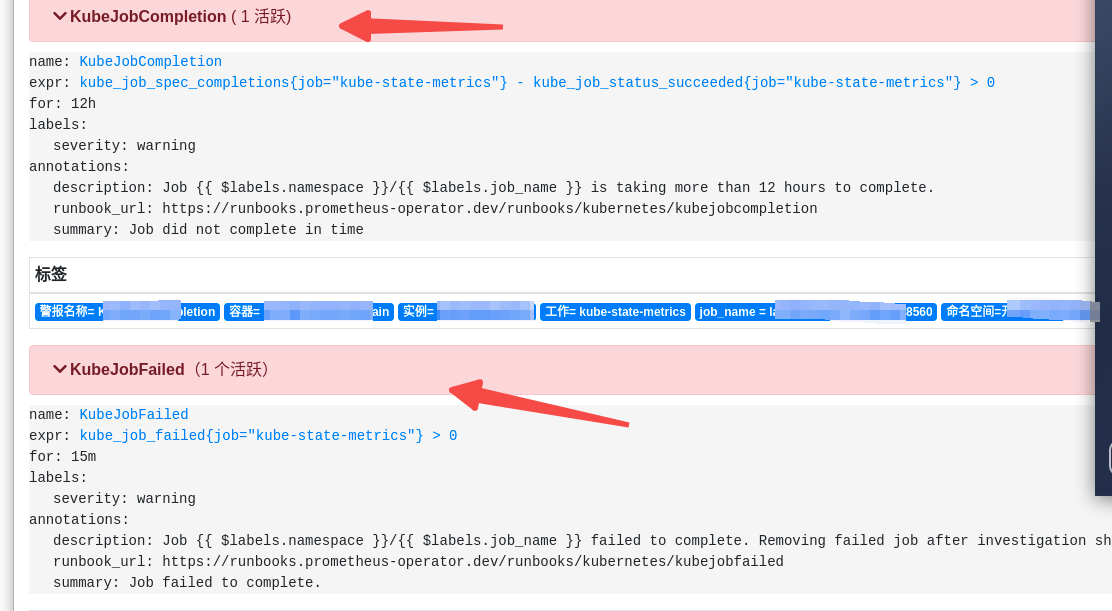
elerts配置文件在kubernetes-prometheusRule.yaml中:
[root@k8s-master-01 manifests]# grep -r KubeJobFailed ./
./kubernetes-prometheusRule.yaml: - alert: KubeJobFailed
[root@k8s-master-01 manifests]# grep -r KubeJobCompletion ./
./kubernetes-prometheusRule.yaml: - alert: KubeJobCompletion

两个elert的相关配置如下: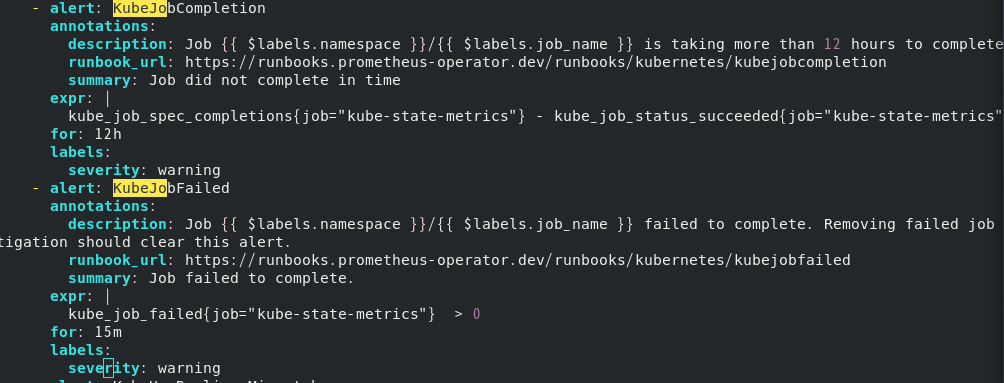
2. 具体相关的可以借鉴:
三篇文章仔细读一下很相似,最早的是Prometheus: K8s Cronjob alerts,2018年写的。Prometheus 监控kubernetes Job资源误报的坑 是阳明大佬写的。但是就事论事,跟Monitoring kubernetes jobs有很大雷同。由于规则记录,报警规则我还是不太熟悉….没有深入研究具体的其参考阳明大佬的博客吧!https://www.qikqiak.com/post/prometheus-monitor-k8s-job-trap/…….不知为不知毕竟都用了默认的.等熟悉一下再去深入。这里就先删除失败的job了。后续系统研究……

若有收获,就点个赞吧
0 人点赞
