3.2规范化
一、L1/L2规范化
L1: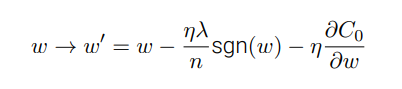
L2: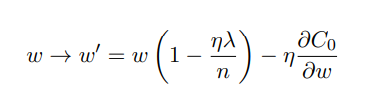
区别:
- 在 L1 规范化中,权重通过⼀个常量向 0 进⾏缩⼩。
- 在 L2 规范化中,权重通过⼀个和 w 成⽐例的量进⾏缩⼩的。
最终的结果就是:L1 规范化倾向于聚集⽹络的权重在相对少量的⾼重要度连接上,⽽其他权重就会被驱使向 0 接近。
二、弃权
从随机(临时)地删除⽹络中的⼀半的隐藏神经元开始,同时让输⼊层和输出层的神经元保持不变。 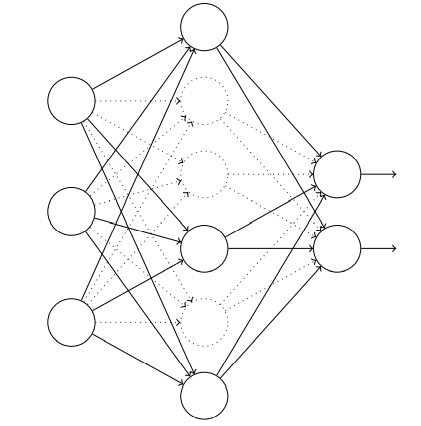
步骤:
我们前向传播输⼊ x,通过修改后的⽹络,然后反向传播结果,同样通过这个修改后的⽹络。 在⼀个⼩批量数据⼩批量的若⼲样本上进⾏这些步骤后,我们对有关的权重和偏置进⾏更新。 然后重复这个过程,⾸先重置弃权的神经元,然后选择⼀个新的随机的隐藏神经元的⼦集进⾏ 删除,估计对⼀个不同的⼩批量数据的梯度,然后更新权重和偏置。
(可以理解为训练了多个小型神经网络,进行平均投票法,降低了个别网络判断错误对整体的影响)
(减少了复杂的互适应的神经元 )
弃权技术在训练⼤规模深度⽹络时尤其有⽤,这样的⽹络中过度拟合问题经常特别突出。
三、人为扩展训练数据集
大致步骤:人为对数据集进行一定的扭曲变形旋转等形态学变换
3.3权重初始化
一、随机初始化变量
通过独立高斯随机变量来选择 权重 和 偏置,其被归⼀化为均值为 0,标准差 1。
二、优化后的随机变量
假设我们有⼀个有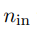 个输⼊权重的神经元
个输⼊权重的神经元
使⽤均值为 0 ,标准差为 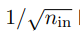 的⾼斯 随机分布初始化这些权重。
的⾼斯 随机分布初始化这些权重。
也就是说,我们会向下挤压⾼斯分布,让我们的神经元更不可能饱和。我们会继续使⽤均值为 0 标准差为 1 的⾼斯分布来对偏置进⾏初始化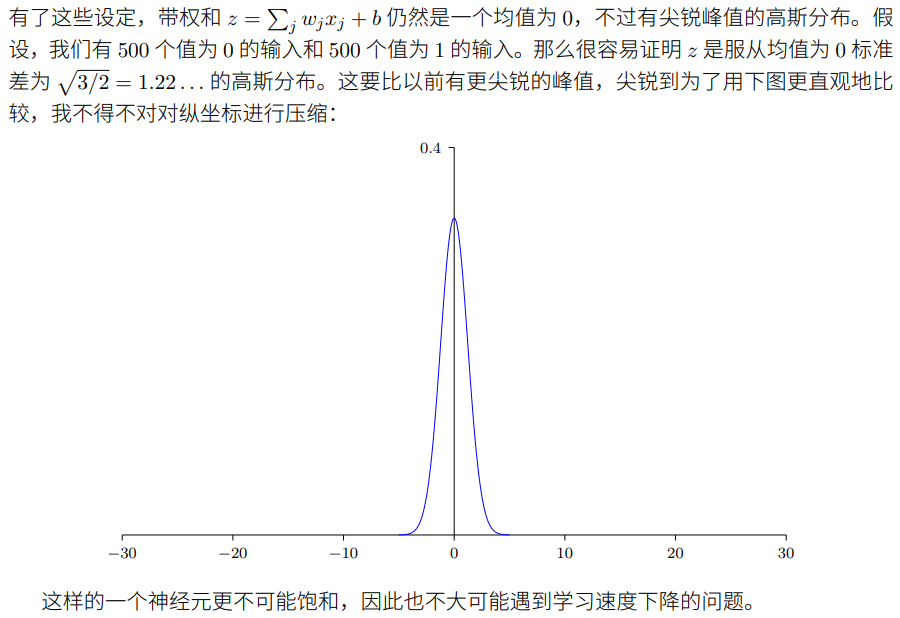
3.5 超参数的选择
一、宽泛策略
- 简化训练集提升速度
- 简化初始网络
- 通过更加频繁的监控来获得准备率的反馈
二、具体分析
- 学习速率
参照训练数据的代价函数来找到阈值,并慢慢调整。
学习速率调整:我们⼀直都将学习速率设置为常量。但是,通常采⽤可变的学习速率更加有 效。在学习的前期,权重可能⾮常糟糕。所以最好是使⽤⼀个较⼤的学习速率让权重变化得更 快。
使⽤提前停⽌来确定训练的迭代期数量
在每个回合的最后,我们都要计算验证集上的分类准确率。当准确率不再提升,就终⽌它。
规范化参数
我建议,开始时不包含规范化(λ = 0.0),确定 η 的值。使⽤确定出来的 η,我 们可以使⽤验证数据来选择好的 λ。从尝试 λ = 1.0 开始,然后根据验证集上的性能按照因⼦ 10 增加或减少其值。⼀旦我已经找到⼀个好的量级,你可以改进 λ 的值。这⾥搞定后,你就可以 返回再重新优化 η。
⼩批量数据⼤⼩
⼩批量数据⼤⼩的选择其实是相对独⽴的⼀个超参数(⽹络整体架 构外的参数)
可以确定相对可以接受的其他超参数,然后开始对小批量数据的大小开始进行调整

若有收获,就点个赞吧
0 人点赞
