1,关键词过滤用的txt文本将关键词记录并上传至服务器(关键词用 | 隔开)
2,上传文件时为保证存取的文本内容不乱码,做了utf8转码并将txt文本内容保存
/*** 将非UTF-8字符集的编码转为UTF-8* @author chenrui* @datetime 2019/10/14 19:00* @param mixed $mixed 源数据* @return array|string utf-8格式数据*/public static function charsetToUTF8($mixed){if (is_array($mixed)) {foreach ($mixed as $k => $v) {if (is_array($v)) {$mixed[$k] = self::charsetToUTF8($v);} else {$encode = mb_detect_encoding($v, array('ASCII', 'UTF-8', 'GB2312', 'GBK', 'BIG5'));if ($encode == 'EUC-CN') {$mixed[$k] = iconv('GBK', 'UTF-8', $v);}}}} else {$encode = mb_detect_encoding($mixed, array('ASCII', 'UTF-8', 'GB2312', 'GBK', 'BIG5'));if ($encode == 'EUC-CN') {$mixed = iconv('GBK', 'UTF-8', $mixed);}}return $mixed;}
3,判断时获取关键词内容组成的数组,循环判断所检测字符串是否存在关键词
foreach ($keyArr as $arr) {foreach ($arr as $key=>$val){//字符串str中是否包含关键词valif(strripos($str,$val) !== false){$matches[] = $val;}}/*$blackList = "/" . implode("|", $arr) . "/i";if (preg_match($blackList, $str, $m)) {$matches = $m;return false;}*/}//$matches = [];if(!empty($matches)){return false;}return true;
然后就这样,神奇的事出现在。文本中的第一个词始终匹配失败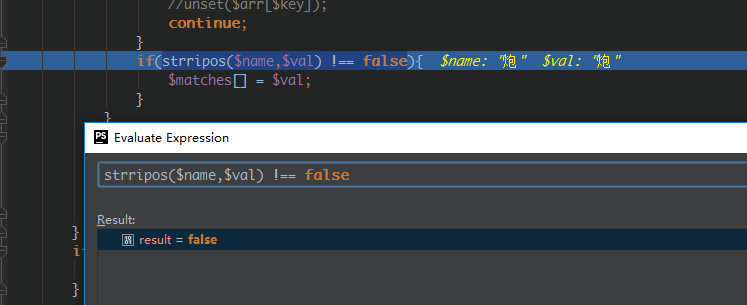
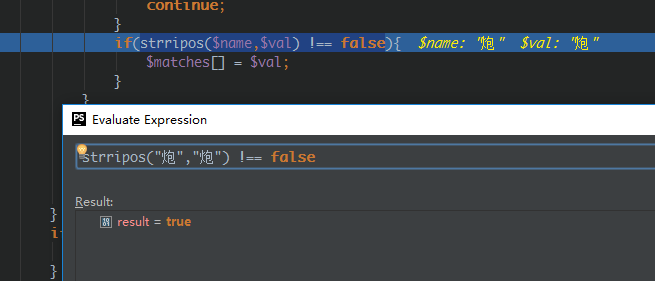
用尽各种方法,都不能知道什么情况会这样。并且整个文件中就第一个词不会被匹配上。
如果我自己在桌面上创建txt文件并上传时,第一个词又能匹配上。
将name和val值交换后,又会出现这种: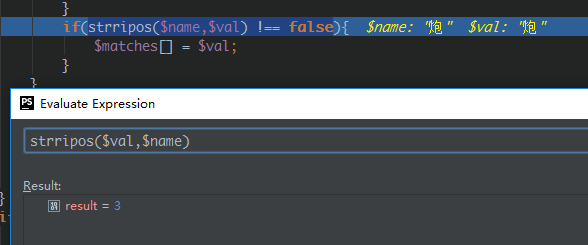
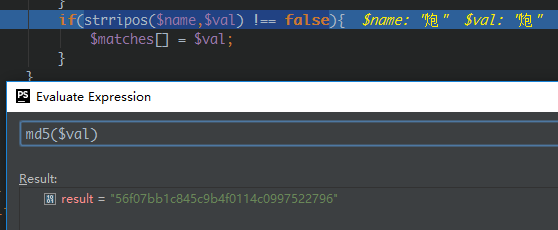
说明$val中包含$name,且$name位于$val的第4位。
算了下md5值,发现两个字符串其实真不是一样的: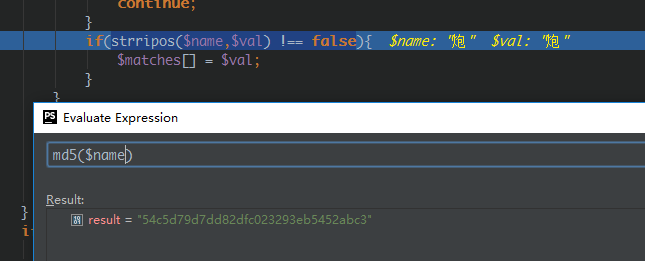
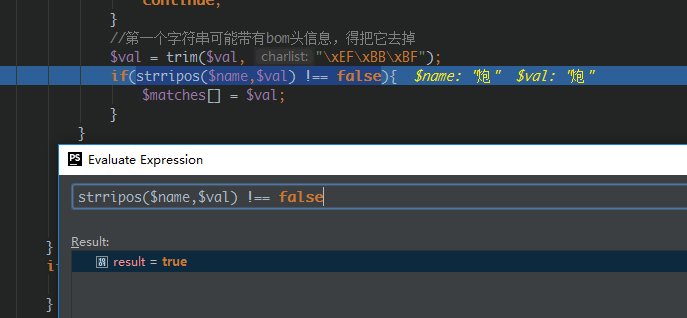
到这儿基本就明了了,检测不成功是因为$val带了bom头。因为保存到服务器中的是utf8格式的文件。我将其下载后用记事本打开编辑完后再上传。使得文本内容中其实包含了bom头的信息。
坑!!!
然后调整了下,就ok了!
//第一个字符串可能带有bom头信息,得把它去掉$val = trim($val, "\xEF\xBB\xBF");if(strripos($name,$val) !== false){$matches[] = $val;}
后来想了想,为了方便,其实在文本内容上传时,就把bom头信息去掉就没有任何问题了。

若有收获,就点个赞吧
0 人点赞
