昨天朋友给了我一个任务,让我想办法获取http://lishi.tianqi.com/hongya/201611.html中的部分内容到excel表中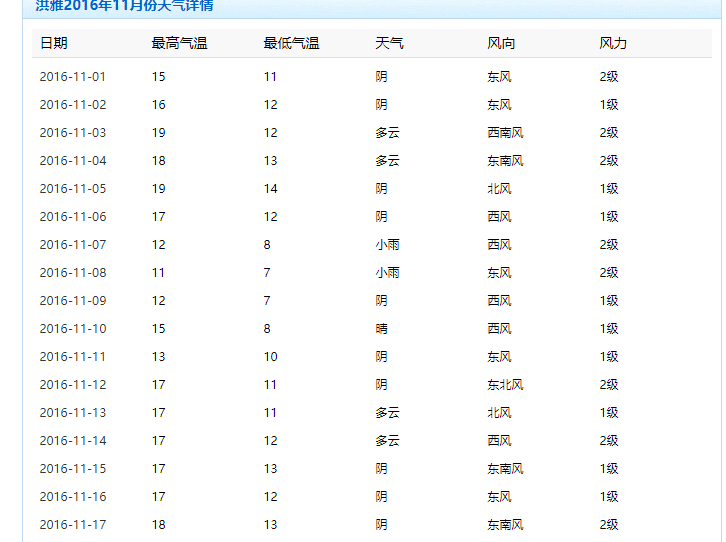
通过网址和页面规律,我觉得可以扒指定地点,指定时间段内的内容。这还是蛮简单的。
先贴一下我获取网站内容的方法吧
<?phprequire_once "OTagString.class.php";$str = file_get_contents("http://lishi.tianqi.com/hongya/201611.html");$str = iconv("gb2312", "utf-8",$str); //转码,防止乱码//获取需要的内容$class = new OTagString();$str2 = $class->get_str($str,"<div class=\"tqtongji2\">","<div class=\"lishicity03\">");$str2 = trim($str2);//echo $str2;$table_data = preg_match_all('#<ul>(.*?)</ul>#si',$str2,$match);//print_r($match[0]);$table_array = $match[0];//$table_array = explode('<li>',$match[0]);//print_r($table_array);exit;$data = [];$data2 = [];for($i=0;$i<count($table_array);$i++){$data[$i] = explode('</li>',$table_array[$i]);//只要前四组数据for($j = 0;$j<4;$j++){$data2[$i][$j] = preg_replace('/\s(?=\s)/','',trim(strip_tags($data[$i][$j])));}}print_r($data2);
结果:
ps:相关经验见
https://www.yuque.com/darry/php/qpbnq2
https://www.yuque.com/darry/php/ti0nm3

若有收获,就点个赞吧
0 人点赞
