How to choose two models?
https://pubs.rsna.org/doi/pdf/10.1148/radiology.148.3.6878708

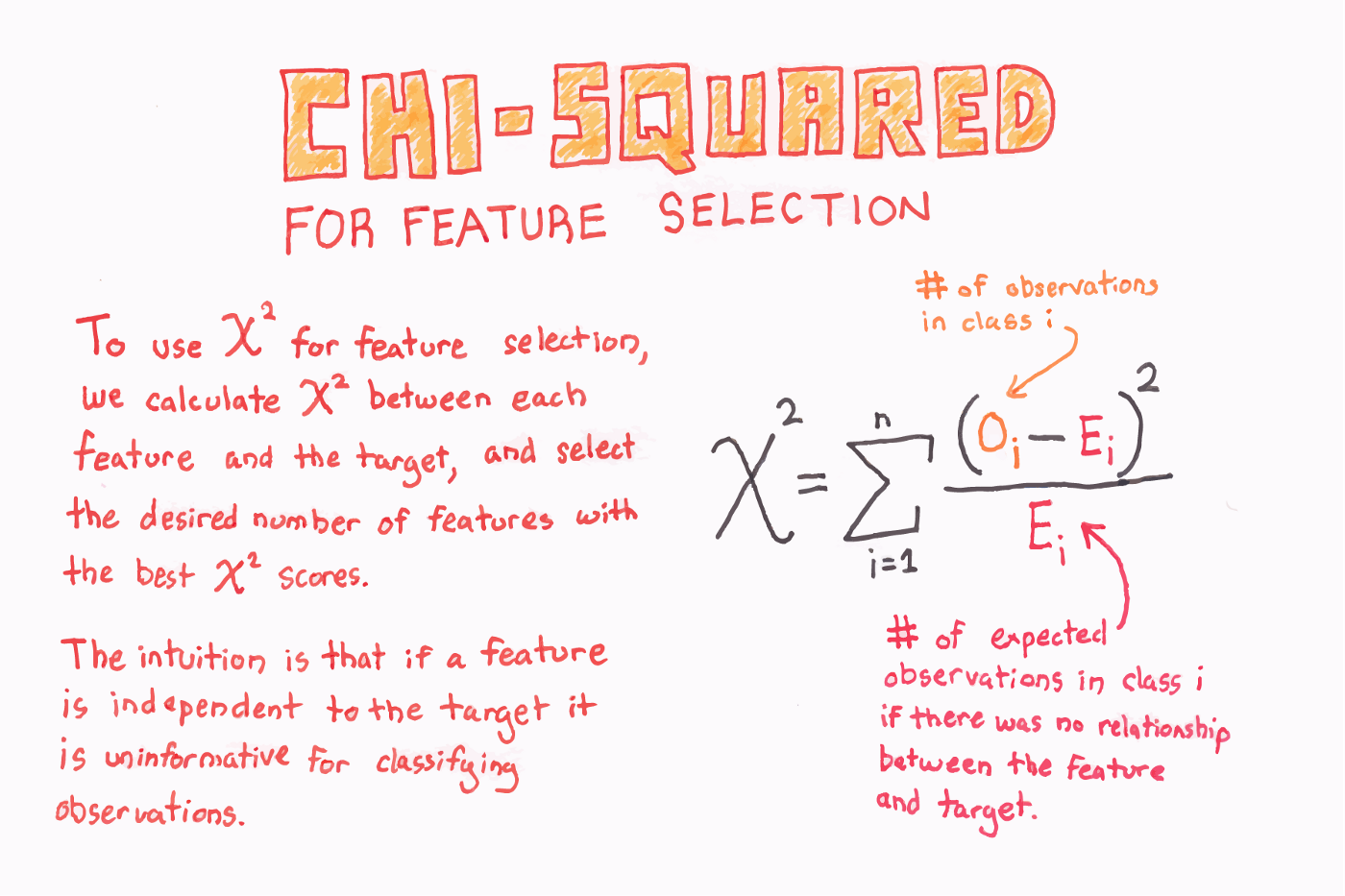
How to conduct feature selection?
highest mutual information:
the one that reduces the uncertainty (entropy) in the label.
multi-collinear features:
fraction of variance unexplained(FVU), build a linear regression model to predict feature K, given features A,B,C and D.
- Pearson Correlation:
we check the absolute value of the Pearson’s correlation between the target and numerical features in our dataset
- chi-square
- RFE, recursive feature elimination
- Lasso, SelectFromModel
- one-hot, ordinalEncoding, LabelEncoder
What’s log loss?
Log-loss is indicative of how close the prediction probability is to the corresponding actual/true value (0 or 1 in case of binary classification). The more the predicted probability diverges from the actual value, the higher is the log-loss value.
To sum up, farther the prediction probability is from the actual value, higher is its log-loss value.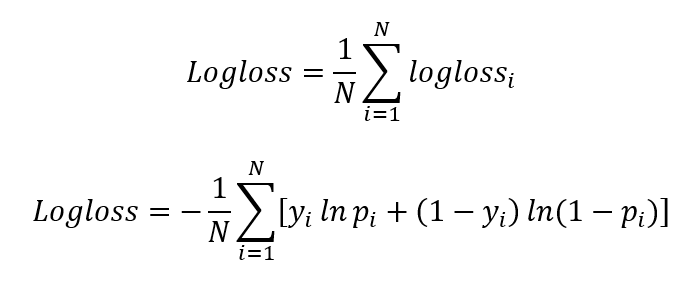
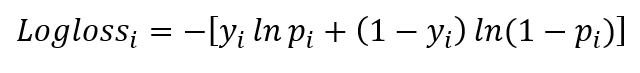
both logloss and MSE indicate how far the predictions are from the actual values.Relative entropy, cross entropy, KL divergence
cross entropy = log loss
average message length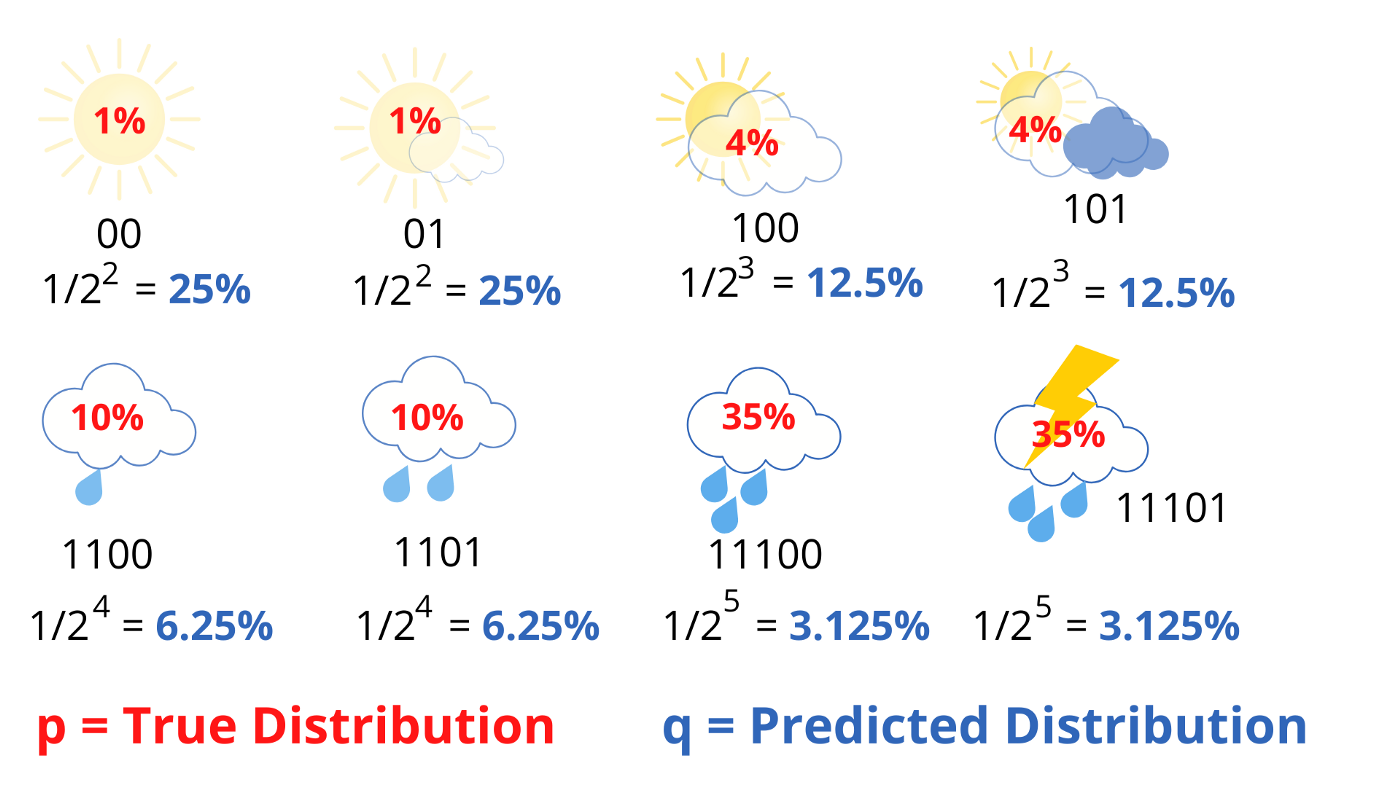
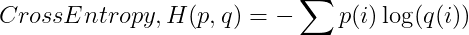
True Probability Distribution p and Predicted Probability Distribution q
If our predictions are perfect, that is the predicted distribution is equal to the true distribution, then the cross-entropy is simply equal to entropy. But, if the distributions differ, then the cross-entropy will be greater than the entropy by some number of bits. This amount by which the cross-entropy exceeds the entropy is called the Relative Entropy or more commonly known as the Kullback-Leibler Divergence (KL Divergence). In short,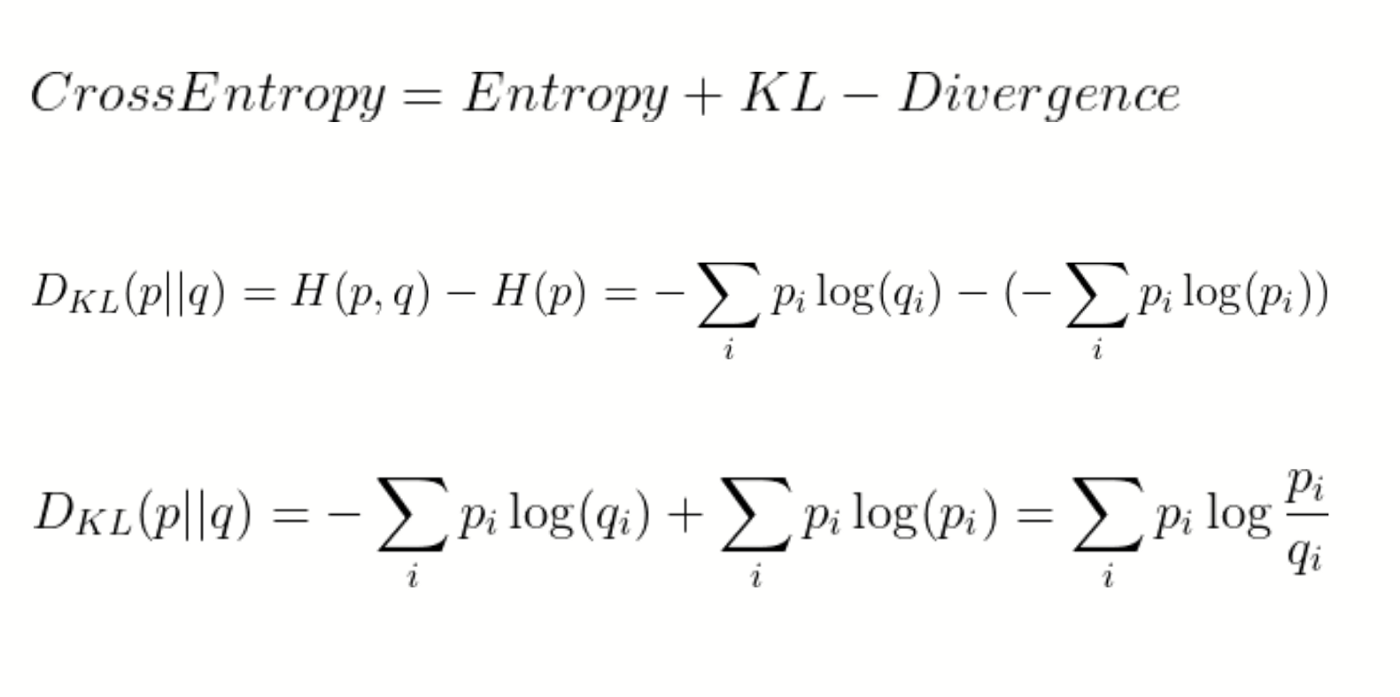
softmax作为做后一层, 用cross entropy算loss
SparseCategoricalCrossentropy and CategoricalCrossentropy both compute categorical cross-entropy. The only difference is in how the targets/labels should be encoded.
forward v.s. backward
forward pass: loss computation
backward propagation: gradient computation
softmax v.s. sigmoid
| Softmax Function | Sigmoid Function |
|---|---|
| Used for multi-classification in logistic regression model. | Used for binary classification in logistic regression model. |
| The probabilities sum will be 1 | The probabilities sum need not be 1. |
| Used in the different layers of neural networks. | Used as activation function while building neural networks. |
| The high value will have the higher probability than other values. | The high value will have the high probability but not the higher probability. |
If you use the softmax function in a machine learning model, you should be careful before interpreting it as a true probability, since it has a tendency to produce values very close to 0 or 1. If a neural network had output scores of [8, 5, 0], like in this example, then the softmax function would have assigned 95% probability to the first class, when in reality there could have been more uncertainty in the neural network’s predictions. This could give the impression that the neural network prediction had a high confidence when that was not the case.

“max” because amplifies probablity of largest xi,
“soft” because still assigns some probability to smaller xi.
DNN为什么要有biasterm,biasterm的intuition是什么
https://stackoverflow.com/questions/2480650/what-is-the-role-of-the-bias-in-neural-networks
a bias value allows you to shift the activation function to the left or right
That’s useful, but what if you wanted the network to output 0 when x is 2? Just changing the steepness of the sigmoid won’t really work — you want to be able to shift the entire curve to the right
wx, w只能scale改变x, 不能移动

若有收获,就点个赞吧
0 人点赞
