神经网络训练不起来怎么办?
Batch
epoch: see all the batchs once
shuffle, shuffle after one epoch, then next epoch’s batchs will be differenti with previous one.

batch size 太小的时候, 一个epoch需要的时间会更久
小的batch size在testing data上表现更好.
如上图loss函数的曲线, testing和training的distribution有差异, 如果找到的是sharp minima, 那么这个差异是很大的; 如果找到的是flat minimal, 这个差异就比较小. 而small batch容易收敛在flat minima, large batch容易收敛在sharp minima, 因为small batch更新gradient比较频繁, 很容易跳出sharp minima.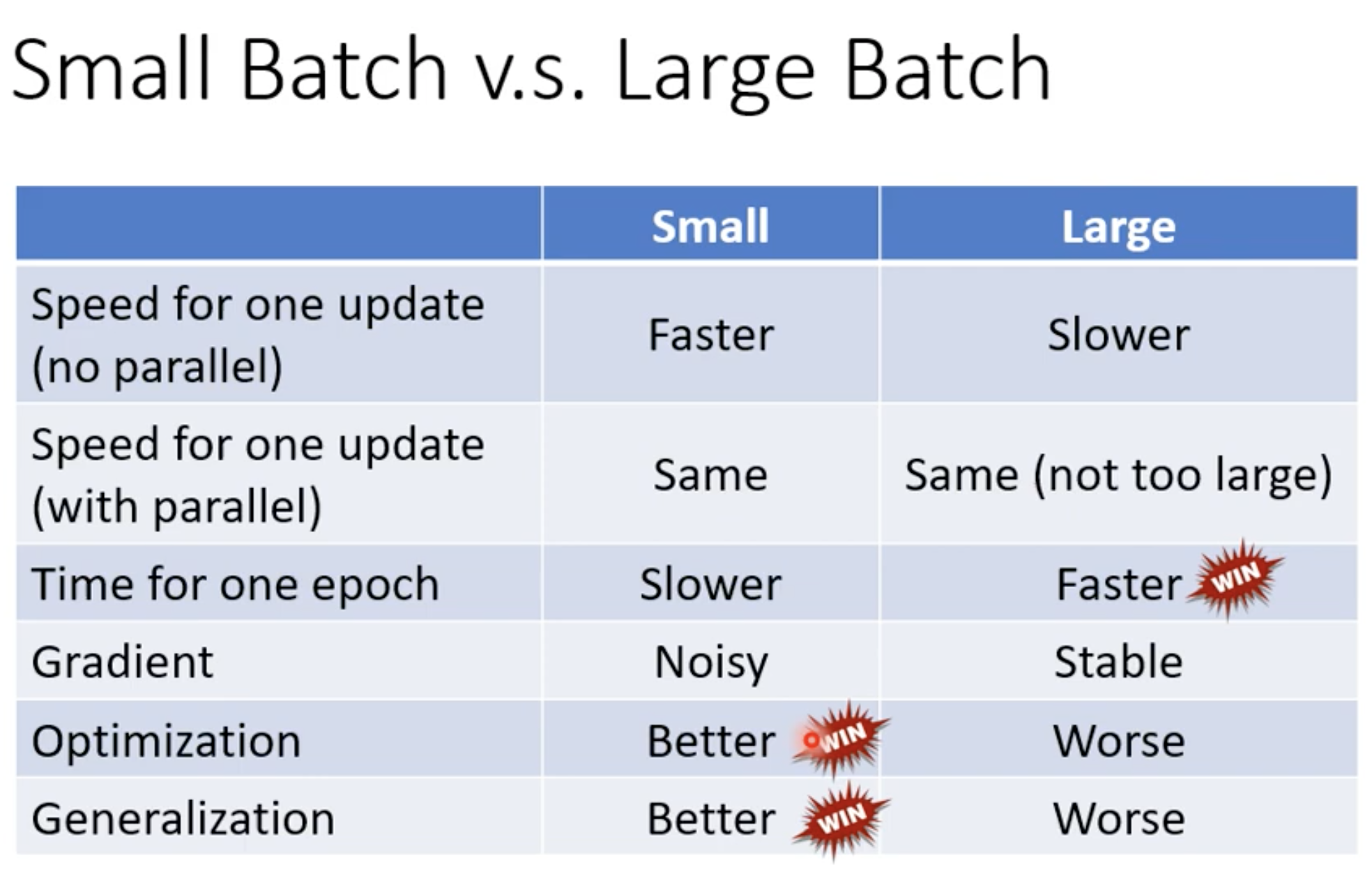
Momentum
escape saddle point or local minima
Movement: movement of last step minus gradient at present.
movement not just based on gradient but also previous movement.
Concluding remarks
- critical points have zero gradient
- critical points can be either saddle point or local minima
- can be determined by Hessian matrix
- escape saddle point by the direction of the eigenvector of the Hessian matrix
- local minima may be rare
- smaller batch size and momentum help to escape critical points
Learning Rate
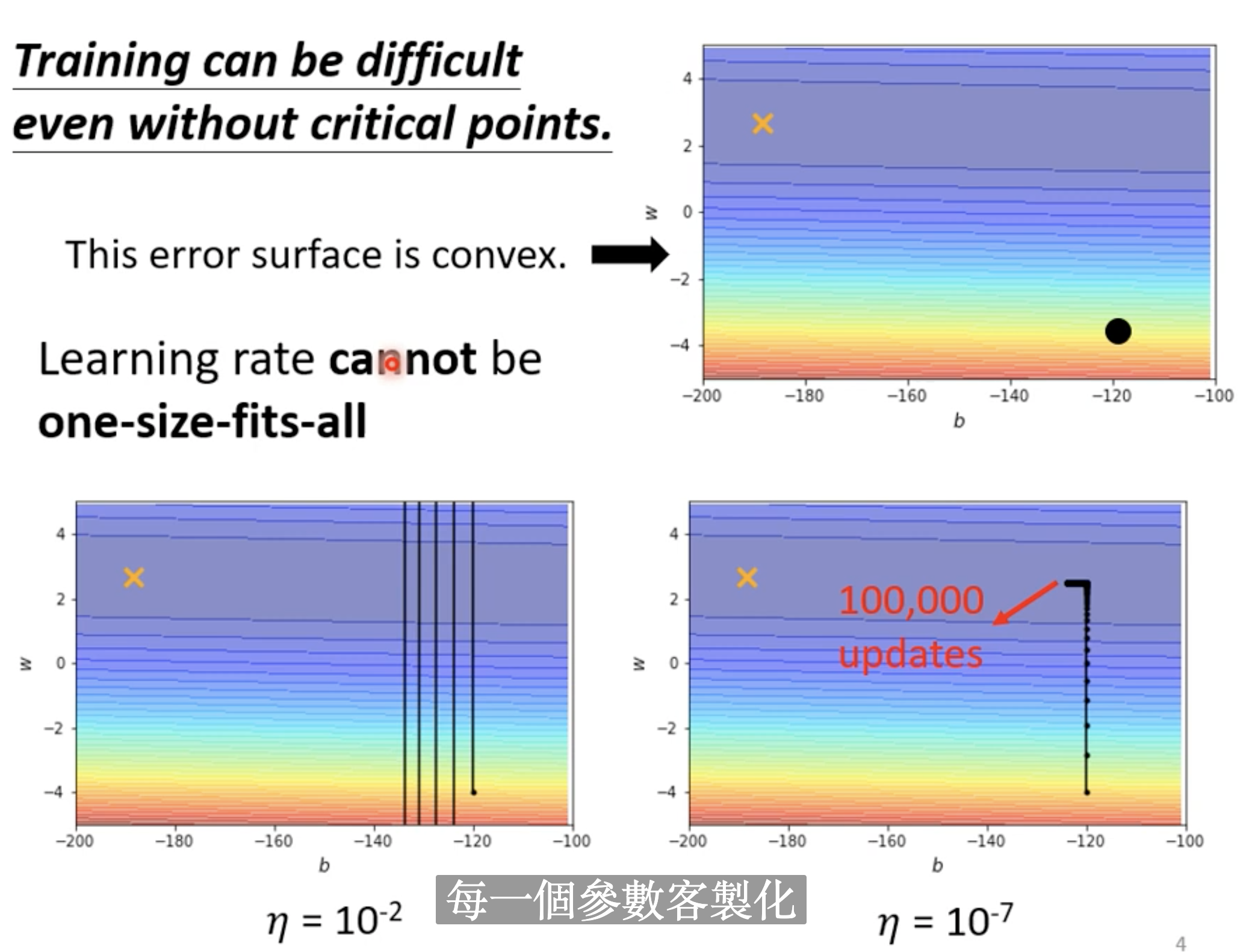
这个error surface里, b的方向很陡峭, w的方向很平滑, 一开始learning rate大的时候, 会bounce, 用小的learning rate可以慢慢降下去, 但是之后因为gradient太小了, 又无法收敛, 此时又需要增加learning rate.
所以learning rate是需要adapted.
General principle:
平滑的方向, aka gradient比较小的方向, 需要大的learning rate.
陡峭的方向, aka gradient比较大的方向, 需要小的learning rate.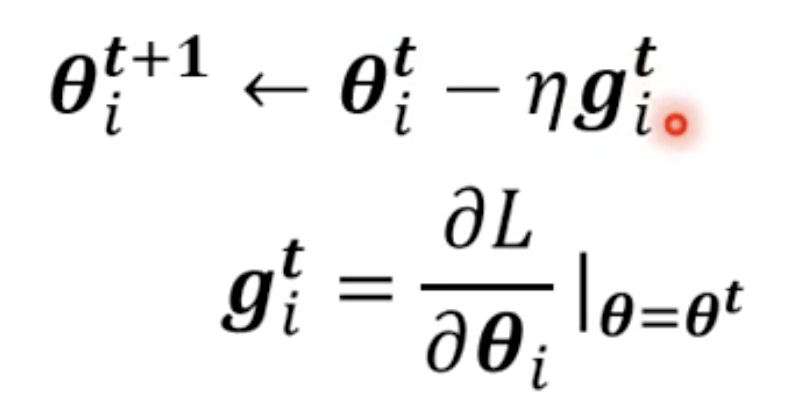

第一次的时候没有区别, 就是正的获得负的η, 之后每次更新参数的时候, 都和之前所有的gradient的值有关系.
这个方法就是Adagrad.
为什么这个方法可以做到之前提到的general principle?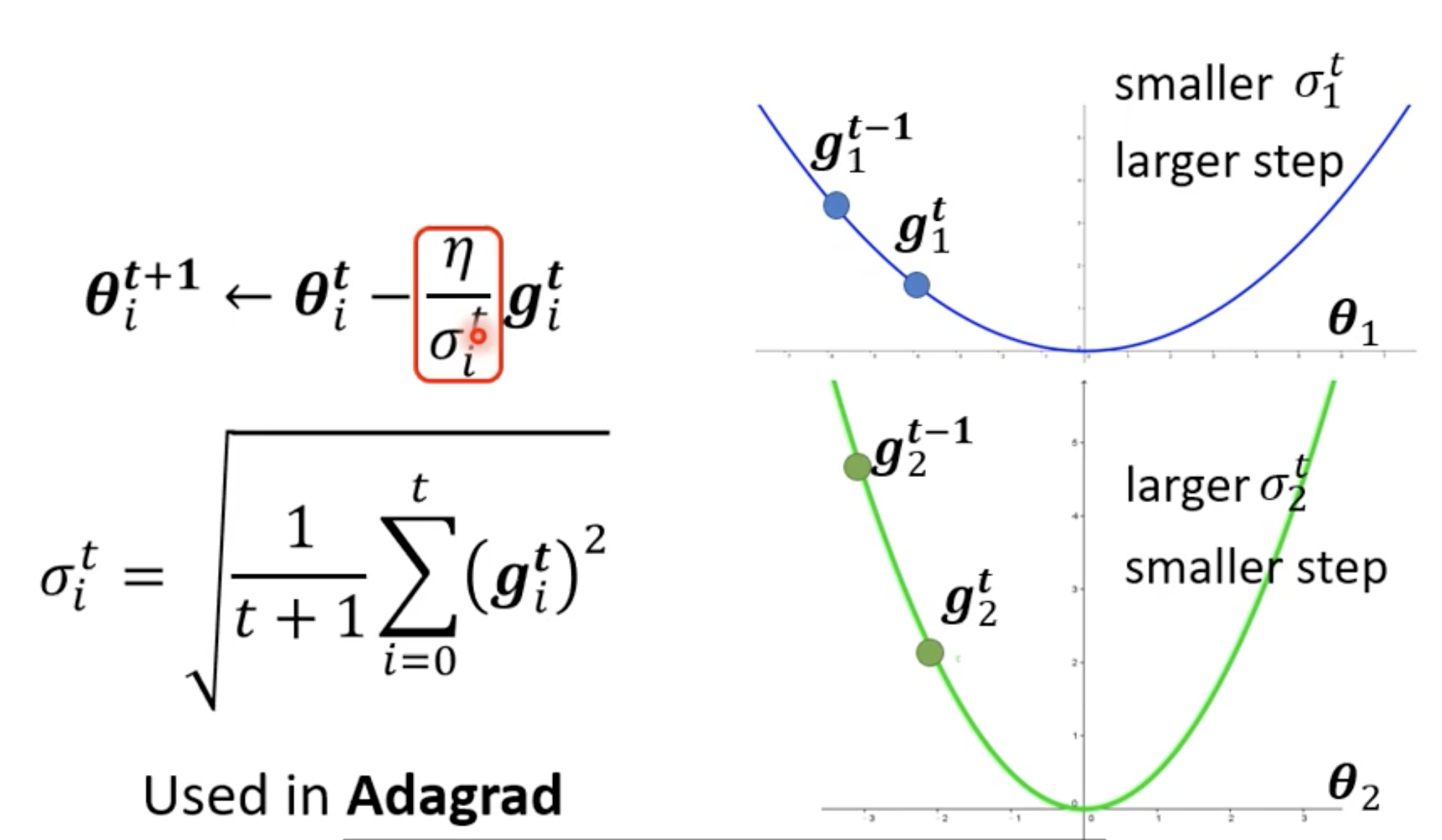
继续进阶 — >RMSProp (Root Mean Square, proportion)
因为即便是同一个参数的gradient, 在不同的位置也是在变化的, 所以对于不同位置的gradient, 要有不同的权重. 这就是proportion.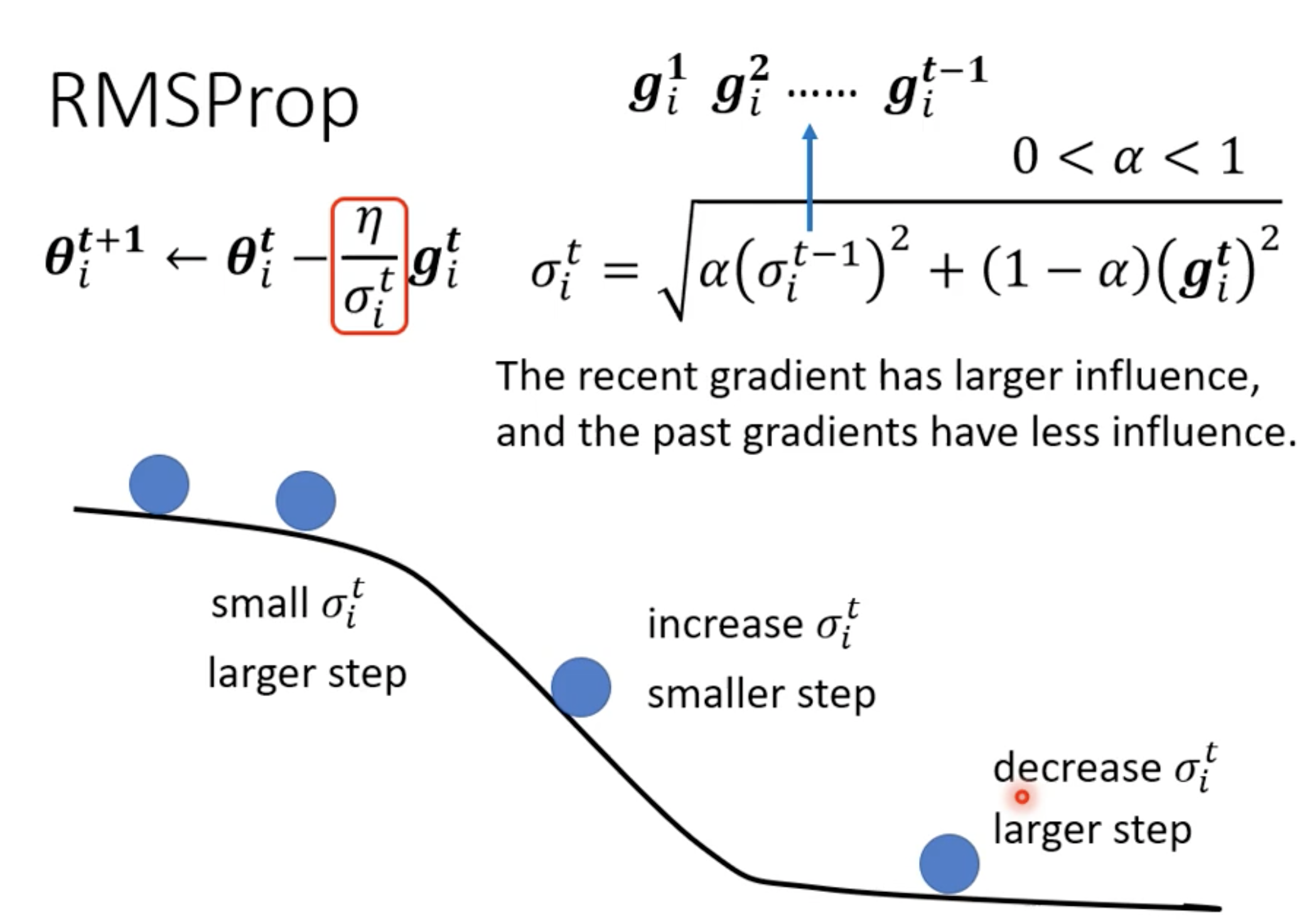
最常用的Adam = RMSProp + Momentum
一般来说直接用pytorch里adam预设好的参数.
一般用learning rate decay , 在训练BERT的时候会用到warm up
需要先让σ收集一些error surface的信息, 降低variance. 所以learning rate从很小的值逐渐上升是个warm up的过程
- momentum是加在gradient上, 改变的是步伐的方向.
- RMS在learning rate的分母上,改变的是步伐的大小.
- learning rate scheduling, 抵消σ的累积

若有收获,就点个赞吧
0 人点赞
