决策树最核心的一步是选择最优划分属性, general来说, 最优的标准应该符合:
我们希望每次选择的属性可以让划分后的分支数据更有区分性,使各个分支的数据分类纯度更高,最好是每个分支的样本数据尽可能属于同一类别。
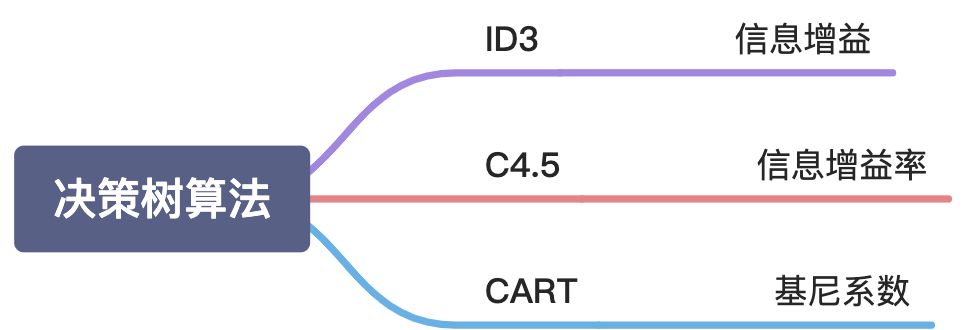 属性划分的标准是让每个分支纯度更高,最好是每个分支的数据尽可能属于同一类别,其实就是尽可能增加分类的确定性。而熵表示了事件的不确定性,消除熵可以增加事件的确定性,所以只需计算划分前后熵的变化就可以了。
属性划分的标准是让每个分支纯度更高,最好是每个分支的数据尽可能属于同一类别,其实就是尽可能增加分类的确定性。而熵表示了事件的不确定性,消除熵可以增加事件的确定性,所以只需计算划分前后熵的变化就可以了。
- 划分之前计算事件的熵:Ent(X)
- 按照属性 A 划分后再次计算事件的熵:Ent(X|A)
- 则 Ent(X) - Ent(X|A) 就是划分之后熵被消除了多少。

若有收获,就点个赞吧
0 人点赞
