LRU缓存淘汰算法
缓存是一种提高数据读取性能的技术,应用广泛。
当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?
常见的策略:
- 先进先出策略FIFO
- 最少使用策略LFU
- 最近最少使用策略LRU
如何用链表来实现LRU缓存淘汰策略呢?
链表
单链表、双向链表和循环链表
链表
单链表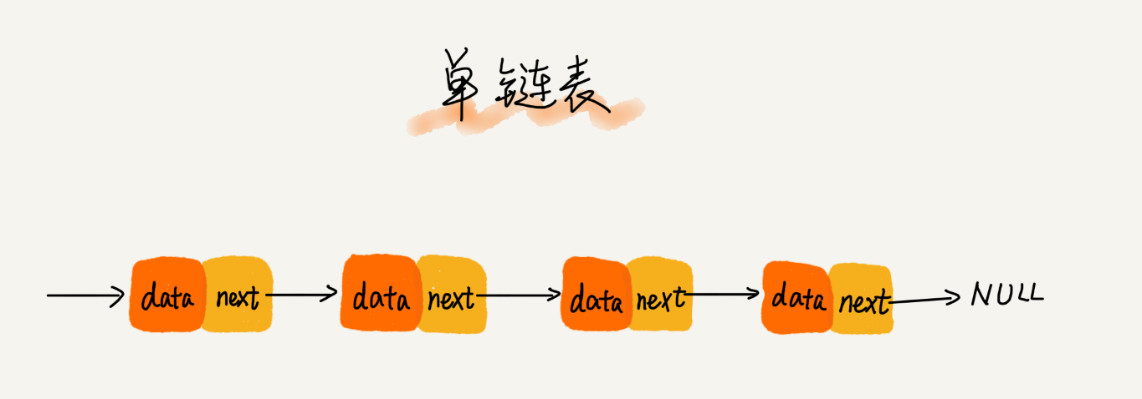
链表也支持数据的查找、插入和删除操作,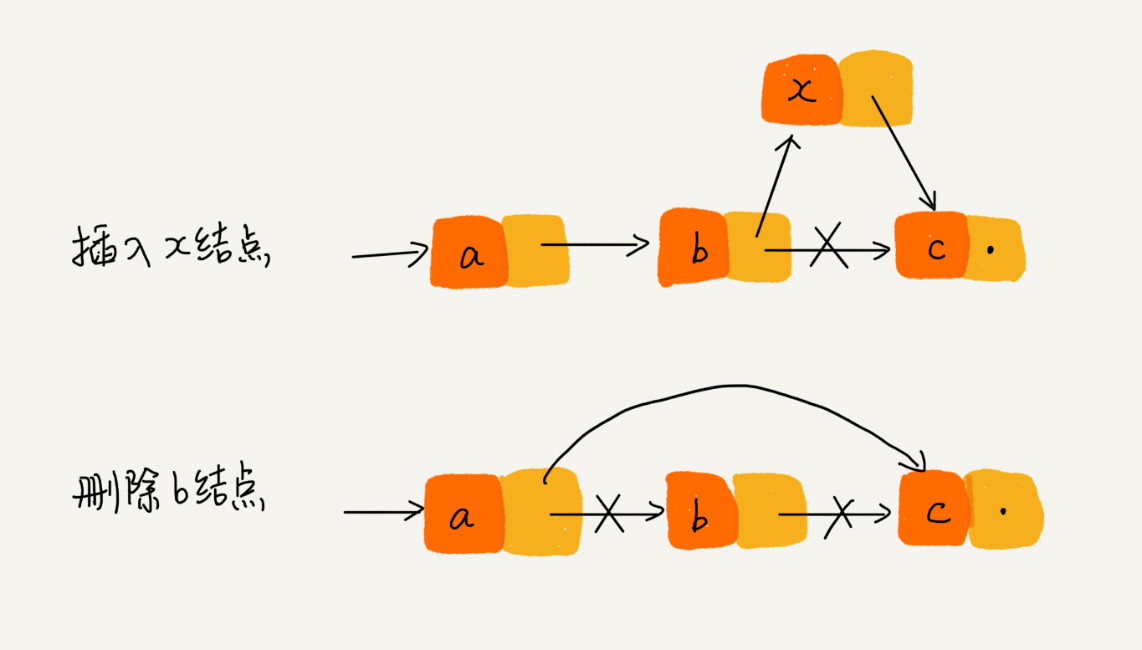
链表插入和删除操作对应的时间复杂度是O(1)
查找需要一个一个地往下数,需要的时间复杂度是O(n)
循环链表和双向链表
循环链表是一种特殊的单链表。循环链表的尾结点指针是指向链表的头结点。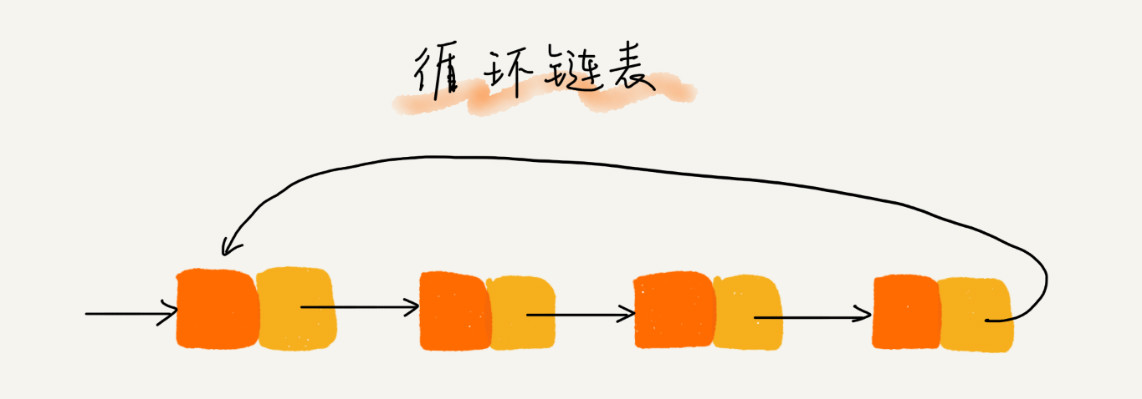
双向链表:
单向链表只有一个方向,结点只有一个后继指针next指向后面的结点。而双向链表,支持两个方向,每个结点不止有一个后继指针next指向后面的结点,还有一个前驱指针prev指向前面的结点。
双向链表比单链表占用更多的内存空间。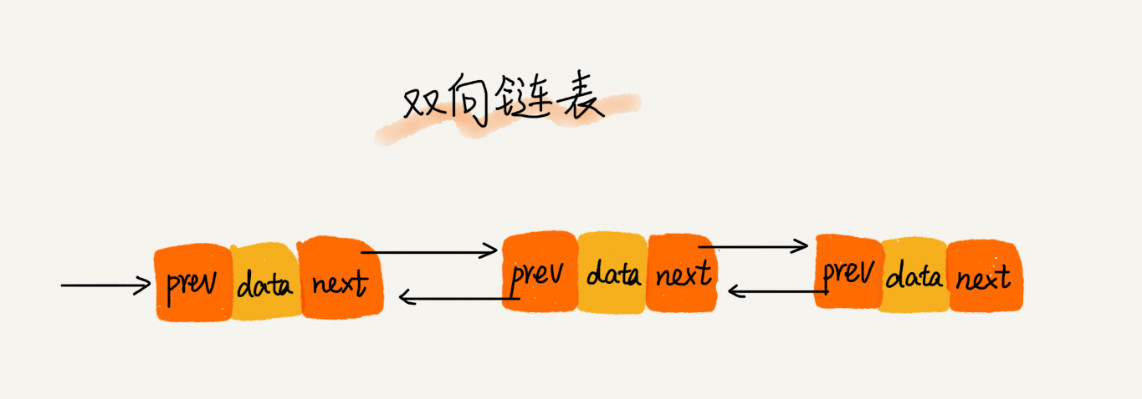
链表的删除:
- 删除结点中”值等于某个给定值“的结点;
- 删除给定指针指向的结点。
空间换时间
对于执行慢的程序,可以通过消耗更多的内存(空间换时间)来进行优化;而消耗过多内存的程序,可以通过消耗更多的时间(时间换空间)来降低内存的消耗。

链表VS数组性能对比
链表和数组对比,它们的插入、删除、随机访问操作的时间复杂度正好相反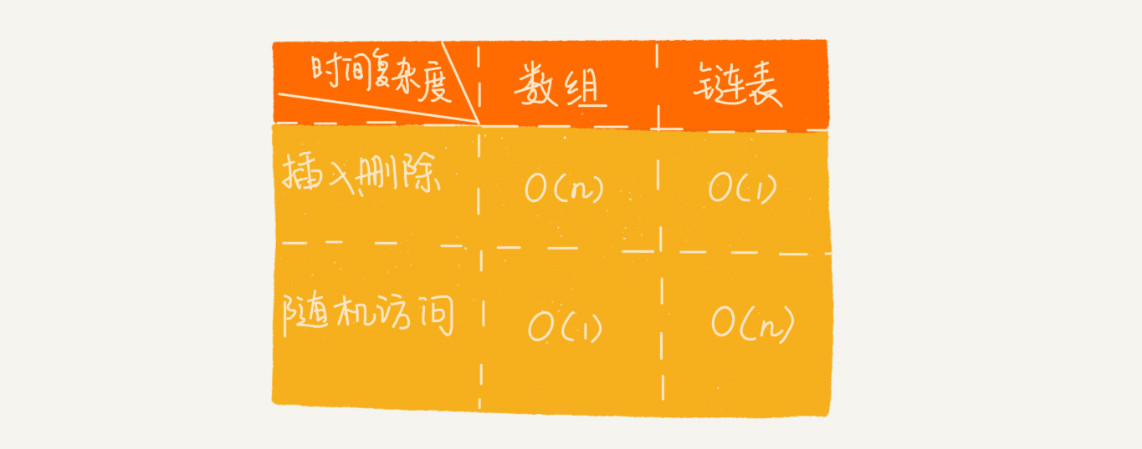
数组
优点:简单易用,连续的内存空间,可以借助CPU的缓存机制,预读数组中的数据,访问效率更高。
缺点:大小固定,一经声明就要占用整块连续内存空间。声明的数组过大,可能造成内存不足,声明过小,可能出现不够用的情况。只能申请一个更大的内存空间,把原数组拷贝进去,非常费时。
链表
在内存中并不是连续的存储,对CPU不太友好,没办法有效预读
没有空间限制,动态扩容。
更适合插入、删除操作频繁的场景。
如何实现LRU缓存淘汰算法?
思考
判断一个字符串是否是回文字符串
function huiwen (str) {return str === str.split('').reverse().join('')}
如何轻松写出正确的链表代码
理解指针或引用的含义
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向这个变量,通过指针就能找到这个变量
警惕指针丢失和内存泄露
单链表插入操作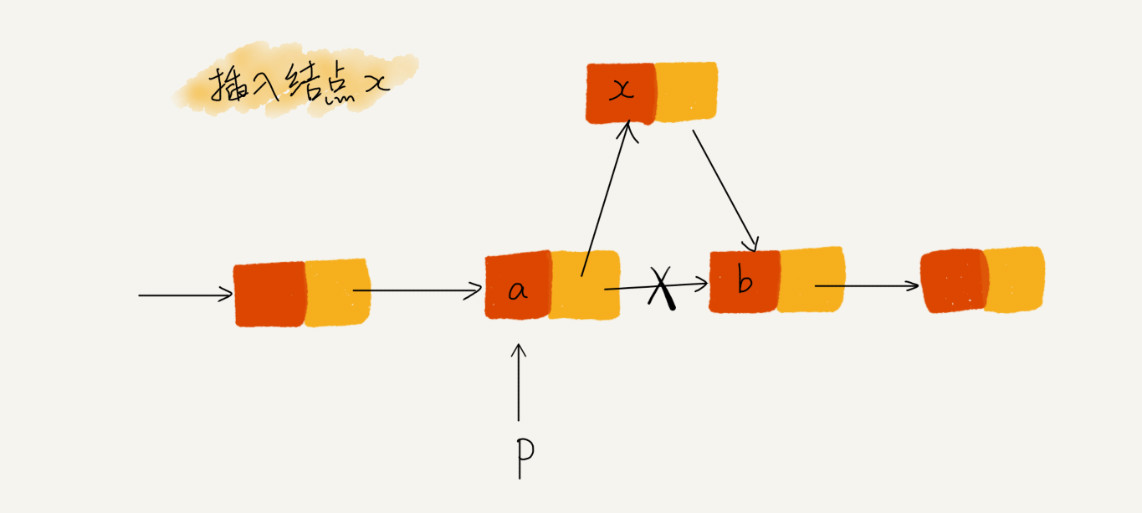
插入结点时,一定要注意操作顺序。删除链表结点时,一定要手动释放内存空间。
利用哨兵简化实现难度
链表插入操作
// 插入操作new_node->next = p->next;p->next = new_node;// 在头结点插入if (head == null) {head = new_node;}
链表结点删除操作
p->next = p->next->next;// 删除链表中的最后一个结点if (head->next == null) {head = null;}
针对链表的插入删除操作,需要对插入第一个结点和删除最后一个结点的情况进行特殊处理。
带头链表
head指针都会一直指向这个哨兵结点。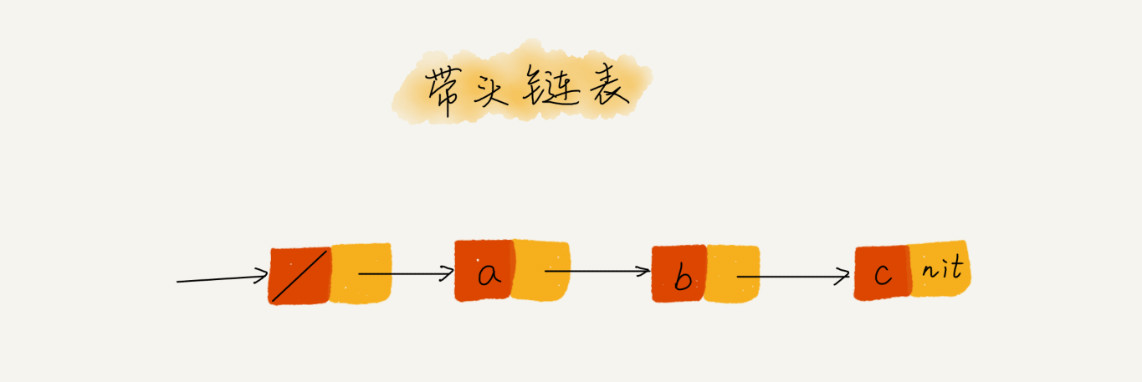
留意边界条件处理
写完代码要注意检查边界条件是否考虑周全
- 如果链表为空,是否能正常工作
- 链表只包含一个结点时,是否能正常工作
- 链表只包含两个结点时,是否正常
-
举例画图,辅助思考
多写多练,没有捷径
熟能生巧,可以多写几遍下面的经典案例
单链表反转
- 链表中环的检测
- 两个有序的链表合并
- 删除链表倒数第n个结点
- 求链表的中间结点
扩展
约瑟夫问题
人们站在一个等待被处决的圈子里。 计数从圆圈中的指定点开始,并沿指定方向围绕圆圈进行。 在跳过指定数量的人之后,执行下一个人。 对剩下的人重复该过程,从下一个人开始,朝同一方向跳过相同数量的人,直到只剩下一个人,并被释放。
想不明白-_-||
# -*- coding: utf-8 -*-class Node(object):def __init__(self, value):self.value = valueself.next = Nonedef create_linkList(n):head = Node(1)pre = headfor i in range(2, n+1):newNode = Node(i)pre.next= newNodepre = newNodepre.next = headreturn headn = 5 #总的个数m = 2 #数的数目if m == 1: #如果是1的话,特殊处理,直接输出print (n)else:head = create_linkList(n)pre = Nonecur = headwhile cur.next != cur: #终止条件是节点的下一个节点指向本身for i in range(m-1):pre = curcur = cur.nextprint (cur.value)pre.next = cur.nextcur.next = Nonecur = pre.nextprint (cur.value)

若有收获,就点个赞吧
0 人点赞
