数组是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
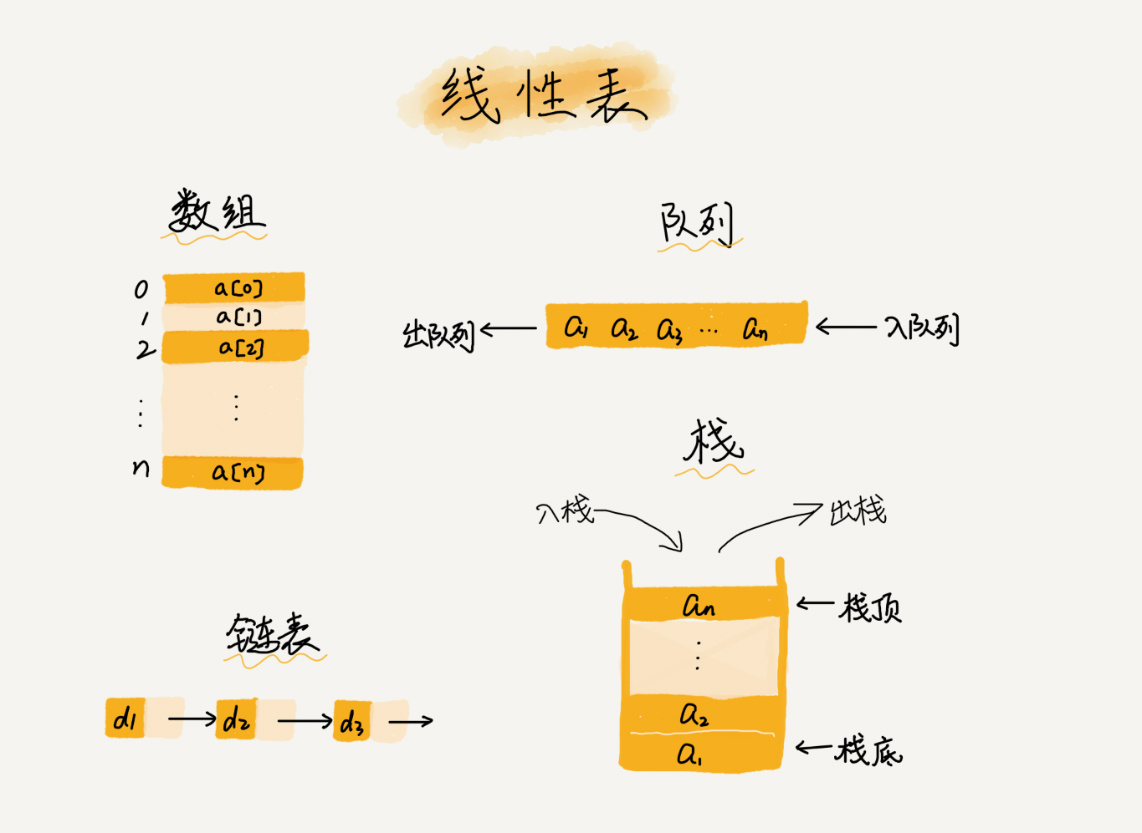
- 数组是线性表
- 数据具有连续的内存空间和相同类型的数据
数组支持随机访问,根据下标随机访问的时间复杂度为O(1)
低效的插入和删除
数组插入到某一位,需要将某一位后面的数据向后移动,最好的时间复杂度为O(1),最坏的时间复杂度是O(n),所以平均时间复杂度是O(n)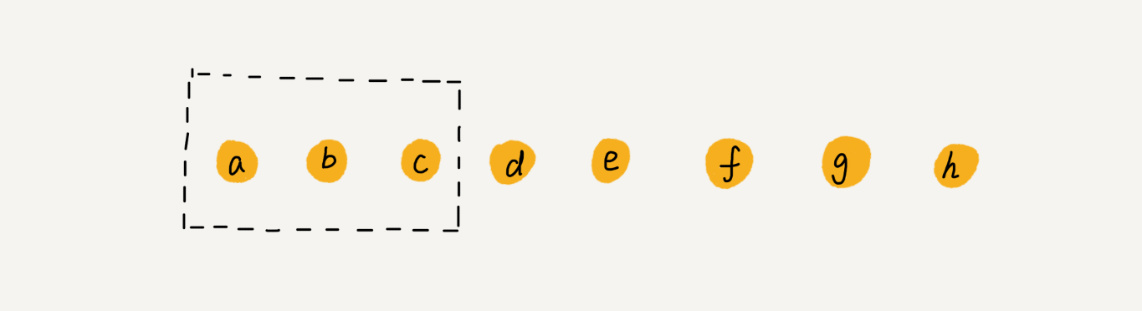
现在要删除a、b、c为避免你数据搬移三次,可以先记录下已经删除的数据。每次删除操作并不是真正的搬移数据,只是记录数据已经被删除。当数组没有更多空间存储数据时,我们再出发执行一次真正的删除操作,这样就大大减少删除操作导致的数据搬移。
警惕数组的访问越界问题
数组编号为什么从0开始
数组下标最确切的定义应该是”偏移offset“。如果用a来表示数组的首地址,a[0]就是偏移为0的位置,也就是首地址,a[k]就表示偏移k个type_size的位置,所以计算a[k]的内存地址只需要用这个公式:
a[k]_address = base_address + k * type_size
但如果从1开始计数,数组元素a[k]的内存地址就会变为:
a[k]_address = base_address + (k-1)*type_size
从1开始编号,每次随机访问数组元素都多了一次减法运算,对于CPU来说,就多了一次减法指令。
数组作为非常基础的数据结构,通过下标随机访问数组元素又是非常基础的编程操作,效率优化就要尽可能做到极致。所以为了减少一次减法操作,数组选择从0开始编号。
还有历史沿用的原因。
总结思考
数组是最基础、最简单的数据结构。支持存储相同类型的一组数据,最大的特别就是支持随机访问,插入、删除操作也变得比较低效
二维数组寻址公式
// 对于 m * n 的数组,a [ i ][ j ] (i < m,j < n)的地址为:address = base_address + ( i * n + j) * type_size

若有收获,就点个赞吧
0 人点赞
