难点:动态规划、递归
去的过程叫“递”,回来的过程叫“归”
递归需要满足三个条件
- 一个问题的解可以分解为几个子问题的解
- 这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样
- 存在递归终止条件
假如这里有n个台阶,每次你可以跨1个台阶或者2个台阶,请问走这n个台阶有多少种走法?
分析:
首先看每一次走有多少种情况,有两种情况,一种是第一次走1个台阶,一种是第一次走2个台阶,从而推到出递推公式
f(n) = f(n-1) + f(n-2)
然后再找出边界条件,当n为1的时候,只有一种走法,当n为2的时候有两种走法,这两种都不满足公式,当n为3的时候满足公式,所以根据求解的代码为
function f (n) {if (n === 1) return 1if (n === 2) return 2return f(n-1) + f(n-2)}
写递归代码的关键是找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。
编写递归代码的关键是,只要遇到递归,我们就把它抽象成一个递推公式,不用想一层层的调用关系,不要试图用人脑去分解递归的每个步骤。
避免思维误区,去思考机器怎么执行。
写递归代码需注意
一、警惕堆栈溢出
限制最大深度,如果超过最大深度就报错。
考虑边界条件,0、1、2这些
递归代码要警惕重复
在递归时会出现重复计算的问题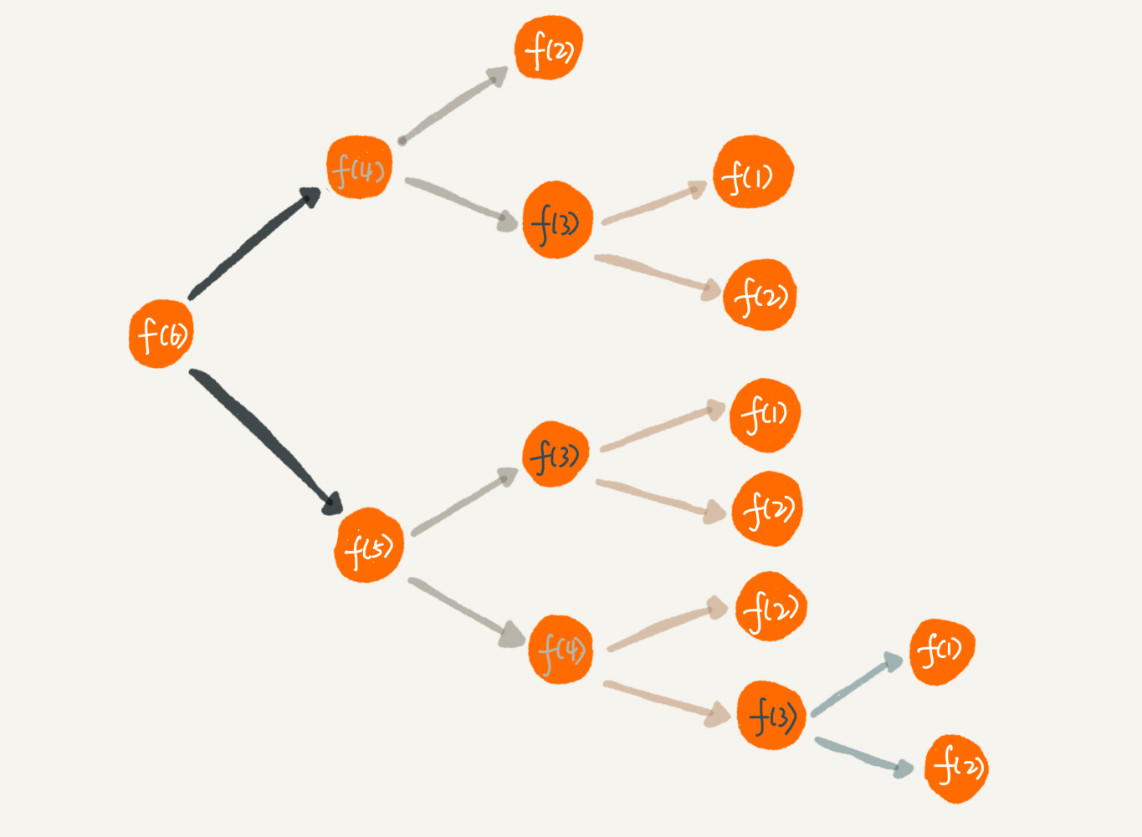
图中想要得到f(5)的值,需要计算f(3)f(4),可f(4)已经计算过了,如果还需要计算一遍无形中就计算了很多次,避免重复的问题,可以用对象字典来进行保存,如果之前计算过这个值就直接从对象中取出。
let jsonKey = {}function f (n) {if (n === 1) return 1if (n === 2) return 2if (jsonKey[n]) {return jsonKey[n]}let ret = f(n-1) + f(n-2)jsonKey[n] = retreturn ret}
递归改写非递归
递归有利有弊,优点是递归代码表达力很强,写起来简洁。弊就是空间复杂度高、有堆栈溢出的风险,存在重复计算、过多的函数调用等问题。
基本上所有递归的写法都可以写成非递归的方式。

若有收获,就点个赞吧
0 人点赞
