独立的SQLAlchemy
Flask-SQLAlchemy
安装和验证
安装
先安装pymsql
然后安装sqlalchemy
pip install pymysqlpip install flask-sqlalchemy
需要提供的参数:
HOSTNAME = "127.0.0.1"PORT = "3306"DATABASE = "xt_flask"USERNAME = "root"PASSWORD = "abcabc"DB_URI = 'mysql+pymysql://{}:{}@{}:{}/{}'.format(USERNAME,PASSWORD,HOSTNAME,PORT,DATABASE)engine = create_engine(DB_URI)with engine.connect() as conn:rs = conn.excute("SELECT 1")rs.fetchone()
参数列表
- hostname 域名,本地域名 127.0.0.1或是localhost
- username 用户名,登录到mysql的用户
- password 密码,mysql用户的密码
- port 端口号,mysql数据库默认3306
- database 数据库名,目标数据库
URI构成
URI由 服务器名,协议名(包名):// 用户名 : 密码 @ 域名 : 端口 / 资源名(数据库名)?charset = utf8
例如:mysql+pymysql://pwd12345:root@localhost:3306/test_db?charset=utf8'
连接参数
https://flask-sqlalchemy.palletsprojects.com/en/2.x/config/#configuration-keysapp.config['SQLALCHEMY_DATABASE_URI'] = DB_URI
SQLAlchemy配置参数
| 参数 | 说明 | 建议 | | —- | —- | —- | | SQLALCHEMY_DATABASE_URI | 应该用于连接的数据库 URI。例子:
- sqlite:////tmp/test.db
- mysql://username:password@server/db
| 务必指明 | | SQLALCHEMY_BINDS | 将绑定键映射到 SQLAlchemy 连接 URI 的字典。有关绑定的更多信息,请参阅具有绑定的多个数据库。 Multiple Databases with Binds. | 无需修改 | | SQLALCHEMY_ECHO | 如果设置为 True,SQLAlchemy 将记录所有发送到 stderr 的语句,这对调试很有用。. | 调试建议开启 | | SQLALCHEMY_RECORD_QUERIES | 可用于显式禁用或启用查询记录。查询记录在调试或测试模式下自动发生。 See get_debug_queries() for more information. | 调试建议开启 | | SQLALCHEMY_NATIVE_UNICODE | 可用于显式禁用本机 unicode 支持。当与指定无编码数据库的不正确的数据库默认值一起使用时,某些数据库适配器(例如某些 Ubuntu 版本上的 PostgreSQL)需要这样做。
Deprecated as of v2.4 and will be removed in v3.0. | 无需修改 | | SQLALCHEMY_POOL_SIZE | 数据库池的大小。默认为引擎的默认值(通常为 5)。
Deprecated as of v2.4 and will be removed in v3.0. | 无需修改 | | SQLALCHEMY_POOL_TIMEOUT | 指定池的连接超时时间(以秒为单位)。
Deprecated as of v2.4 and will be removed in v3.0. | 无需修改 | | SQLALCHEMY_POOL_RECYCLE | 自动回收连接的秒数。这是 MySQL 所必需的,默认情况下,它会在空闲 8 小时后删除连接。请注意,如果使用 MySQL,Flask-SQLAlchemy 会自动将此设置为 2 小时。一些后端可能使用不同的默认超时值。有关超时的更多信息,请参阅 Timeouts.
Deprecated as of v2.4 and will be removed in v3.0. | 无需修改 | | SQLALCHEMY_MAX_OVERFLOW | 控制池达到其最大大小后可以创建的连接数。当这些额外的连接返回到池中时,它们将被断开并丢弃。
Deprecated as of v2.4 and will be removed in v3.0. | 无需修改 | | SQLALCHEMY_TRACK_MODIFICATIONS | 如果设置为 True,Flask-SQLAlchemy 将跟踪对象的修改并发出信号。默认值为 None,它启用跟踪,但发出警告,表示将来默认禁用。这需要额外的内存,如果不需要,应该禁用。 | 建议禁用 | | SQLALCHEMY_ENGINE_OPTIONS | 要发送到的关键字 args 字典create_engine(). See also engine_options to SQLAlchemy. | 无需修改 |
ORM
步骤
1. 继承db.Model
class MyTable(db.Model):
2. 设置表名
__tablename__ = "mytable"
3. 创建字段
- 成员变量名就是字段名 db.Column
- 字段属性通过db继承
- 支持关键字
例如:
class MyTable(db.Model):__tablename__ = "mytable"id = db.Column(db.Integer, primary_key=True, autoincrement=True)class User(db.Model): # 表名将会是 user(自动生成,小写处理)id = db.Column(db.Integer, primary_key=True) # 主键name = db.Column(db.String(20)) # 名字class Movie(db.Model): # 表名将会是 movieid = db.Column(db.Integer, primary_key=True) # 主键title = db.Column(db.String(60)) # 电影标题year = db.Column(db.String(4)) # 电影年份
常用字段:
- db.Integer 整型
- db.String (size) 字符串,size 为最大长度,比如db.String(20)
- db.Text 长文本
- db.DateTime 时间日期,Pythondatetime对象
- db.Float 浮点数
-
4. 创建表
操作
创建
下面的操作演示了如何向数据库中添加记录:
>>> from app import User, Movie # 导入模型类>>> user = User(name='Grey Li') # 创建一个 User 记录>>> m1 = Movie(title='Leon', year='1994') # 创建一个 Movie 记录>>> m2 = Movie(title='Mahjong', year='1996') # 再创建一个 Movie 记录>>> db.session.add(user) # 把新创建的记录添加到数据库会话>>> db.session.add(m1)>>> db.session.add(m2)>>> db.session.commit() # 提交数据库会话,只需要在最后调用一次即可
提示 在实例化模型类的时候,我们并没有传入 id 字段(主键),因为 SQLAlchemy 会自动处理这个字段。
最后一行 db.session.commit() 很重要,只有调用了这一行才会真正把记录提交进数据库,前面的 db.session.add() 调用是将改动添加进数据库会话(一个临时区域)中。读取
通过对模型类的 query 属性调用可选的过滤方法和查询方法,我们就可以获取到对应的单个或多个记录(记录以模型类实例的形式表示)。查询语句的格式如下:
<模型类>.query.<过滤方法(可选)>.<查询方法>
下面是一些常用的过滤方法:
filter() 使用指定的规则过滤记录,返回新产生的查询对象
- filter_by() 使用指定规则过滤记录(以关键字表达式的形式),返回新产生的查询对象
- order_by() 根据指定条件对记录进行排序,返回新产生的查询对象
- group_by() 根据指定条件对记录进行分组,返回新产生的查询对象
下面是一些常用的查询方法:
- all() 返回包含所有查询记录的列表
- first() 返回查询的第一条记录,如果未找到,则返回None
- get(id) 传入主键值作为参数,返回指定主键值的记录,如果未找到,则返回None
- count() 返回查询结果的数量
- first_or_404() 返回查询的第一条记录,如果未找到,则返回404错误响应
- get_or_404(id) 传入主键值作为参数,返回指定主键值的记录,如果未找到,则返回404错误响应
- paginate() 返回一个Pagination对象,可以对记录进行分页处理
下面的操作演示了如何从数据库中读取记录,并进行简单的查询:
>>> from app import Movie # 导入模型类>>> movie = Movie.query.first() # 获取 Movie 模型的第一个记录(返回模型类实例)>>> movie.title # 对返回的模型类实例调用属性即可获取记录的各字段数据'Leon'>>> movie.year'1994'>>> Movie.query.all() # 获取 Movie 模型的所有记录,返回包含多个模型类实例的列表[<Movie 1>, <Movie 2>]>>> Movie.query.count() # 获取 Movie 模型所有记录的数量2>>> Movie.query.get(1) # 获取主键值为 1 的记录<Movie 1>>>> Movie.query.filter_by(title='Mahjong').first() # 获取 title 字段值为 Mahjong 的记录<Movie 2>>>> Movie.query.filter(Movie.title=='Mahjong').first() # 等同于上面的查询,但使用不同的过滤方法<Movie 2>
提示 我们在说 Movie 模型的时候,实际指的是数据库中的 movie 表。表的实际名称是模型类的小写形式(自动生成),如果你想自己指定表名,可以定义 tablename 属性。
对于最基础的 filter() 过滤方法,SQLAlchemy 支持丰富的查询操作符,具体可以访问文档相关页面查看。除此之外,还有更多的查询方法、过滤方法和数据库函数可以使用,具体可以访问文档的 Query API 部分查看。
更新
下面的操作更新了 Movie 模型中主键为 2 的记录:
>>> movie = Movie.query.get(2)>>> movie.title = 'WALL-E' # 直接对实例属性赋予新的值即可>>> movie.year = '2008'>>> db.session.commit() # 注意仍然需要调用这一行来提交改动
删除
下面的操作删除了 Movie 模型中主键为 1 的记录:
>>> movie = Movie.query.get(1)>>> db.session.delete(movie) # 使用 db.session.delete() 方法删除记录,传入模型实例>>> db.session.commit() # 提交改动
表关系
一对多
外键
# 外键的数据类型一定和所引用字段的数据类型一致# db.ForeignKey("表明.字段名")# 外键是属于数据库层面的,不推荐直接在ORM使用db.ForeignKey("table.col")
建议使用relationship:
article = Article(title="123",content="xxx")user = User(username="zhangsan")article.author = userdb.session().add(article)db.session().commit()
由于author和user绑定,因此在增加article时,user也会同步增加。
重置表:
删除所有表然后新建所有表
>>> db.drop_all()>>> db.create_all()
一对一
Migrate映射管理
安装和配置
pip install flask-migrate
from flask_migrate import Migratedb = SQLAlchemy(app)migrate = Migrate(app, db)
迁移
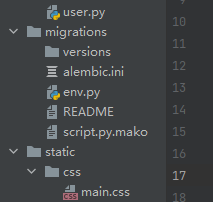
初始化:
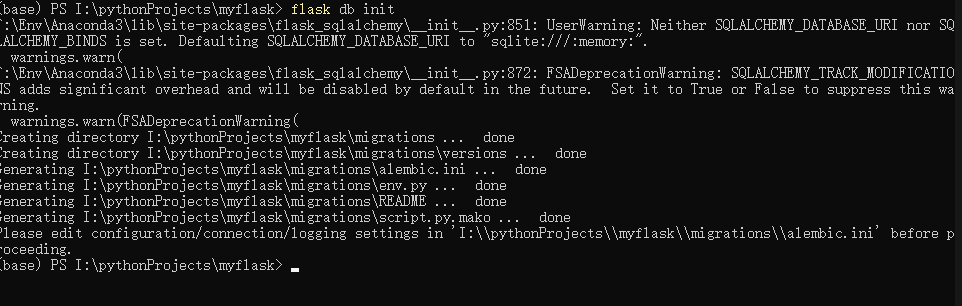
flask db init
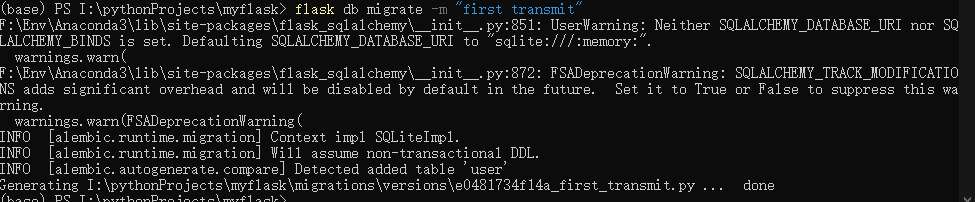
生成脚本
flask db migrate -m "first transmit"
开始映射
flask db upgrade
每次更改模型都可以重新生成脚本然后执行

若有收获,就点个赞吧
0 人点赞
