Flink 和 Spark 的区别
- Flink 是事件驱动,来一个数据则启动计算,Spark 则是时间驱动,每到一个批次时间启动一次计算。Spark Streaming 用微批模拟的流。
- Flink 是标准的流处理模型,一个事件在一个节点处理完后,直接发往下一个节点进行处理。
Flink介绍
Flink 是有状态的计算结构,何为有状态的计算结构,如下图所示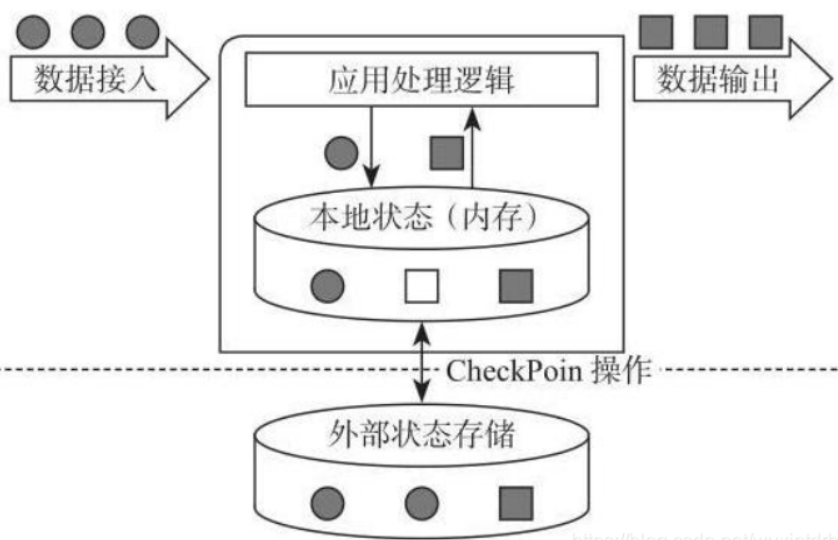
而有状态流计算架构(如图所示)的提出,企业基于实时的流式数据,维护所有计算过程的状态,所谓状态就是计算过程中产生的中间计算结果,每次新的数据进入到流式系统中 都是基于中间状态结果进行运算,最终产生正确的统计结果。
基于有状态计算的方式最大的优势是不需要将原始数据重新从外部存储中拿出来,从而进行全量计算。
Flink运行时组件及其功能
JobManager,任务的分配,调度,管理,接收提交好的 jar 包,生成执行计划图,分成每个执行的 Task。
TaskManager,干活的,对内存尽快隔离。
ResourceManager,管理 slot。
Dispatch,提供Restful接口。
Flink中的TaskManger和Slot
一个 TaskManager 就是一个 JVM 进程,而一个 Slot 则是一个 JVM 进程中的一个线程。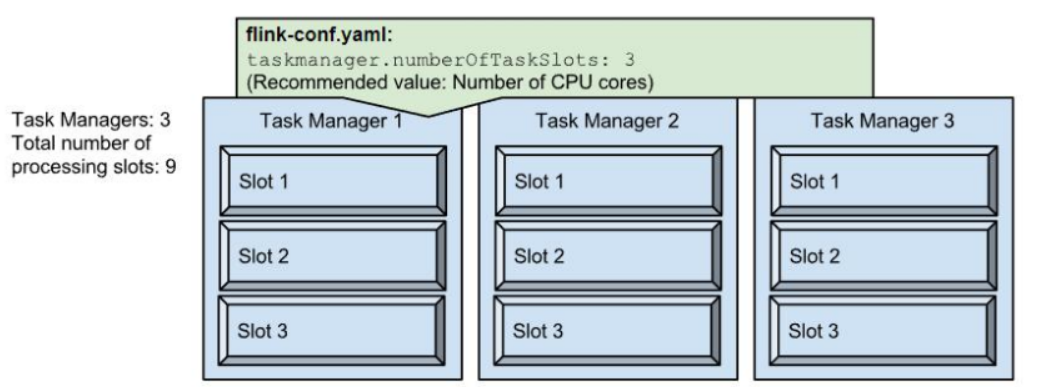
Flink配置文件解读
$FlinkHome/conf/flink-conf.yaml
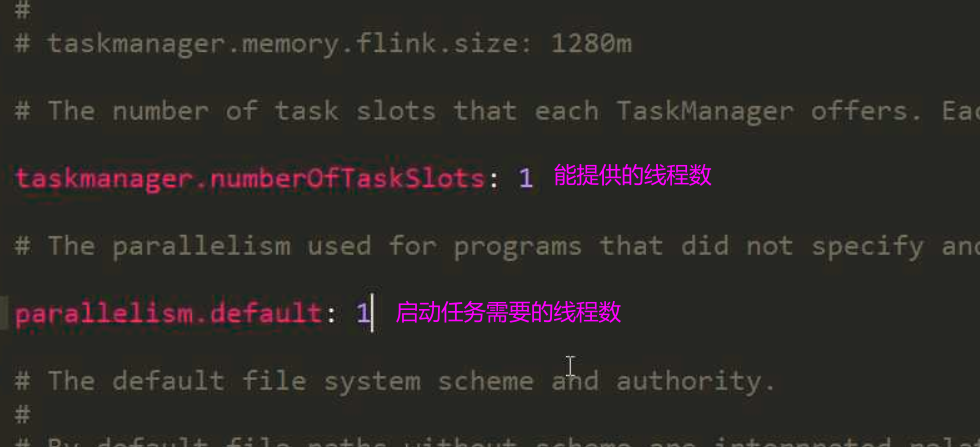
Flink程序编写
新建一个 Maven 项目,pom依赖中加入如下内容
<build><plugins><plugin><!-- 这是个编译java代码的 --><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.5.1</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration><executions><execution><phase>compile</phase><goals><goal>compile</goal></goals></execution></executions></plugin><!-- 该插件用于将Scala代码编译成class文件 --><plugin><!-- 这是个编译scala代码的 --><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.1</version><executions><execution><id>scala-compile-first</id><phase>process-resources</phase><goals><goal>add-source</goal><goal>compile</goal></goals></execution></executions></plugin><!-- maven打包插件 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
如果编写 scala 代码,则继续在 pom 文件中添加 Flink 依赖,
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.1</version>
</dependency>
Flink的Yarn提交流程
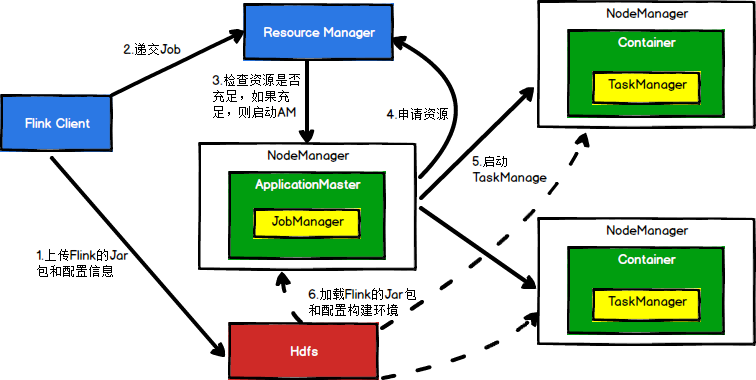
Flink的Yarn-Perjob模式提交命令
先进入 Flink 的根目录,再执行下面的命令
./flink run -m yarn-cluster -c 待执行类的全类名 -yqu yarn的队列名 要执行的jar包包名 程序的控制台参数
一个示例如
./flink run -m yarn-cluster -c com.atguigu.wc.Flink03_WordCount_Unbounded\
FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host hadoop102 --port 7777
Flink任务能合并到一个任务链的条件
- 必须是同一个共享组
- 没有开启新的任务链
- 没有 Hash
- 没有 Rebalance
Flink消费Kafka数据代码Java
需要添加的 pom 依赖为
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.10.1</version>
</dependency>
代码为
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "consumer-group");
DataStreamSource<String> kafkaDS = env.addSource(new FlinkKafkaConsumer011<>(
"topic",
new SimpleStringSchema(), props)
);
kafkaDS.print();
env.execute("Source_Kafka");
Max和MaxBy
max 只会替换比较的那个字段,maxBy 则把比较的那个字段所在的行 所有的字段均替换
- 新建一个 Maven 项目
添加pom依赖
<dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.10.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.12</artifactId> <version>1.10.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.12</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka-0.11_2.12</artifactId> <version>1.10.1</version> </dependency> </dependencies>在根目录下 新建一个目录 sensor,添加一个 sensor.txt 文件,内容如下
sensor_1,1547718199,35.8 sensor_6,1547718201,15.4 sensor_7,1547718202,6.7 sensor_10,1547718205,38.1 sensor_1,1547718201,36 sensor_1,1547718208,36
创建一个 JavaBean 对象 SensorReading,如下图
package com.atguigu.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class SensorReading {
private String id;
private Long ts;
private Double temp;
@Override
public String toString() {
return id + ", " + ts + ", " + temp;
}
}
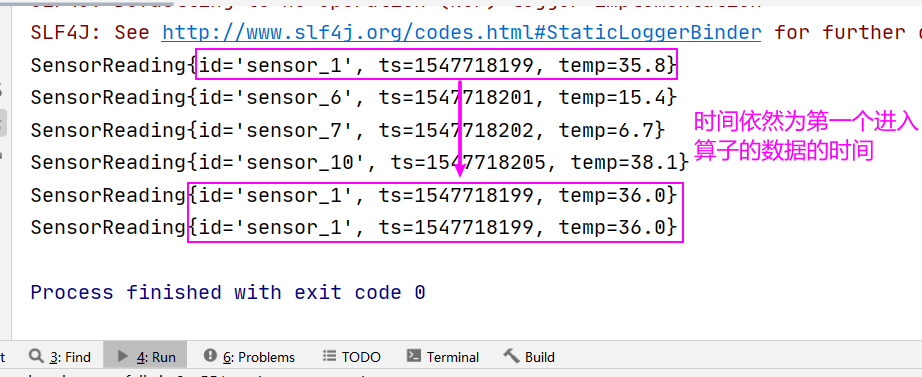
Transform_Max 的代码如下
package com.chiato.day02;
import com.chiato.bean.SensorReading;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Transform_Max {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> lineDS = env.readTextFile("sensor");
SingleOutputStreamOperator<SensorReading> beanDS =
lineDS.map(new MapFunction<String, SensorReading>() {
@Override
public SensorReading map(String line) throws Exception {
String[] fields = line.split(",");
return new SensorReading(
fields[0],
Long.parseLong(fields[1]),
Double.parseDouble(fields[2])
);
}
});
SingleOutputStreamOperator<SensorReading> result = beanDS.keyBy("id").max("temp");
// SingleOutputStreamOperator<SensorReading> result = beanDS.keyBy("id").maxBy("temp");
result.print();
env.execute();
}
}

WaterMark
watermark 是一个特殊的数据,在流中传输,表示时间推进的一种机制。表示小于等于watermark的数据全部到齐。
Watermark是在流中传输的特殊的数据,用于表示事件进展机制,单调递增,表示小于等于Watermark的数据全部到齐,
事件时间语义下,用于触发窗口的计算和关闭。
状态
注意:状态编程只能用于 keyed 操作之后,每个 key 对应一个状态。

若有收获,就点个赞吧
0 人点赞
