注意:所有Flink代码均需要引入的依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.10.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.12</artifactId><version>1.10.1</version></dependency>
对接Kafka Source
需要添加的 pom 依赖为
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.10.1</version>
</dependency>
代码为
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "consumer-group");
DataStreamSource<String> kafkaDS = env.addSource(new FlinkKafkaConsumer011<>(
"topic",
new SimpleStringSchema(), props)
);
kafkaDS.print();
env.execute("Source_Kafka");
对接ElasticSearch Sink
引入pom依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6_2.12</artifactId>
<version>1.10.1</version>
</dependency>
</dependencies>
package com.chiato.day03;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import java.util.ArrayList;
import java.util.HashMap;
public class Flink_ES_Sink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 读取一个目录下的所有文件(目录在项目根目录下),转换为输入流
DataStreamSource<String> inputDS = env.readTextFile("sensor/");
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("hadoop102", 9200));
ElasticsearchSink<String> elasticsearchSink =
new ElasticsearchSink.Builder<String>(httpHosts, new MyESSinkFunc()).build();
inputDS.addSink(elasticsearchSink);
env.execute();
}
public static class MyESSinkFunc implements ElasticsearchSinkFunction<String> {
@Override
public void process(String element, RuntimeContext ctx, RequestIndexer indexer) {
String[] splits = element.split(",");
HashMap<String, String> source = new HashMap<>();
source.put("id", splits[0]);
source.put("ts", splits[1]);
source.put("temp", splits[2]);
IndexRequest indexRequest =
new IndexRequest("sensor").type("_doc").source(source);
indexer.add(indexRequest);
}
}
}
读取的目录及其中的文件内容如下
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
sensor_1,1547718201,36
sensor_1,1547718208,35
 为 ES 所在主机及其端口号。
为 ES 所在主机及其端口号。
对接Redis Sink
引入的 pom 依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
</dependencies>
需要建立的目录及目录下需要建立的文件同https://www.yuque.com/cosmopolitan/yyh3le/gtp0sd#Rh2fh
核心代码如下
package com.chiato.day03;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
/**
* Redis Sink示例程序
*/
public class Flink_Redis_Sink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 读取文本文件所在目录,(自行创建目录和文件即可)
DataStreamSource<String> inputDS = env.readTextFile("sensor/");
FlinkJedisPoolConfig conf =
new FlinkJedisPoolConfig.Builder().setHost("hadoop102").setPort(6379).build();
inputDS.addSink(new RedisSink<>(conf, new MyRedisMapper()));
env.execute();
}
public static class MyRedisMapper implements RedisMapper<String> {
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET, "sensor");
}
@Override
public String getKeyFromData(String data) {
return data.split(",")[0];
}
@Override
public String getValueFromData(String data) {
return data.split(",")[2];
}
}
}

对接Kafka Sink
所需要的依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.10.1</version>
</dependency>
核心代码
package com.chiato.day03;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011;
public class Flink_Kafka_Sink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> inputDS = env.readTextFile("sensor");
DataStreamSink<String> kafkaDS = inputDS.addSink(
new FlinkKafkaProducer011<String>("hadoop102:9092", "test",
new SimpleStringSchema()));
env.execute();
}
}
对接自定义JDBC Sink
引入依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.44</version>
</dependency>
核心代码
package com.chiato.day03;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class Flink_Jdbc {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> inputDS = env.readTextFile("sensor/");
inputDS.addSink(new JdbcSink());
env.execute();
}
public static class JdbcSink extends RichSinkFunction<String> {
Connection conn = null;
PreparedStatement preparedStatement = null;
@Override
public void open(Configuration parameters) throws Exception {
conn = DriverManager.getConnection("jdbc:mysql://hadoop102:3306/test", "root", "123456");
preparedStatement = conn.prepareStatement(
"insert into sensor (id, temp) values (?,?) on duplicate key update temp=?");
}
@Override
public void invoke(String value, Context context) throws Exception {
// 给预编译sql赋值
String[] fields = value.split(",");
preparedStatement.setString(1, fields[0]);
preparedStatement.setDouble(2, Double.parseDouble(fields[2]));
preparedStatement.setDouble(3, Double.parseDouble(fields[2]));
// 执行sql
preparedStatement.execute();
}
@Override
public void close() throws Exception {
preparedStatement.close();
conn.close();
}
}
}
其中的 jdbc:mysql://hadoop102:3306/test 为要连接的数据库及要进入的库
insert into sensor (id, temp) values (?,?) on duplicate key update temp=? 为待执行的sql,sensor 为要操作的表名。
窗口操作
countWindow
代码如下
package com.chiato.day02other;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
public class Count_Window_Group {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> socketDS = env.socketTextStream("hadoop102", 8888);
// 输入的数据形如
// hadoop,1
// flink,2
SingleOutputStreamOperator<Tuple2<String, Integer>> mapDS = socketDS.map(
new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
String[] splits = value.split(",");
return new Tuple2<>(splits[0], Integer.parseInt(splits[1]));
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> keyed = mapDS.keyBy(0);
WindowedStream<Tuple2<String, Integer>, Tuple, GlobalWindow> window = keyed.countWindow(5);
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = window.sum(1);
sum.print();
env.execute();
}
}
countWindow 对于分组数据,必须一个组满足触发条件,则该组数据的计算会被触发,其他组的计算不会被触发。
在 nc 窗口输入如下图所示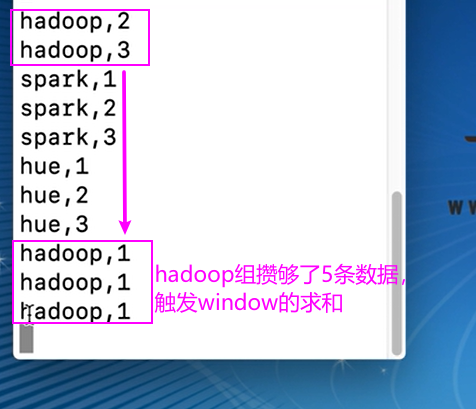
触发了窗口的计算,结果如下图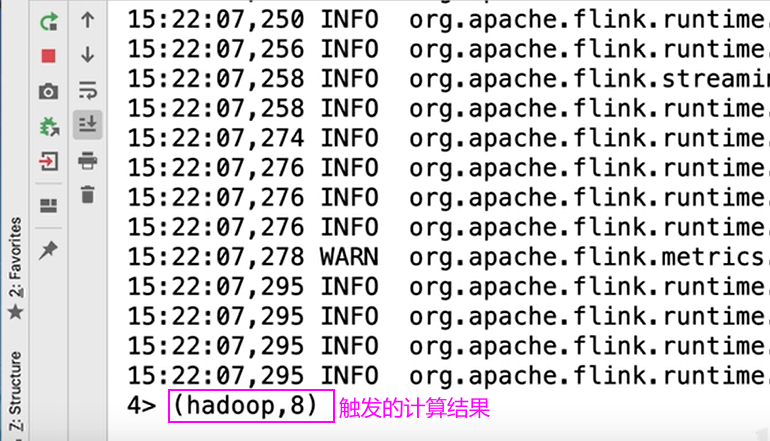
EventTime
如果是并行的 Source,例如 KafkaSource,创建 Kafka 的 Topic 时有多个分区,则每个 Source 对应的分区都满足触发条件时,整个窗口才会被触发,与 Flink 的分组没有关系。
使用 EventTime 作为处理时间的代码如下
package com.chiato.day04;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class Window_EventTime {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// socket端口输入的数据格式如
// hello 1547718199
// flink 1547718200
// ...
// 其中第二位为 秒级时间戳
SingleOutputStreamOperator<String> socketDS =
env.socketTextStream("hadoop102", 8888).
assignTimestampsAndWatermarks(
new AscendingTimestampExtractor<String>() {
// 获取EventTime中的时间戳
@Override
public long extractAscendingTimestamp(String line) {
String[] fields = line.split(" ");
return Long.parseLong(fields[1]) * 1000L;
}
}
);
SingleOutputStreamOperator<Tuple2<String, Integer>> word2OneDS =
socketDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
String[] splits = value.split(" ");
return Tuple2.of(splits[0], 1);
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> keyed = word2OneDS.keyBy(0);
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> windowDS =
keyed.timeWindow(Time.seconds(5));
SingleOutputStreamOperator<Tuple2<String, Integer>> sumDS = windowDS.sum(1);
sumDS.print();
env.execute();
}
}

使用窗口函数
窗口聚合函数AggregateFunction
AggregateFunction是来一个 event,触发窗口内的一次运算。
下面的需求是求每个班的英语平均分
导入依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.10.1</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- Apache Flink dependencies -->
<!-- These dependencies are provided, because they should not be packaged into the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
</dependencies>
核心代码:
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TestAggFunctionOnWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple3<String, String, Long>> input = env.fromElements(ENGLISH_TRANSCRIPT);
//求各班级英语平均分
DataStream<Double> avgScore = input.
keyBy(0).
countWindow(2).
aggregate(new AverageAggregate());
avgScore.print();
env.execute();
}
/**
* 英语成绩
*/
public static final Tuple3[] ENGLISH_TRANSCRIPT = new Tuple3[]{
Tuple3.of("class1", "张三", 100L),
Tuple3.of("class1", "李四", 78L),
Tuple3.of("class1", "王五", 99L),
Tuple3.of("class2", "赵六", 81L),
Tuple3.of("class2", "钱七", 59L),
Tuple3.of("class2", "马二", 97L)
};
/**
* 求第二个字段的平均值(sum/count)
* 累加器为一个2元组tuple,元组第一个值为分数总和,第二个值为所有参与求和的总个数,
* 最终用元组第一个元素除以第二个元素得到平均值
*/
private static class AverageAggregate
implements AggregateFunction<Tuple3<String, String, Long>, Tuple2<Long, Long>, Double> {
/**
* 创建累加器来保存中间状态(sum和count)
*/
@Override
public Tuple2<Long, Long> createAccumulator() {
return new Tuple2<>(0L, 0L);
}
/**
* 将元素添加到累加器并返回新的累加器value
*/
@Override
public Tuple2<Long, Long> add(Tuple3<String, String, Long> value, Tuple2<Long, Long> accumulator) {
//来一个元素计算一下sum和count并保存中间结果到累加器
return new Tuple2<>(accumulator.f0 + value.f2, accumulator.f1 + 1L);
}
/**
* 从累加器提取结果
*/
@Override
public Double getResult(Tuple2<Long, Long> accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
/**
* Session Window中两个窗口需要合并时,需要将各个窗口的累加器合并为一个大累加器
*/
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> a, Tuple2<Long, Long> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
}
使用ProcessWindowFunction
ProcessWindowFunction获得
一个迭代器,该迭代器包含进入窗口中的所有元素;
一个上下文对象,该对象可以访问时间和状态信息。
缺点:不能对窗口的元素做增量聚合,需要缓冲在内部,直到认为窗口可以处理为止。
需求:求每个班的英语平均分
这里面我们简单起见及调试方便,使用Count Window
导入依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.10.1</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- Apache Flink dependencies -->
<!-- These dependencies are provided, because they should not be packaged into the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
</dependencies>
核心代码:
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
import org.apache.flink.util.Collector;
public class TestProcessWinFunOnWindow {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple3<String,String,Long>> input=env.fromElements(ENGLISH_TRANSCRIPT);
//求各班级英语平均分
DataStream<Double> avgScore=input.keyBy(0).countWindow(2).process(new MyProcessWindowFunction());
avgScore.print();
env.execute();
}
/**
* 英语成绩
*/
public static final Tuple3[] ENGLISH_TRANSCRIPT = new Tuple3[] {
Tuple3.of("class1","张三",100L),
Tuple3.of("class1","李四",78L),
Tuple3.of("class1","王五",99L),
Tuple3.of("class2","赵六",81L),
Tuple3.of("class2","钱七",59L),
Tuple3.of("class2","马二",97L)
};
// 如果是使用的time window,则ProcessWindowFunction泛型最后的window需要将GlobalWindow改为TimeWindow
public static class MyProcessWindowFunction
extends ProcessWindowFunction<Tuple3<String,String,Long>, Double, Tuple, GlobalWindow> {
/**
*
* @param tuple 窗口的key
* @param context 上下文对象,可以访问时间和状态信息
* @param elements 窗口中累积多个元素
* @param out 写出输出结果
*/
@Override
public void process(Tuple tuple, Context context, Iterable<Tuple3<String, String, Long>> elements, Collector<Double> out) throws Exception {
long sum = 0;
int count = 0;
for (Tuple3<String, String, Long> element : elements) {
sum += element.f2;
count ++;
}
out.collect((double)sum / count);
}
}
}
窗口聚合函数和ProcessWindowFunction联合使用
窗口聚合函数如AggregateFunction,只是把结果增量聚合起来,但是并没有往下游发送,而窗口要关闭时,则利用ProcessWindowFunction可以把 窗口聚合函数的结果取到,发送到下游去。
Trigger(触发器)
触发窗口中计算逻辑的执行,并将计算结果发往下游。
每个 Window Assigner(即滑动窗口,滚动窗口等) 有一个默认的 Trigger,一般就够用了。
使用allowedLateness
package com.chiato.day04;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.OutputTag;
public class Window_EventTime_Late {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// socket端口输入的数据格式如
// hello 1547718199
// flink 1547718200
// ...
// 其中第二位为 秒级时间戳
SingleOutputStreamOperator<String> socketDS =
env.socketTextStream("hadoop102", 8888).
assignTimestampsAndWatermarks(
new AscendingTimestampExtractor<String>() {
// 获取EventTime中的时间戳
@Override
public long extractAscendingTimestamp(String line) {
String[] fields = line.split(" ");
return Long.parseLong(fields[1]) * 1000L;
}
}
);
SingleOutputStreamOperator<Tuple2<String, Integer>> word2OneDS =
socketDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
String[] splits = value.split(" ");
return Tuple2.of(splits[0], 1);
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> keyed = word2OneDS.keyBy(0);
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> windowDS =
keyed.timeWindow(Time.seconds(5))
.allowedLateness(Time.seconds(2))
.sideOutputLateData(new OutputTag<Tuple2<String, Integer>>("sideOutput"){});
SingleOutputStreamOperator<Tuple2<String, Integer>> sumDS = windowDS.sum(1);
sumDS.print();
// 获取并打印侧输出流
DataStream<Tuple2<String, Integer>> sideOutput =
sumDS.getSideOutput(new OutputTag<Tuple2<String, Integer>>("sideOutput") {});
sideOutput.print();
env.execute();
}
}
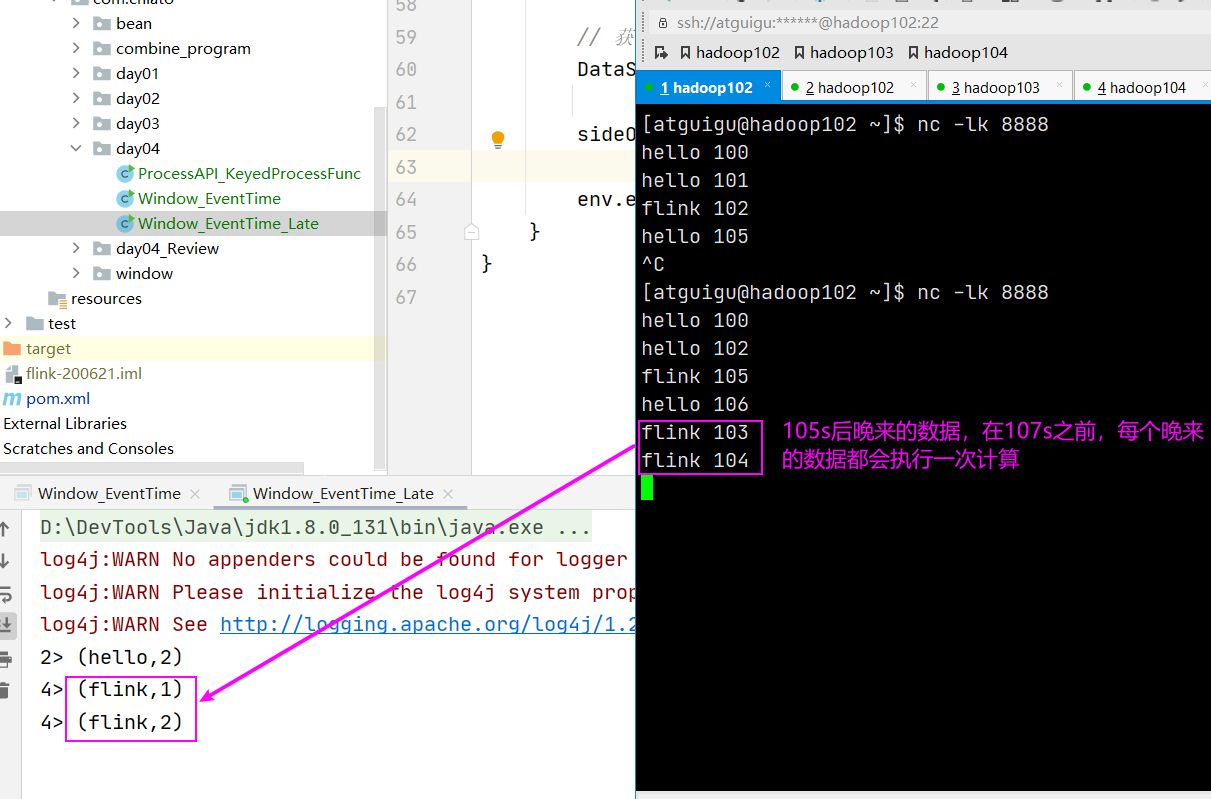
watermark+allowedLateness
窗口大小是 5s,watermark 是 2s,allowedLateness 是 2s,allowedLateness在 watermark之后,
到 watermark 时,触发窗口的批次计算,在watermark和allowedLateness之间,每来一个迟到数据,触发一次计算,allowedLateness之后,数据放到侧输出流。
代码如下:
package com.chiato.day04;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.OutputTag;
public class Window_EventTime_Watermark_And_Late {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// socket端口输入的数据格式如
// hello 1547718199
// flink 1547718200
// ...
// 其中第二位为 秒级时间戳
SingleOutputStreamOperator<String> socketDS =
env.socketTextStream("hadoop102", 8888).
assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(2)){
@Override
public long extractTimestamp(String line) {
String[] fields = line.split(" ");
return Long.parseLong(fields[1]) * 1000L;
}
}
);
SingleOutputStreamOperator<Tuple2<String, Integer>> word2OneDS =
socketDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
String[] splits = value.split(" ");
return Tuple2.of(splits[0], 1);
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> keyed = word2OneDS.keyBy(0);
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> windowDS =
keyed.timeWindow(Time.seconds(5))
.allowedLateness(Time.seconds(2))
.sideOutputLateData(new OutputTag<Tuple2<String, Integer>>("sideOutput"){});
SingleOutputStreamOperator<Tuple2<String, Integer>> sumDS = windowDS.sum(1);
sumDS.print("main");
// 获取并打印侧输出流
DataStream<Tuple2<String, Integer>> sideOutput =
sumDS.getSideOutput(new OutputTag<Tuple2<String, Integer>>("sideOutput") {});
sideOutput.print("sideOutput");
env.execute();
}
}

WaterMark

使用 EventTime 的滚动窗口代码
package com.chiato.window;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class Window_EventTime_Tumpling {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 输入数据的格式为 时间戳,分组,个数
// 1000,a,3
// 4999,a,2
SingleOutputStreamOperator<String> inputDS =
env.socketTextStream("hadoop102", 8888)
.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(2)) {
// 仅仅将数据中的时间字段提取出来,不改变数据格式
@Override
public long extractTimestamp(String line) {
String[] fields = line.split(",");
return Long.parseLong(fields[0]);
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> word2SumDS =
inputDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String line) throws Exception {
String[] fields = line.split(",");
return Tuple2.of(fields[1], Integer.parseInt(fields[2]));
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> keyed = word2SumDS.keyBy(0);
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> window =
keyed.window(TumblingEventTimeWindows.of(Time.seconds(5)));
window.sum(1).print();
env.execute();
}
}
hadoop102 为虚拟机主机名,8888 为虚拟机上开启 netcat 的端口号,虚拟机及nc需要自行安装设置。

窗口滚动时间为5秒,设置了延迟2秒触发,所以在第7秒时,触发前5秒的数据进行计算。
Process Timer使用
package com.chiato.day04;
import com.chiato.bean.SensorReading;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.streaming.api.TimerService;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class ProcessAPI_keyedProcessFunc_OnTimer {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketDS = env.socketTextStream("hadoop102", 8888);
SingleOutputStreamOperator<SensorReading> sensorDS = socketDS.map(new MapFunction<String, SensorReading>() {
@Override
public SensorReading map(String value) throws Exception {
String[] splits = value.split(",");
return new SensorReading(splits[0], Long.parseLong(splits[1]), Double.parseDouble(splits[2]));
}
});
KeyedStream<SensorReading, Tuple> keyedStream = sensorDS.keyBy("id");
SingleOutputStreamOperator<String> process = keyedStream.process(new MyKeyedProcessFunc());
process.print();
env.execute();
}
public static class MyKeyedProcessFunc extends KeyedProcessFunction<Tuple, SensorReading, String> {
@Override
public void processElement(SensorReading value, Context ctx, Collector<String> out) throws Exception {
TimerService timerService = ctx.timerService();
long ts = timerService.currentProcessingTime();
System.out.println(ts);
timerService.registerProcessingTimeTimer(ts + 5000L);
out.collect(value.getId());
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
System.out.println("Time" + timestamp);
out.collect("定时器工作了");
}
}
}
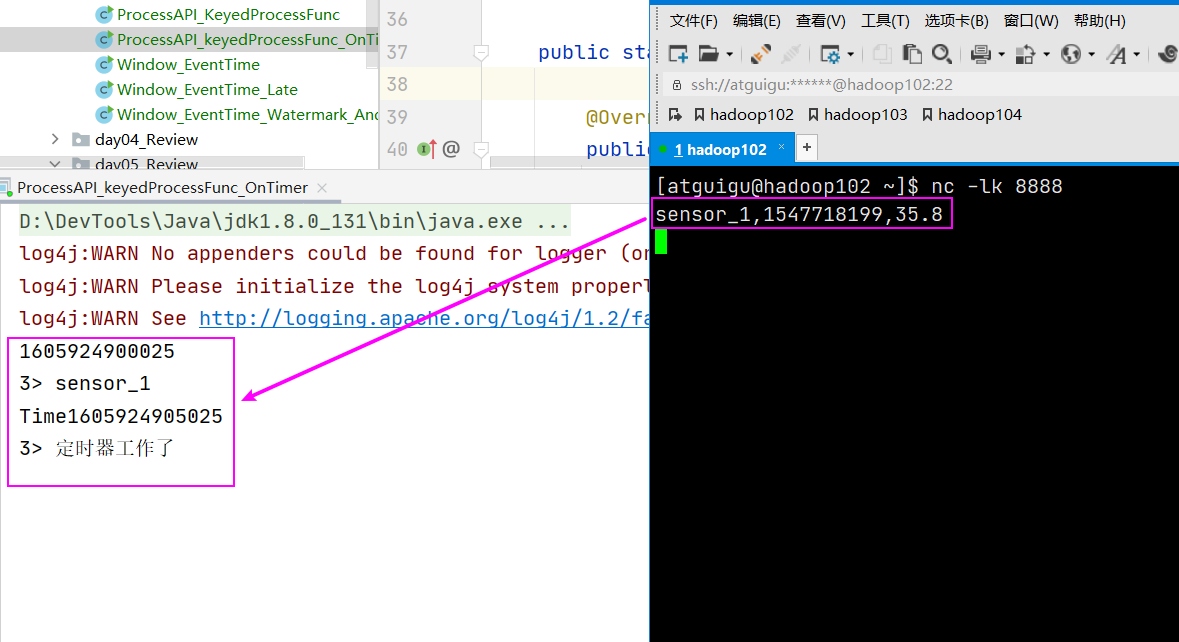
状态自定义使用
定义一个定时器,若传感器温度连续 5s 没有下降,则报警,中间下降,则重置定时器。
package com.chiato.day05;
import com.chiato.bean.SensorReading;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimerService;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class State_OnTimer {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketDS = env.socketTextStream("hadoop102", 8888);
SingleOutputStreamOperator<SensorReading> sensorDS = socketDS.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], Long.parseLong(fields[1]), Double.parseDouble(fields[2]));
});
KeyedStream<SensorReading, Tuple> keyedDS = sensorDS.keyBy("id");
SingleOutputStreamOperator<String> processDS = keyedDS.process(new MyKeyedFunc());
processDS.print();
env.execute();
}
public static class MyKeyedFunc extends KeyedProcessFunction<Tuple, SensorReading, String> {
ValueState<Double> lastTempState = null;
ValueState<Long> tsState = null;
@Override
public void open(Configuration parameters) throws Exception {
lastTempState = getRuntimeContext().getState(new ValueStateDescriptor<Double>("last_temp", Double.class));
tsState = getRuntimeContext().getState(new ValueStateDescriptor<Long>("last_ts", Long.class));
}
@Override
public void processElement(SensorReading value, Context ctx, Collector<String> out) throws Exception {
Double lastTemp = lastTempState.value();
double curTemp = value.getTemp();
lastTempState.update(curTemp);
TimerService timerService = ctx.timerService();
long ts = timerService.currentProcessingTime() + 5000;
if (tsState.value() == null) {
// 第一次设置定时器 或者温度连续上升触发定时器后,重新设置定时器
timerService.registerProcessingTimeTimer(ts);
tsState.update(ts);
} else if (lastTemp != null && curTemp < lastTemp) {
// 删除旧的定时器,开启新的定时器
timerService.deleteProcessingTimeTimer(tsState.value());
timerService.registerProcessingTimeTimer(ts);
tsState.update(ts);
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
out.collect(ctx.getCurrentKey() + "温度连续5s没有下降");
tsState.clear();
}
}
}
SensorReading 为自定义的 JavaBean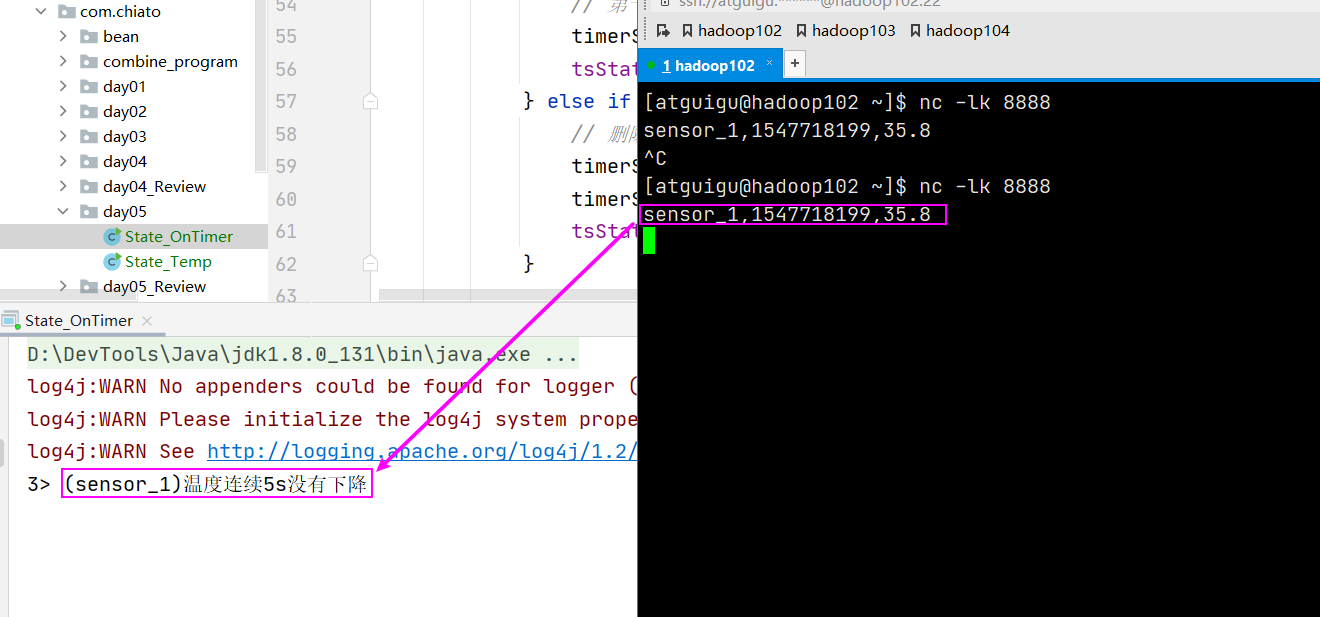

若有收获,就点个赞吧
0 人点赞
