Spark常用端口号
查看当前 Spark-shell 运行任务情况:4040,关闭shell即不再可用
Spark Master 内部通信端口:7077
Spark Standalone 模式下 Master Web 端口号:8080,类比 yarn任务查看端口号 8088
历史服务器端口号:18080
序列化
Spark 2.0 以后开始支持 Kryo序列化,比较轻量,序列化和网络传输速度快。
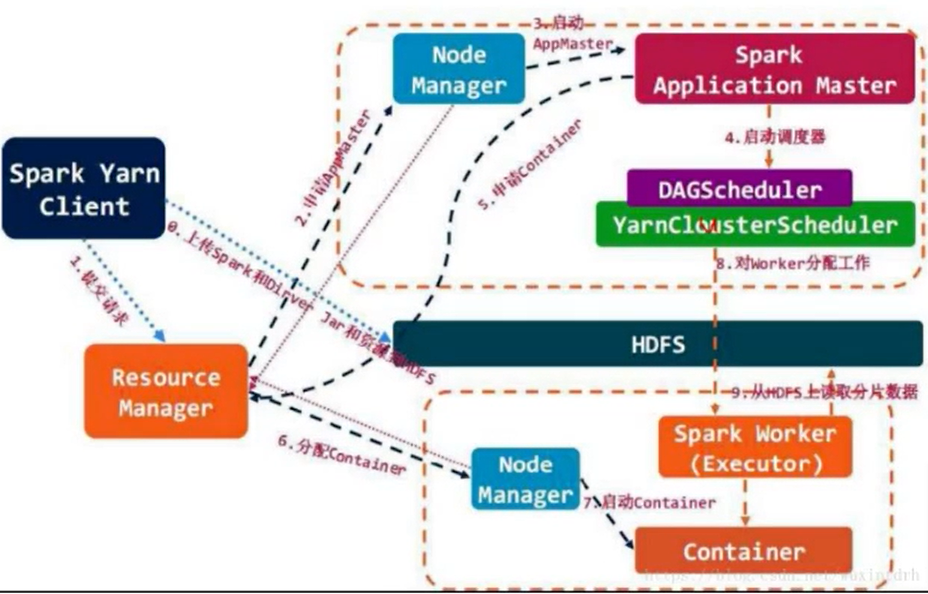
Job提交流程
RDD特征
分区
RDD会对数据进行分区,每个分区会形成一个 Task,每个 Task 发往一个 Executor,(可以理解为每个 Executor 对应一个计算节点)
如下图,1,2 划为1个分区,形成一个 Task,发往一个 Executor 进行计算,3,4 划为1个分区,形成一个 Task,发往另一个 Executor 进行计算,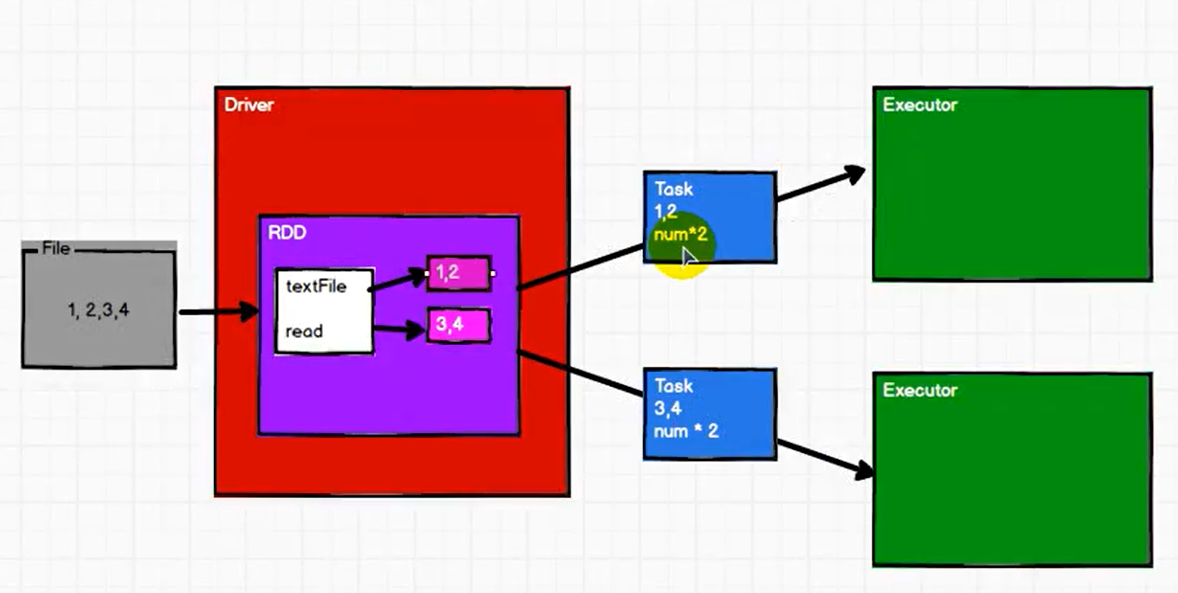
每个分区为单位进行计算
如上图,每个分区的计算逻辑是相同的,计算逻辑是事先封装好的,与分区的数据一同形成一个 Task,发往 Executor。
Rdd之间形成依赖列表
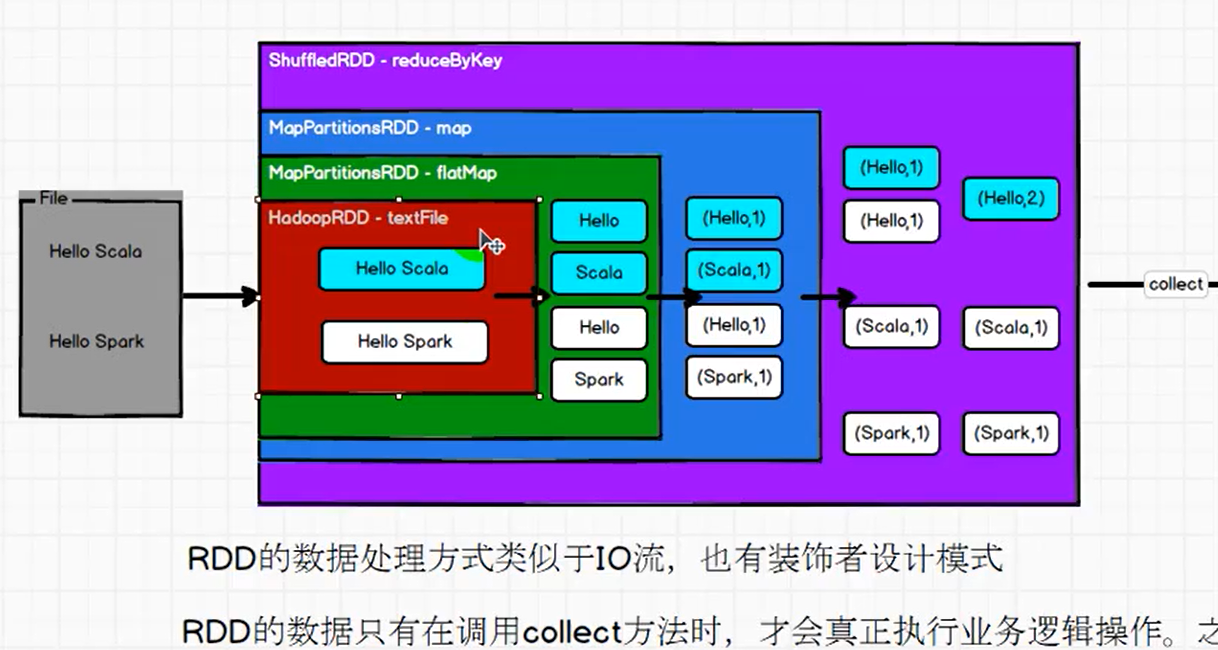
如上图,map 必须在 flatMap 构建完成之后才能构建,于是形成血缘依赖关系。
分区器
如图,如果把 1,2 放在下面的分区,3,4 放在上面的分区,不行吗?
也可以,这就是分区的规则,由分区器决定,类比 Kafka 里面生产者往 topic 分区发送数据的规则。
移动数据不如移动计算逻辑
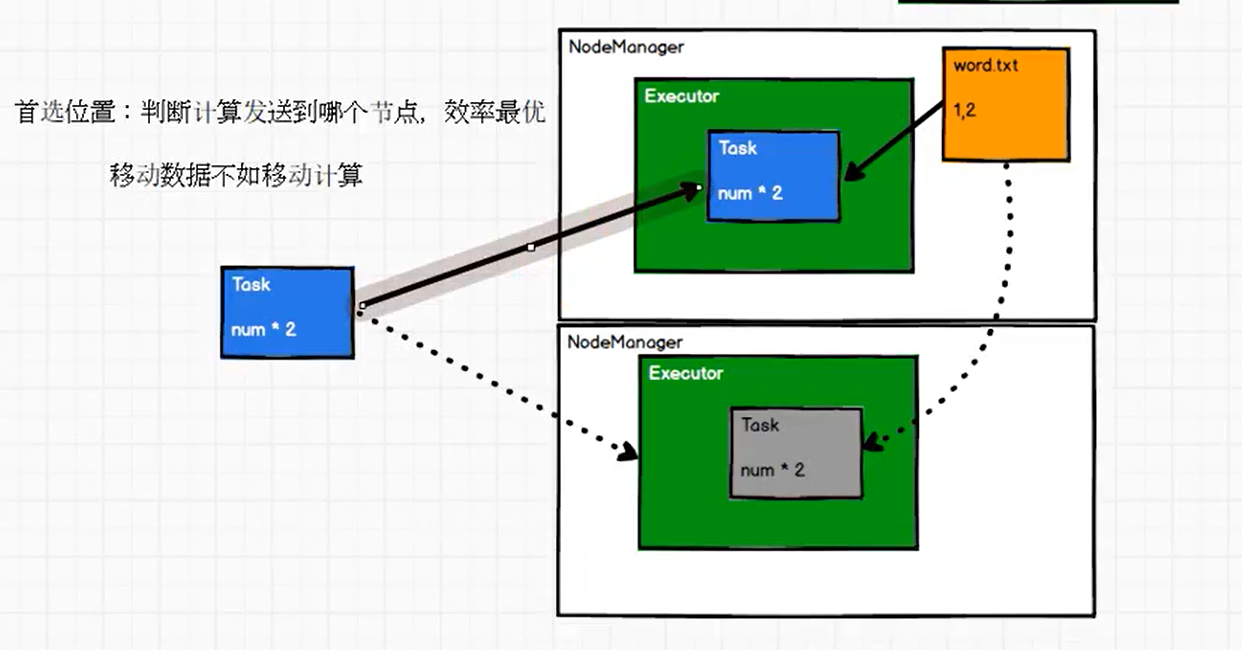
分配 Task 时,应根据数据所在节点,考虑优先将某个 Task 发往哪个计算节点。如图,把数据 1,2 所在分区的形成的 Task 发往上面计算节点就比发往下面计算节点 更优,因为这样 数据和计算逻辑在同一个节点,不会产生网络 IO,反之则会产生网络 IO,效率低。
所以说移动数据不如移动计算任务(决定某个计算任务发往哪个 Executor 执行)。
Spark的Shuffle
Shuffle 就是某个分区数据 去往另一个分区的过程,Shuffle 可能会引起数据倾斜。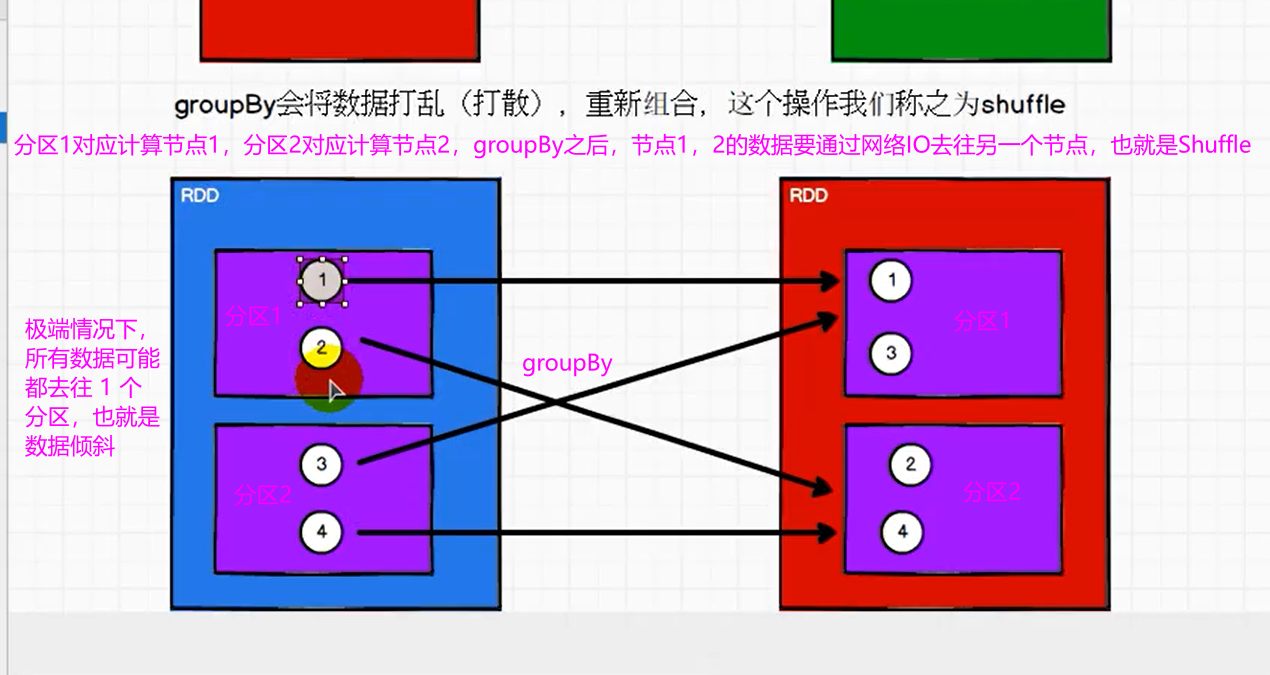
编写Spark客户端代码的pom依赖
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.0.0</version></dependency></dependencies><build><finalName>SparkCoreTest</finalName><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.4.6</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin></plugins></build>
算子
coalesce
coalesce 没有开启 shuffle 参数时,只能缩减分区数,不能扩大分区数。
coalesce 默认不会将一个分区的数据拆开,发往不同的其他分区,即默认不进行 shuffle,问题是可能导致数据倾斜。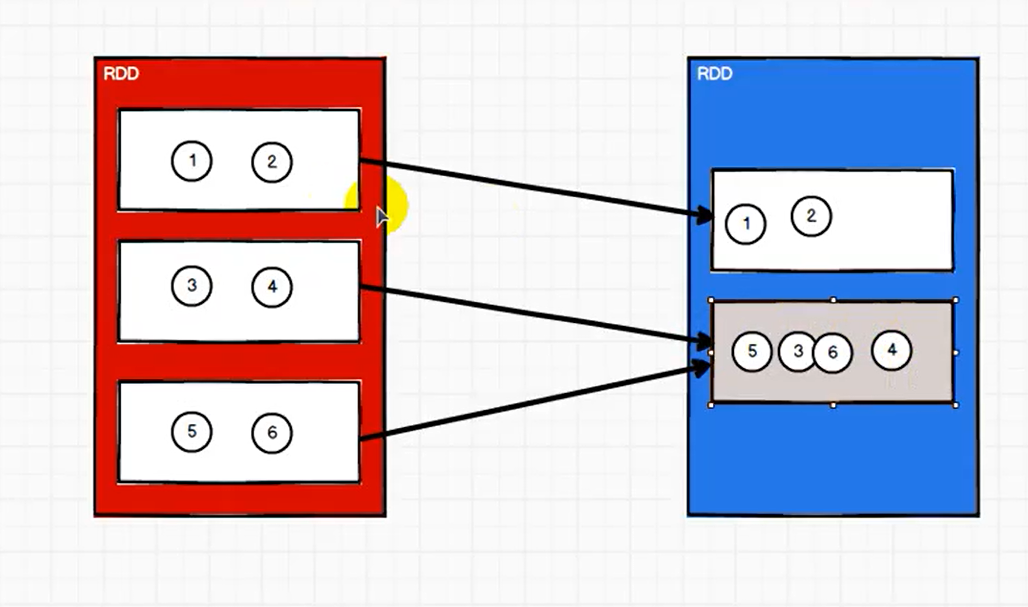
coalesce 开启 shuffle 的结果如下,相对会让数据变得均衡一些。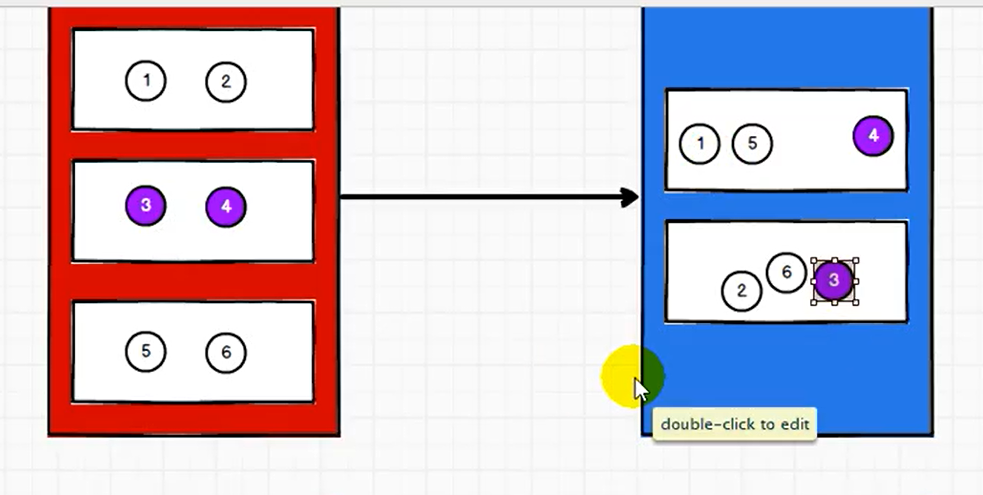
分区数变化总结
如果想缩减分区,就使用 coalesce,同时想数据均衡,则开启 shuffle 参数。
如果想扩大分区,则使用 repartition,且必定会引起 shuffle。
partitionBy
reduceByKey和groupByKey区别
- reduceByKey
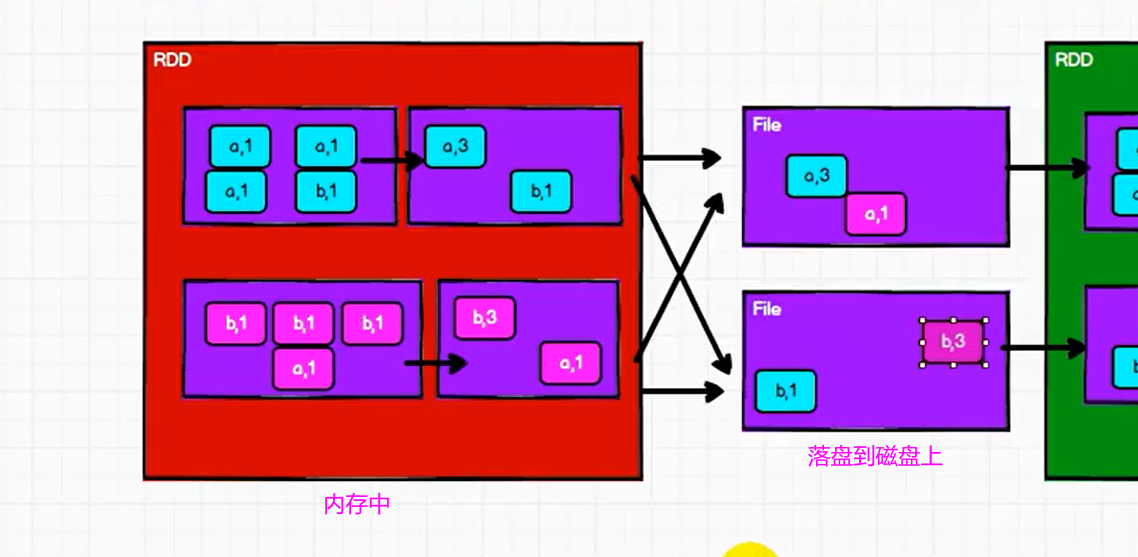
- groupByKey
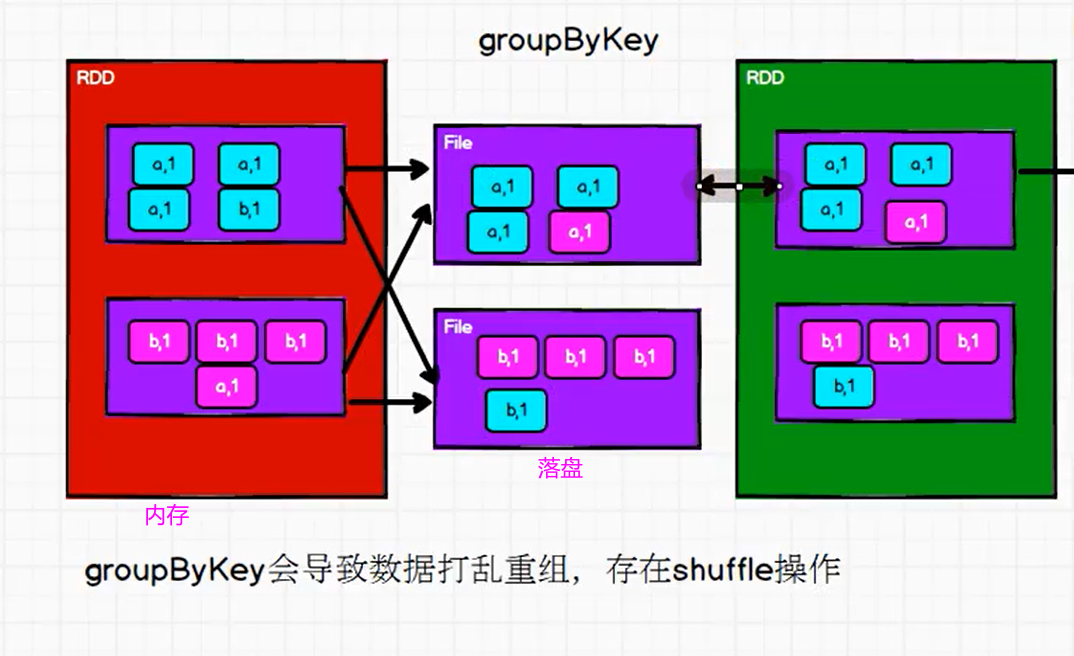
对比 reduceByKey 和 groupByKey 的示意图,可以看出,
reduceByKey 只存储了 1个(a,3),
而 goupByKey 却存储了 3个 (a,1),
明显 reduceByKey 落盘的数据量没有那么大,会用到更少的磁盘IO,效率更高。
即 reduceByKey 会对分区内的数据提前进行预聚合功能,可以有效减少落盘的数据量,提高 shuffle 的性能。
aggregateByKey
reduceByKey 是分区内和分区间数据聚合的规则一样,aggregateByKey 则分区内和分区间的规则可以不一样。
aggregateByKey 存在函数的柯里化,
第一个参数列表表示初始值,
主要用于碰到每个 key 对应的第一个 value 时,和该初始值进行分区内计算
第二个参数列表需要传递两个参数,(传递的参数为函数)
第一个参数表示分区内计算规则,
第二个参数表示分区间计算规则,
下面为一段示例代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkRDD_aggregateByKey {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("MySpar")
val sc = new SparkContext(sparkConf)
// 分区内取最大值,分区间求和
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)), 2
)
val aggRDD: RDD[(String, Int)] = rdd.aggregateByKey(0)(
(x, y) => math.max(x, y),
_ + _
)
aggRDD.collect().foreach(println)
sc.stop()
}
}
aggregateByKey 示意图如下:
aggregateByKey 的简化版本就是 foldByKey,分区内和分区间数据聚合的规则一样。
combineByKey
combineByKey 共有3个参数,
第一个参数,
将相同 key 的第一个值进行结构的转换
第二个参数,(传递的参数为函数)
表示分区内的计算规则
第三个参数,(传递的参数为函数)
表示分区间的计算规则
计算下面 rdd,相同key的平均值
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)), 2
)
使用aggregateByKey
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object SparkRDD_aggregateByKeyAdvanced {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("MySpar")
val sc = new SparkContext(sparkConf)
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)), 2
)
// 给定一个元组初始值(0,0),一个用于累加所有数的和,一个用于累加所有数的个数
val aggRDD: RDD[(String, (Int, Int))] = rdd.aggregateByKey((0, 0))(
(t, v) => {
(t._1 + v, t._2 + 1)
},
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
// 累加结果 相除得到平均值
val value: RDD[(String, Int)] = aggRDD.mapValues {
case (sum, count) => {
sum / count
}
}
value.collect().foreach(println)
sc.stop()
}
}
这样看起来作为初始值的元组 (0,0) 没有算入累加次数,所以下面换 combineByKey 的方法。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkRDD_combineByKey {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("MySpar")
val sc = new SparkContext(sparkConf)
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(
("a", 1), ("a", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6)), 2
)
val combineRDD: RDD[(String, (Int, Int))] = rdd.combineByKey(
v => (v, 1),
(t: (Int, Int), v) => {
(t._1 + v, t._2 + 1)
},
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val value: RDD[(String, Int)] = combineRDD.mapValues {
case (sum, count) => {
sum / count
}
}
value.collect().foreach(println)
sc.stop()
}
}
由于对相同 key 的第一个值做了结构变换,所以后面需要手动指定数据类型
11中wordcount实现方式
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object WordCount {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("MyWordCount")
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.makeRDD(List("Hello Spark","Hello Scala"))
val words: RDD[String] = rdd.flatMap(_.split(" "))
val wordOne: RDD[(String, Int)] = words.map((_, 1))
println("实现方式1")
wordOne.reduceByKey(_ + _).collect().foreach(println)
println("实现方式2")
wordOne.groupByKey().map{
case (words, iter) => {
(words, iter.size)
}
}.collect().foreach(println)
println("实现方式3")
wordOne.aggregateByKey(0)(_+_, _+_).collect().foreach(println)
println("实现方式4")
wordOne.foldByKey(0)(_+_).collect().foreach(println)
println("实现方式5")
wordOne.combineByKey(
countOne => countOne,
(x:Int,y) => x+y,
(x:Int,y:Int)=> x+y
).collect().foreach(println)
println("实现方式6")
words.countByValue().foreach(println)
println("实现方式7")
wordOne.countByKey().foreach(println)
println("实现方式8")
words.map(word => mutable.Map[String,Long]((word,1)))
.reduce(
(m1,m2) => {
m2.foreach {
case (word, count) => {
val newCount: Long = m1.getOrElse(word, 0L) + count
m1.update(word, newCount)
}
}
m1
}
).foreach(println)
println("实现方式9")
words.map(word => mutable.Map[String,Long]((word,1)))
.aggregate(mutable.Map[String,Long]())(
(m1,m2) => {
m2.foreach {
case (str, count) => {
val newCount: Long = m1.getOrElse(str, 0L) + count
m1.update(str, newCount)
}
}
m1
},
(m1,m2) => {
m2.foreach {
case (word, count) => {
val newCount: Long = m1.getOrElse(word, 0L) + count
m1.update(word, newCount)
}
}
m1
}
).foreach(println)
println("实现方式10")
words.map(word => mutable.Map[String,Long]((word,1)))
.fold(mutable.Map[String,Long]())(
(m1,m2) => {
m2.foreach {
case (str, count) => {
val newCount: Long = m1.getOrElse(str, 0L) + count
m1.update(str, newCount)
}
}
m1
}
).foreach(println)
println("实现方式11")
words.groupBy(word=>word).map{
case (str, strings) => (str, strings.size)
}.collect().foreach(println)
sc.stop()
}
}
RDD持久化
rdd 中不存储数据,一个 rdd 若要重复使用,需要从头获取数据再执行一遍。
示例代码:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkRDD_persist {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("myspark")
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.makeRDD(List("Hello Spark", "Hello Scala"))
val flatRDD: RDD[String] = rdd.flatMap(_.split(" "))
val mapRDD: RDD[(String, Int)] = flatRDD.map(
word => {
println("@@@@@@@@@@@@")
(word, 1)
})
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
reduceRDD.collect().foreach(println)
println("################################")
val groupRDD: RDD[(String, Iterable[Int])] = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
sc.stop()
}
}
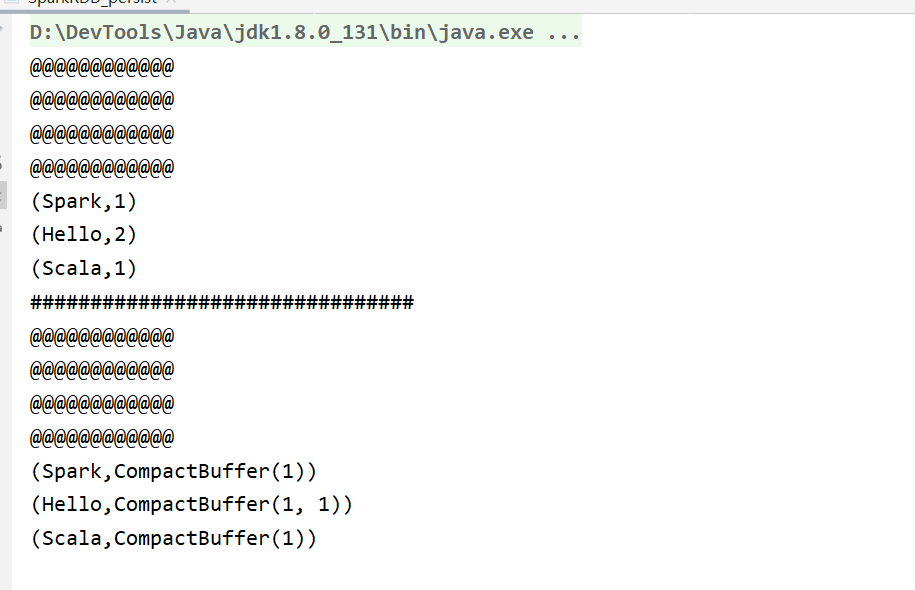
上述代码中,”@@@@@@@@@@@@@” 会在 “#########################################” 前和后都打印一次,说明 map 算子实际走了两次,并不是一次,这说明 rdd 并不保存数据,两个 job ,重复的算子需要跑两次。
cache和persist
从上述结果可知,跑两次重复的计算时非常浪费计算资源,不合理的,所以出现了解决办法,就是 rdd 持久化。持久化为 cache 操作,cache 在内存中缓存中间 rdd 的计算结果。
cache 是 persist 的特殊情况,persist 则可以设置缓存级别 确定将结果缓存在内存中还是磁盘中。
持久化另外一个应用场景是前面的 rdd 操作非常长,重跑起来非常麻烦,这样缓存起来非常方便。
代码实现
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkRDD_persist {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("myspark")
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.makeRDD(List("Hello Spark", "Hello Scala"))
val flatRDD: RDD[String] = rdd.flatMap(_.split(" "))
val mapRDD: RDD[(String, Int)] = flatRDD.map(
word => {
println("@@@@@@@@@@@@")
(word, 1)
})
mapRDD.cache()
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
reduceRDD.collect().foreach(println)
println("################################")
val groupRDD: RDD[(String, Iterable[Int])] = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
sc.stop()
}
}
此时结果为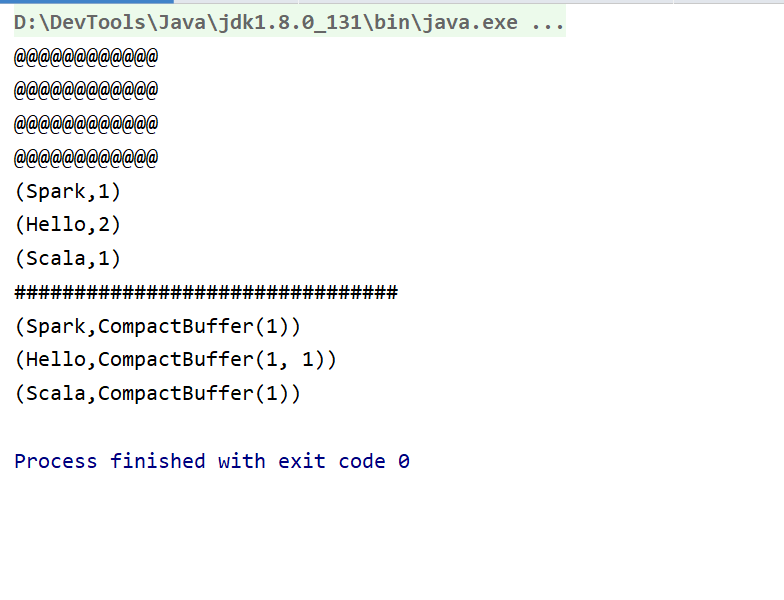
cache和persist 使用后,在job执行完毕后,缓存的数据会被删除。
checkpoint
checkpoint 需要落盘,要指定检查点保存路径,检查点路径保存的文件,在 job 执行完毕后不会删除。
一般保存路径都是分布式存储系统,如 hdfs。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkRDD_persist {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("myspark")
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.makeRDD(List("Hello Spark", "Hello Scala"))
val flatRDD: RDD[String] = rdd.flatMap(_.split(" "))
val mapRDD: RDD[(String, Int)] = flatRDD.map(
word => {
println("@@@@@@@@@@@@")
(word, 1)
})
sc.setCheckpointDir("cp")
mapRDD.checkpoint()
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
reduceRDD.collect().foreach(println)
println("################################")
val groupRDD: RDD[(String, Iterable[Int])] = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
sc.stop()
}
}
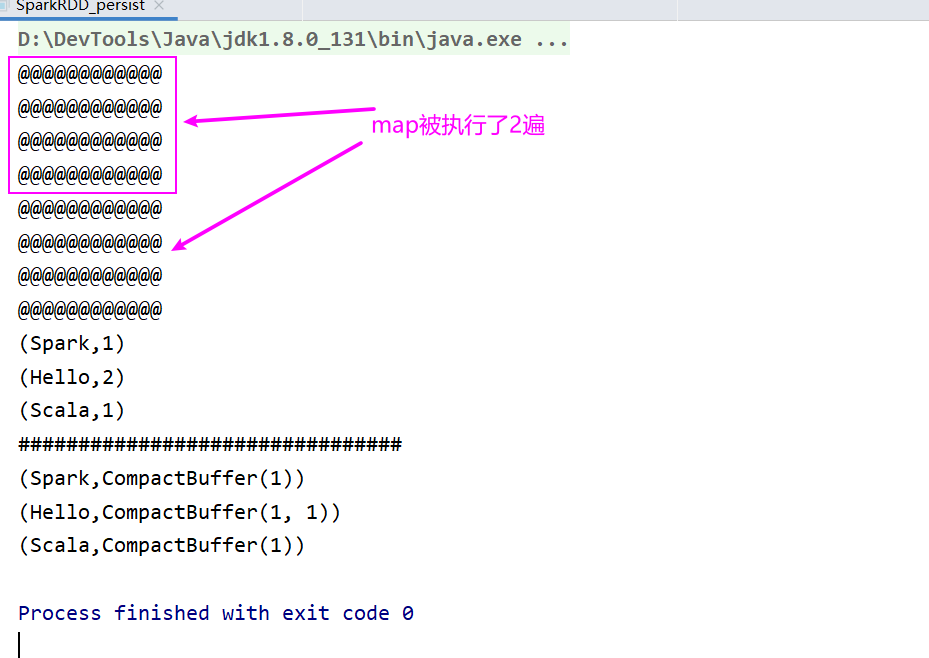
checkpoint 为保证数据安全,会再独立的执行一次持久化前的所有 rdd,所以会执行两次。
cache和checkpoint区别
- cache 是 persist 的特殊情况,persist 和 cache 持久化数据会在 job 执行完毕后将数据删除。
- checkpoint 持久化数据在 job 执行完毕后仍会保存,且一般会持久化到分布式系统,如 hdfs 中,更安全。
- checkpoint 会独立的再执行一遍 前面缓存前所有的 rdd,效率低,所以一般和 cache 结合使用,在调用 checkpoint 前,先调用 cache,然后再调用 checkpoint,这样可以避免二次执行 缓存前的 rdd。
- cache和persist 会在血缘关系中添加新的依赖,一旦出现问题,可以重头读取数据。checkpoint 会切断 缓存前的血缘关系,新建血缘关系,等同于改变数据源。
自定义实现累加器
- 继承 AccumulatorV2[IN, OUT]
IN和OUT表示累加器的输入输出泛型
- 在调用方法中使用上下文对象 sc 注册累加器(
sc.register(acc, "name")) - 调用累加器的 add 方法(
acc.add(word)) ```scala
import org.apache.spark.rdd.RDD import org.apache.spark.util.AccumulatorV2 import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object SparkAcc_WordCount { def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster(“local[*]”).setAppName(“MySpark”) val sc = new SparkContext(sparkConf) val lineRDD: RDD[String] = sc.makeRDD(List( “Hello Spark”, “Hello Scala” )) val flatRDD: RDD[String] = lineRDD.flatMap(.split(“ “))
val acc = new MyAccumulator()
sc.register(acc, "wordAcc")
flatRDD.foreach(
word => {
acc.add(word)
}
)
acc.value.foreach(println)
sc.stop()
} }
class MyAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]] {
private var wordAcc = mutable.MapString, Long
// 判断累加器是否为初始状态 override def isZero: Boolean = { wordAcc.isEmpty }
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = { new MyAccumulator() }
override def reset(): Unit = { wordAcc.clear() }
// 每个 Executor 上,累加器的行为 override def add(word: String): Unit = { val newCnt: Long = wordAcc.getOrElse(word, 0L) + 1 wordAcc.update(word, newCnt) }
// 多个累加器到 Driver 端的合并操作 override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = { val otherMap: mutable.Map[String, Long] = other.value
otherMap.foreach {
case (word, cnt) => {
val totalCnt: Long = wordAcc.getOrElse(word, 0L) + cnt
wordAcc.update(word, totalCnt)
}
}
}
// 累加器的值 override def value: mutable.Map[String, Long] = { wordAcc } } ```

若有收获,就点个赞吧
0 人点赞
