- 基础知识
- 01 查找最晚入职员工的所有信息
- 02 查找入职员工时间排名倒数第三的员工所有信息
- 03 查找在当前时刻(to_date=‘9999-01-01’),各个部门的经理的薪水详情以及其对应部门编号dept_no
- 04 查找所有已经分配部门的员工的last_name和first_name以及dept_no(请注意输出描述里各个列的前后顺序)
- 05 查找所有员工的last_name和first_name以及对应部门编号dept_no,也包括暂时没有分配具体部门的员工(请注意输出描述里各个列的前后顺序)
- 06 查找所有员工入职时候的薪水情况,给出emp_no以及salary, 并按照emp_no进行逆序(请注意,一个员工可能有多次涨薪的情况)
- 07 查找薪水变动超过15次的员工号emp_no以及其对应的变动次数t
- 08 获取所有部门当前(dept_manager.to_date=’9999-01-01’)manager的当前(salaries.to_date=’9999-01-01’)薪水情况,给出dept_no, emp_no以及salary(请注意,同一个人可能有多条薪水情况记录)
- 09 获取所有非manager的员工emp_no
- 10 获取所有员工当前的(dept_manager.to_date=’9999-01-01’)manager,如果员工是manager的话不显示(也就是如果当前的manager是自己的话结果不显示)。输出结果第一列给出当前员工的emp_no,第二列给出其manager对应的emp_no。
- 11 获取所有部门中当前(dept_emp.to_date = ‘9999-01-01’)员工当前(salaries.to_date=’9999-01-01’)薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary,按照部门升序排列。
- 12 从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。
- 13 从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。注意对于重复的emp_no进行忽略(即emp_no重复的title不计算,title对应的数目t不增加)。
- 14 查找employees表所有emp_no为奇数,且last_name不为Mary(注意大小写)的员工信息,并按照hire_date逆序排列(题目不能使用mod函数)
基础知识
SELECT 用于筛选出自己想要的数据
*、 是通配符,表示都要
-- 和 #都是SQL的注释
/* */多行的注释
ORDER BY 根据指定的列对结果集进行排序,默认按照升序,降序 ORDER BY DESC 值得注意的是需要是最后的一条子句。ORDER by 2,3 不能使用SELECT 里面没有的行
DESC 如果对多个进行的话,需要对每一列都使用
LIMIT(m, n)从第 m + 1 行开始取 n 条记录
WHERE 条件语句,ORDER BY 要在其之后
DISTINCT
去重复,对于所有的列都是有效的,DISTINCT不能用于COUNT(*) 和
LEFT JOIN ``` ON` 左边联表查询,有表没有匹配的话,那还是输出一个NULL
IN 表示数据在一个范围之内 IN的操作比OR要快
LIKE 和通配符操作起来,一起实现匹配
% 任何字符出现任意次 % 不能匹配NULL
_ 匹配单个字符
TRIM() 去掉两边的空格键
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
SELECT 子句顺序
- SELECT
- FROM
- WHERE
- GROUP BY
- HAVING
-
聚合函数
AVG() 获取一列的平均值,忽略NULL
- COUNT()如果是* 就会不会忽略空行, 如果指定一个行就会忽略
- MAX() 返回里面的最大值,对于文书的数据,会返回排序后的最后一行, 忽略NULL
- MIN()和MAX 差不多,相反
- SUM()
分组数据
GROUP BY
用于把数据分割成为多个逻辑组,对每一个组进行计算
必须在WHERE 之后,ORDER BY 之前
在使用GROUP BY的时候也要记得使用ORDER BY 保证里面顺序
HAVING 过滤分组,类似于WHERE 可以用于替代WHERE
01 查找最晚入职员工的所有信息

思路1:目前里面的日期都不是同一天。 可以使用ORDER BY 反向排序, LIMIT 来选取
SELECT * FROM employees ORDER BY hire_date DESC LIMIT 0,1
思路2: 子查询
先查询出最晚的聘用日期
SELECT * FROM employees
WHERE hire_date = (
SELECT MAX(hire_date)
FROM employees
)
02 查找入职员工时间排名倒数第三的员工所有信息

思路1:考虑到里面的日期是没有重复的,就是同一天入职的只有一个人。
SELECT * FROM employees
ORDER BY hire_date DESC
LIMIT 2,1
思路2:
和上面的一样,做一个筛选
SELECT * FROM employees
WHERE hire_date = (
SELECT DISTINCT hire_date
FROM employees
ORDER BY hire_date DESC
LIMIT 1 OFFSET 2
)
03 查找在当前时刻(to_date=‘9999-01-01’),各个部门的经理的薪水详情以及其对应部门编号dept_no
思路
这个就是联表查询一下
SELECT s.* , d.dept_no FROM salaries AS s , dept_manager as d
WHERE s.to_date='9999-01-01'
AND d.to_date='9999-01-01'
AND s.emp_no = d.emp_no;
04 查找所有已经分配部门的员工的last_name和first_name以及dept_no(请注意输出描述里各个列的前后顺序)
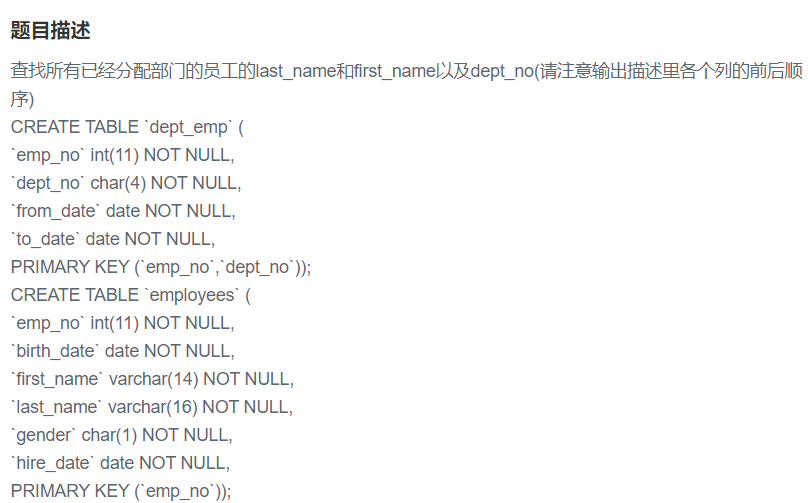
思路 就是连表查询一下
SELECT e.last_name, e.first_name, d.dept_no
FROM employees AS e,dept_emp as d
WHERE e.emp_no = d.emp_no
05 查找所有员工的last_name和first_name以及对应部门编号dept_no,也包括暂时没有分配具体部门的员工(请注意输出描述里各个列的前后顺序)

这道题用到了联表查询的 左连接
LEFT JOIN ON 左边的没有也会显示出来
INNER JOIN ON 都有的才会显示出来
RIGHT JOIN ON 右边没有的也会显示出来
FULL JOIN ON 不管有没有,都会被显示出来
06 查找所有员工入职时候的薪水情况,给出emp_no以及salary, 并按照emp_no进行逆序(请注意,一个员工可能有多次涨薪的情况)

这道题考察的是对于这个题目的理解,因为s这个表里面对于一个员工可能有不同的薪水数据。需要的是最初的那个数据,可以认为是聘用的时间,等于开始的时间。
SELECT e.emp_no, s.salary
FROM employees AS e, salaries AS s
where s.emp_no = e.emp_no
AND e.hire_date = s.from_date
ORDER BY
e.emp_no DESC
07 查找薪水变动超过15次的员工号emp_no以及其对应的变动次数t

主要使用 COUNT() 函数来记录一下出现的次数, 用Having 来做一个筛选
SELECT emp_no, count(emp_no) AS t
FROM salaries GROUP BY emp_no
having t>15;
08 获取所有部门当前(dept_manager.to_date=’9999-01-01’)manager的当前(salaries.to_date=’9999-01-01’)薪水情况,给出dept_no, emp_no以及salary(请注意,同一个人可能有多条薪水情况记录)
做一个内连接的查询, 加上条件语句
SELECT d.dept_no, d.emp_no, s.salary
FROM dept_manager AS d
INNER JOIN salaries AS s
ON d.emp_no = s.emp_no
WHERE d.to_date ='9999-01-01' AND s.to_date='9999-01-01'
SELECT d.dept_no, d.emp_no, s.salary
FROM dept_manager AS d
INNER JOIN salaries AS s
ON d.emp_no = s.emp_no
WHERE d.to_date =’9999-01-01’ AND s.to_date=’9999-01-01’
09 获取所有非manager的员工emp_no

筛选出所有的人之后,去掉是主管的id
SELECT emp_no
FROM employees
WHERE emp_no NOT IN (SELECT emp_no FROM dept_manager);
10 获取所有员工当前的(dept_manager.to_date=’9999-01-01’)manager,如果员工是manager的话不显示(也就是如果当前的manager是自己的话结果不显示)。输出结果第一列给出当前员工的emp_no,第二列给出其manager对应的emp_no。
使用连接和条件语句来规定里面的数据。
SELECT e.emp_no, m.emp_no AS manager_no
FROM dept_emp AS e
LEFT JOIN dept_manager AS m
ON e.dept_no = m.dept_no
WHERE e.emp_no != m.emp_no
AND e.to_date='9999-01-01'
AND m.to_date='9999-01-01';
11 获取所有部门中当前(dept_emp.to_date = ‘9999-01-01’)员工当前(salaries.to_date=’9999-01-01’)薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary,按照部门升序排列。
关联子查询,外表固定一个部门,内表进行子查询
关联子查询,外表固定一个部门,内表进行子查询
SELECT d1.dept_no, d1.emp_no, s1.salary
FROM dept_emp as d1
INNER JOIN salaries as s1
ON d1.emp_no=s1.emp_no
AND d1.to_date='9999-01-01'
AND s1.to_date='9999-01-01'
WHERE s1.salary in (SELECT MAX(s2.salary)
FROM dept_emp as d2
INNER JOIN salaries as s2
ON d2.emp_no=s2.emp_no
AND d2.to_date='9999-01-01'
AND s2.to_date='9999-01-01'
AND d2.dept_no = d1.dept_no
)
ORDER BY d1.dept_no;
12 从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。

用GROUP BY 分组, 使用HAVING 做一个条件判断
SELECT title, COUNT(title) AS t
FROM titles
GROUP BY title
HAVING t>=2;
13 从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。注意对于重复的emp_no进行忽略(即emp_no重复的title不计算,title对应的数目t不增加)。

需要先使用emp_no 进行一个去重,之后使用GROUP BY 哈 HAVING 来做一个筛选
SELECT title, COUNT(title) AS t
FROM (SELECT DISTINCT emp_no, title FROM titles)
GROUP BY title
HAVING t>=2;
14 查找employees表所有emp_no为奇数,且last_name不为Mary(注意大小写)的员工信息,并按照hire_date逆序排列(题目不能使用mod函数)

主要的难点就是在奇偶数的判断上, 奇数 可以使用 % 2 =1 来判断,也可以使用mod(num,2)=1 来判断
SELECT *
FROM employees
WHERE last_name != 'Mary'
AND emp_no % 2 =1
ORDER BY hire_date DESC

若有收获,就点个赞吧
0 人点赞
