1 概述
1.1 数据库查询的问题
- 性能低:使用模糊查询,左边有通配符,不会走索引,会全表扫描,性能低
- 功能弱:如果以“华为手机”作为条件,查询不出来数据
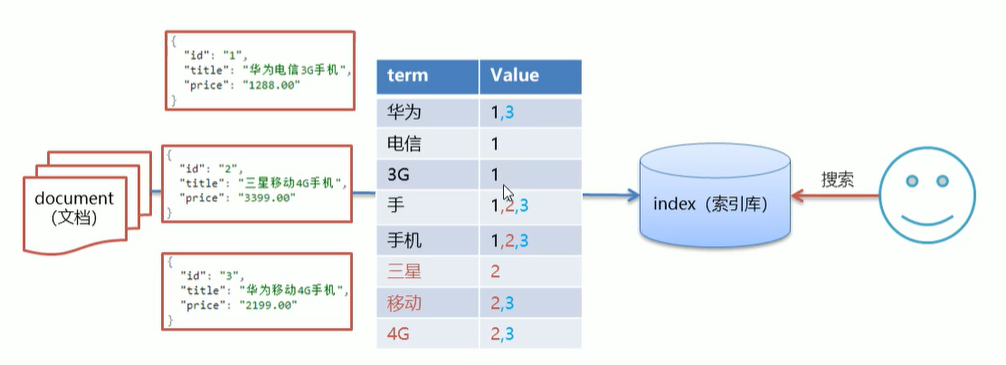
解决方案:倒排(反向)索引:将各个文档中的内容进行分词,形成词条。然后记录词条和数据的唯一标识(id)对应关系形成的产物
例如:床前明月光
将一段文本按照一定的规则,拆分为不同的词条(trem)
1.2 Elasticsearch数据的存储和搜索原理
1.3 概念
- Elasticsearch是一个基于Lucene的搜索服务器
- 是一个分布式、高扩展、高实时的搜索与数据分析引擎
- 基于RESTful web接口
- 使用Java语言开发的,并作为apache许可条款下的开发源码发布,是一种流行的企业级搜索引擎
应用场景:海量数据的查询,日志数据分析,实时数据分析
注意点:
- mysql有事务性,而Elasticsearch没有事务性,删除的数据无法恢复
- Elasticsearch没有物理外键特性。如果对数据要求高慎用
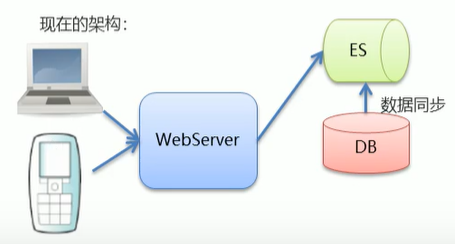
- MySQL负责存储数据,Elasticsearch负责搜索数据
2 安装
2.1 Elasticsearch安装
windows版
修改elasticsearch配置文件:config/elasticsearch.yml,增加以下两句命令:
此步为允许elasticsearch跨越访问,如果不安装后面的elasticsearch-head是可以不修改,直接启动。
http.cors.enabled: truehttp.cors.allow‐origin: "*"
启动:
点击ElasticSearch下的bin目录下的elasticsearch.bat启动,控制台显示的日志信息如下:
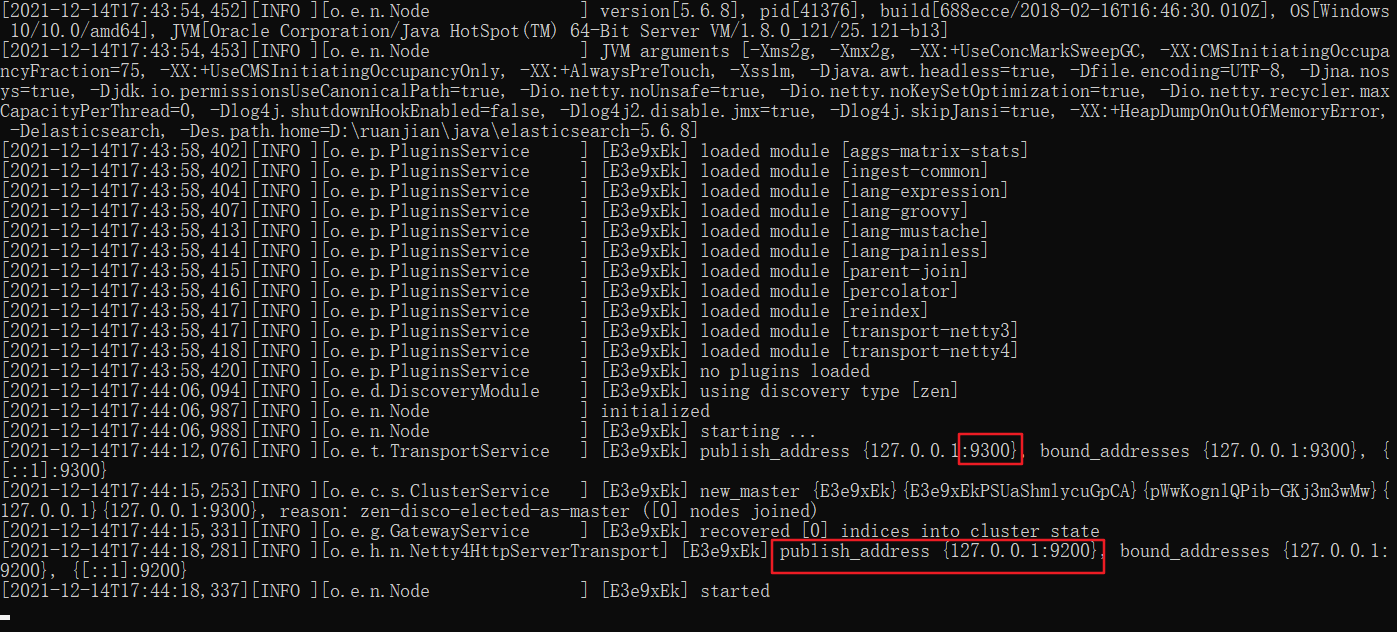
注意:9300是tcp通讯端口,集群间和TCPClient都执行该端口,9200是http协议的RESTful接口 。
通过浏览器访问ElasticSearch服务器,看到如下返回的json信息,代表服务启动成功:
访问:http://localhost:9200/
返回的信息: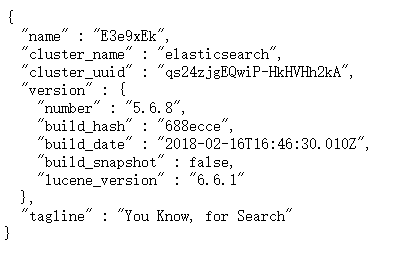
2.2 安装ES的图形化界面插件
下载:https://github.com/mobz/elasticsearch-head
下载nodejs:https://nodejs.org/en/download/
查看node版本号:node -v
将grunt安装为全局命令 ,Grunt是基于Node.js的项目构建工具
npm install -g grunt-cli

进入elasticsearch-head-master目录启动head,在命令提示符下输入命令
npm install
grunt server
3 ElasticSearch相关概念
- 索引index :ElasticSearch存储数据的地方
- 映射mapping:定义了每个字段的类型,字段所使用的分词器等。相当于关系型数据库中的表结构
- 文档document:ElasticSearch种最小的数据单元。长以json格式显示。一个document相当于关系数据库中的一行数据
- 倒排索引:将各个文档中的内容进行分词,形成词条。然后记录词条和数据的唯一标识(id)对应关系形成的产物
- 类型type:
- 一种type就像一类表。
- 在ElasticSearch7.x默认type为_doc
4 操作ElasticSearch
4.1 RESTful风格介绍
- 定义接口的规范
- 基于http
- 每一个url代表一个资源
- 操作方式
- get:获取资源
- post:新建、更新资源
- put:更新资源
- delete:删除资源
4.2 操作索引
添加索引:put http://ip:端口/索引名称
查询索引: get http://ip:端口/索引名称
删除索引:delete http://ip:端口/索引名称
关闭索引:post http://ip:端口/索引名称/_close
打开索引:post http://ip:端口/索引名称/_open
4.3 操作映射
- 简单数据类型
- 字符串
- text:会分词,不支持聚合
- keyword:不会分词,将全部内容作为一个词条,支持聚合
- 数值
- 布尔 boolean
- 二进制 binary
- 范围类型
- integer_range
- float_range
- long_range
- double_range
- date_range
- 日期 date
- 字符串
- 复杂数据类型
- 数组[]
- 对象{}
创建索引put person
查询索引get person
删除索引 delete person
查询映射 get person/_mapping
添加映射/字段
put person/_mapping{
"properties":{
"name":{
"type":"keyword"
},
"age":{
"type":"integer"
}
}
}
创建索引并添加映射
put person{
"mappings":{
"properties":{
"name":{
"type":"keyword"
},
"age":{
"type":"integer"
}
}
}
}
4.4 操作文档
添加文档,指定ID
put/post person/_doc/1{
"name":"zhangsan",
"age":30
}
添加文档,不指定ID
put person/_doc/{
"name":"zhangsan",
"age":30
}
根据ID查询文档 person/_doc/id
查询所有文档 peerson/_search
4.4 分词器
4.4.1 Elasticsearch的内置分词器
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤), 小写处理
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
- Patter Analyzer - 正则表达式,默认\W+(非字符分割)
- Language - 提供了30多种常见语言的分词器
- Customer Analyzer 自定义分词器
内置分词器对中文不友好。处理方式一个字一个词
4.4.2 IK分词器
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
解压,将解压后的elasticsearch文件夹拷贝到elasticsearch-5.6.8\plugins下,并重命名文件夹为analysis-ik
重新启动ElasticSearch,即可加载IK分词器
4.4.2.1 分类
ik_smart 最少切分
ik_max_word 最细粒度划分
get _analyze{
"analyze":"ik_smart ",
"text":"我爱北京天安门"
}
4.4.2.2 语法
es默认使用分词器是stsndard。一个字一个词
term 词条查询查询的条件字符串和词条完全匹配
match 先会对查询的字符串进行分词,在查询,求交集
get person/_search{
"query":{
"term":{
"adddress":{
"value":"北"
}
}
}
}
创建索引,添加映射,指定使用Ik分词器
put person{
"mappings":{
"properties":{
"name":{
"type":"text",
"analyzer":"ik_max_word "
},
"age":{
"type":"integer"
}
}
}
}
match的使用
get person/_search{
"query":{
"match":{
"address":"北京"
}
}
}
5 java api
5.1 springboot 整合es
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
5.2 操作
package com.example.demo;
import com.alibaba.fastjson.JSONObject;
import com.example.demo.pojo.UserPo;
import com.mongodb.util.JSON;
import org.bson.json.JsonObject;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.IndicesClient;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.Test;
import org.springframework.beans.factory.annotation.Autowired;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
/**
* @Author gett
* @Date 2021/12/19 14:23
* @Description
*/
public class ESdemo {
@Autowired
RestHighLevelClient client;
@Test
// 添加索引
public void addIndex() throws IOException {
// 使用client获取操作索引的对象
IndicesClient indices = client.indices();
// 具体操作,获取返回值
CreateIndexRequest request = new CreateIndexRequest("person");
// 设置mappings
String mappings="";
request.mapping(mappings, XContentType.JSON);
CreateIndexResponse createIndexResponse = indices.create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
@Test
// 操作文档
public void addDoc() throws IOException {
Map data = new HashMap<>();
data.put("name","zhangsan");
IndexRequest person = new IndexRequest("person").id("1").source(data);
IndexResponse index = client.index(person, RequestOptions.DEFAULT);
System.out.println(index.getId());
}
@Test
// 添加文档,使用对象作为数据
public void addDoc2() throws IOException {
UserPo userPo = new UserPo();
userPo.setId("20211219");
userPo.setUsername("zhangsan");
// 将对象转为json
String s = JSONObject.toJSONString(userPo);
// 获取操作文档的对象
IndexRequest indexRequest = new IndexRequest();
// 添加数据、获取结果
IndexResponse index = client.index(indexRequest, RequestOptions.DEFAULT);
System.out.println(index);
}
}
6 高级
6.1 批量操作-脚本
bullk批量操作是将文档的增删改查一系列操作,通过一次请求全部做完,减少网络的传输次数
post /_bulk{
"action":{
"metadatd"
}
}{
"data"
}
post /_bulk{
"delete":{
"_index":"person",
"_id":"5"
}
}
{
"create":{
"_index":"person",
"_id":"5"
}
}
{
"name":"zhangsan",
"age":30
}
{
"uodate":{
"_index":"person",
"_id":"5"
}
}{
"name":"lisi"
}
// 批量操作 bulk
@Test
public void testBulk() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
DeleteRequest deleteRequest = new DeleteRequest("person","1");
bulkRequest.add(deleteRequest);
Map map = new HashMap<>();
IndexRequest indexRequest = new IndexRequest("person").id("6").source(map);
bulkRequest.add(indexRequest);
BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulk);
}
6.2 导入数据
@Autowired
RestHighLevelClient client;
@Resource
private TfBImpicInfoMapper tfBImpicInfoMapper;
// 批量导入
@Test
public void importData() throws IOException {
// 查询所有数据
List<TfBImpicInfo> tfBImpicInfos = tfBImpicInfoMapper.selectList(null);
BulkRequest bulkRequest = new BulkRequest();
for (TfBImpicInfo info:tfBImpicInfos){
IndexRequest indexRequest = new IndexRequest();
indexRequest.id(info.getId()).source(JSONObject.toJSONString(info),XContentType.JSON);
bulkRequest.add(indexRequest);
}
client.bulk(bulkRequest,RequestOptions.DEFAULT);
}
6.3 查询
6.3.1 matchAll 查询所有
默认情况下es一次展示10条,可以通过from和size控制分页
get person/_search{
"query":{
"match_all":{}
},
"form":0,
"siza":100
}
// 查询所有
@Test
public void matchAll() throws IOException {
// 构建查询请求。指定查询的索引名称
SearchRequest person = new SearchRequest("person");
// 创建查询条件构造器。
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
QueryBuilder query=QueryBuilders.matchAllQuery();
sourceBuilder.query(query);
// 添加查询条件构造器
person.source(sourceBuilder);
// 添加分页信息
sourceBuilder.from(0);
sourceBuilder.size(100);
SearchResponse search = client.search(person, RequestOptions.DEFAULT);
// 获取命中对象
SearchHits hits = search.getHits();
// 获取总记录数
long value = hits.getTotalHits().value;
// 获取数据 数组
ArrayList<TfBImpicInfo> objects = new ArrayList<>();
SearchHit[] hitsHits = hits.getHits();
for (SearchHit hit:hitsHits){
// 获取json字符串
String sourceAsString = hit.getSourceAsString();
TfBImpicInfo info = JSONObject.parseObject(sourceAsString, TfBImpicInfo.class);
objects.add(info);
}
6.3.2 term 查询
不会对查询条件进行分词
get person/_search{
"query":{
"term":{
"adddress":{
"value":"北"
}
}
}
}
// term词条查询
@Test
public void termQuery() throws IOException {
SearchRequest person = new SearchRequest("person");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
TermQueryBuilder query = QueryBuilders.termQuery("titel", "华为");
sourceBuilder.query(query);
person.source(sourceBuilder);
SearchResponse search = client.search(person, RequestOptions.DEFAULT);
SearchHits hits = search.getHits();
long value = hits.getTotalHits().value;
ArrayList<TfBImpicInfo> objects = new ArrayList<>();
SearchHit[] hitsHits = hits.getHits();
for (SearchHit hit:hitsHits){
// 获取json字符串
String sourceAsString = hit.getSourceAsString();
TfBImpicInfo info = JSONObject.parseObject(sourceAsString, TfBImpicInfo.class);
objects.add(info);
}
for (TfBImpicInfo info:objects){
System.out.println(info);
}
}
6.3.3 match查询
对查询条件分词。将分词后的查询条件和词条进行等值匹配
get person/_search{
"query":{
"match":{
"address":"北京",
"operator":"or/and"
}
}
}
// match词条查询
@Test
public void matchuery() throws IOException {
SearchRequest person = new SearchRequest("person");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
MatchQueryBuilder query = QueryBuilders.matchQuery("titel", "华为");
query.operator(Operator.AND);//求并集
sourceBuilder.query(query);
person.source(sourceBuilder);
SearchResponse search = client.search(person, RequestOptions.DEFAULT);
SearchHits hits = search.getHits();
long value = hits.getTotalHits().value;
ArrayList<TfBImpicInfo> objects = new ArrayList<>();
SearchHit[] hitsHits = hits.getHits();
for (SearchHit hit:hitsHits){
// 获取json字符串
String sourceAsString = hit.getSourceAsString();
TfBImpicInfo info = JSONObject.parseObject(sourceAsString, TfBImpicInfo.class);
objects.add(info);
}
for (TfBImpicInfo info:objects){
System.out.println(info);
}
}
6.3.4 模糊查询
- wildcard:会对查询条件进行分词。还可以使用通配符?和*。模糊查询
- regexp:正则查询
- prefix:前缀查询
get person/_search{
"wildcard":{
"title":{
"value":"华"
}
}
}
6.3.5 范围查询
range
get person/_search{
"query":{
"price":{
"gte":2000,
"lte":3000
}
}
}
6.3.6 queryString
- 会对查询条件进行分词,将分词后的查询条件和词条进行等值匹配。默认取并集or。
可以指定多个查询字段
get person/_search{ "query":{ "query_string":{ "fields":["字段1","字段2"], "query":"查询条件1 or 查询条件2" } } }``` @Test public void queryStringQuery() throws IOException {
SearchRequest person = new SearchRequest("person"); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); QueryStringQueryBuilder query= QueryBuilders.queryStringQuery("华为").field("title").field( "categoryName").defaultOperator(Operator.AND); sourceBuilder.query(query); person.source(sourceBuilder); SearchResponse search = client.search(person, RequestOptions.DEFAULT); SearchHits hits = search.getHits(); long value = hits.getTotalHits().value; ArrayList<TfBImpicInfo> objects = new ArrayList<>(); SearchHit[] hitsHits = hits.getHits(); for (SearchHit hit:hitsHits){// 获取json字符串
String sourceAsString = hit.getSourceAsString(); TfBImpicInfo info = JSONObject.parseObject(sourceAsString, TfBImpicInfo.class); objects.add(info); } for (TfBImpicInfo info:objects){ System.out.println(info); }}
<a name="m5BZD"></a>
### 6.3.7 布尔查询
对多个查询条件连接
- must (and)条件必须成立
- must_not(not)条件必须不成立
- should(or)条件可以成立
- filter:条件必须成立,性能比must高。不会计算得分
get person/_search{ “query”:{ “bool”:{ “must”:[{}], “filter”:[{}] } } }
<a name="zzsUE"></a>
### 6.3.8 聚合脚本
- 指标聚合:相当于mysql的聚合函数。max\min\avg\sum
- 桶聚合:分组
get person/_search{ “query”:{ “match”:{ “title”:”华为” } }, “aggs”:{ “max_price”:{ “max”:{ field”:”price” } } } }
get person/_search{ “query”:{ “match”:{ “title”:”华为” } }, “aggs”:{ “person_brands”:{ “terms”:{ “field”:”brandName”, “size”:100 } } } }
// 聚合查询 @Test public void aggQuery() throws IOException { SearchRequest person = new SearchRequest(“goods”); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 查询title包含手机的数据 MatchQueryBuilder query = QueryBuilders.matchQuery(“title”, “手机”); sourceBuilder.query(query);
// 查询品牌列表 // 参数:自定义的名称,将来用户获取数据。分组的字段 AggregationBuilder agg = AggregationBuilders.terms(“goods_brands”).field(“brandName”).size(100); sourceBuilder.aggregation(agg);
person.source(sourceBuilder);
SearchResponse search = client.search(person, RequestOptions.DEFAULT);
SearchHits hits = search.getHits();
long value = hits.getTotalHits().value;
ArrayList<TfBImpicInfo> objects = new ArrayList<>();
SearchHit[] hitsHits = hits.getHits();
for (SearchHit hit:hitsHits){
// 获取json字符串 String sourceAsString = hit.getSourceAsString(); TfBImpicInfo info = JSONObject.parseObject(sourceAsString, TfBImpicInfo.class); objects.add(info); }
for (TfBImpicInfo info:objects){
System.out.println(info);
}
// 获取聚合结果
Aggregations aggregations = search.getAggregations();
Map
ArrayList<Object> lists = new ArrayList<>();
for (Terms.Bucket bucket :buckets) {
Object key = bucket.getKey();
lists.add(key);
}
for (Object list:lists){
System.out.println(list);
}
}
<a name="s2OtE"></a>
### 6.3.9 高亮查询
高亮三要素:
- 高亮字段
- 前缀
- 后缀
get goods/_search{ “query”:{ “match”:{ “title”:”电视” } }, “highlight”:{ “fields”:{ “title”:{ “pre_tags”:”“, “post_tage”:”“ } } } }
// 高亮查询 @Test public void lightQuery() throws IOException { SearchRequest person = new SearchRequest(“goods”); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 查询title包含手机的数据 MatchQueryBuilder query = QueryBuilders.matchQuery(“title”, “手机”); sourceBuilder.query(query);
// 设置高亮 HighlightBuilder highlightBuilder = new HighlightBuilder(); // 设置三要素 highlightBuilder.field(“title”); highlightBuilder.preTags(““); highlightBuilder.postTags(““);
sourceBuilder.highlighter(highlightBuilder);
// 查询品牌列表 // 参数:自定义的名称,将来用户获取数据。分组的字段 AggregationBuilder agg = AggregationBuilders.terms(“goods_brands”).field(“brandName”).size(100); sourceBuilder.aggregation(agg);
person.source(sourceBuilder);
SearchResponse search = client.search(person, RequestOptions.DEFAULT);
SearchHits hits = search.getHits();
long value = hits.getTotalHits().value;
ArrayList<TfBImpicInfo> objects = new ArrayList<>();
SearchHit[] hitsHits = hits.getHits();
for (SearchHit hit:hitsHits){
// 获取json字符串
String sourceAsString = hit.getSourceAsString();
TfBImpicInfo info = JSONObject.parseObject(sourceAsString, TfBImpicInfo.class);
// 获取高亮结果,替换goods中的title
Map
// 替换 info.setTitle(fragments[0].toString());
objects.add(info);
}
for (TfBImpicInfo info:objects){
System.out.println(info);
}
}
<a name="ztLAc"></a>
## 6.4 索引别名和重建索引
<a name="afWf9"></a>
### 6.4.1 重建索引
随着业务需求的变更,索引的结构可能发生改变<br />es的索引一旦创建,只允许添加字段,不允许改变字段。<br />因为改变字段,需要重建倒排索引,影响内部缓存结构,性能太低。<br />此时,需要重建一个新的索引,并将原有索引的数据导入到新索引中
put student_index_v1{ “mappings”:{ “properties”:{ “birthday”:{ “type”:”date” } } } }
get student_index_v1
put student_index_v1/_doc/1{ “birthday”:”1999-01-01” }
业务变更了,需要改变birthday的字段类型 创建新的索引:student_index_v2 将数据student_index_v1拷贝student_index_v2里
put student_index_v2{ “mappings”:{ “properties”:{ “birthday”:{ “type”:”text” } } } }
_reindex拷贝数据 post _reindex{ “source”:{ “index”:”student_index_v1” }, “dest”:{ “index”:”student_index_v2” } }
get student_index_v2
get student_index_v1 put student_index_v1/_doc/2{ “birthday”:”1999年01月01日” }
Java操作es,他现在使用的是student_index_v1
- 改代码(不推荐)
- 索引别名(推荐)
<a name="WnmNZ"></a>
### 6.4.2 索引别名
1. 先删除student_index_v1
1. 给student_index_v2起别名。student_index_v1
delete student_index_v1
post student_index_v2/_alias/student_index_v1
get student_index_v1/_search
<a name="qXhKv"></a>
# 7 集群
<a name="yvnGk"></a>
## 7.1 集群介绍
- 集群:多个人做一样的事
- 分布式:多个人做不一样的事
集群解决的问题:
1. 让系统高可用
1. 分担请求压力
分布式解决的问题:
1. 分担存储和计算的压力,提速
1. 解耦
<a name="l1k4P"></a>
## 7.2 相关概念
- 集群cluster:一组拥有共同的cluster name 的节点
- 节点node:集群中的一个es实例
- 索引index:es存储数据的地方,相当于关系数据库中的database概念
- 分片shard:索引可以被拆分为不同的部分进行存储,成为切片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
- 主分片primary shard:相对于副本分片的定义
- 副本分片repilica shard:每个主分片可以有一个或者多个副本,数据和主分片一样
<a name="G45u4"></a>
## 7.3 搭建集群
1. 将安装包复制三份,分别起名
1. 修改elasticsearch.yml文件
1. 启动三个节点
<a name="JgARa"></a>
## 7.4 集群原理
- 在集群管理中,默认主分片
- 在创建索引时。如果不指定分片配置。默认主分片1,副本分片1
- 在创建索引时。可以通过settings设置分片
“setting”:{ “number_of_shards”:1, “number_of_replicas”:1 } ```
- 分片与自平衡:当节点挂掉后,挂掉的节点分片会自平衡到其他节点中
- 在es中,每个查询在每个分片的单个线程中执行,但是,可以并从处理多个分片
- 分片数量一旦确定好,不能修改
索引分片推荐的配置方案:
- 每个分片推荐大小10-30gb
- 分片数量推荐=节点数量*1-3倍
7.5 路由原理
- 文档存入对应的分片,es计算分片编号的过程,成为路由
- es是怎么知道一个文档应该存放到那个分片中呢?
- 查询时,根据文档id查询文档,es又该去那个分片中查询数据呢?
- 路由算法:shard_index=hash(id)%number_of_primary_shards
7.6 脑裂
- 一个正常es集群中只有一个主节点,主节点负责管理整个集群,如创建或删除索引,跟踪那些节点是集群的一部分,并决定哪些分片分配给相关的节点
- 集群的所有节点都会选择同一个节点作为主节点
- 脑裂问题的出现就是因为从节点在选择主节点上出现分歧导致一个集群出现多个主节点从而使集群分裂,使得集群处于异常状态
7.6.1 脑裂的原因
- 网络原因:网络延迟
- 一般es集群会在内网部署,也可能在外网部署,比如阿里云
- 内网一般不会出现此问题,外网的网络出现的可能性比较大
- 节点负载:
- 主节点的角色即为master又为data。数据访问量较大时,可能会导致master节点停止响应(假死状态)
- jvm内存回收:
- 当master节点设置的jvm内存较小时,引发jvm的大规模内存回收。造成es进程失去响应
7.6.2 避免脑裂
- 网络原因:discovery.zen.ping.timeout超时时间配置大一点,默认3s
- 节点负载:角色分离策略
- 候选主节点配置为
- node.master:true
- node.data:false
- 数据节点配置为
- node.master:false
- node.data:true
- 候选主节点配置为
- jvm内存回收:修改config/jvm.options文件的-Xms 和-Xmx为服务器的内存一半

若有收获,就点个赞吧
0 人点赞
