一、简介+链接
针对人群计数这个挑战,现有的人群密度图回归是不是最优解决方案?针对小尺度高密集场景,检测技术是否还有用武之地?针对更为廉价的人头中心点标注,我们还能做检测吗?本文展示了一项全新的范式,来解答上述几个问题。
资源链接:
二、看论文中补充的小知识点
1、匈牙利匹配算法(最大匹配)
解决问题:
无权重的二分图的最大匹配问题。(不求最合适,但求匹配最多)
使用方法:
依次匹配,有机会就上,没机会创造条件也要上(后来的抢,前来的让)
学习资料:
- 知乎——带你入门多目标跟踪(三)匈牙利算法&KM算法
-
2、KM算法(Kuhn-Munkres Algorithm)(完美匹配)
解决问题:
带权二分图的最优匹配问题。(力求匹配最合适)
使用方法:
依次匹配,找最完美的。
只和权重与左边分数(顶标)相同的边进行匹配,若找不到边匹配,对此条路径的所有左边顶点的顶标减d,所有右边顶点的顶标加d。参数d我们在这里取值为0.1。
学习资料: -
3.NMS(非极大值抑制)
解决问题:
非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的元素,用于目标检测中,就是提取置信度高的目标检测框,而抑制置信度低的误检框。
使用方法:
一般来说,用在当解析模型输出到目标框时,目标框会非常多,具体数量由anchor数量决定,其中有很多重复的框定位到同一个目标,nms用来去除这些重复的框,获得真正的目标框。如下图所示,人、马、车上有很多框,通过nms,得到唯一的检测框。
方法分为:标准nms、soft-nms、adaptive nms。(具体见学习资料)
4.patch-level、pixel-level
概念:
patch-level:补丁级别的,介于像素和图像之间,也就是块;
pixel-level:像素级别的。像素是图像的基本单位;
image-level:图像级别,一张图;
参考资料:
图像分割中的一些术语,pixel-wise,patch-wise,image-wise
5.欧几里得距离
概念:
两点之间的距离。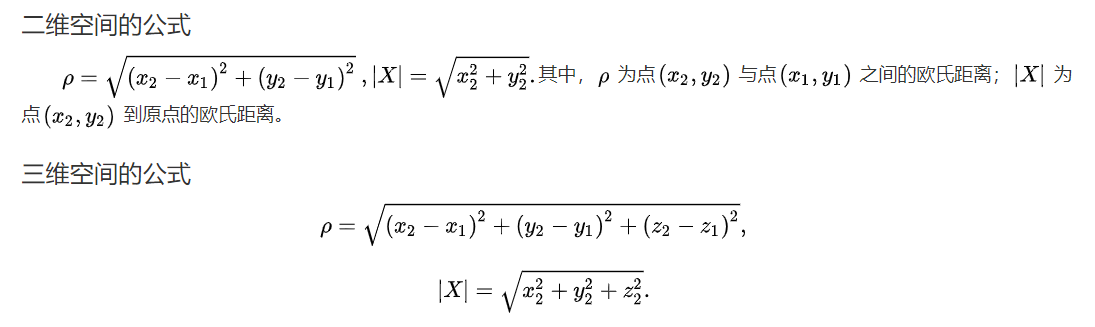
参考资料:
欧几里得距离是什么—知乎
三、论文阅读
1.论文创新点
- 提出了一种新框架:这个框架基于点,不仅能实现人群计数,而且能在人群中定位个体。该框架鼓励细粒度(个人)的预测,可以满足异常行为检测等更高级的任务;
- 提出了一种新度量:density Normalized Average Precision (nAP),密度归一化平均精度,进行性能评估。关注到人群中密度变化,添加了重复预测的惩罚;
- 提出了一种新的解决方案:Point to Point Network(P2PNet)。省去多余步骤,直接预测一组点建议来表示人头,采用了匈牙利匹配算法。精度最优,定位良好,也可激励其他依赖点的任务。
2.创新点展开学习
(1)新框架:不仅实现人群计数还能定位个体
(2)密度归一化平均精度
- 将预测点按置信度从高到低的顺序,依次判断是TF还是FP;
- 只有预测点与地面真实点匹配时,才能被判断为TP。在此之前,该地面真实点不能与其他置信度更高的预测点匹配;
- 匹配过程的公式
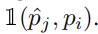 和相关参数介绍如下图所示:
和相关参数介绍如下图所示: 黄圈、蓝圈、红圈分别代表阈值(σ)为1、0.5和0.25的区域;
黄圈、蓝圈、红圈分别代表阈值(σ)为1、0.5和0.25的区域;
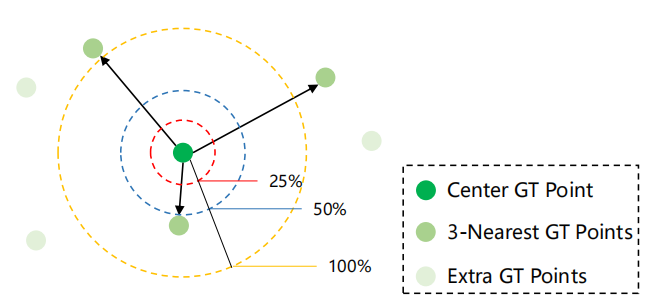

使用一对一的关联匹配策略。并且除了像素距离外,在参考标准中也加入置信度。
原文描述: 围绕同一地面真实点的两个预测建议。如果他们有相同的置信度,接近pi的应该匹配为正,并鼓励获得更高的定位精度。而另一个建议应该被匹配为负的,并被监督以降低其置信度,因此在下一次训练迭代中可能不会再次匹配。相反,如果这两种建议与圆周率的距离相同,则具有更高信心的建议应该被训练为具有更高的信心。上述两种情况都将鼓励积极的建议有更准确的位置和相对较高的信心,这有利于在拟议的框架下改进nAP。
(3)P2PNet
a.一对一关联策略
b.损失函数
c.网络结构
四、代码阅读
1、环境配置
阅读readme.md文件
The codes is tested with PyTorch 1.5.0. It may not run with other versions.
Installation
- Clone this repo into a directory named P2PNET_ROOT
- Organize your datasets as required
- Install Python dependencies. We use python 3.6.5 and pytorch 1.5.0
pip install -r requirements.txt
Organize the counting dataset
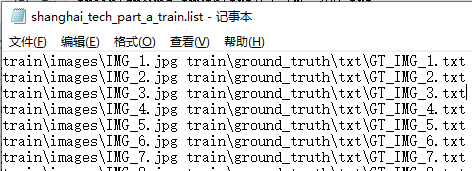
We use a list file to collect all the images and their ground truth annotations in a counting dataset. When your dataset is organized as recommended in the following, the format of this list file is defined as:
我们使用列表文件来收集计数数据集中的所有图像及其基本事实注释。当数据集按照以下建议进行组织时,此列表文件的格式将定义为:
train/scene01/img01.jpg train/scene01/img01.txt train/scene01/img02.jpg train/scene01/img02.txt … train/scene02/img01.jpg train/scene02/img01.txt
Dataset structures:
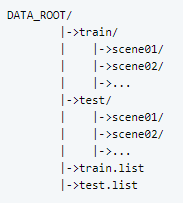
DATA_ROOT is your path containing the counting datasets.
DATA_ROOT是包含计数数据集的路径。
Annotations format
For the annotations of each image, we use a single txt file which contains one annotation per line. Note that indexing for pixel values starts at 0. The expected format of each line is:
对于每个图像的注释,我们使用单个 txt 文件,该文件每行包含一个注释。请注意,像素值的索引从 0 开始。每行的预期格式为:
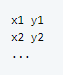
Training
The network can be trained using the train.py script. For training on SHTechPartA, use
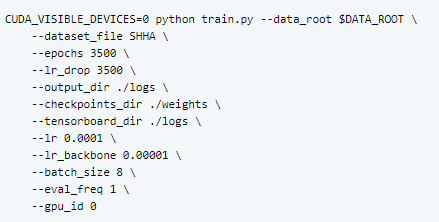
By default, a periodic evaluation will be conducted on the validation set.
Testing
SHTechPartA 上的训练模型(MAE 为 51.96)位于”./weights“,运行以下命令以启动可视化演示:
CUDA_VISIBLE_DEVICES=0 python run_test.py —weight_path ./weights/SHTechA.pth —output_dir ./logs/
Acknowledgements
- 部分代码借用自C^3 框架。
- 我们参考DETR来实施我们的匹配策略。
Citing P2PNet(引用代码)
If you find P2PNet is useful in your project, please consider citing us:@inproceedings{song2021rethinking,
title={Rethinking Counting and Localization in Crowds: A Purely Point-Based Framework},
author={Song, Qingyu and Wang, Changan and Jiang, Zhengkai and Wang, Yabiao and Tai, Ying and Wang, Chengjie and Li, Jilin and Huang, Feiyue and Wu, Yang},
journal={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2021} }
Related works from Tencent Youtu Lab
- [AAAI2021] To Choose or to Fuse? Scale Selection for Crowd Counting. (paper link & codes)
- [ICCV2021] Uniformity in Heterogeneity: Diving Deep into Count Interval Partition for Crowd Counting. (paper link & codes)
2.配置过程中遇到的问题
1)引入包问题
包之间有版本依赖,用anaconda管理版本2)其他问题
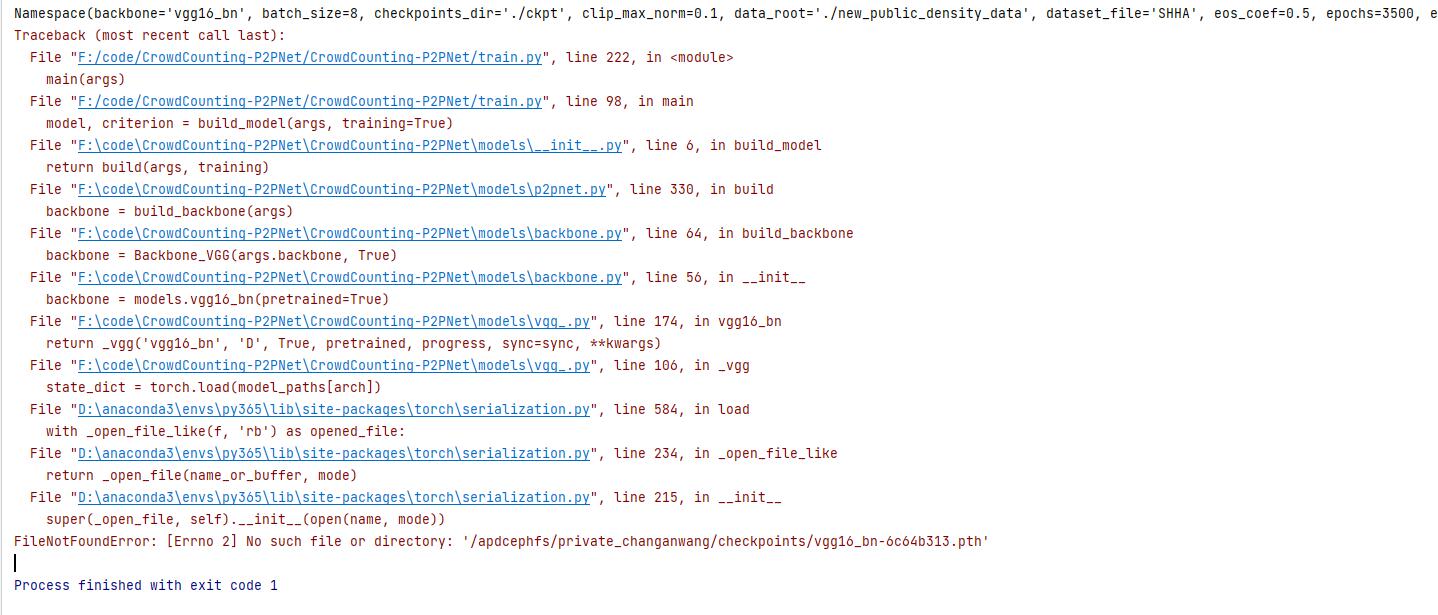
问题1:找不到vgg16的.pth文件
 参考文献:
VGG网络的Pytorch官方实现过程解读
pytorch 预训练模型下载
pytorch官网预训练模型百度云下载 VGG16,Densnet169,inception_v3
pytorch 从本地加载 .pth 格式模型
解决办法:
参考文献:
VGG网络的Pytorch官方实现过程解读
pytorch 预训练模型下载
pytorch官网预训练模型百度云下载 VGG16,Densnet169,inception_v3
pytorch 从本地加载 .pth 格式模型
解决办法:- 先找到代码位置:
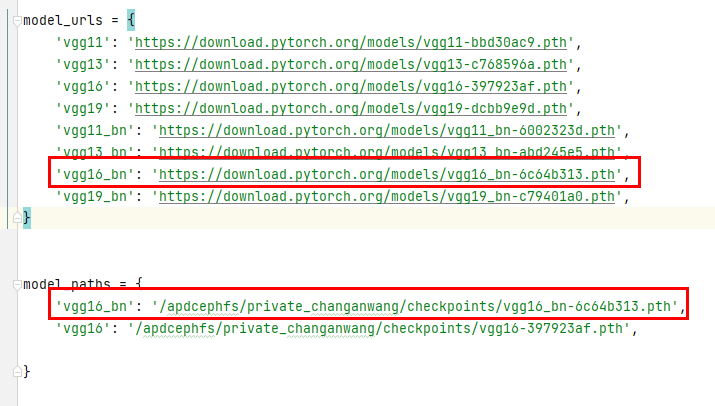
- 下载 ‘vgg16_bn-6c64b313.pth’ 文件:’https://download.pytorch.org/models/vgg16_bn-6c64b313.pth‘
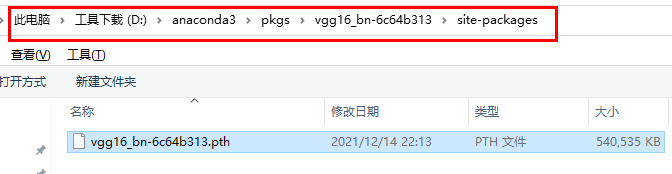
- 把他放在文件夹下(此处我参考计算机中.pth文件的存放规律):
- 代码中路径修改:

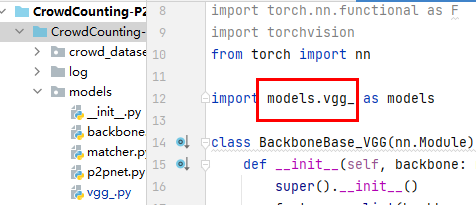
问题2:本项目的包引用失败
参考文献: 解决python中import时无法识别自己写的包和模块的方法 这种问题可以用下面的方法解决: 1)打开File—》Setting—》打开 Console下的Python Console,把选项(Add source roots to PYTHONPAT)点击勾选上 2)右键点击自己的工作空间,找下面的Mark Directory as 选择Source Root,就可以解决上面的问题了!
问题3:数据集问题
参考文献: shanghaiTech 数据集详细介绍 shanghai-tech数据集下载地址 见上文中四-1-Organize the counting dataset的数据存放设置
解决办法:
- 先下载数据集
- 从参考文献中的图可知DATA_ROOT是放数据集的地址。查看代码,找好位置,放上数据集,改下文件名
- 因为此论文数据集需要的标注是txt的,但是下载的数据集的标注是.mat格式的,所以先下载个matlab,并且将.mat格式的变成.txt格式的,格式见上文中四-1-Annotations format的标签格式。
参考文献: MATLAB下载和破解-语雀 《MATLAB的基本语法》-语雀 最后完整版代码—《MATLAB的存取》-语雀 最后实现的效果如下所示:把.mat数据按要求存成.txt
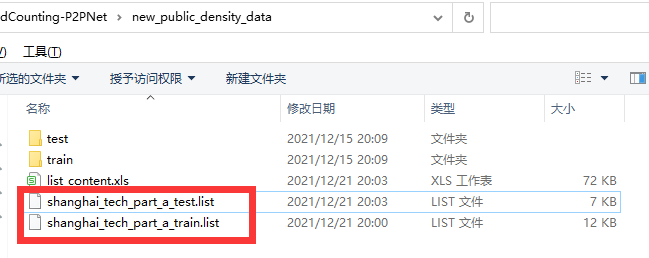
- 从参考文献中的图可知需要有list文件,去代码中找到list文件的命名,然后创建好list文件

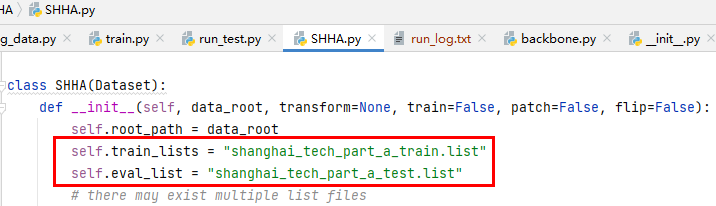
问题4:训练过程中的问题
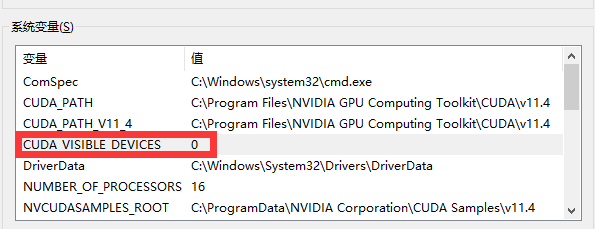
- 不是内部文件错误
参考资料:解决报错:‘CUDA_VISIBLE_DEVICES‘ 不是内部或外部命令,也不是可运行的程序或批处理文件。 解决办法:将CUDA_VISIBLE_DEVICES=0设成环境变量,然后删除换行,变成同一行的命令
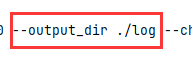
- 文件路径
解决办法:给的参数有误,参数里面的路径修改一下,从logs改成log
- 数据集路径报错
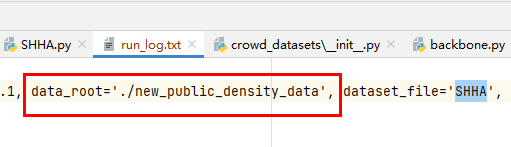
将指令修改一下,’$DATA_ROOT’改成具体的路径’./new_public_density_data’
- 修改后的训练指令:
python train.py —data_root ./new_public_density_data —dataset_file SHHA —epochs 3500 —lr_drop 3500 —output_dir ./log —checkpoints_dir ./weights —tensorboard_dir ./log —lr 0.0001 —lr_backbone 0.00001 —batch_size 8 —eval_freq 1 —gpu_id 0 5.训练多轮中的报错:

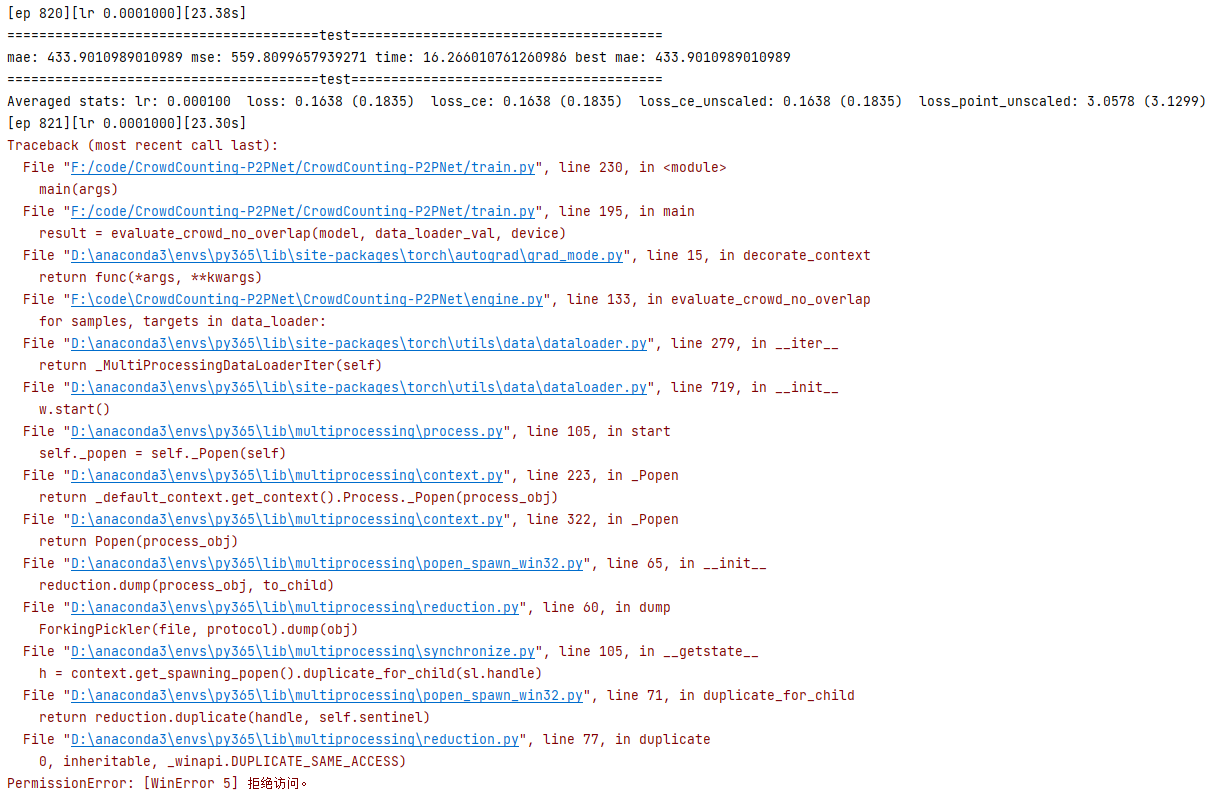
问题5:PermissionError: [WinError 5] 拒绝访问。
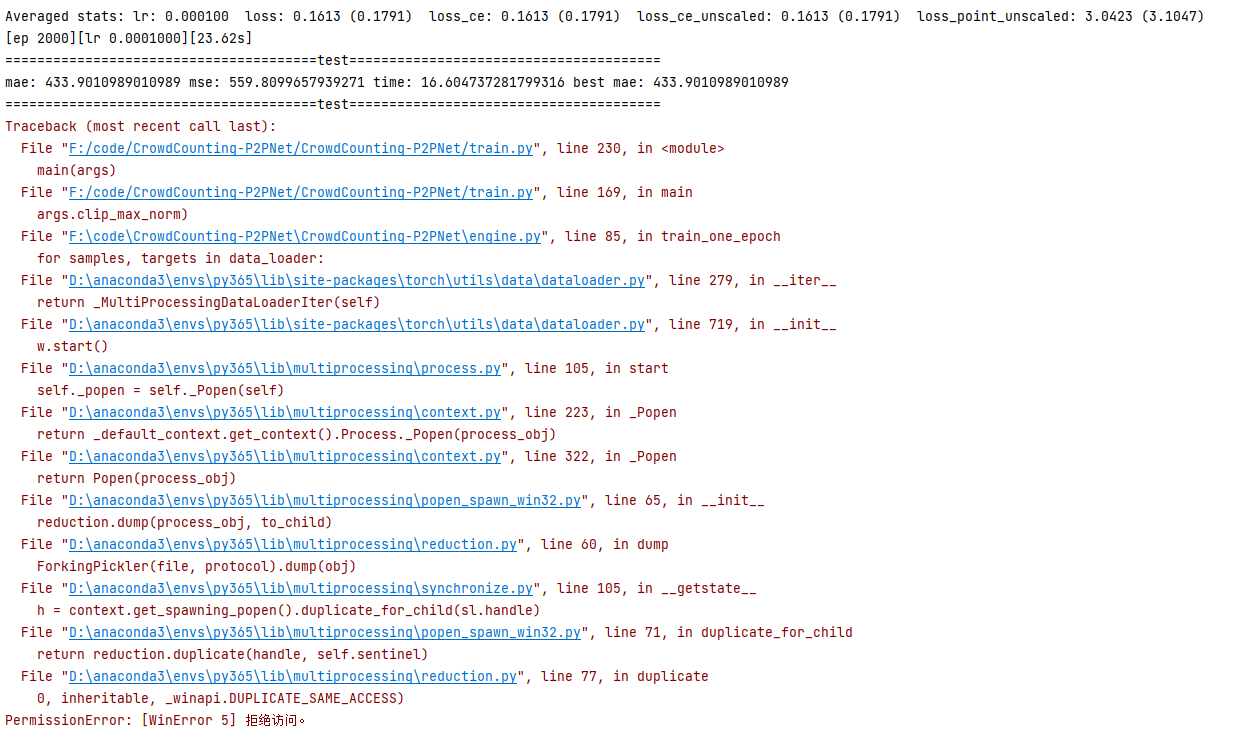
参考资料:
三步解决python PermissionError: [WinError 5]拒绝访问的情况 PermissionError: [WinError 5] 拒绝访问。解决办法
解决办法:
- 第一步:
关闭跟python相关的所有程序,如jupyter,pycharm,Anaconda等等,这一步非常重要!!! 好了,第一步完成下面开始常规操作的两步:
- 第二步:
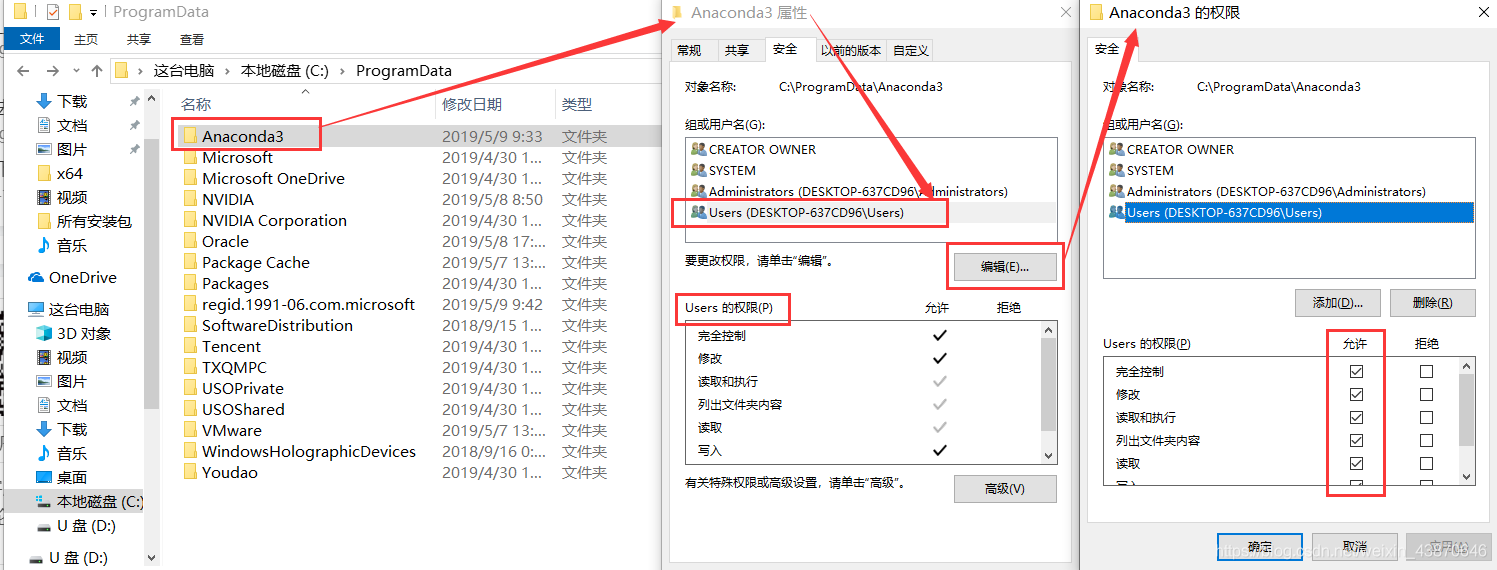
赋予用户对python的“完全控制”的权限,步骤如下: 找到按照python的位置,本文用的是Anaconda,安装在D盘,位置为:D:\Anaconda3。找到python- 右键- 属性- 安全- 点击“组或用户名”中的Users- 编辑- 点击点击“组或用户名”中的Users- 把“完全控制”打钩- 应用- OK
- 第三步:
执行完第二步一般就能解决问题。如果还没解决问题的话,请执行第三部,找到你安装python的文件夹,本人用的是Anaconda3,那么就直接对该文件夹(本人安装位置为D:\Anaconda3),右键属性,按照第二步的方法执行一遍就OK了!
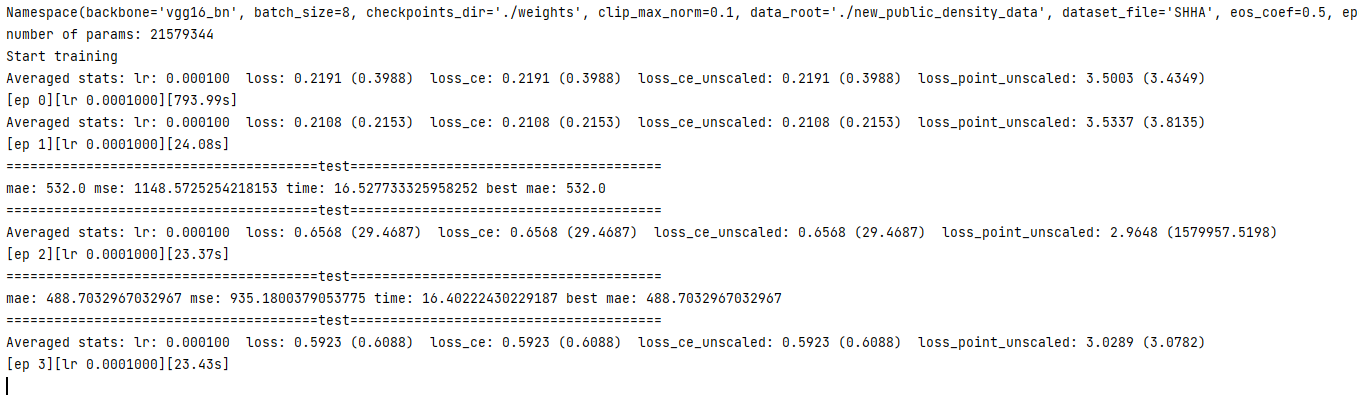
3.最后成果

若有收获,就点个赞吧
0 人点赞
