一、人群统计的数据集
人群统计数据集
UCSD
UCSD 数据集是最早的人群计数数据集之一, 它从一个人行道上的摄像机中采集。该数据集由来自一个视频序列的 2 000 个尺寸为 238×158 的帧和每五帧中每 个行人的注释组成,其中包含 49 885 个行人实例。 下载链接为:http://visal.cs.cityu.edu.hk/downloads/
Mall
该数据集是在购物中心收集的,它由 200 个尺寸 为 320×240 的帧组成,共包含 62 325 名行人。与 USCD 相 比,该数据集覆盖了更多不同的照明条件、更多的密度水 平以及不同的活动模式,其具有更大的透视失真及更严重的遮挡。 下载链接为:http://personal.ie.cuhk.edu.hk/~ccloy/downloads_mall_dataset.html
UCF_CC_50
UCF_CC_50是第一个真正具有挑战性 的数据集。它由来自公共网站的 50 幅分辨率不同的 Web 图像组成,共包含 63 075 个被标记的个体。该数据集中的 · 250 ·第 8 期 图像具有较大的密度差异,但其偏少的图像数量也给研究 人员使用带来了不便。 下载链接为:http://download.csdn.net/detail/qq_14845119/9800218
WorldExpo’10
WorldExpo’10 是一个 大型跨场景人群计数数据集,主要收集自上海世博会。它 由 1 132 个由 108 个监控摄像头拍摄的带注释的视频序列 组成,共有 3 920 个尺寸为 576×720 的帧,有 199 923 个被标 记的行人。
ShanghaiTech
ShanghaiTech 是近几年 大规模人群统计数据集之一,由 1 198 幅图像和 330 165 个 注释组成。其被分为两部分,A 部分是从网上随机选取的 图片,具有较高的密度,B 部分图片是在上海市一条街道上 拍摄的。该数据集覆盖了不同场景类型和不同密度级别, 其复杂的尺度变化与透视失真也为研究人员带来了新的挑战。下载链接为:https://www.datafountain.cn/datasets/5670
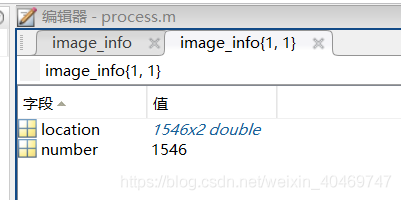
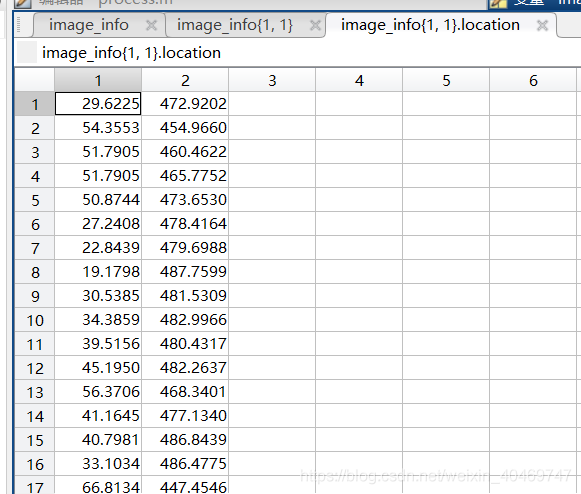
详细数据集介绍:shanghaiTech 数据集详细介绍 A部分训练集:300张图片,测试集:182张图片。
B部分训练集:400张图片,测试集:316张图片。 ground_trust里面是人头的坐标。适合用在密度图解法中。用matlab打开,里面是人头注释

UCF-QNRF
包含1535张图像,人数从49到12865不等,相较于其他几个主流人群密度估计数据集最新且注释量最大。下载链接为:https://www.crcv.ucf.edu/data/ucf-qnrf/
NWPU-Crowd 数据集
NWPU-Crow d 数据集是西北工业大学于 2020 年发表 的大型人群计数图像数据库,包括 5 109 张图像,平均分辨率为 2 191 × 3 209,平均人群计数数量为 418。
github:https://github.com/gjy3035/NWPU-Crowd-Sample-Code
链接:https://paperswithcode.com/dataset/nwpu-crowd
计数:
location:
PETS2009
第11届国际跟踪与监控性 能评价研讨会上引入的数据集,包含3个不同的人 群场景S1、S2和S3,其中S1主要 用 于 人 数 统 计 和密度估计,S2用于 行 人 跟 踪,S3用于 光 流 分 析 以及事件识别。 下载链接为:http://www.cvg.reading.ac.uk/PETS2009/a.html
Fudan
录制于上海复旦大学光华楼的入口,总共1500帧,被分为5个不同 的 部 分。这个数据集不仅提供了原图像,而且还提供了分割出的前景二值图,以及一些提取的人群特征供研究者使用。
GrandCentral
由香港中文大学Zhou提供,拍摄了一段包含33min的纽 约 中央火车站的人群视频,监控的范围比较大,且行人比较多。
Chunxi_Road
由成都电子科技大学的付敏提供,拍摄于春熙路,包含的行人比较多,且行人姿态(有运动的也有静止的)和着装各异,该数据集更接近于真实的人群场景。
乱糟糟
1、王小刚教授整理的好多数据集:http://www.ee.cuhk.edu.hk/~xgwang/王小刚
2、http://personal.ie.cuhk.edu.hk/~ccloy/download.html :有CUHK Crowd Dataset数据集 吕健勤
3、http://vcis.ahu.edu.cn:8080/安徽大学,这个数据集已经给了标注
4、http://blog.csdn.net/zhuiqiuk/article/details/73497982
Caltech行人
数据库
http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/
该数据库是目前规模较大的行人数据库,采用车载摄像头拍摄,约10个小时左右,视频的分辨率为640×480,30帧/秒。标注了约250,000帧(约137分钟),350000个矩形框,2300个行人,另外还对矩形框之间的时间对应关系及其遮挡的情况进行标注。数据集分为set00~set10,其中set00~set05为训练集,set06~set10为测试集(标注信息尚未公开)。性能评估方法有以下三种:(1)用外部数据进行训练,在set06~set10进行测试;(2)6-fold交叉验证,选择其中的5个做训练,另外一个做测试,调整参数,最后给出训练集上的性能;(3)用set00~set05训练,set06~set10做测试。由于测试集的标注信息没有公开,需要提交给Pitor Dollar。结果提交方法为每30帧做一个测试,将结果保存在txt文档中(文件的命名方式为I00029.txt I00059.txt ……),每个txt文件中的每行表示检测到一个行人,格式为“[left, top,width, height, score]”。如果没有检测到任何行人,则txt文档为空。该数据库还提供了相应的Matlab工具包,包括视频标注信息的读取、画ROC(Receiver Operatingcharacteristic Curve)曲线图和非极大值抑制等工具。
CUHK Occlusion Dataset
中大遮挡数据集用于活动分析和拥挤场景的研究。该数据集包含来自 Caltech [1] 、ETHZ [2] 、TUD-Brussels [3] 、INRIA [4] 、Caviar [ 5]和我们收集的图像数据集的 1063 张 被遮挡的行人图像。它分为10 个剪辑,可以从以下链接下载。http://www.ee.cuhk.edu.hk/~xgwang/CUHK_pedestrian.html
JHU-CROWD
包含 4,250 张图像和 111 万条注释。该数据集是在各种不同的场景和环境条件下收集的。具体来说,除了许多干扰图像之外,该数据集还包括多个具有基于天气的退化和光照变化的图像,使其成为一个非常具有挑战性的数据集。此外,该数据集由图像级和头部级的丰富注释组成。(同页还有应用此数据集的论文以及其他相似数据集)下载链接:https://paperswithcode.com/dataset/jhu-crowd
论文:https://arxiv.org/pdf/1910.12384v1.pdf
数据集环境/场景/人数复杂,而且也包含了一些无人场景。 在图像级和头部级都收集了更丰富的注释集。 头部标注包括头部的x、y位置以及对应的遮挡水平、模糊水平和大小水平。遮挡标签有三个级别:{未遮挡,部分遮挡,完全遮挡}。模糊blur级别有两个标签:{Blur, no-blur}。 由于获得尺寸是一个更困难的问题,每个头都用尺寸指示器标记。标注者被要求先用边框标注图片中最大和最小的头部。然后,注释器被要求为图像中的每个头部分配一个大小级别,这样这个大小级别就表示了与最大和最小的注释边界框的相对大小。 图像级注释包括标签(如马拉松、商场、步行、体育场等)和捕捉图像时的天气条件。数据集中点级注释的总数为1,114,785个。

JHU-CROWD++
大规模无约束人群统计数据集,具有4,372张图像和151万注释的综合数据集。与现有数据集相比,在各种不同的场景和环境条件下收集了所提出的数据集。此外,数据集还提供了相对更丰富的注释集,如点、近似边界框、模糊级别等。
下载链接:http://www.crowd-counting.com/
提出此数据集的文章: JHU-CROWD++: Large-Scale Crowd Counting Dataset and A Benchmark Method
数据集亮点
- 包括几幅具有基于天气的退化和光照变化的图像,使其成为一个非常具有挑战性的数据集。此外,该数据集包含图像级别和头部级别的丰富注释。
- 提供头部级别的标签(点、近似边界框、模糊级别等)和图像级别的标签(场景类型和天气状况)。
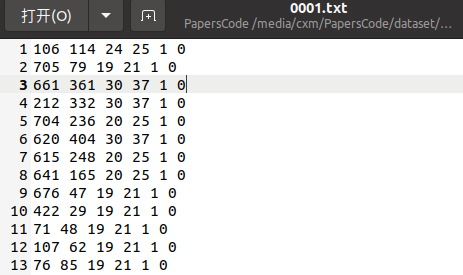
head-level标注示例:(点、近似边界框、模糊级别)
标注中:
- 头级/点级注释包括x , y头部位置和相应的遮挡级别、模糊级别和大小级别。数据集中的点级注释总数为 1,515,005。遮挡标签分为三个级别:{未遮挡、部分遮挡、完全遮挡}。模糊级别有两个标签:{ blur, no-blur }。在 JHU-CROWD 中,每个头部都标有一个大小指示器。我们通过为每个头部注释提供“近似”大小(宽度和高度)来改进这些大小注释。为了获得这些,注释者被指示为一组具有相似大小的相邻头部注释边界框。请注意,这些边界框只是“近似的”,不如检测数据集中的边界框准确。上图说明了我们数据集中提供的示例注释。
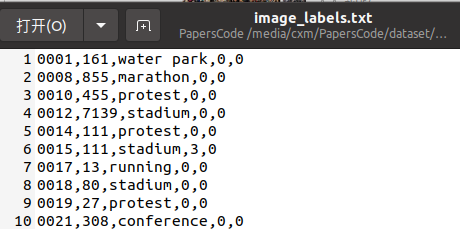
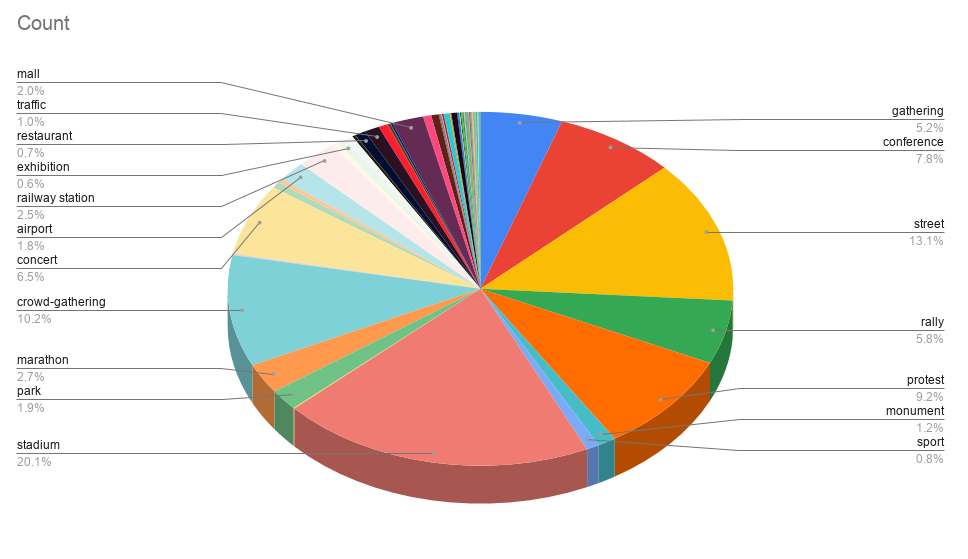
- 图像级标注包括场景标签(如马拉松、商场、火车站、体育场等)和天气标签(雨、雪和雾)。下图 说明了所提出数据集中场景标签的分布。
 图片标签展示:
图片标签展示:
CUHK-SYSU(行人检测和人群重定位)
CUHK-SYSU 是一个大规模的人员搜索基准数据集,包含18184张图像和8432个行人,以及99,809个标注好的边界框。根据图像来源,数据集可分为在街道场景下采集和影视剧中采集两部分。在街道场景下,图像通过手持摄像机采集,包含数百个场景,并尝试尽可能的包含不同的视角、光线、分辨率、遮挡和背景等。另一部分数据集采集自影视剧,因为它们可以提供更加多样化的场景和更具挑战性的视角。
该数据集为行人检测和人员重识别提供注释。每个查询人会出现在至少两个图像中,并且每个图像可包含多个查询人和更多的其他人员。数据集被划分为训练集和测试集。训练集包含11206张图片和5532个查询人,测试集包含6978张图片和2900个查询人。更多信息可参考:End-to-End Deep Learning for Person Search
WiderPerson 数据集
WiderPerson 数据集是野外行人检测基准数据集,其图像选自广泛的场景,不再局限于交通场景。我们选择了 13,382 张图像并标记了大约 400K 带有各种遮挡的注释。我们随机选择 8000/1000/4382 图像作为训练、验证和测试子集。与 CityPersons 和 WIDER FACE 数据集类似,我们不发布测试图像的边界框基本事实。用户需要提交最终的预测文件,我们将进行评估。数据集下载地址:http://m6z.cn/6nUs1C
加州理工学院行人检测数据集
加州理工学院行人数据集由大约 10 小时的 640x480 30Hz 视频组成,该视频取自在城市环境中通过常规交通行驶的车辆。注释了大约 250,000 帧(在 137 个大约分钟长的片段中),总共 350,000 个边界框和 2300 个独特的行人。注释包括边界框和详细的遮挡标签之间的时间对应关系。数据集下载地址:http://m6z.cn/5N3Yk7
小目标检测数据集
- TinyPerson数据集:在 TinyPerson 中有 1610 个标记图像和 759 个未标记图像(两者主要来自同一视频集),总共有 72651 个注释。数据集下载地址:http://m6z.cn/6vqF3T

二、评价指标
1、平均绝对误差 MAE、均方误差 MSE
为了评估模型的计数性能及密度估计性能,引入平均绝对误差 MAE 和均方误差 MSE,定义如下: 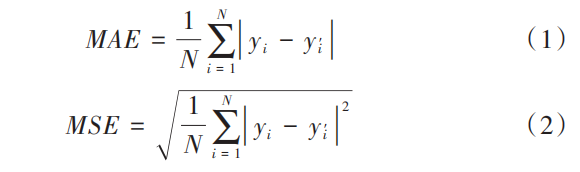
其中,N 是测试样本的数量,yi 是样本的真实计数值,y’i 是经模型估计得到的与 yi 相对应的计数值。
MAE 和 MSE 可以分别在一定程度上反映模型的准确性与稳健性。一般情况下,两个误差的值越小表明模型的性能越理想。
2、平均偏差误差MDE
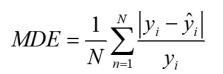
其中N为视频中选取帧的总数,yi 为第i帧密度真实值,^yi为第i 帧的密度估计值。
MDE不仅能评测算法性能,还可以反映出密度的变化,因此被大量用于评价人数统计算法。
对于人群密度估计,常常被看作是一个分类问题,因此一般都用正确率来评价算法的性能。
3、峰值信噪比PSNR、结构相似性指数SSIM
为了评估模型生成的密度图质量,引入峰值信噪 比(PSNR)和结构相似性指数(SSIM)。
- PSNR 用来衡量处理后的图像与原始图像之间的误差,一般 PSNR 值越高表明误差越小。同时,受外在因素及人类视觉局限性影响, PSNR 值可能与人们对图像品质的主观感受不完全一致。
- SSIM 用来评价估计的密度图与实际密度图间的局部模式一致性,它用亮度、对比度与结构相似度 3 个因子来衡量图像质量,并分别将均值、标准差和协方差看作3个因子的度量,根据3个局部统计量计算出两幅图像之间的相似性。 其范围为 0 到 1,一般 SSIM 为 1 即表明两个图像相同。
三、资源库
1.数据集及下载地址
图像数据库与下载地址——CSDN
香港城市大学收集的数据集与下载地址
数据集与论文对应网页
datafountain,有各种数据集
上面有些做成种子的数据集2.论文、代码资源库
人群计数超全资源,包含代码、工具、数据集、论文(有顶会的)、leaderboard等——github版
人群计数超全资源,包含代码、工具、数据集、论文(有顶会的)、leaderboard等——文章版
AI顶会所有文章下载地址
计算机视觉资源大全——包含论文、新手入门等一系列资源
收集论文+代码的网站——dblp
四、参考文献
- 人群密度估计综述_江中华
- 人数统计与人群密度估计技术研究现状与趋势_张君军
- 基于CNN的人群计数与密度估计研究综述_钮嘉铭
- 基于计算机视觉的目标计数方法综述_蒋妮
- 基于卷积神经网络的人群计数算法研究_向飞宇
- 基于卷积神经网络的人群密度估计综述_白若楷
- 基于生成对抗网络的人群密度估计算法研究_沈赞

若有收获,就点个赞吧
0 人点赞
