TransCrowd:使用 Transformer 进行弱监督人群计数-2021
https://paperswithcode.com/paper/transcrowd-weakly-supervised-crowd-counting 文章链接:https://arxiv.org/abs/2104.09116 代码链接:https://github.com/dk-liang/TransCrowd 讲解链接:https://zhuanlan.zhihu.com/p/366275398
新增知识点
transformer中的token
参考资料:
视觉Transformer中的token具体指什么,如何理解? - 教练我想学CV的回答 - 知乎 用transformer做视觉,具体是怎么把图片转成token的?-知乎提问 transform中的token理解(单词或词语的标记)
理解:
token可以是一个像素、一块图像等,传统做法是把图像切割成一个个patch,每个patch是一个token,但是需要将每个patch进行处理后才是token,常见的处理是将其进行FC(线性连接)
别人的理解:
所以ViT把一张图切分成一个个16x16的patch(具体数值可以自己修改)每个patch看作是一个token,这样一共就只有(224/16)(224/16)=196个token了。当然了,单单的切分还不够,还要做一个线性映射+位置编码等等。不同的Transformer在处理细节上也会有不同,比如最近看的Swin-T加入了多尺度,从最开始的44的patch缩放到后边的32*32
代码
运行代码遇到的问题
问题1:路径中”\“转’/‘
问题描述:
相关代码: path_sets = [img_train_path, img_test_path] #这两路径在这段代码之上定义了
img_paths = []
for path in path_sets:
for img_path in glob.glob(os.path.join(path, ‘*.jpg’)):
img_path = img_path.replace(‘\‘, ‘/‘)
img_paths.append(img_path)因为图片路径使用 glob.glob(os.path.join(path, ‘*.jpg’)) 使得到的图像路径拼接处有\,而后期地址的切割使用split(‘/‘),因此会出现问题。 网上没有直接教”\“替换成’/‘的,只能自己尝试。
解决办法:
img_path = img_path.replace(‘\‘, ‘/‘)
下面这种方法不生效
img_path = img_path.replace(‘\\‘, ‘/‘)
问题2:RuntimeWarning: invalid value encountered in true_divide
问题描述:
F:/code/TransCrowd-main/data/predataset_qnrf.py:93: RuntimeWarning: invalid value encountered in true_divide density_map = density_map / np.max(density_map) * 255
解决办法:
参考链接: 解决RuntimeWarning: invalid value encountered in true_divide 在运行程序时出现 RuntimeWarning: invalid value encountered in true_divide的警告,可能是在使用numpy时出现了0除以0的情况造成的。
在这里的原因: 因为密度图中无人的地方标注为0,所以相除时候必然会出现0除以0的现象,在本代码中没影响。
问题3:Corrupt JPEG data: 21 extraneous bytes before marker 0xd9
问题描述:
错误代码: Corrupt JPEG data: 61 extraneous bytes before marker 0xd9 Corrupt JPEG data: 21 extraneous bytes before marker 0xd9
上面提到了52张照片,这里只截图了一张(1197),这些图片没有生成对应的资料
解决办法:
参考资料: Corrupt JPEG data: 111 extraneous bytes before marker 0xd9… Corrupt JPEG data: 2 extraneous bytes before marker 0x 在OpenCV中使用imread()加载图像时,如何捕获损坏的JPEG? python运行问题记录 使用opencv(python)读取图片时,报如上错误,据说是因为图片破损。try_except未能捕获该警告。 这上面的参考材料给的方法我无法操作,还不知道为啥报这个错,不过感觉好像也没问题。
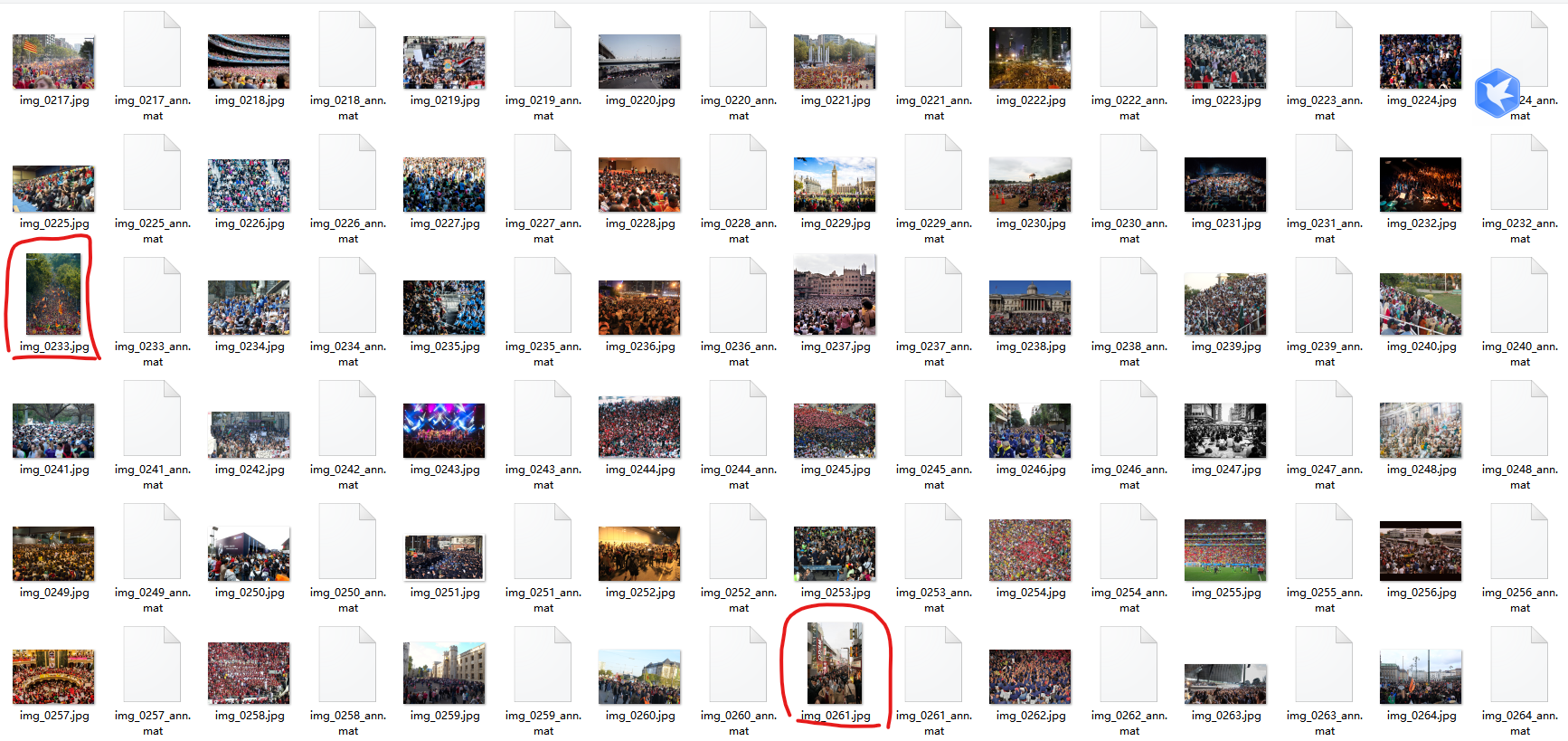
上面说的没生成图片的问题: 根据代码可以判断出,要将原图片压缩成1152768大小的(根据原来的长宽相对大小来调整)。之后再以384384划分成一块块,因为有的图片长>宽,有的相反,所以有的被调整成1152768,有的被调整成7681152。所以必然出现某些下标没有图(每个图都被分成6份)
问题4:timm包
参考资料:
视觉 Transformer 优秀开源工作:timm 库 vision transformer 代码解读 timm库 vision_transformer.py代码 timm的历史版本
问题描述:
ModuleNotFoundError: No module named ‘timm.models.vision_transformer’


解决办法:
这是个很难搞的问题,指定版本0.1.30带入到代码中,指定库不存在,只能下载更高版本的库; 但是高版本库又有其它问题,现在只能暂时先用3.9版本的Python,以及0.5版本的timm。 后面看看有没有问题。 在解决这个问题的过程中,anaconda-navigator更新完之后还打不开了…
问题5:NNI
参考资料:
NNI (Neural Network Intelligence) 是一个帮助用户自动进行特征工程,神经网络架构搜索,超参调优以及模型压缩的轻量且强大的工具包。
NNI 管理自动机器学习 (AutoML) 的 Experiment,调度运行由调优算法生成的 Trial 任务来找到最好的神经网络架构和/或超参,支持各种训练环境,如本机,远程服务器,OpenPAI,Kubeflow,基于 K8S 的 FrameworkController(如,AKS 等), DLWorkspace (又称 DLTS), AML (Azure Machine Learning), AdaptDL(又称 ADL) ,和其他的云平台甚至 混合模式 。 DLTS),AML (Azure Machine Learning)AdaptDL(又称 ADL) ,和其他的云平台甚至混合模式 。
使用场景
- 想要在自己的代码、模型中试验不同的自动机器学习算法。
- 想要在不同的环境中加速运行自动机器学习。
- 想要更容易实现或试验新的自动机器学习算法的研究员或数据科学家,包括:超参调优算法,神经网络搜索算法以及模型压缩算法。
- 在机器学习平台中支持自动机器学习。

若有收获,就点个赞吧
0 人点赞
