倒排索引(了解)
查看所有的表(es中没有库的概念)

查看某个表的详细信息(如字段信息)
删除表
DELETE account
新增数据
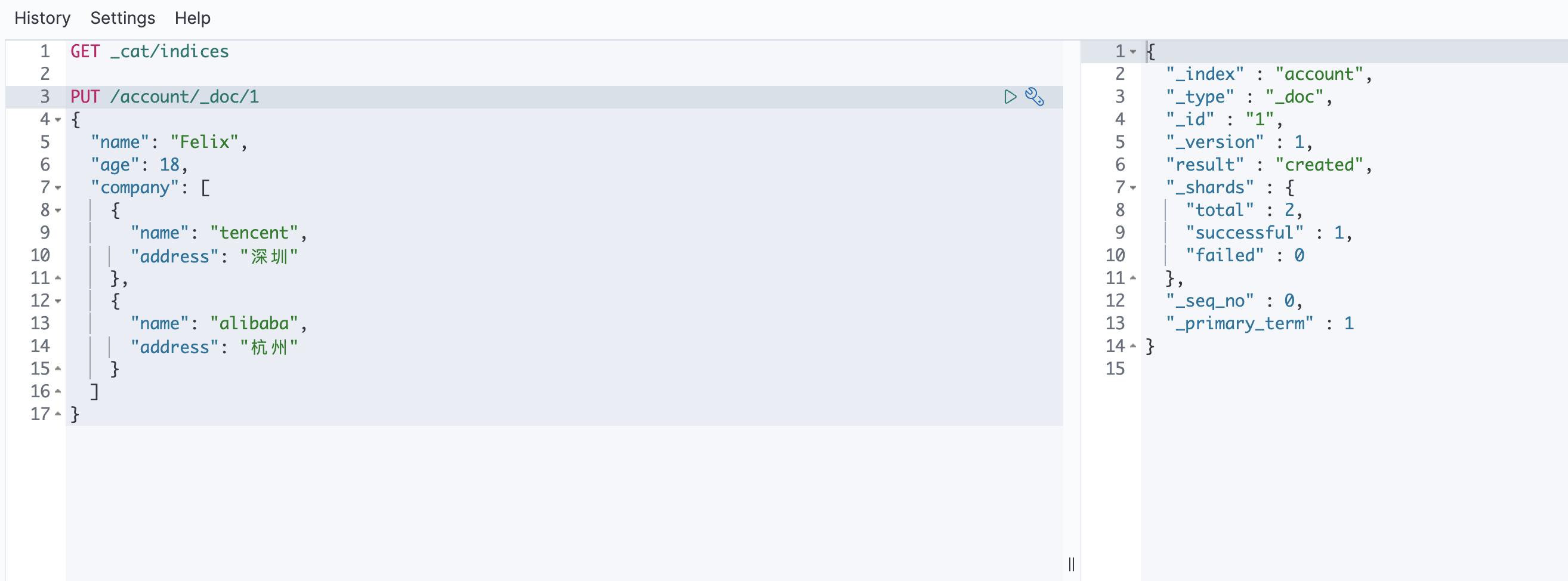
1.通过put+id新建数据
该方法如果id不存在的话就会新建, 存在的话就会更新数据
// acount是表名, _doc意思是文档, 目前这个写法是固定的, 1是idPUT /account/_doc/1{"name": "Felix","age": 18,"company": [{"name": "tencent","address": "深圳"},{"name": "alibaba","address": "杭州"}]}
2.通过post新建数据
POST /user/_doc{"name": "Felix","age": 18,"company": [{"name": "tencent","address": "深圳"},{"name": "alibaba","address": "杭州"}]}
3.通过post+id新建数据
4.通过post+_create新建数据
没有就新建, 有就报错POST /account/_create/1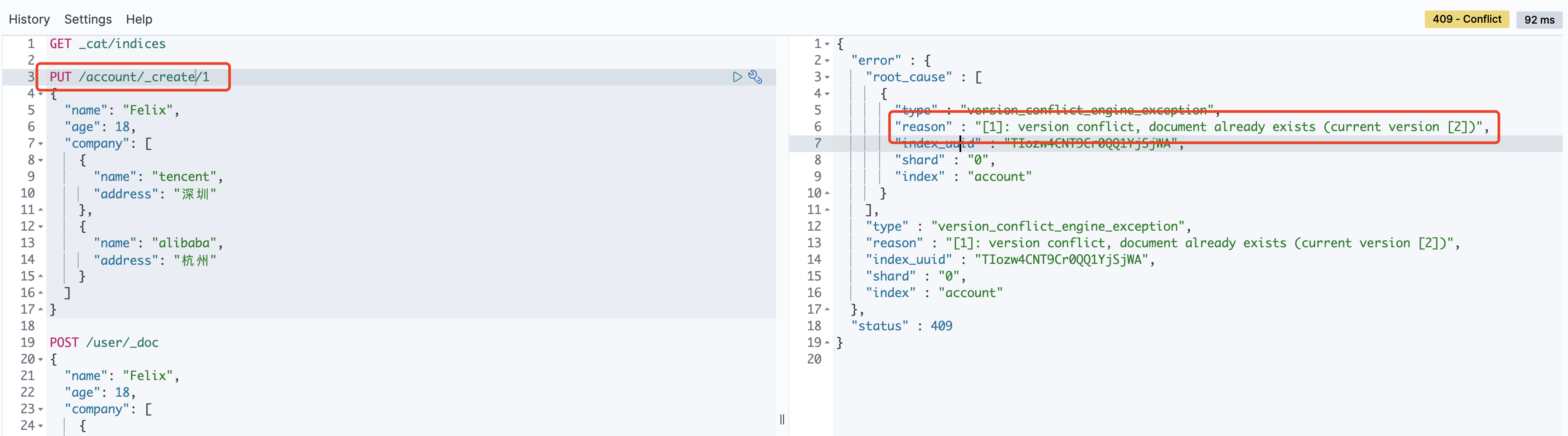
查询数据
1.查询某一条数据的详细信息(包括版本号等)
2.查询某一条数据的内容
3.通过url查询数据(不推荐)
GET _search?q=Felix // 查询所有表GET user/_search?q=Felix // 查询user表
4.通过request body查询数据
// 查询所有数据GET account/_search{"query": {"match_all": {}}}
更新数据
POST account/_update/1{"doc": {"company" : [{"name" : "zhongkeyuan","address" : "北京"}]}}// company里面所有的内容都会被替换(如果数组里面有2条数据, 那么会替换成"北京"这一条)// 此方法会检查数据库里面的数据和需要更新的数据是否一样, 如果一样, 则不会做任何操作(_version和_seq_no的数字不会变)
删除数据
DELETE account/_doc/2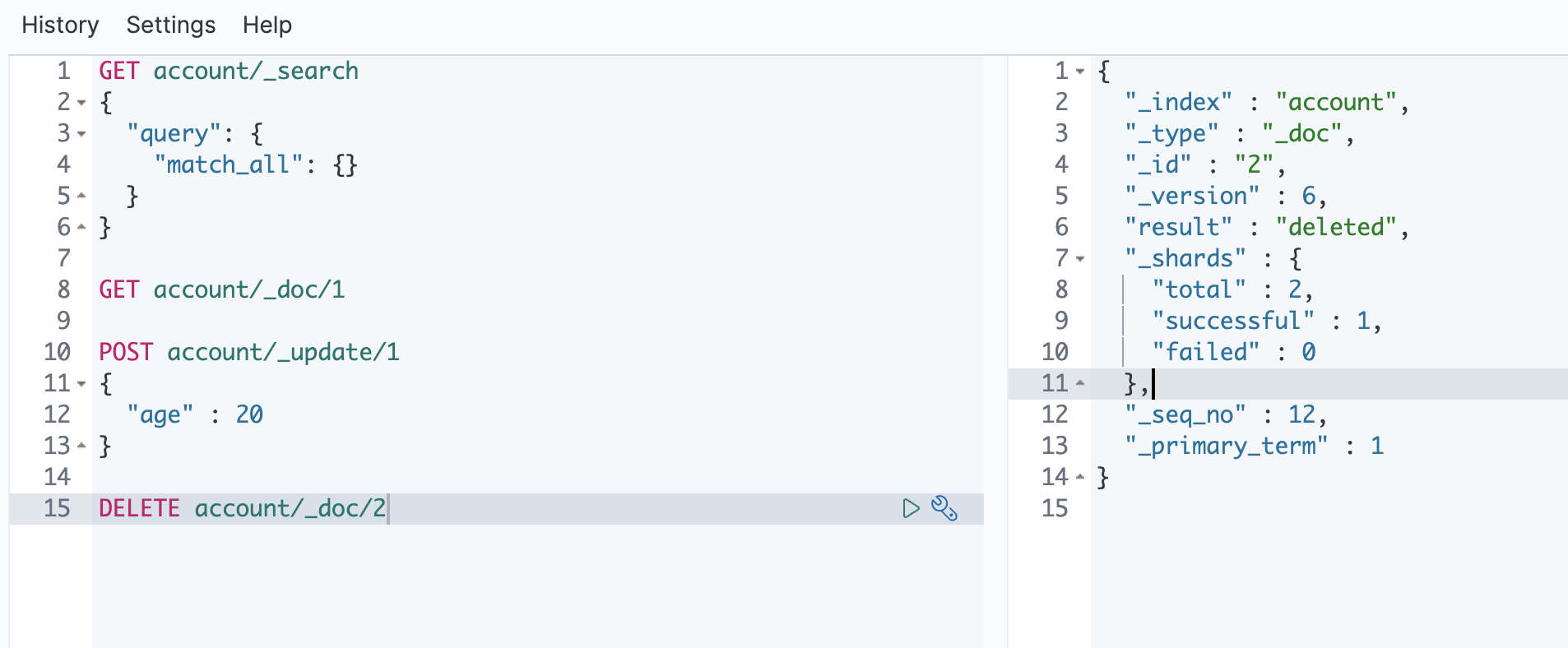
批量操作
批量操作数据
POST _bulk// 索引(查询){ "index": { "_index": "test", "_id": "1" } }{ "field1": "value1" }// 删除{ "delete": { "_index": "test", "_id": "2" } }// 新增{ "create": { "_index": "test", "_id": "3" } }{ "field3": "value3" }// 更新{ "update": { "_index": "test", "_id": "1" } }{ "doc": { "field3": "value3" } }
聚合查询mget
// 分别从user和account中查询数据GET _mget{"doc": [{"_index": "user","_id": 1,},{"_index": "account","_id": 2,}]}
1.全文查询
1.全文查询(match)[匹配查询]
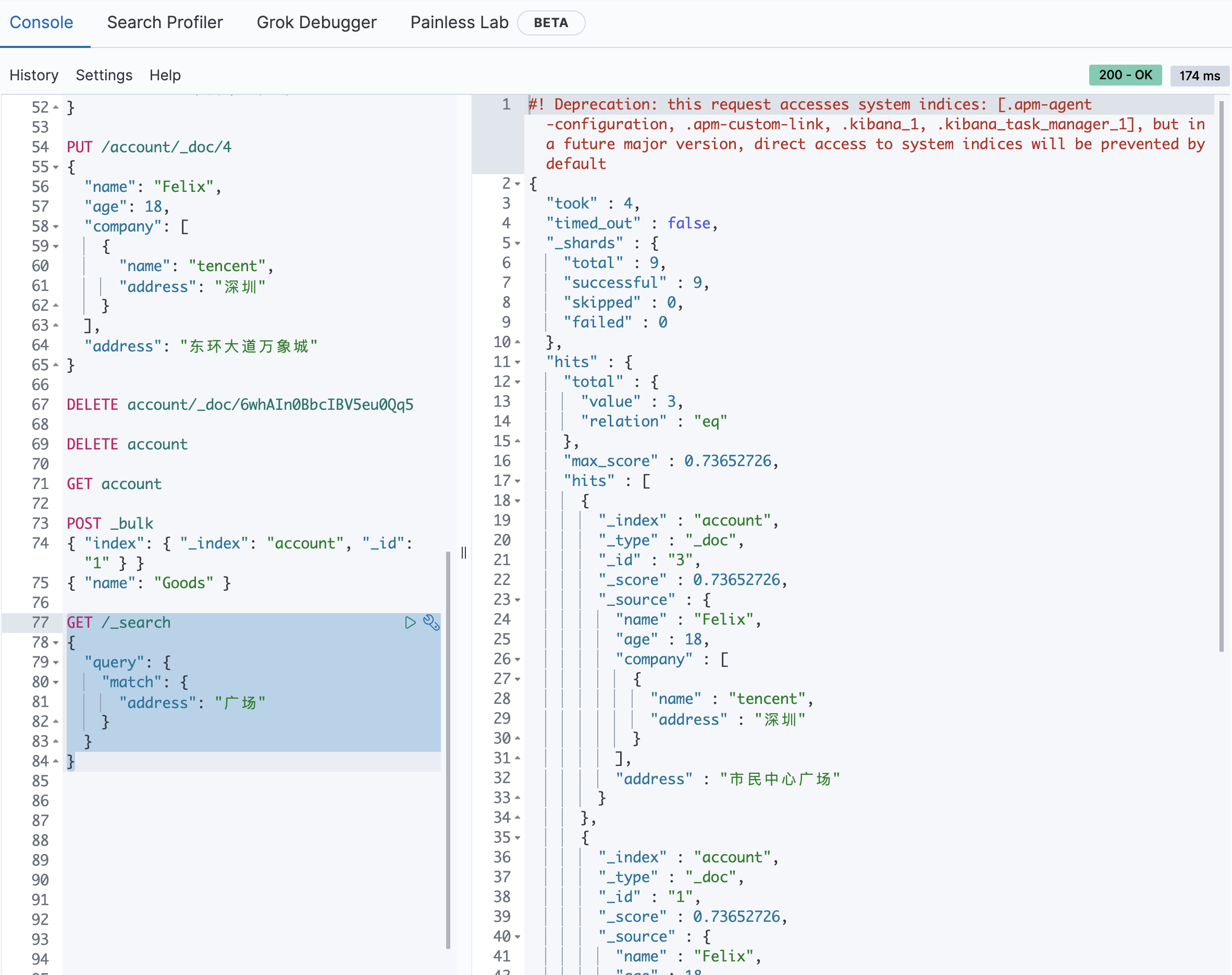
// 对于es来说 from和size分页在数据量比较小的情况下可行, 数据量大的时候会影响性能, 使用scrollGET account/_search{"query": {"match_all": {}},"from": 4,"size": 4}GET /_search{"query": {"match": {"address": "广场"}}}
1.短语查询(match_phrase)
// Madison street会作为一个整体, 如果分开就不会查出来GET user/_search{"query": {"match_phrase": {"address": "Madison street"}}}
2.通过multi_match指定查询字段权重
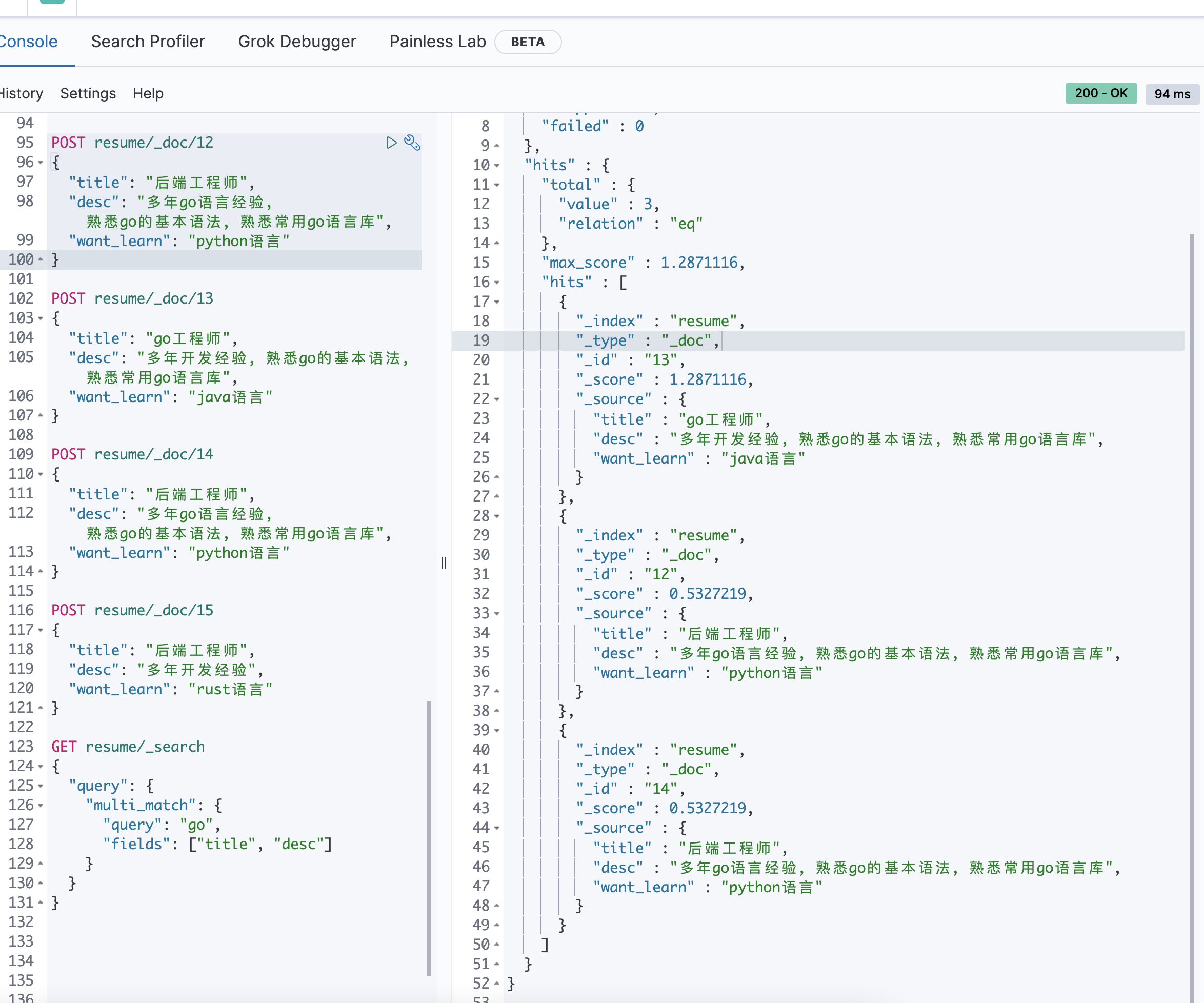
POST resume/_doc/12{"title": "后端工程师","desc": "多年go语言经验, 熟悉go的基本语法, 熟悉常用go语言库","want_learn": "python语言"}POST resume/_doc/13{"title": "go工程师","desc": "多年开发经验, 熟悉go的基本语法, 熟悉常用go语言库","want_learn": "java语言"}POST resume/_doc/14{"title": "后端工程师","desc": "多年go语言经验, 熟悉go的基本语法, 熟悉常用go语言库","want_learn": "python语言"}POST resume/_doc/15{"title": "后端工程师","desc": "多年开发经验","want_learn": "rust语言"}GET resume/_search{"query": {"multi_match": {"query": "go","fields": ["title", "desc"]// "fields": ["title^3", "desc"] 设置权重(权重分会x2)}}}
4.query_string
GET account/_search{"query": {"query_string": {"default_field": "address", // 加上这行会只在address字段进行查询"query": "广场" // 可以使用AND或OR连接符}}}
2.term查询
GET user/_search{"query": {"term": {"address": "madison street"}}}
range查询
GET user/_search{"query": {"range": {"age": {"gte": 10,"lte": 20,"boost": 2.0}}}}
exist查询
// 查询包含age字段的数据GET user/_search{"query": {"exist": {"field": "age"}}}
fuzzy模糊查询
GET /_search{"query": {"fuzzy": {"user.id": {"value": "ki"}}}}
3.bool复合查询(must, should, must_not, filter)
{"quey": {"bool": {"must": [], // 条件必须满足"should": [], // 可满足可不满足, 满足会加分"must_not": [], // 条件必须不满足"filter": [] // 将结果进行过滤}}}// must: 必须匹配, 查询上下文, 加分// should: 应该匹配, 查询上下文, 加分// must_not: 必须不匹配, 过滤上下文, 过滤// filter: 必须匹配, 过滤上下文, 过滤// 示例GET user/_search{"query": {"bool": {"must": [{"term": {"country": {"value": "china"}// 这里也可以直接简写成 "country": "china" 注意term查询如果录入数据的时候没有做term那就要写成小写, 因为倒排索引会把所有字母转成小写},},{"range": {"age": {"gte": 20,"lte": 30}}}],"must_not": [{"term": {"gender": "m" // 过滤掉gender为M的人}}],"should": [{"match": {"firstname": "Felix" // 不会影响结果条数, 但是满足firstname是felix的结果分数会高一些}}],// 在原来的结果上过滤, 但是不影响评分(相当于所有的数据还是原来的, 只是把复合条件的结果拿出来而已)"filter": [{"range": {"age": {"gte": 20,"lte": 30}}}]}}}
mapping
PUT usertest{"mappings": {"properties": {"age": {"type": "integer"},"name": {"type": "keyword" // 不会分词},"desc": {"type": "text" // 会分词}}}}
测试
// 新建mappingsPUT usertest{"mappings": {"properties": {"age": {"type": "integer"},"name": {"type": "keyword"},"desc": {"type": "text"}}}}// 查看mappingsGET usertest// 插入数据POST usertest/_doc{"age": 18,"name": "Felix Chan","desc": "He is a good guy!He is handsome!He is great!"}GET usertest/_search{"query": {"match": {"name": "Felix" // 获取不到, 因为设置了type是keyword不会分词// "name": "Felix" // 可以获取}}}GET usertest/_search{"query": {"match": {"desc": "he good" // 可以获取, 因为已经text会分词}}}
analyzer查询过程
GET _analyze{"analyzer": "standard","text": "The 2 QUIKC Red-Fox jumped over the bridge!"}// standard: 标准分词器, 按词切分, 小写处理// simple: 简单分词器, 按照非字母切分(符号被过滤), 小写处理// stop: 小写吹李, 停用词过滤(the, a, is...)// whitespace: 空格分词器, 不转小写// keyword: 不做分词// patter: 正则表达式, 默认\W+// 语言分词器: 提供了30多重常见语言的分词器//
新建mapping的时候指定analyzer
PUT usertest{"mappings": {"properties": {"age": {"type": "integer","analyzer": "whitespace", // 指定存储的时候用什么analyzer"search_analyzer": "simple" // 指定搜索的时候用什么analyzer}}}}// 使用顺序
搜索的时候指定analyzer
GET user/_search{"query": {"match": {"desc": {"query": "Felix Chan","analyzer": "keyword"}}}}
查看setting中的默认analyzer
查询的时候使用analyzer的顺序
1.先使用search的时候指定的analyzer
2.如果1不存在, 使用存储的时候search_analyzer指定的analyzer
3.如果2不存在, 使用存储的时候analyzer指定的analyzer
4.如果3不存在, 使用的setting中指定的analyzer
如果以上都不存在, 则使用标准的analyzer
ik分词器的安装和配置
github下载地址: https://github.com/medcl/elasticsearch-analysis-ik
1.下载对应版本的ik
2.解压并且重命名为ik并放到docker-elasticsearch的plugins目录下

3.修改ik目录的权限chmod 777 -R ik
4.重启容器: docker-compose restart
试用
ik有两个分词器”ik_smark”、”ik_max_word”
GET _analyze{"text": "中华牙膏","analyzer": "ik_smart"}GET _analyze{"text": "中华牙膏","analyzer": "ik_max_word"}GET _analyze{"text": "中国科学技术大学","analyzer": "ik_max_word"}

自定义分词词库
1.cd到docker-elasticsearch/plugins/ik/config目录
2.mkdir custom
3.新建两个文件
vim mydic.dic // 用于存放用户词库
vim extra_stop_word.dic // 用于存放停用词(的, 是, 又…)
4.回到docker-elasticsearch/plugins/ik/config目录
打开配置文件vim IKAnalyzer.cfg.xml 

配置路径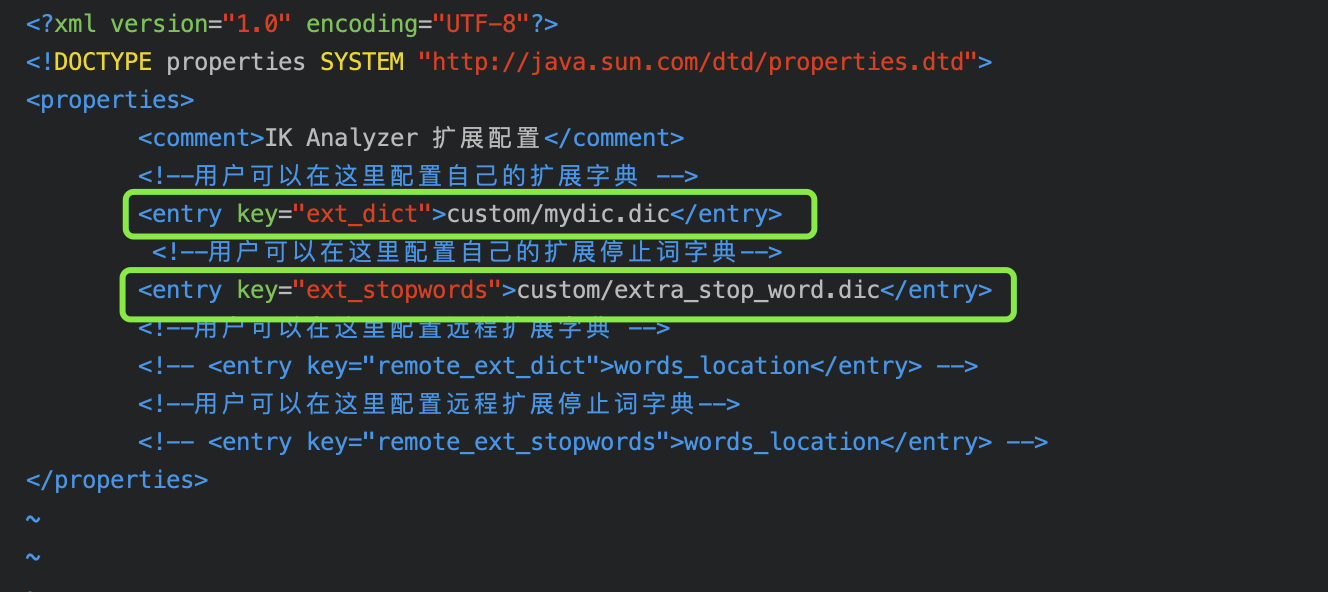
5.重启elasticsearchdocker-compose restart

若有收获,就点个赞吧
0 人点赞
