- Python is a programming language that lets you work quickly and integrate systems more effectively
- 1.python的特点
- 2,print和input() 每个输出之间的间隔,默认空格,end结尾的符号,默认是换行/n
- 注解、变量和基本数据类型
- 注解 1.单行注释,#号开头 2.多行注释,以三对单引号或者双引号包含起来
- 3.标识符 标识符是自己定义的,如变量名 、函数名等
- 4.数据类型
- 5.字符串: 字符串就是一系列任意文本。Python中的字符串用单引号 或者双引号括起来,同时可以使用反斜杠(\)转义特殊字符。
- 13.常用的字符串操作
- 6.列表 列表写在[ ]内,元素之间用逗号隔开:List1=[‘abc’,’你好’,123] 列表是由一系列按特定顺序排列的元素组成,列表能存储多种类型的数据,其中的元素之间可以没有任何关系
- 常用操作:
- 常用方法:
- 7.元祖 元祖写在小括号内,元素之间用逗号隔开: tuple1=(‘abc’,’你好’,123)
- 常用操作:
- 常用函数
- 8.字典 (jaon对象) 字典是一种映射类型,使用{ }表示,他是一个无序的键(key)值(value)对集合 字典是另外一种可变容器类型,且可以存储任意类型对象。
- 常用操作:
- 常用函数:
- 9.集合 set 集合set是基本数据类型的一种,它有可变集合(set)和不可变集合(frozenset)两种
- 常用操作:
- 常用函数:
- 10.运算符
- 11.输入和输出
- Input输入
- print输出,
- 12.常用的格式符号
- 14.循环
- 15常用函数
- 16.推导式
- 17.函数:
- yield
- 18.生成器和迭代器
- 19.变量的作用域:
- 20.匿名函数
- 21.面向对象
- 22.文件和异常:
- 常用函数:
- 23.异常
- 23.文件夹操作
- 24模块和包
- 自带属性:
Python is a programming language that lets you work quickly and integrate systems more effectively
1.python的特点
面向对象的解释型语言
简单易学
丰富的库
强制使用制表符作为语句缩进(white space
2,print和input() 每个输出之间的间隔,默认空格,end结尾的符号,默认是换行/n
print(“hello me”, “hello you”, “hello world”, sep=”_”,end=” “)
name=input()
注解、变量和基本数据类型
注解 1.单行注释,#号开头 2.多行注释,以三对单引号或者双引号包含起来
3.标识符 标识符是自己定义的,如变量名 、函数名等
1、只能包含字母、数字和下划线。变量名可以以字母或者下划线开头。但是不能以数字开头。
2、不能包含空格,但可以使用下划线来分隔其中的单词。
3、不能使用Python中的关键字作为变量名
4、建议使用驼峰命名法,驼峰式命名分为大驼峰(UserName)。和小驼峰(userName)。
4.数据类型

1.int Python可以处理任意大小的整数,当然包括负整数,在程序中的表示方法和数学上的写法一模一样。
2.float 浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的
3.complex 一个实数和一个虚数的组合构成一个复数。t = 3+4j
4.bool bool值是特殊的整型,取值范围只有两个值,也就是True和False。
a,b,c=1,2,3 print(type(num))
无穷大 math.inf
5.字符串: 字符串就是一系列任意文本。Python中的字符串用单引号 或者双引号括起来,同时可以使用反斜杠(\)转义特殊字符。
name=‘1’ print(type(nume)) string a='fsfaf\'dfasfas' b="afd'fsa'saf" <br />常用操作: <br /> [开始坐标:截取坐标:步长(默认1)] 字符串截取,左闭右开 ,负数代表重后面开始数 最后一位为-1 a=fasfdas a[1:3] as a[-2:] as a='asfsda' a[::-1] 倒叙 a[5:2:-1] (+)字符串连接符 a=a+"asfdsa" (*)复制当前字符串
13.常用的字符串操作
find 检测字符串是否包含指定字符,如果是返回开始的索引值,否则返回 - 1 str1 = ‘hello world’ print(str1.find(‘lo’)) 3
index 检测字符串是否包含指定字符,如果是返回开始的索引值,否则提示错误
str1 = ‘hello world’ print(str1.index(‘lo’)) 3
count 返回str1在string中指定索引范围内[start,end)出现的次数
str1 = ‘hello world’ print(str1.count(‘lo’)) 1 print(str1.count(‘lo’, 5, len(str11)))0
replace 将str1中的str1替换成str2,如果指定count,则不超过count次
str1 = ‘hello world hello china’ print(str1.replace(‘hello hello hello’, ‘HELLO’)) HELLO HELLO HELLO print(“hello hello hello”.replace(‘hello’, ‘HELLO’, 1)) HELLO hello hello
split 如果 maxsplit有指定值,则仅分割 maxsplit 个子字符串
str1 = ‘hello world hello china’ print(str1.split(‘ ‘)) print(str1.split(‘ ‘,2))
capitalize 将字符串的首字母大写 str1 = ‘hello world hello china’ print(str1.capitalize())
title 将字符串中每个单词的首字母大写 str1 = ‘hello world hello china’ print(str1.title())
startswith 检查字符串是否是以 obj 开头, 是则返回 True,否则返回 False str1 = ‘hello world hello china’ print(str1.startswith(‘hello’))
endswith 检查字符串是否是以 obj 结尾, 是则返回 True,否则返回 False
str1 = ‘hello world hello china’ print(str1.endswith(‘china’))
lower 将字符串转换为小写 str1 = ‘Hello World HELLO CHINA’ print(str1.lower())
upper 将字符串转换为大写 str1 = ‘hello world hello china’ print(str1.upper())
ljust 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 str1 = ‘hello’ print(str1.ljust(10))
rjust 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 str1 = ‘hello’ print(str1.rjust(10))
center 返回一个原字符串居中,并使用空格填充至长度
width 的新字符串 str1 = ‘hello’ print(str1.center(15))lstrip 去除字符串左边空白字符 str1 = ‘ hello’ print(str1) print(str1.lstr1ip())
rstrip 去除字符串右边空白字符 str1 = ‘hello ‘ print(str1) print(str1.lstr1ip())
strip 去除字符串两边空白字符 str1 = ‘ hello ‘ print(str1) print(str1.lstr1ip())
partition 可以将字符串以str1进行分隔成三个部分 str1前,str1,str1后 str1 = ‘hello world hello china’ print(str1.partition(‘world’)) (‘hello ‘, ‘world’, ‘ hello china’)
join str1 中每个字符后面插入list,构造出一个新的字符串
str1 = ‘_’
list = [‘hello’,’world’,’hello’,’china’]
print(str1.join(list)) hello_world_hello_china
isspace 如果 str1 中只包含空格,则返回 True,否则返回 False.
str1 = ‘ ‘ print(str1.isspace())
isalnum 如果 str1 所有字符都是字母或数字则返回 True,否则返回 False
str1 = ‘a123’ print(str1.isalnum()) ture
isdigit 如果 str1 只包含数字则返回 True 否则返回 False
str1 = ‘aa123’ print(str1.isdigit()) false
isalpha 如果 str1 所有字符都是字母 则返回 True,否则返回 False
str1 = ‘abc’ print(str1.isalpha())
6.列表 列表写在[ ]内,元素之间用逗号隔开:List1=[‘abc’,’你好’,123] 列表是由一系列按特定顺序排列的元素组成,列表能存储多种类型的数据,其中的元素之间可以没有任何关系
注意:List写在方括号之间,元素用逗号隔开,和字符串一样,List可以被索引和切片
List中的元素是可以被改变的 List可以使用加号(+)操作进行拼接
常用操作:
元素修改 tudent[0]=‘tom’
添加 student.append(‘篮球’)
插入 student.insert(4,‘音乐’) 原来索引往后推
删除 使用pop()方法删除元素:pop方法用于移出列表中的一个元素(默认是最后一个元素),
可以指定元素索引,并且返回该元素的值。
使用del语句删除元素:如果知道要删除的元素在列表中的位置,可使用del语句删除元素,元素一旦被删除之后就再无法访问、 del list
使用remove()方法删除元素:当不知道元素索引,只知道元素值的时候,使用remove()方法删除元素
查找 in(存在),如果存在那么结果为true,否则为false
not in(不存在),如果不存在那么结果为true,否则false
常用方法:
len(list) 返回列表元素个数 students=[‘jack’,’tom’,’john’] len(students) 3
max(list) 返回列表元素中的最大值。默认数值型的参数,取最大值。字符型的参数,取字母排序靠后者。
max([‘jack’,’tom’,’john’]) tom max([1,15,16]) 16 只能同类型比较
min(list) 返回列表元素中的最小值。默认数值型的参数,取最小值。字符型的参数,取字母排序靠前者。
list.count(obj) 统计某个元素在列表中出现的次数
extends(list) 扩展列表,在一个列表的末尾一次性追加一个新的列表,参数为一个列表
list.index(obj) 用于从列表中找出某一个值第一个匹配项的索引位置 如果没有则报错
list.reverse() 反向列表中的元素
list.sort() 对列表进行排序,该方法没有返回值。更改的是原数组
list.clear() 用于清空列表
list.copy() 复制列表
7.元祖 元祖写在小括号内,元素之间用逗号隔开: tuple1=(‘abc’,’你好’,123)
tuple的元素不可改变,但是可以包含可变的对象,比如list也可以像字符串一样截取
构造包含0个或者1个元素的元祖有特殊语法规则: tuple1=() #空元祖 tuple2=(1,) #一个元素,需要在元素后添加逗号 a=(a) type(a) int
常用操作:
访问: tuple[0] 多维元祖 tuple[0][0]
删除: del 元组名 del tuple
截取: students[0:3] 左包右闭
常用函数
len(tuple) 计算元祖中元素的个数
max(tuple) 返回列表元素中的最大值。
min(tuple) 返回列表元素中的最小值。
tuple(list) 将列表转换为元祖
8.字典 (jaon对象) 字典是一种映射类型,使用{ }表示,他是一个无序的键(key)值(value)对集合 字典是另外一种可变容器类型,且可以存储任意类型对象。
dict1={} dict2={‘name’:’北风’,’age’:10}
字典是一种映射类型,它的元素是键值对
键(key)必须使用不可变类型(字符串、数值、元组),在同一个字典中,键必须是唯一的。
常用操作:
访问: students[‘name’]
修改:students[‘age’]=20
添加:students[‘address’]=’上海’
删除:del 字典名[key] 使用del语句删除元素:del既可以删除指定的字典元素(列表也可以指定),也可以删除整个字典,如果不指定key,代表删除整个字典
使用clear()方法清空整个字典:被清空的字典最后会剩下一个空的字典在,而用del删除的字典在程序当中就不存在了。
常用函数:
len(dict)** 计算字典中元素的个数
str(dict) 输出字典,已可打印的字符串表示
type(variable) 返回输入变量的数据类型,如果变量是字典就返回
seq=(‘name’,’age’,’sex’) dict1=dict.fromkeys(seq)
print(“新字典为:”,dict1){‘name’: None, ‘age’: None, ‘sex’: None}
dict2=dict.fromkeys(seq,’jack’) print(“新字典为:”,dict2) {‘name’: ‘jack’, ‘age’: ‘jack’, ‘sex’: ‘jack’}
dict.get(key,default=None) 返回指定键的值,如果值不在字典中返回default值
key in dict 如果键在字典dict里返回true,否则返回false
dict.keys() 以列表返回一个字典所有的键
dict.setdefault(key,default=None) 和get类似,但如果键不存在于字典中,将会添加键并将值设为default
dict.values() **以列表返回一个字典中的所有值
9.集合 set 集合set是基本数据类型的一种,它有可变集合(set)和不可变集合(frozenset)两种
集合(set)是一个无序的不重复元素序列。可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:parame = {value01,value02,…} a = set(‘abracadabra’) {‘a’, ‘r’, ‘b’, ‘c’, ‘d’}
创建集合set、集合set添加、集合删除、交集、并集、差集的操作都是非常实用的方法。
常用操作:
添加: s.add( x ) 将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
s.update( x ) x 可以有多个,用逗号分开。
移除:s.remove( x ) 将元素 x 从集合 s 中移除,如果元素不存在,则会发生错
s.discard( x ) 如果元素不存在,不会发生错误
s.pop() 随机删除 括号内不能有元素
常用函数:
len**(s)
s.clear() 清空集合
x in s 判断元素是否在集合中存在
[difference() ](https://www.runoob.com/python3/ref-set-difference.html)返回多个集合的差集
[copy() **](https://www.runoob.com/python3/ref-set-copy.html)拷贝一个集合
10.运算符
基本运算符 + - / % 取余 // 取整除,返回商的整数部分 ^ 幂次
赋值运算符** = += -= = /= //= / %= a%=5 a=a%5
比较运算符 > < == != >= <=
逻辑运算符 and or not bool(a) false a可以取(){} ‘’ [] 0
位运算符 **& | ^(按位异或) ~ 按位取反 << >>
11.输入和输出
Input输入
通过它能够完成从键盘获取数据,然后保存到指定的变量中input获取的数据,都以字符串的方式进行保存,即使输入的是数字,那么也是以字符串方式保存
print输出,
可以输出多个,用,号隔开 使用
参数:sep 每个输出之间的符号,默认是空格 ,
end 输出最后的补充
file 吧数据输出到什么文件 f = open(r"F:\text.txt","w")print('test',file = f) # 输出到文件f.close() # 关闭文件
12.常用的格式符号
d,i,u十进制
o 八进制
x/X 十六进制
e/E 科学计数法
f/F十进制浮点
g/G 按照e或者f格式返回
c/r/s 接受整数或者单个ascii字符/返回repr形式转换python对象/str1形式返回python对象
print(“%5d:%5s:%o:%x”%(15,15,9,10 )) # 15: 15:11:a
#%5s意思是字符串长度为5,当原字符串的长度超过5时,按原长度打印,长度不足时,左侧补全空格
%-5s 当数据个数不足5时,右侧补全空格
%.5s截取5位 如果不足五五则保留字符串
#%a.bs这种格式是上面两种格式的综合,首先根据小数点后面的数b截取字符串,
#当截取的字符串长度小于a时,还需要在其左侧补空格
#%05d意思是打印结果为5位整数,当整数的位数不够5位时,在整数左侧补0
#%.3d小数点后面的3意思是打印结果为3位整数,超过3时,打印原来的
#当整数的位数不够3位时,在整数左侧补0,所以%.3d的打印结果是014
#%a.bf,a表示浮点数的打印长度,b表示浮点数小数点后面的精度
14.循环
if
一个if只能有一个else,但是可以拥有多个elif。Python中没有switch-case,可以使用if-elif-else来代替switch-case
if 条件:
满足if条件执行的代码块1
elif 条件1:
满足条件1执行的代码块2
elif 条件2:
满足条件2执行的代码块3
else:
不满足以上条件执行的代码块4
while
while 条件:
满足条件执行代码块
else: (可以没有)
不满足条件执行代码块
for
for
else:
常用关键字 continue break pass
**
15常用函数
range() range(start, stop[, step]) 
16.推导式
列表推导式:列表推导式(list comprehension)是利用其它列表创建新列表的一种方式,工作原理类似for循环,即可对得到的元素进行转换变形 ,其基本格式如下(可以有多个for语句)
[expr for value in collection ifcondition ] expr可以使for循环的变量,也可以是表达式
[i for i in range(30) if i % 3 is 0]
def squared(x):
return xx
multiples = [squared(i) for i in range(30) if i % 3 is 0]
集合推导式:集合推导式跟列表推导式非常相似,唯一区别在于用{}代替[]。其基本格式如下:
{ expr for value in collection if condition }
{i for i in range(30) if i % 3 is 0}
squared = {x2 for x in [1, 1, 2]}
字典推导式:*{ key_expr: value_expr for value in collection if condition }
mcase = {‘a’: 10, ‘b’: 34, ‘A’: 7, ‘Z’: 3}
mcase_frequency = {
k.lower(): mcase.get(k.lower(), 0) + mcase.get(k.upper(), 0)
for k in mcase.keys()
if k.lower() in [‘a’,’b’]
}
17.函数:
函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
任何传入参数和自变量必须放在圆括号中间。
函数的第一行语句可以选择性地使用文档字符串—-用于存放函数说明。
函数内容以冒号起始,并且缩进。
def 函数名([参数列表]):
#参数列表可选项
函数体
函数参数—不定长参数 : :加了星号()的变量名会存放所有未命名的变量参数。加了()会存放所有命名的变量参数
可变对象与不可变对象传递:
不可变类型:如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
可变类型:*如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
yield
yield 的作用就是把一个函数变成一个generator,带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个生成器,如调用Xun函数,不会执行该函数,而是返回一个iterable迭代对象!
区别:与return类似,都可以返回值,但不一样的地方,yield可以返回多次值,而return只能返回一次。
18.生成器和迭代器
迭代器:
迭代器 迭代是Python最强大的功能之一,是访问集合元素的一种方式。 迭代器是一个可以记住遍历的位置的对象。 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。
迭代器只能往前不会后退。 迭代器有两个基本的方法:iter() 和 next()。
字符串,列表或元组,集合对象都可用于创建迭代器:
生成器(generator):
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回yield的值。并在下一次从当前位置继续运行。
生成器-send(generator)
a = yield 1 这个表达式,如果这个表达式只是x = 1,相信每个人都能理解是把1的值赋值给了x.
而现在等号右边是一个yield 1,所以先要执行yield 1,然后才是赋值.
yield把1值返回到了调用者那里,因为执行等号右边的yield就是暂停,所以不会对a赋值
那这个表达式的下一步操作:赋值,却换句话说a = yield 1 只执行了一半
而send()里面的值的作用是把值传进当前的yield.
19.变量的作用域:
局部变量,就是在函数内部定义的变量
全局变量是声明在函数外部的变量,定义在函数外的拥有全局作用域
在函数内使用global 修改全局变量
20.匿名函数
定义函数的过程中,没有给定名称的函数就叫做匿名函数;Python中使用lambda表达式来创建匿名函数。
●lambda只是一个表达式,函数体比def简单很多。
●lambda的主体是一个表达式,而不是一个代码块,所以不能写太多的逻辑进去。
●lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
●lambda定义的函数的返回值就是表达式的返回值,不需要return语句块
●lambda表达式的主要应用场景就是赋值给变量、作为参数传入其它函数
lambda匿名函数的表达式规则是:lambda 参数列表: 表达式
sum = lambda arg1, arg2: arg1 + arg2 sum(10,20) 30
21.面向对象
类的名称:类型<br /> 属性:对象的属性<br /> 方法:对象的方法<br />**类变量:**类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。**如果需要用在函数中使用类名.类属性.**<br />**实例变量:**定义在方法中的变量,只作用于当前实例的类。<br />**类的属性的访问:**<br />可以使用点实例化对象名+.来访问对象的属性<br />也可以使用以下函数的方式来访问属性<br />getattr(obj, name[, default]) : 访问对象的属性<br />hasattr(obj,name) : 检查是否存在一个属性<br />setattr(obj,name,value) : 设置一个属性。如果属性不存在,会创建一个新属性<br />delattr(obj, name) : 删除属性<br />**注意:name需要加单引号,obj为实例化对象名称**<br />**Python内置类属性**<br />__dict__ : 类的属性(包含一个字典,由类的属性名:值组成) 实例化类名.__dict__<br />__doc__ :类的文档字符串 (类名.)实例化类名.__doc__<br />__name__: 类名,实现方式 类名.__name__<br />__bases__ : 类的所有父类构成元素(包含了以个由所有父类组成的元组)<br />**__init__()构造方法和self**<br /> __init__()是一个特殊的方法属于类的专有方法,被称为类的构造函数或初始化方法,方法的前面和后面都有两个下划线。<br /> 这是为了避免Python默认方法和普通方法发生名称的冲突。每当创建类的实例化对象的时候,__init__()方法都会默认被运行。作用就是初始化已实例化后的对象。<br /> 在方法定义中,第一个参数self是必不可少的。类的方法和普通的函数的区别就是self,self并不是Python的关键字,你完全可以用其他单词取代他,只是按照惯例和标准的规定,推荐使用self。<br />**__name__:**如果是放在Modules模块中,就表示是模块的名字;<br /> 如果是放在Classs类中,就表示类的名字;<br />**__main__:**模块,xxx.py文件本身.被直接执行时,对应的模块名就是__main__了<br />可以在if __name__ == “__main__”:<br />中添加你自己想要的,用于测试模块,演示模块用法等代码。<br />作为模块,被别的Python程序导入(import)时,模块名就是本身文件名xxx了。
22.文件和异常:
open函数
在python中,使用open函数,打开一个已经存在的文件,或者新建一个新文件。
函数语法 open(name[, mode[, buffering[,encoding]]])
name : 一个包含了你要访问的文件名称的字符串值(区分绝对路径和相对路径)。
mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
file1.close() 关闭文件
read(num):可以读取文件里面的内容。num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据
with…open 关键字with在不再需要访问文件后将其关闭。这可让Python去确定:你只管打开文件,并在需要时使用它,Python自会在合适的时候自动将其关闭。
访问模式:
r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
w 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
a 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入
rb 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式
wb 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
ab 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入
r+ 打开一个文件用于读写。文件指针将会放在文件的开头。(先读再写)
w+ 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
a+ 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
rb+ 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb+ 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
ab+ 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
readlines() 可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素
file_object.write(“I love programming.”) 文件写入
常用函数:
read(size) size为读取的长度,打开模式有b(二进制) 就按byte为单位,无b就以字符为单位
readline()/readlines() 读取第一行/把文件每一行作为一个list的一个成员,并返回这个list。
write() 把str写到文件中,write()并不会在str后加上一个换行符
writelines(seq) 把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
close() 关闭文件
flush() 把缓冲区的内容写入硬盘
tell() 返回文件游标操作的当前位置,以文件的开头为原点
write() 把str写到文件中,write()并不会在str后加上一个换行符
seek(offset[,whence]) offset — 开始的偏移量,也就是代表需要移动偏移的字节数
whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
truncate() 把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
23.异常
try:
<语句>
except <异常类型1>[, 异常参数名1]:
<异常处理代码1>
except <异常类型2>[, 异常参数名2]:
<异常处理代码2>
else:
<没有异常时候的处理代码>
finally:
<不管是否有异常,最终执行的代码块>


23.文件夹操作
python编程时,经常和文件、目录打交道,这是就离不了os模块。os模块包含普遍的操作系统功能,与具体的平台无关。



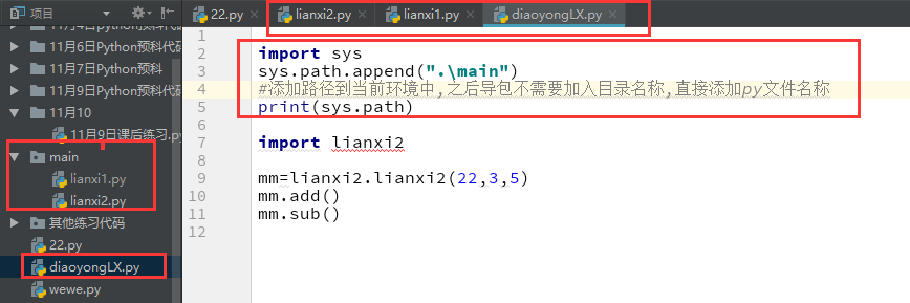
24模块和包
同级目标可以使用import或者form import导入
子级目录导入
直接使用子级文件名.文件名导入

自带属性:
builtins‘,
‘doc‘, 当前文件描述和注解 作者和创建时间等,,否则时None
‘file‘, 当前文件路径 E:/python/test1/test.py
‘loader‘,
‘name‘,za当前文件运行时 main ,被调用时是文件名
‘package‘ 包名
, ‘spec‘

若有收获,就点个赞吧
0 人点赞
