- log_device_placement参数来打印运行每一个运算的设备。
- ">配置里面是把具体运行过程在哪里执行给打印出来
sess =tf.Session(config=tf.ConfigProto(log_device_placement=True))
- ">InteractiveSession和常规的Session不同在于,自动默认设置它自己为默认的session
即无需放在with块中了,但是这样需要自己来close session
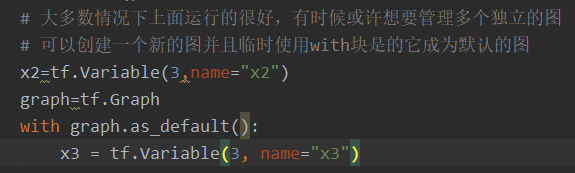
- tf.Graph
- gradients1=tf.gradients(mse,[theta])[0]
- tf.assign(A,B)
- tf.argmax(y, 1) 按行返回最大数的下标
- tf.equal(A, B)
- tf.cast(equalArry, tf.float32) 类型转化
- saver = tf.train.Saver() 保存模型,
- tf.reshape(x, [-1, 28, 28, 1]) 改变形状
- tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
- tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=logits)
- tf.nn.in_top_k(logits, y, 1) 正确率 ,返回ture或者false
- with arg_scope([fully_connected],
- weights_regularizer=tf.contrib.layers.l2_regularizer(scale=0.1)):
- reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
- 常用操作
- 常用的随机操作
- 优化器选择
- 模型评估
- fully_connected
- keras
由Goole Brain开源,设计初衷是加速机器学习的研究
1.导包:import tensorflow as tf tensorflow.version
from tensorflow.contrib.framework import arg_scope 统一设置实参
from tensorflow.contrib.layers import fully_connected 全连接层
数据类型:
tf.Variable 变量
tf.constant(dataset,dtype=tf.float32,name=”X”)
tf.placeholder(dtype=tf.float32,name=”X”) 占位
tf.device 指定运行的设备 **with tf.device(‘/cpu:0’**):
–比如第一个GPU的名称为/gpu:0,第二个GPU名称为/gpu:1,以此类推。
log_device_placement参数来打印运行每一个运算的设备。
配置里面是把具体运行过程在哪里执行给打印出来
sess =tf.Session(config=tf.ConfigProto(log_device_placement=True))
.initializer初始
全局初始化tf.global_variables_initializer()
sess.run(tf.global_variables_initializer())
eval()
eval()其实就是tf.Tensor的session.run()的另一种写法,
1、eval()也是启动计算的一种方式。基于tensorflow基本原理,首先需要定义图,然后计算图,
其中计算图的函数有常见的run()函数,如sess.run(),eval()也是类似。
2、eval()只能用于tf.tensor类对象,也就是有输出的operaton(加减乘除等操作)。没有输出的operation,使用
session.run()
session的运行,1.过程.run;2.sess.run(过程)

tf.InteractiveSession()
InteractiveSession和常规的Session不同在于,自动默认设置它自己为默认的session
即无需放在with块中了,但是这样需要自己来close session
tf.Graph
gradients1=tf.gradients(mse,[theta])[0]
tf.assign(A,B)
tf.argmax(y, 1) 按行返回最大数的下标
tf.argmax(input, axis=None, name=None, dimension=None)
input:输入Tensor
axis:0表示按列,1表示按行
name:名称
dimension:和axis功能一样,默认axis取值优先。新加的字段
tf.equal(A, B)
是对比这两个矩阵或者向量的相同位置的元素,如果是相等的那就返回True,反正返回False,返回的值的矩阵维度和A是一样的
tf.cast(equalArry, tf.float32) 类型转化
saver = tf.train.Saver() 保存模型,
tf.reshape(x, [-1, 28, 28, 1]) 改变形状
tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
直接通过z和真实的y计算交叉熵损失,还会将y进行one_hot编码
如果y已经进行过one_hot编码,则使用
tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=logits)
求出的是整体损失,还要求平均
tf.nn.in_top_k(logits, y, 1) 正确率 ,返回ture或者false
tf.nn.in_top_k(logits, y, m) logits中每一行的前m个最大的元素的下标,是否包含y
with arg_scope([fully_connected],
weights_regularizer=tf.contrib.layers.l2_regularizer(scale=0.1)):
reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
获取正则项的损失
常用操作
大多数运算符都进行了重载操作,使我们可以快速使用 (+ - /) 等,但是有一点不好的是使用重载操作符后就不能为每个操作命名了。
#**(1)加法+*
ts_add1=tf.add(ts1,ts2,name=None)
ts_add2=ts1+ts2 #二者等价
tf.add_n(list) n项加和 操作数需要时list
#**(2)减法-
ts_sub1=tf.subtract(ts1,ts2,name=None)
ts_sub2=ts1-ts2 #二者等价
#*(3)乘法
ts_mul1=tf.multiply(ts1,ts2,name=None)
ts_mul2=ts1*ts2
可以用于两个矩阵的对应位置相乘
#**(4)除法/
ts_div1=tf.divide(ts1,ts2,name=None)
ts_div2=tf.div(ts1,ts2,name=None) #div 支持 broadcasting(即shape可不同)
ts_div3=ts1/ts2
#(5)**矩阵相乘
tf.matmul(x,y) 相当于 np.dot(x,y)
#(6) log
tf.log(y_pre)
#(7)#tf.reduce_sum(Ytf.log(y_pre)*,reduction_indices=[1]) 加和
reduction_indices=[1] 按照列加和, 加完变成一列
reduction_indices=[0]按照行加和,加完变成一行
#(8) tf.reduce_mean() 求平均**
常用的随机操作
tf.random_normal 服从正太分布的随机
tf.random_normal(shape,mean=0.0,stddev=1.0,dtype=tf.float32,seed=None,name=None) 
tf.random_uniform从均匀分布中返回随机值。
- random_uniform( shape,# 生成的张量的形状 minval=0, maxval=None, dtype=tf.float32, seed=None, name=None )
tf.random_uniform([n + 1, 1], -1.0, 1.0)
返回值的范围默认是0到1的左闭右开区间,即[0,1)。minval为指定最小边界,默认为1。maxval为指定的最大边界,如果是数据浮点型则默认为1,如果数据为整形则必须指定。
tf.random_shuffle()**沿着要被洗牌的张量的第一个维度,随机打乱,经常用于x的打乱顺序
tf.random_shuffle(value,seed=None,name=None)**
优化器选择
所谓的优化器,就是tensorflow中梯度下降的策略,用于更新神经网络中数以百万的参数。
通过上面的图我们可以看到,一共有11个优化器,以及1个tf.train.Optimizer的基类。这11个优化器分别是:
1. Tf.train.GradientDescentOptimizer(learning_rate, use_locking=False,name=’GradientDescent)
learning_rate学习率
use_locking, 是否更新梯度
2.Tf.train.MomentumOptimizer (self, learning_rate, momentum,
use_locking=False, name=‘Momentum’, use_nesterov=False)
momentum是动量值的系数η
这个函数是带动量的梯度下降,与之前的区别就是在一次梯度下降的计算时,同时考虑到上一次梯度下降的大小和方向,就好像梯度下降是有惯性一样。Use_nesterov这个参数指的是,是否使用nesterov版本的带动量的梯度下降,
3.Tf.train.AdagradOptimizer(self, learning_rate,
initial_accumulator_value=0.1, use_locking=False, name=‘Adagrad’)
AdagradOptimizer实际上属于自适应的梯度下降算法。
4 Tf.train.AdadeltaOptimizer(self, learning_rate=0.001, rho=0.95,
epsilon=1e-08, use_locking=False, name=‘Adadelta’)
AdaDelta,是google提出的一种对于AdaOptimizer的改进,同样是一种自适应的优化器,
模型评估
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
fully_connected

复习:
np.c_[A,B],两个矩阵拼接
dataset=np.c_[np.ones((m,1)),dataset]
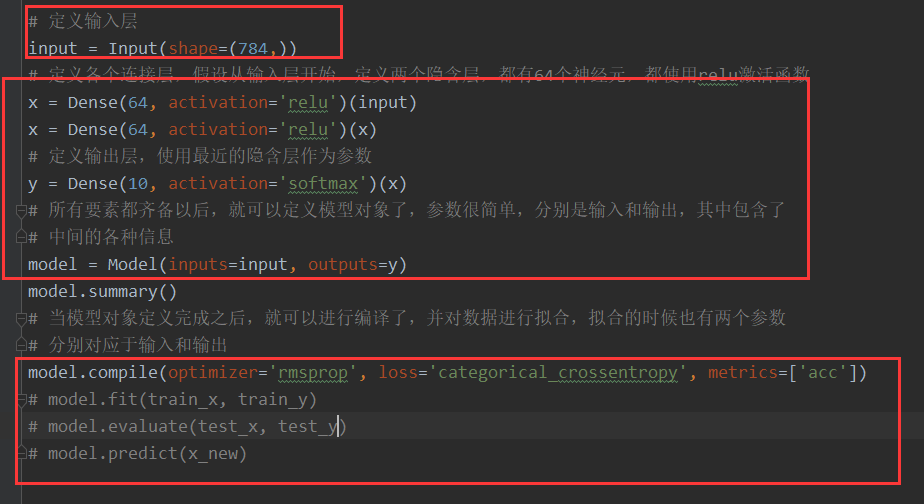
keras
只能使用python,对tensorFlow能做二次封装,使用更快,更方便.
作用是将代码翻译成tensorflow 能理解的api,keras底层依赖是tensorflow,所以keras核tensorflow版本需要对应。
from keras.models import Sequential

from keras.layers import Dense
from keras.layers import Input
from keras.layers import Activation
from keras.models import Model
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D

若有收获,就点个赞吧
0 人点赞
