

neural network
- 激活函数:将神经元的净输入信号转换成单一的输出信号,以便进一步在网络中传播。
2. 网络拓扑:描述了模型中神经元的数量以及层数和它们连接的方式。
3. 训练算法:指定如何设置连接权重,以便抑制或增加神经元在输入信号中的比重。
一.常用的激活函数
1.relu

优点:
1.仿生物学原理:相关大脑方面的研究表明生物神经元的信息编码通常是比较分散及稀疏的。通常情况下,大脑中在同一时间大概只有1%-4%的神经元处于活跃状态。使用relu激活函数可以使只有部分神经源出于激活状态。
2.更加有效率的梯度下降以及反向传播:避免了梯度爆炸和梯度消失问题
3.简化计算过程:没有了其他复杂激活函数中诸如指数函数的影响;同时活跃度的分散性使得神经网络整体计算成本下降。
2.sigmoid

3.tanh

二、输出层常用的激活函数
三、反向传播和正向传播
前向传播,就是make predictions,然后计算输出误差,然后计算出每个神经元节点对误差的贡献
反向传播Backpropagation,就是梯度下降,调整参数,使用reverse-mode autodiff(反向自动求导)
链式求导法则(复合函数求导)
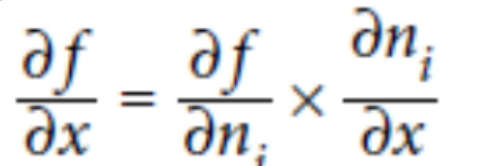
Dropout
在深度学习中,最流行的正则化技术,它被证明非常成功,即使在顶尖水准的神经网络中也可以带来1%到2%的准确度提升
在每一次训练step中,每个神经元,包括输入神经元,但是不包括输出神经元,有一个概率神经元被临时的丢掉,意味着它将被忽视在整个这次训练step中,但是有可能下次再被激活,超参数p叫做dropout rate,一般设置50%,在训练之后,神经元不会再被dropout
梯度消失
在梯度下降中,随着算法反向反馈到前面几层,梯度会越来越小,最终,没有变化,这时或许还没有收敛到比较好的解,这就是梯度消失问题,深度学习遭受不稳定的梯度,不同层学习在不同的速度上
如果我们看逻辑激活函数,当输入比较大,不管正负,将会饱和在0或1,这样梯度就是0,因此当反向传播开始,它几乎没有梯度传播回神经网络,所以就会导致只更改高的几层,低的几层不会变化
RELU的变型
解决:ReLU激活函数不完美,有个问题是dying ReLU,在训练的时候一些神经元死了,当它们输出小于0
Leakly Relu
max(az,z),a=0.01,
RReLU,Random,a是一个在给定范围内随机取值的数在训练时,固定的平均值在测试时,过拟合可以试试
PReLU,Parametric,a是一个在训练过程中需要学习的参数,它会被修改在反向传播中,适合大数据集
*ELU,exponential,计算梯度的速度会慢一些,但是整体因为没有死的神经元,整体收敛快,超参数0.01
融合了sigmoid和ReLU,左侧具有软饱和性,右侧无饱和性。
右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。
ELU的输出均值接近于零,所以收敛速度更快。
在 ImageNet上,不加 Batch Normalization 30 层以上的 ReLU 网络会无法收敛,PReLU网络在MSRA的Fan-in (caffe )初始化下会发散,而 ELU 网络在Fan-in/Fan-out下都能收敛。
参数初始化



BN
为了使每一层得输出值有较好得分布(例如高斯分布),以便于back propagation时计算gradient,更新weight。
BN的使用位置
BN算法过程

BN的作用
(1)允许较大的学习率
(2)减弱对初始化的强依赖性
(3)保持隐藏层中数值的均值、方差不变,让数值更稳定,为后面网络提供坚实的基础
(4)有轻微的正则化作用(相当于给隐藏层加入噪声,类似Dropout)
BN存在的问题
(1)每次是在一个batch上计算均值、方差,如果batch size太小,则计算的均值、方差不足以代表整个数据分布。 这时可用GN
(2)batch size太大:会超过内存容量;需要跑更多的epoch,导致总训练时间变长;会直接固定梯度下降的方向,导致很难更新。
卷积神经网络(CNN)
卷积的计算


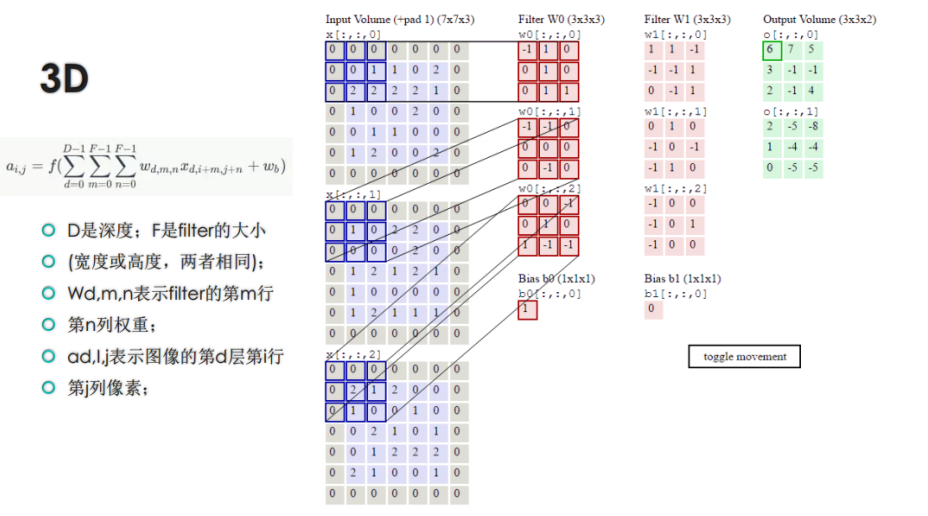
Padding模式
VALID 不适用zero padding,有可能会忽略图片右侧或底下,这个得看stride的设置 会改变输入得形状
假设以mn得卷积核对 xy得样本步长为1进行卷积,则样本形状变成x-(m-1)/2/1 ,y-(n-1)/2/1
SAME 必要会加zero padding,这种情况下,输出神经元个数等于输入神经元个数除以步长。
权值共享,
针对卷积神经网络来说,WX 中得W相当于卷积核中得每一个数,并且针对每一个节点的w相同。
池化Pooling
ü **目标就是降采样subsample,shrink,减少计算负荷,内存使用,参数数量(*也可防止过拟合)
ü 减少输入图片大小也使得神经网络可以经受一点图片平移,不受位置的影响
ü 正如卷积神经网络一样,在池化层中的每个神经元被连接到上面一层输出的神经元,只对应一小块感受野的区域。我 们必须定义大小,步长,padding类型
ü 池化神经元没有权重值,它只是聚合输入根据取最大或者是求均值
ü 22的池化核,步长为2,没有填充,只有最大值往下传递,其他输入被丢弃掉了
长和宽两倍小,面积4倍小,丢掉75%的输入值
一般情况下,池化层工作于每一个独立的输入通道,所以输出的深度和输入的深度相同
常用的池化核大小:2x2 步长2
 池化核2*2,步长等于2,
池化核2*2,步长等于2,
CNN架构
ü 典型的CNN架构堆列一些卷积层
ü 一般一个卷积层后跟ReLU层,然后是一个池化层,然后另一些个卷积层+ReLU层,然后另一个池化层,通过网络传递的图片越来越小,但是也越来越深,例如更多的特征图!
ü 最后常规的前向反馈神经网络被添加,由一些全连接的层+ReLU层组成,最后是输出层预测,例如一个softmax层输出预测的类概率
ü 一个常见的误区是使用卷积核过大,你可以使用和99的核同样效果的两个33的核,好处是会有更少的参数需要被计算,还可以在中间多加一个非线性激活函数ReLU,来提供复杂程度
多次使用小卷积核得到大卷积核统样的结果,连续使用小的卷积可以降低计算的w数量。并且可以使用多次非线性变化。
LeNet

共有7层。两次卷积两次池化,两次全连接,一次输出。
使用的非线性变化使tanh,
出现在1998
Alexnet

卷积—池化—卷积—池化—卷积-卷积-卷积-池化—全连接-全连接—输出
共有11层
出现在2012,首次使用连续小卷积核,首次使用relu激活函数
VGG16 (2014)
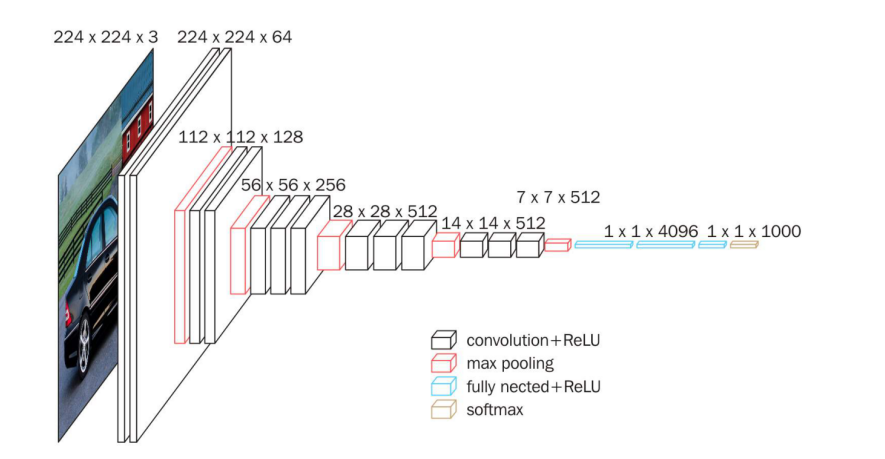
共有21层。
应用:1.使用全面的卷积核池化层,可以得到向量,可以用于计算相似度,距离,(人脸识别)
2.迁移学习
Inception (2014)
V1: 1*1+1(s) 的卷积层,可以通过通道数降维,防止数据维度爆炸
特点:
1.GoogLeNet 最大的特点就是使用了 Inception
模块,它的目的是设计一种具有优良局部拓扑结构的网络,即对输入图像并行地执行多个卷积运算或池化操作,并将所有输出结果拼接为一个非常深的特征图。
2.通过 11、33 或 5*5 等不同的卷积运算与池化操作可以获得输入图像的不同信息,并行处理这些运算并结合(在通道上的叠加)所有结果将获得更好的图像表征
3.通过三次输出loss来尽可能的优化参数,尽可能防止过拟合
整个网络有九个Inception模块,分别在第四个、第七个和第九个输出loss
v2 特点:
1.在所有的非线性变化前增加了BN做归一化
2.去掉了中间的两个输出loss
3.讲55的卷积改为两个33的卷积
4.10个模块网络,在3和8是3条线的网络,去掉了11的卷积
V3特点:
1.在Inception 模块中 把33的卷积通道改成两个33
使用13和31 链接的方式代替33 使用17和71代替77
ResNet 2015
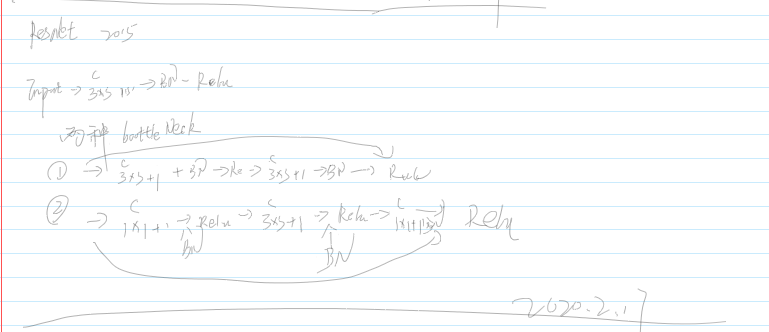
DenseNet 2016





目标检测
一般用于矩形的框出检测结果,可以用一组对角坐标,或者用左上坐标加w,h cv2.rectangle(image, (gX - 5, gY - 5), (gX + gW + 5, gY + gH + 5), (0, 0, 255), 1) #画矩形,对角点**
选择搜索(Selective Search)
图像中物体可能存在的区域应该是有
某些相似性或者连续性区域的。因此,选择搜索基于上面这一想
法采用子区域合并的方法进行提取bounding boxes候选边界框。
首先,对输入图像进行分割算法产生许多小的子区域。其次,根
据这些子区域之间相似性(相似性标准主要有颜色、纹理、大小等
等)进行区域合并,不断的进行区域迭代合并。每次迭代过程中对
这些合并的子区域做bounding boxes(外切矩形),这些子区域外切
矩形就是通常所说的候选框.
IOU的计算:

构造训练集的方式
正例(ground truth):
负样本:
如果区域A与GT的重合度在20-50%之间,而且A与其他的
任何一个已生成的负样本之间的重合度不大于70%,则A被采纳为负样本; 

R_CNN,ss提候选框,将所有的region proposal(候选区域)reshape统一的形状,然后convolution(卷积),之后进行svm分类和回归
先使用softmax训练卷积及卷积之前的网络,固定参数,在训练reg和svm ,由于训练笔记多,需要多次缓存,所以比较慢
spp-net 先图像经过卷积网络,ss提候选框,然后在特征图上的region proposal使用空间金字塔池化 (spatial pymramid pooling ) 得到统一形状的输出 然后进行svm和回归,
fast-r-cnn 先图像经过卷积网络,ss提候选框,然后在特征图上的region proposal使用ROI poling(一种特殊的池化方式) 得到统一形状的输出 然后进行softmax和回归,
faster r-cnn 先图像经过卷积网络,然后在特征图上的每个锚点(anchor)生成9个anchor box,在使用(Region proposal network )RPN 网络 (判断是否是object,修正proposal位置)计算得到region proposal ,然后将region proposal 使用rol池化得到统一形状输出,在使用softmax(判断是什么)和回归(修正目标框位置)
faster r-cnn
region proposal network
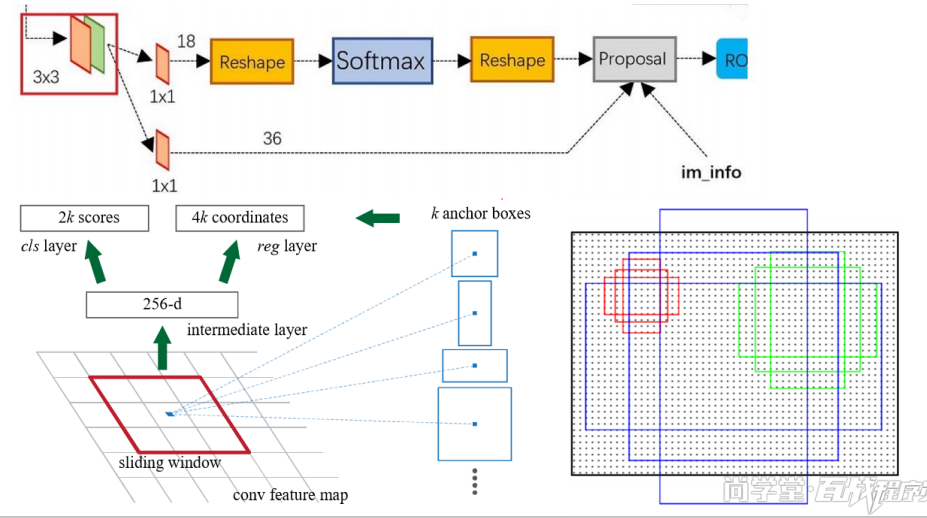
标记正负例标签
• 和每一个gt的重叠比例IoU最大的那个bbox是正例(一张图会有很
多gt)
• 对于任意的bbox和任意gt的IoU的比例大于0.7就是正例
• 对于任意的bbox和任意gt的IoU的比例小于0.3就是负例
损失函数

Lambda控制更重视回归还是分类
• Pi*是真实的类别标签0或1,对于回归是负例就不加调整损失了
• 一张图片有很多个anchor,用i来表示index第几个
• 早期实现及公开的代码中,λ=10,cls项的归一化值为mini-batch的
大小,即Ncls=256,reg项的归一化值为anchor位置的数量,即
Nreg~2,400,这样cls和reg项差不多是等权重的
循环神经网络


Qt 代表t时刻的输出
St 代表t时刻向下个时刻的输出,St=f(W(Xt+St-1) 其中Xt和St-1 是在第二个维度上的拼接,St-1 的形状是(m,n)Xt的形状是(m,k) 其中m代表每次输入的样本个数,n代表隐藏层的结点个数,k代表样本维度,则Xt+St+1的形状是(m,k+n) W的形状是k+n,n V的形状是(n,outpoint)
BasicRCNNCell(普通的循环单元)

使用的非线性变化是tanh
LSTM (Long Short Time Memory)




若有收获,就点个赞吧
0 人点赞
