作者:洛佳
现代内核设计中,常运用地址空间来隔离内核与应用。在分页内存管理下这样的方法较为简便;但也有利用此类设计的安全漏洞出现。本文尝试将完整的地址空间交还给应用,空间中不再保留内核的部分,而由“跳板页”机制切换到内核,我们希望借此解决传统内核的一部分安全问题。
在前面的文章中,我们介绍了一种简单的生成器内核,它使用了较新的生成器语法,便于编写。现代的系统内核通常基于地址空间隔离不同的应用、应用与内核,本文中我们使用Rust语言编写内核,尝试将它的生成器语法与全隔离内核相结合,提出跨空间跳板内核的解决方案,以为完整的异步内核实现提供参考。
1 全隔离内核
传统内核的地址空间有时分为上下两部分:下部分由各个应用轮流占有,而上部分保留于内核使用。这种设计在运行用户程序时,限制用户访问上半部分内存,来避免内核数据本身受到破坏。这部分数据仍然保存在地址空间中,只是通过权限设置,让攻击者无法直接访问。
攻击者确实无法直接访问,于是侧信道攻击出现了。
访问这部分地址的数据,即使访问失败,它也被用于计算其它访问目标的地址,这个目标将进入处理核的高速缓存中。于是攻击者通过时间差,探测其它访问目标的访问时间,计算出最快的访问地址,从而倒推出禁止访问地址的数据值。这类攻击原理中最出名的是Meltdown攻击,它可以以数十千字节每秒的速度套出内核的机密信息。
我们可以采用一种比较新的地址空间设计,rCore-Tutorial内核就采用了类似的设计。在这种设计中,所有的地址全部交由应用使用,内核本身不保留地址。这种设计将无法访问的内核数据挡在地址空间切换之后,而不是留在高地址区域。因为它除了少量需的跳板页,完全不与内核本身共享内存空间,我们可以称之为“全隔离内核”。
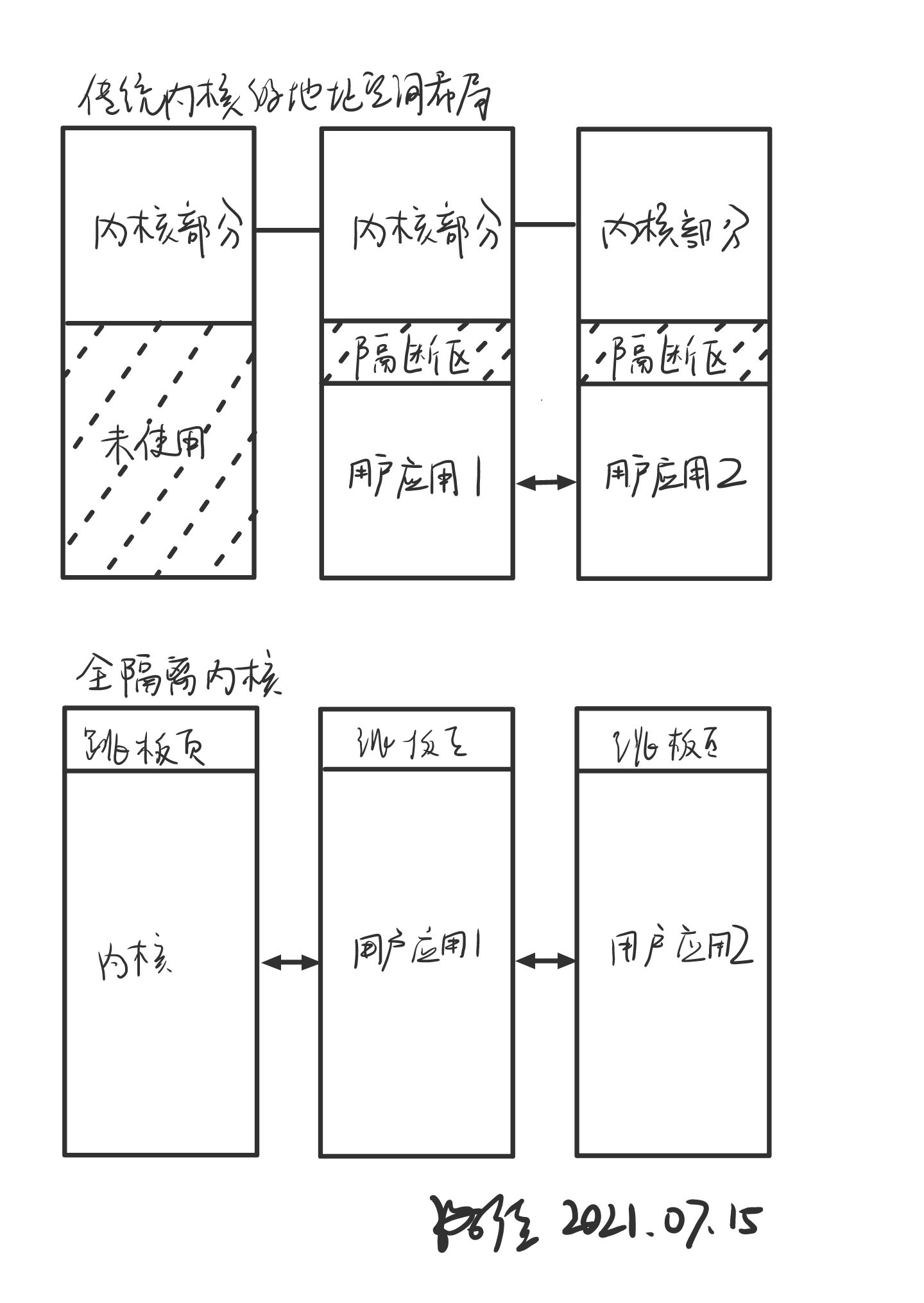
全隔离内核的用户空间中并非仍然存在不可访问的内核数据,而是完全挡在地址空间之外。除此之外,它为应用提供更多的地址位置,允许运行更大的应用程序,或加载更多的动态链接库,以便于提高用户程序设计的灵活性。
注意的是我们通过全隔离机制,可以减少通过其它通道获得内核数据的途径,并不能防止此类攻击命中用户程序的其它部分。针对此类攻击,重新设计处理核的电路仍然是最彻底的防御方法。
2 跳板代码页和跳板数据页
全隔离空间没有和内核本身交集的部分,会出现地址切换“尴尬的代码”问题。我们可以使用跳板页的思想来解决问题。
跳板页是内核和用户空间中保留的少量共享部分。在地址空间切换完成后,程序指针的值没有变化,在上一空间这个指针指着有效的代码,但下一个空间中,该地址就并非是有效的代码了。跳板页的思想是,在不同的地址空间中保留仅有地址相同的有效部分,它们能保证在切换完成后短暂的步骤内,处理核仍然能运行有效的代码。
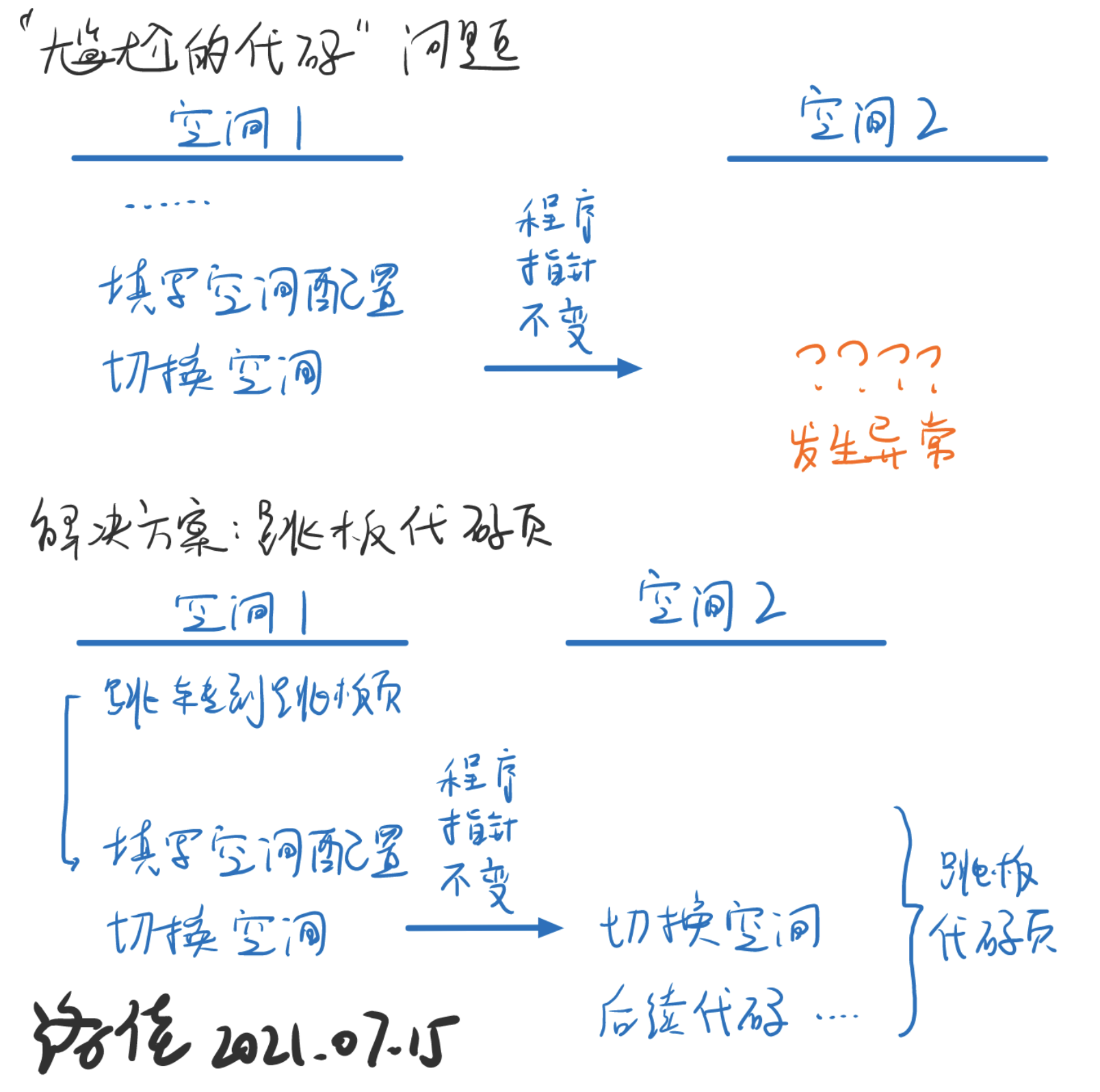
这是跳板代码页的设计思路。切换完成后,应当有一部分的代码完成上下文的加载过程。上下文应该加载到哪儿呢?由于地址空间已经切换,全隔离内核中无法访问内核数据段的内容,因此我们专门设计“跳板数据页”,这是映射到用户空间的一个部分,用于保存当前用户的上下文。
进入用户态时,上下文在切换空间后恢复。为什么不能在之前恢复呢?是因为如果这样做,那么在系统调用、中断等情形需要陷入内核时,需要保存上下文,这些上下文包括内核的地址空间配置,此时就没有地方得知内核的地址空间如何设置了。所以上下文恢复应当在跳板页中用户空间执行的部分。因为每个用户程序需要一个上下文,因此每个处理核都应当有一个跳板数据页,而跳板代码页可以共享同一个。
我们注意到,地址空间切换完成后,特权级的切换并未立即完成。进入新的地址空间后,跳板页的剩余部分将完成特权级的切换流程。因此,跳板页在所有的地址空间下,无论是内核还是用户的空间,都应只有内核特权级可见。跳板代码页和跳板数据页都应当遵守这个规则。
3 帧翻译算法
我们的代码能够在程序间切换了。除了切换,它仍然需要使用操作系统的功能,需要提供部分数据给操作系统使用。在传统内核中,直接设置“以用户身份访问”位,即可直接通过当前地址空间访问用户。然而全隔离内核要求用户和系统的数据隔离,就需要额外的方法。
这里我们选择恢复到传统中模拟页表查询的流程。
不同于简单的页表查询,我们的代码将根据需要查询的缓冲区长度,增加虚拟页号的数值,访问多个页时,多次地查询页表。这样就能连续查询内核需要的所有用户数据了。
我们在分页空间的代码中加入下面的部分。
// impl<M: PageMode, A: FrameAllocator + Clone> PagedAddrSpace<M, A> 中的实现/// 根据虚拟页号查询物理页号,可能出错。pub fn find_ppn(&self, vpn: VirtPageNum) -> Result<(&M::Entry, PageLevel), PageError> {let mut ppn = self.root_frame.phys_page_num();for &lvl in M::visit_levels_until(PageLevel::leaf_level()) {// 注意: 要求内核对页表空间有恒等映射,可以直接解释物理地址let page_table = unsafe { unref_ppn_mut::<M>(ppn) };let vidx = M::vpn_index(vpn, lvl);match M::slot_try_get_entry(&mut page_table[vidx]) {Ok(entry) => if M::entry_is_leaf_page(entry) {return Ok((entry, lvl))} else {ppn = M::entry_get_ppn(entry)},Err(_slot) => return Err(PageError::InvalidEntry)}}Err(PageError::NotLeafInLowerestPage)}
为了简化设计,我们假设内核具有恒等映射,可以直接通过虚拟地址访问物理地址。于是查找单个物理页号的过程完成了。
然后,我们可以编写完整的帧翻译流程。
// 帧翻译:在空间1中访问空间2的帧。本次的实现要求空间1具有恒等映射特性pub fn translate_frame_read</*M1, A1, */M2, A2, F>(// as1: &PagedAddrSpace<M1, A1>,as2: &PagedAddrSpace<M2, A2>,vaddr2: VirtAddr,len_bytes2: usize,f: F) -> Result<(), PageError>where// M1: PageMode,// A1: FrameAllocator + Clone,M2: PageMode,A2: FrameAllocator + Clone,F: Fn(PhysPageNum, usize, usize) // 按顺序返回空间1中的帧{let mut vpn2 = vaddr2.page_number::<M2>();let mut remaining_len = len_bytes2;let (mut entry, mut lvl) = as2.find_ppn(vpn2)?;let mut cur_offset = vaddr2.page_offset::<M2>(lvl);while remaining_len > 0 {let ppn = M2::entry_get_ppn(entry);let cur_frame_layout = M2::get_layout_for_level(lvl);let cur_len = if remaining_len <= cur_frame_layout.page_size::<M2>() {remaining_len} else {cur_frame_layout.page_size::<M2>()};f(ppn, cur_offset, cur_len);remaining_len -= cur_len;if remaining_len == 0 {return Ok(())}cur_offset = 0; // 下一个帧从头开始vpn2 = vpn2.next_page::<M2>(lvl);(entry, lvl) = as2.find_ppn(vpn2)?;}Ok(())}
如果内核不是通过恒等或线性映射布局的,可以维护一个反查询表,需要一个方法让内核直接访问物理空间。在物理空间大于虚拟空间时,这个做法还是有必要实现的。
帧翻译过程完成后,我们可以在空间1中访问空间2的帧了。我们来使用上刚写完的函数,来实现最简单的控制台输出系统调用。
// 核心部分代码。参数:let [fd, buf, len] = args;let buf_vaddr = mm::VirtAddr(buf);mm::translate_frame_read(user_as, buf_vaddr, len, |ppn, cur_offset, cur_len| {let buf_frame_kernel_vaddr = ppn.addr_begin::<M>().0 + cur_offset; // 只有恒等映射的内核有效let slice = unsafe { core::slice::from_raw_parts(buf_frame_kernel_vaddr as *const u8, cur_len) };for &byte in slice {crate::sbi::console_putchar(byte as usize);}}).expect("read user buffer");SyscallOperation::Return(SyscallResult { code: 0, extra: len as usize })
用户使用系统调用时,提供了 若干个变量。当用户传入缓冲区地址和它的长度,帧翻译函数将查询缓冲区占用的所有物理帧,然后内核访问物理帧,来获得它们的内容。内容按块读出,每块包括物理页号、页内的起始偏移地址和剩余长度。最终,本次系统调用将解释每一块内容,并打印到控制台中。
需要注意的是,本次的程序实现只能一块一块地读取数据。如果需要验证跨块的数据合法性,比如需要验证UTF-8字符串是否合法,要么使用方法映射到连续的虚拟地址上再运行,要么需要复制字符串后再运行,否则跨块的合法性验证将可能不正确。
测试程序,我们编写用户程序如下,直接编译,发现输出是对的。
fn main() {println!("Hello, world!");}
事实上,如果将打印的字符串换为超过一帧的长度,也是可以成功打印的。有了跨地址空间访问内存的方法,其它的系统调用也可以开始实现了。
4 跨空间生成执行器
根据上文的分析,每次恢复到用户,先保存执行器上下文,然后切换空间,然后加载用户上下文。每次从用户陷入内核,执行相反的过程即可。
在RISC-V下,编写如下的汇编代码。
#[naked]#[link_section = ".trampoline"]unsafe extern "C" fn trampoline_resume(_ctx: *mut ResumeContext, _user_satp: usize) {asm!(// a0 = 生成器上下文, a1 = 用户的地址空间配置, sp = 内核栈"addi sp, sp, -15*8","sd ra, 0*8(sp)sd gp, 1*8(sp)...... 依次保存tp, s10等寄存器 ......sd s11, 14*8(sp)", // 保存子函数寄存器,到内核栈"csrrw a1, satp, a1", // 写用户的地址空间配置到satp,读内核的satp到a1"sfence.vma", // 立即切换地址空间// a0 = 生成器上下文, a1 = 内核的地址空间配置, sp = 内核栈"sd sp, 33*8(a0)", // 保存内核栈位置"mv sp, a0",// a1 = 内核的地址空间配置, sp = 生成器上下文"sd a1, 34*8(sp)", // 保存内核的地址空间配置"ld t0, 31*8(sp)ld t1, 32*8(sp)csrw sstatus, t0csrw sepc, t1ld ra, 0*8(sp)ld gp, 2*8(sp)...... 依次加载tp, t0等寄存器 ......ld t5, 29*8(sp)ld t6, 30*8(sp)", // 加载生成器上下文寄存器,除了a0// sp = 生成器上下文"csrw sscratch, sp","ld sp, 1*8(sp)", // 加载用户栈// sp = 用户栈, sscratch = 生成器上下文"sret", // set priv, j sepcoptions(noreturn))}
它被链接到专门的跳板代码页中。为了避免和用户程序冲突,跳板代码页被放置在最高的位置上,比如0xffffffffffff000。根据跳板页的长度,我们可以计算它需要多少个页,然后在初始化代码中映射它们。
在后续的代码中,跳板代码页的权限被设置为仅可执行。跳板代码页应当只有内核特权层能访问,否则将可被需要拼接指令的攻击方法利用,或者产生一些逻辑错误。
fn get_trampoline_text_paging_config<M: mm::PageMode>() -> (mm::VirtPageNum, mm::PhysPageNum, usize) {let (trampoline_pa_start, trampoline_pa_end) = {extern "C" { fn strampoline(); fn etrampoline(); }(strampoline as usize, etrampoline as usize)};assert_ne!(trampoline_pa_start, trampoline_pa_end, "trampoline code not declared");let trampoline_len = trampoline_pa_end - trampoline_pa_start;let trampoline_va_start = usize::MAX - trampoline_len + 1;let vpn = mm::VirtAddr(trampoline_va_start).page_number::<M>();let ppn = mm::PhysAddr(trampoline_pa_start).page_number::<M>();let n = trampoline_len >> M::FRAME_SIZE_BITS;(vpn, ppn, n)}
为了跳转到跳板页,由于它在高地址上,我们提前得到函数地址保存,以便恢复函数找到跳板函数的位置。
// 在Runtime::new_user中得到跳板函数的位置extern "C" { fn strampoline(); }let trampoline_pa_start = strampoline as usize;let resume_fn_pa = trampoline_resume as usize;let resume_fn_va = resume_fn_pa - trampoline_pa_start + trampoline_va_start.0;unsafe { core::mem::transmute(resume_fn_va) }// 在初始化执行器函数中得到返回跳板的位置pub fn init(trampoline_va_start: mm::VirtAddr) {extern "C" { fn strampoline(); }let trampoline_pa_start = strampoline as usize;let trap_entry_fn_pa = trampoline_trap_entry as usize;let trap_entry_fn_va = trap_entry_fn_pa - trampoline_pa_start + trampoline_va_start.0;let mut addr = trap_entry_fn_va;if addr & 0x2 != 0 {addr += 0x2; // 必须对齐到4个字节}unsafe { stvec::write(addr, TrapMode::Direct) };}
然后,从用户层返回,我们使用相似的思路编写汇编代码。
#[naked]#[link_section = ".trampoline"]unsafe extern "C" fn trampoline_trap_entry() {asm!(".p2align 2", // 对齐到4字节// sp = 用户栈, sscratch = 生成器上下文"csrrw sp, sscratch, sp",// sp = 生成器上下文, sscratch = 用户栈"sd ra, 0*8(sp)sd gp, 2*8(sp)...... 保存tp到t5 ......sd t6, 30*8(sp)","csrr t0, sstatussd t0, 31*8(sp)","csrr t1, sepcsd t1, 32*8(sp)",// sp = 生成器上下文, sscratch = 用户栈"csrrw t2, sscratch, sp",// sp = 生成器上下文, sscratch = 生成器上下文, t2 = 用户栈"sd t2, 1*8(sp)", // 保存用户栈"ld t3, 34*8(sp)", // t3 = 内核的地址空间配置"csrw satp, t3", // 写内核的地址空间配置;用户的地址空间配置将丢弃"sfence.vma", // 立即切换地址空间"ld sp, 33*8(sp)",// sp = 内核栈"ld ra, 0*8(sp)ld gp, 1*8(sp)...... 加载tp到s10 ......ld s11, 14*8(sp)addi sp, sp, 15*8", // sp = 内核栈"jr ra", // ret指令options(noreturn))}
有了所有的代码之后,我们最终可以实现生成器语法实现的执行器运行时了。
impl Generator for Runtime {type Yield = KernelTrap;type Return = ();fn resume(mut self: Pin<&mut Self>, _arg: ()) -> GeneratorState<Self::Yield, Self::Return> {(self.trampoline_resume)(unsafe { self.context_mut() } as *mut _,self.user_satp); // 立即跳转到跳板页,来进入用户// 从用户返回let stval = stval::read();let trap = match scause::read().cause() {Trap::Exception(Exception::UserEnvCall) => KernelTrap::Syscall(),Trap::Exception(Exception::LoadFault) => KernelTrap::LoadAccessFault(stval),Trap::Exception(Exception::StoreFault) => KernelTrap::StoreAccessFault(stval),Trap::Exception(Exception::IllegalInstruction) => KernelTrap::IllegalInstruction(stval),// ..... 其它的异常和中断e => panic!("unhandled exception: ....")};GeneratorState::Yielded(trap)}}
执行器语法降低了编写内核的思考量,开发者有更多的时间专注于异构计算外设的开发工作中。这种方法暂时相比原来的写法无性能提升,需要编译器技术更新后,对需要保存的执行器上下文有更精细的控制,就有性能提升了。
5 一些思考
我们用执行器语法编写了跨空间跳板内核,它采用了全隔离内核的思想,运用最新的执行器语义降低编程难度。在这之后,异步内核核心的共享内存概念得到了充分的设计经验考验。配合上共享调度器等等核心的概念,我们就可以更便捷、更高效地设计异步内核了。文件、网络等模块也可以更快地完成设计。
编写代码时,因为经常需要操作较高的虚拟地址,可能需要将减法放在运算的前面,或者使用取模回环运算,否则将可能出现运算溢出,干扰内核的正常运行。这种情况很容易在调试时找到。
使用文章的方法编写内核后,完整的地址空间就可以给用户使用了。用户可以把程序链接到0x1000等地址上,无需担心是否与内核冲突。用户的栈也是由内核分配的。
在编写这些代码时,无相之风团队的RISC-V二进制工具箱给了我很大的帮助,让我能更快地完成页表调试过程。完整代码的地址保存在GitHub仓库。
作者简介:
洛佳
华中科技大学网络空间安全学院本科生,热爱操作系统、嵌入式开发。“无相之风”战队成员,飓风内核项目作者之一,3年Rust语言开发经验,社区活跃贡献者。目前致力于向科研、产业和教学界推广Rust语言。

若有收获,就点个赞吧
0 人点赞
