目标
环境
spark2.4.3
YARN 3.1.2 / YARN 2.6.0
PyCharm 2019.2
方法一:开发环境本地driver
此方法在本地开发环境运行python,加载pyspark模块,作为pyspark的driver,连接到yarn上,启动一个spark的Application Master,然后连接到这个AM,并启动executor(worker)容器
1.1.配置
1.1.1.指定YARN环境(XML)
根据HADOOP集群的搭建,使用其中的一小部分XML配置,只要知道HDFS和YARN的地址即可
core-site.xml
<configuration><property><name>fs.default.name</name><value>hdfs://c1</value></property></configuration>
yarn-site.xml
<configuration><property><name>yarn.resourcemanager.hostname</name><value>c1</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
1.1.2.环境变量
HADOOP_CONF_DIR,包含以上两个xml的文件夹
HADOOP_HOME,在子文件夹bin中包含winutils.exe的文件夹
HADOOP_USER_NAME,提供给YARN平台的用户名
1.1.3.PYTHONPATH
使用的python要能找到对应spark版本的pyspark和py4j这两个模块
参考之前文章所描述的
方法1,在pycharm的project interpreter中,配置当前interpreter的python path,添加pyspark中的python文件夹路径和py4j文件路径
方法2,在当前的python环境安装这两个包(自动会装到默认的site-package文件夹,属于PYTHONPATH)
1.2.运行
1.2.1.第一次运行
在pycharm中运行程序
from pyspark.sql import SparkSessionspark=SparkSession.builder.master('yarn').appName('testing1').getOrCreate()
使用yarn 2.6.0
在yarn2.6.0页面,点开对应app名字,右下角点开对应node,左边Tools->Local logs,点开最新的nodemanager的log文件,根据时间定位这次提交,在上下附近找相关的log,看到
2019-07-29 15:35:16,228 WARN org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor: Exit code from container container_e17_1564016774048_0069_01_000001 is : 102019-07-29 15:35:16,228 WARN org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor: Exception from container-launch with container ID: container_e17_1564016774048_0069_01_000001 and exit code: 10ExitCodeException exitCode=10:at org.apache.hadoop.util.Shell.runCommand(Shell.java:604)
在yarn2.6.0页面,点开对应的app名字,右下角点log,这是container log,看到
2019-07-29 15:35:15,840 INFO yarn.ApplicationMaster: Final app status: FAILED, exitCode: 10, (reason: Uncaught exception: org.apache.spark.rpc.RpcTimeoutException:Cannot receive any reply from DESKTOP-RUD1QJ0:56627 in 120 seconds.This timeout is controlled by spark.rpc.askTimeout
使用yarn 3.1.2
在yarn 3.1.2页面,点开对应app名字,右下角点开对应node,左边Tools->Local logs,点开最新的nodemanager的log文件,根据时间定位这次提交,在上下附近找相关的log,看到
2019-08-02 09:40:57,488 INFO org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl: container_1564709857067_0002_02_000001's ip = 172.18.1.181, and hostname = c12019-08-02 09:40:59,349 WARN org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor: Exit code from container container_1564709857067_0002_02_000001 is : 102019-08-02 09:40:59,349 WARN org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor: Exception from container-launch with container ID: container_1564709857067_0002_02_000001 and exit code: 10ExitCodeException exitCode=10:at org.apache.hadoop.util.Shell.runCommand(Shell.java:1009)
在yarn 3.1.2页面,点开对应app名字,右下角点log,出现几个log文件名字,点开stderr,看到
19/08/02 09:40:58 ERROR ApplicationMaster: Uncaught exception:org.apache.spark.SparkException: Exception thrown in awaitResult:...Caused by: java.io.IOException: Failed to connect to DESKTOP-7FRP2AN:56358...Caused by: java.net.UnknownHostException: DESKTOP-7FRP2AN...19/08/02 09:40:58 INFO ApplicationMaster: Final app status: FAILED, exitCode: 10,(reason: Uncaught exception: org.apache.spark.SparkException: Exception thrown in awaitResult:
1.2.2.第二次运行
根据上次失败原因,修改/etc/hosts,把当前使用电脑的host加进去
然后,再运行
from pyspark.sql import SparkSessionspark=SparkSession.builder.master('yarn').appName('testing1').getOrCreate()
失败,看log
在node manager中找到如下内容
2019-08-01 10:12:26,081 WARN org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl:Container [pid=11672,containerID=container_1564625448492_0001_02_000001] is running 247368192B beyond the 'VIRTUAL' memory limit.Current usage: 345.3 MB of 1 GB physical memory used;2.3 GB of 2.1 GB virtual memory used. Killing container.
1.2.3.第三次运行
根据上次失败原因,修改申请的内存大小
from pyspark.sql import SparkSessionspark=SparkSession.builder.master('yarn').config("spark.yarn.am.memory",'2g').appName('testing1').getOrCreate()
方法二:gateway/edgenode上的driver
此方法从本地连接ssh到集群中的edge node,在上面运行python,加载pyspark模块,连接到YARN并启动spark的Application Master,然后启动executor(worker)
2.1.配置
2.1.1.远程edgenode的SSH连接
pycharm菜单,File->Settings,【Build,Execution,Deployment】,【Deployment】
添加一个远程连接,选SFTP模式,写上用户名,密码。然后可以Test一下连接。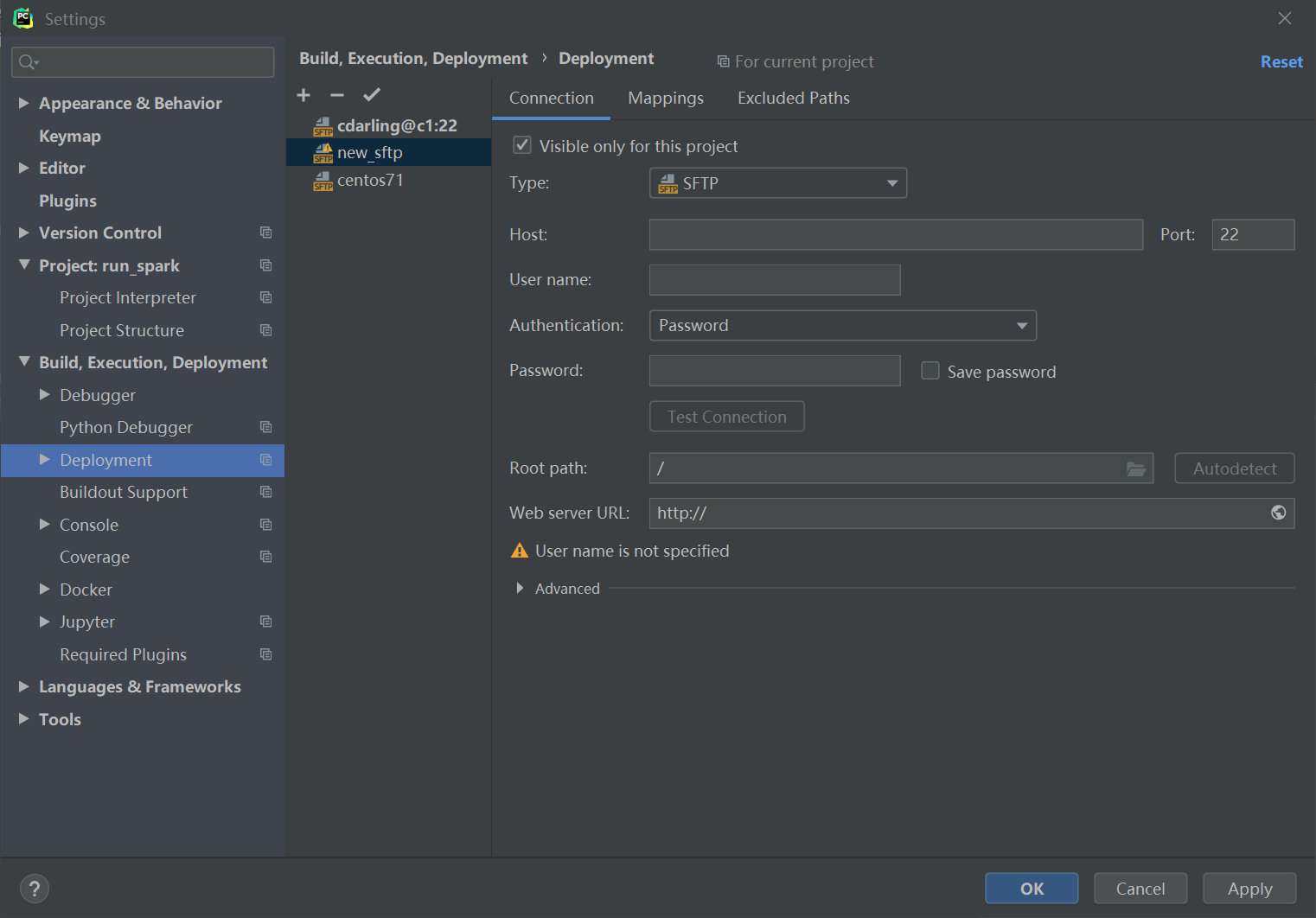
2.1.2.远程环境的python解释器
pycharm菜单,File->Settings,【Project】->【Project Interpreter】
添加一个SSH解释器,确认把这个解释器作为当前project的默认解释器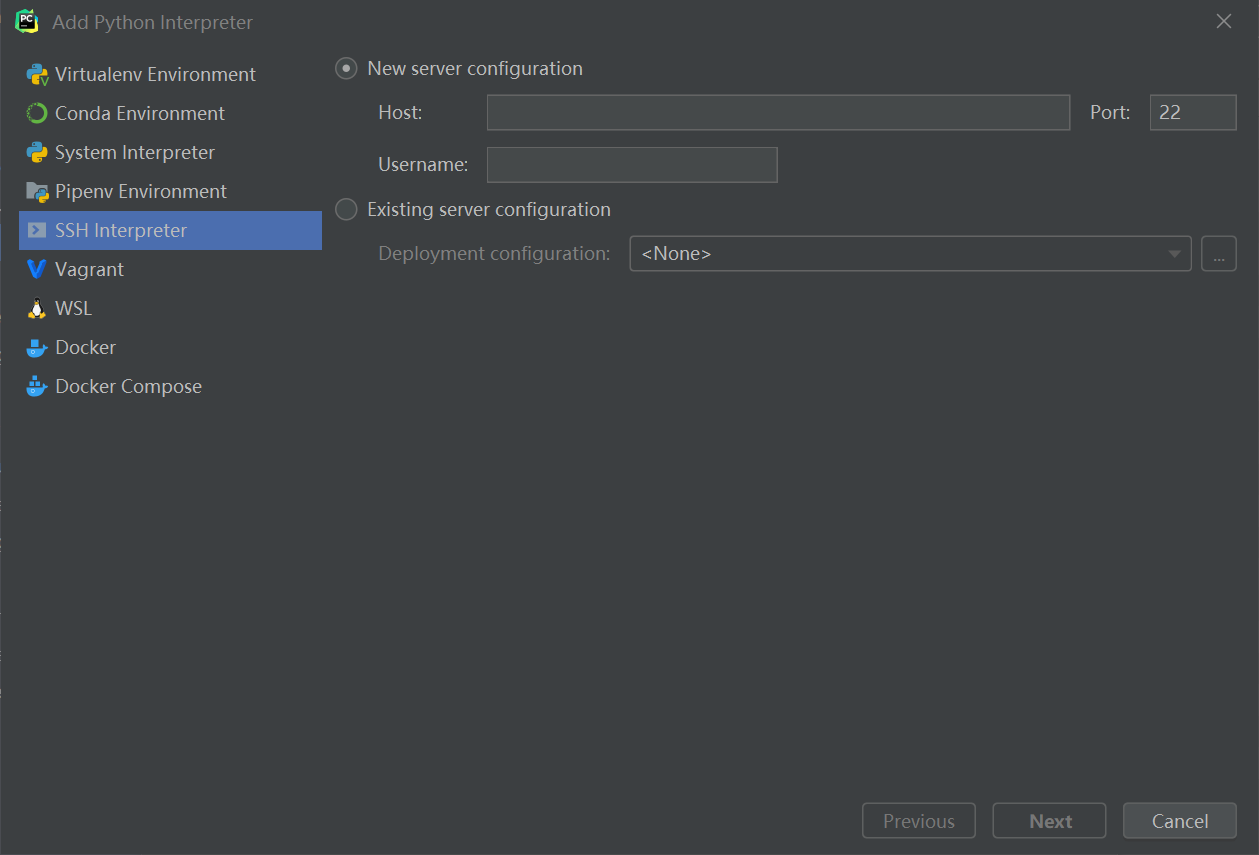
2.1.3.远程python的PYTHONPATH
同方法一,根据之前文章描述的,添加spark中python目录和py4j文件的路径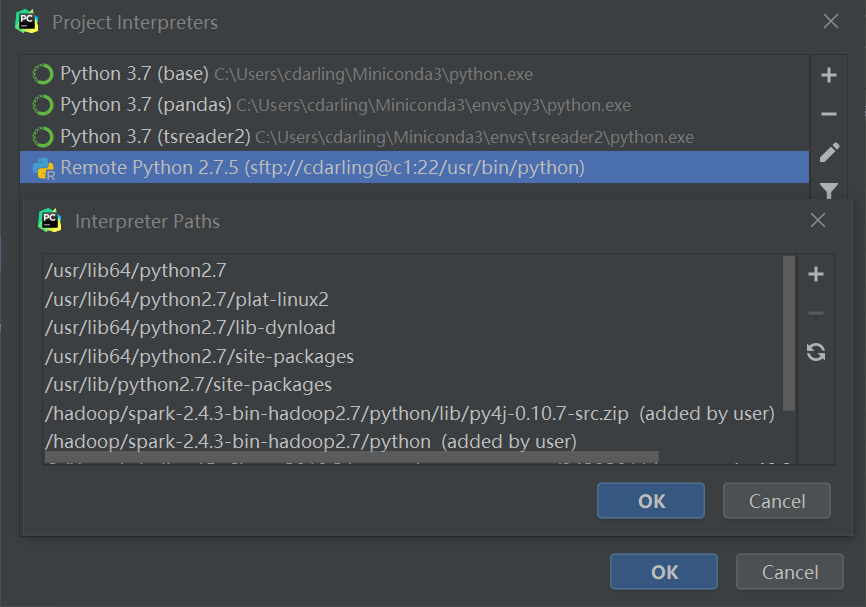
如何找到这两个路径,可以参考本文附录
2.2.运行
2.2.1.第一次运行
from pyspark.sql import SparkSessions=SparkSession.builder.master('yarn').config("spark.yarn.am.memory",'2g').appName('hillo').getOrCreate()sc=s.sparkContextd=sc.parallelize([1,2,3])print(d.collect())
报错如下
Exception in thread "main" org.apache.spark.SparkException:When running with master 'yarn'either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
2.2.2.第二次运行
根据上面报错,找到yarn目录,添加环境变量HADOOP_CONF_DIR
如下,在程序中显示添加即可
from pyspark.sql import SparkSessionimport osos.environ['HADOOP_CONF_DIR']='/hadoop/hadoop-3.1.2/etc/hadoop/'s=SparkSession.builder.master('yarn').config("spark.yarn.am.memory",'2g').appName('hillo').getOrCreate()sc=s.sparkContextd=sc.parallelize([1,2,3])print(d.collect())
成功,输出如下
2019-08-02 10:44:09,146 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).2019-08-02 10:44:10,287 WARN util.Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.2019-08-02 10:44:10,288 WARN util.Utils: Service 'SparkUI' could not bind on port 4041. Attempting port 4042.2019-08-02 10:44:12,119 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.[1, 2, 3]
附录
Q.1.如何找到运行中的pyspark的执行程序路径?
如果能运行pyspark或pyspark2(cloudera中对于2.x版本的命令),可以从这里出发
首先运行pyspark(或pyspark2),然后运行命令
import osos.environ['SPARK_HOME']os.environ['SPARK_CONF_DIR']
就可以看到这两个环境变量的值,我感觉pyspark命令如果能正常运行,会自动配置好这两个变量的
Q.2.如何检查运行中的pyspark的spark配置变量?
正在运行的pyspark环境,肯定是有spark context的(或者从sparksession中得到)
用sc变量可以获取到当前的spark配置变量,以(key,value)的tuple,展示在一个list中
如果想根据key查询,可以转换成字典,比如
t=sc.getConf().getAll()d=dict(t)d['spark.app.name']

若有收获,就点个赞吧
0 人点赞
