目标
在个人使用的开发用电脑上,配置pyspark环境,能够交互式运行REPL(即ipython方式)或任务式(一次运行完)的pyspark程序。
环境
PyCharm 2019.1
MiniConda3
OracleJDK 8
新方法
conda install pyspark=2.4.4
后面的基本不用看了,都是过时的方法
就设置一下HADOOP_HOME,放个winutils.exe就行了
软件下载
https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
下载上面这个压缩包,就能用方法一来配置了
如果是不带hadoop2.7后缀的,则需要另外配置hadoop环境,否则提示找不到log4j,提供之后也会找不到hadoop的包
而pyspark-2.4.3.tar.gz是给python安装到site-package使用的,后面方法二再说
配置HADOOP_HOME
到github下载winutils.exe,放到一个文件夹中的bin子文件夹中,然后把HADOOP_HOME环境变量配置为这个文件夹,比如
HADOOP_HOME=C:\files\hadoop\311
然后我的winutils.exe是在C:\files\hadoop\311\bin\winutils.exe
如果不进行这一步配置,在pyspark初始化的时候会提示找不到winutils.exe
配置这个环境变量,
1可以在系统中配置,右键我的电脑,属性,高级,环境变量
2可以在pycharm当前项目中配置,Run->Edit Configurations,其中的Environment variables即是
方法一:spark-bin-hadoop方式
配置python_path
File->Settings->Project->Project Interpreter
右边点击设置(齿轮图标),Show All,右边就会出现Interpreter Paths配置的按钮,如下图(右边的按钮)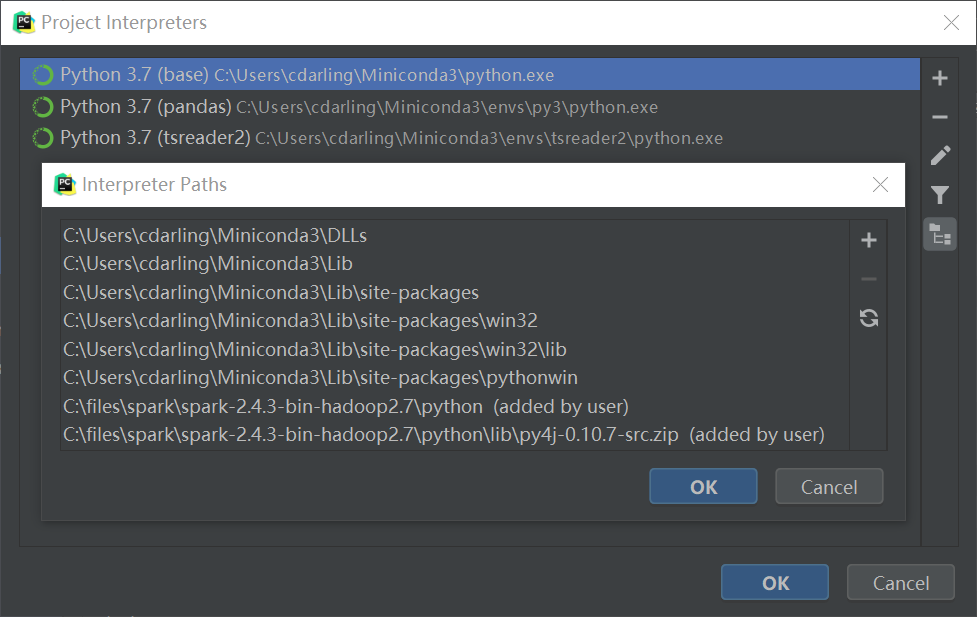
在其中添加之前下载并解压的文件夹中的两个内容,一个python目录,一个python/lib/py4j压缩文件
运行
如下所示
from pyspark.sql import SparkSessionspark=SparkSession.builder.getOrCreate()data=spark.sql('select 1').collect()print(data)
方法二:pyspark.tar.gz方式
如果你的网络不错,可以使用这个方式
可以为这个环境新创建一个conda环境
下载的pyspark-2.4.3.tar.gz目录下操作:
pip install pyspark-2.4.3.tar.gz
然后它会检查这个压缩包,根据其中setup.py的要求,去pypi下载py4j包,这个包不大,但要看你连pypi网络如何
然后在这个环境中,就能使用pyspark了

若有收获,就点个赞吧
0 人点赞
